

【Hadoop】HDFS体系结构分析
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
文章目录
HDFS主要包含NameNode、Secondary NameNode和DataNode三部分且这三部分在分布式文件系统中分属不同的机器其中Secondary NameNode不是必须的在HA架构中Standby NameNode可以替代它。 这一部分如果看不懂没关系先看对各部分的功能介绍如果你不先了解他们是干嘛的那么这些抽象的名词没有任何意义。
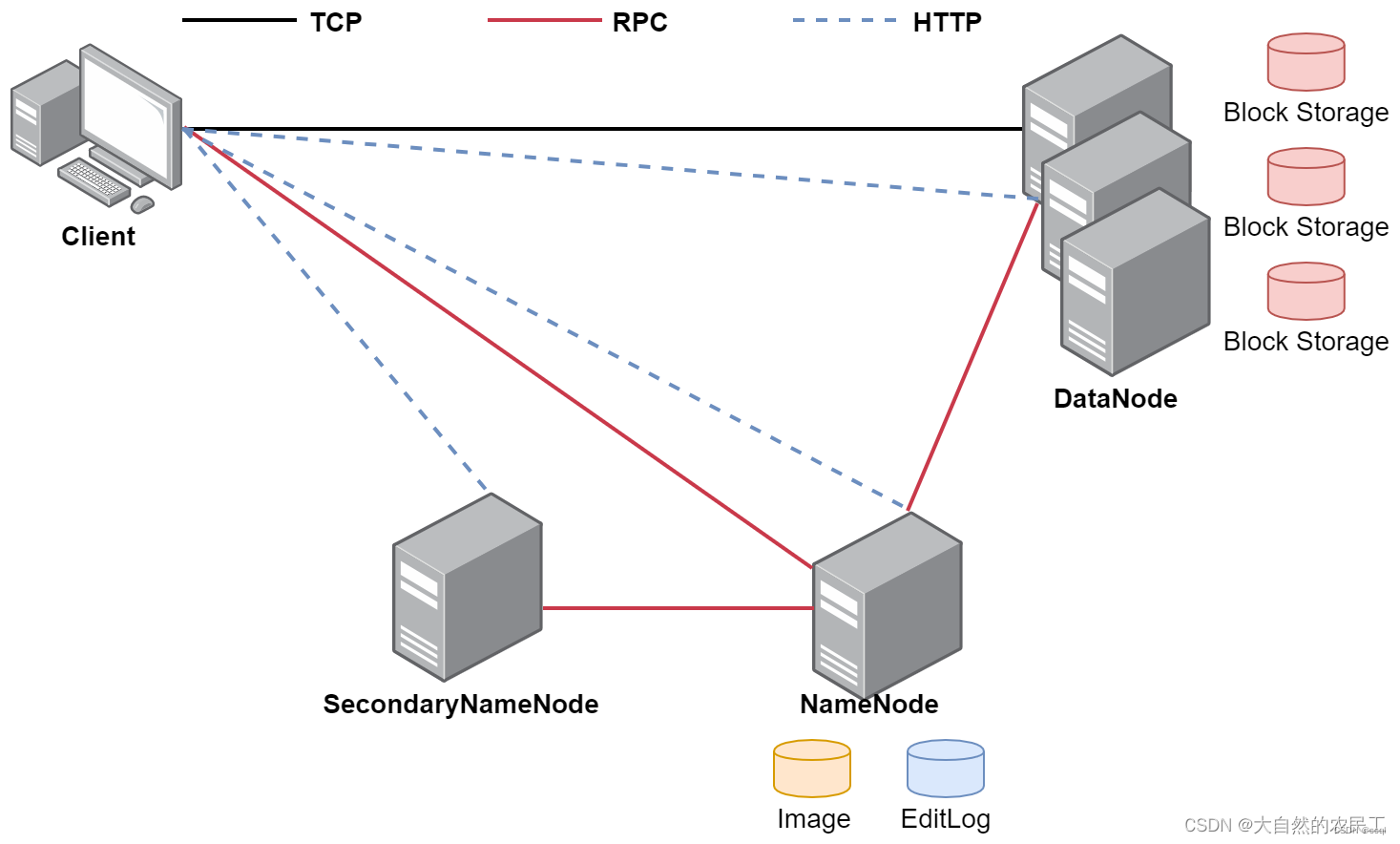
1. NameNode
NameNode主要维护着整个文件系统的文件目录树、文件/目录的信息和每个文件对应的数据块列表并且还负责接收用户的操作请求。
- 目录树表示目录之间的层级关系就是我们在HDFS上执行ls命令可以看到的那个目录结构信息。
- 文件/目录的信息表示文件/目录的的一些基本信息所有者、属组、修改时间、文件大小等信息
- 每个文件对应的数据块列表如果一个文件太大那么在集群中存储的时候会对文件进行切割这个时候就类似于会给文件分成一块一块的存储到不同机器上面。所以HDFS还要记录一下一个文件到底被分了多少块每一块都在什么地方存储着这些信息记录在fsimage文件中。
- 接收用户的操作请求我们在命令行使用hdfs操作的时候是需要先和namenode通信才能开始去操作数据。
NameNode主要包含四个主要文件这四个文件分别是fsimage、edits、seen_txid和VERSION他们十分重要下面会依次介绍。
- fsimage文件
fsimage文件是元数据镜像文件存储某一时刻NameNode内存中的元数据信息类似于定时的快照操作这里的元数据信息是指文件目录树、文件/目录的信息、每个文件对应的数据块列表可以说fsimage中存放了hdfs最核心的数据。 - edits文件
edits文件是操作日志文件事务文件这里面会实时记录用户的所有操作。固化的一些文件内容是存储在fsimage文件中而当前正在上传的文件信息存储在edits文件之中edit文件不唯一这些细致的操作信息会放在多个文件中文件统一命名为edits_*这里的*代表数字编号。edits文件中的信息非常细致举个例子上传一个120M的文件这个事件在fsimage中可能只记录了最终的上传结果信息以及分块编号和地址等而在edits文件中将记录如下的完整过程
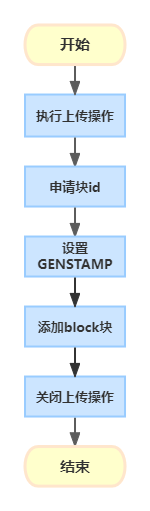
由此可见edits文件中的记录是非常细致而且HDFS的增删改查会在edit文件和fsimage文件中都留下记录但是edits的记录明显更加细致因此实际上fsimage文件中的内容是由edits文件定期合成的这个操作就是由Secondary NameNode完成的且这个进程只负责这一件事之所以在前面说这个进程不是必须的是因为在存在多个NameNode的HA架构中这一部分工作可以由其他的NameNode也就是Standby NameNode来完成。关于HA结构的介绍陈述可以在下一篇博客中看到。 - seen_txid文件
seen_txid文件中只记录一个数字其代表的是NameNode里面最后一个edits文件的编号NameNode重启的时候会按照seen_txid的数字顺序从edits_0000001开始运行edits文件。如果根据对应的seen_txid无法加载到对应的文件NameNode进程将不会完成启动以保护数据一致性。格式化后seen_txid文件记录的数字为0。 - VERSION文件
VERSION文件保存集群的版本信息与DataNode文件的版本信息保持一致当集群被格式化之后会发生变化但重复格式化后DataNode的版本信息不会变会出现版本信息不匹配问题导致bug。
2. Secondary NameNode
在上文对edits文件的介绍中已经提及了Secondary NameNode的作用即定期的把edits文件中的内容合并到fsimage中这个合并操作称为checkpoint。上文也有说过Secondary NameNode并不是必须的因为在存在多个NameNode的HA架构中这一部分工作可以由其他的NameNode也就是Standby NameNode来完成。
3. DataNode
DataNode提供真实文件数据的存储服务针对datanode主要掌握两个概念一个是block一个是replication。
- blockHDFS会按照固定的大小顺序对文件进行划分并编号划分好的每一个块称一个BlockHDFS默认Block大小是 128MBBlokc块是HDFS读写数据的基本单位。若一个文件不足128M那么该文件独占一个Block块这时该块大小不为128M而是这个文件的大小。
- replication译为复制这里指副本默认每个文件的副本为3份在hdfs-site.xml配置文件中进行配置且分别存储在不同的DataNode机器上。
最后举一个例子加深理解假设我们上传了两个10M的文件又上传了一个200M的文件那么会产生多少个block块在HDFS中又会显示几个文件
答会产生4个block块因为默认每个block的大小为128M因此200M的文件会被分为两个块分别是128M和72M。在HDFS中会显示3个文件。