

python分类分析—朴素贝叶斯算法及文本分类案例
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
一、朴素贝叶斯分类算法原理
1.1 概率知识点
- 联合概率:包含多个条件,且所有事件同时成立的概率
- 记作:P(A,B)
- 例如:P(程序员,体型匀称),P(程序员,超重,脱发)
- 条件概率:就是事件A在另外一个事件B已经发生条件下的发生概率
记作:P(A|B)
例如:P(程序员|男生),P(程序员,体重标准|女性)
相互独立:如果P(A,B)=P(A)P(B),则称事件A与事件B相互独立。
1.2 贝叶斯公式
- P(C|W) = [ P(W|C)*P(C) ] / P(W) 其中,w为给定文档的特征值(频数统计,预测文档提供),c为文档类别。
- 即:P(x1,x2,...|Y)= P(Y|X1,X2,…)*P(X1,X2,…)
- 转化一下:P(Y|X1,X2,…)=[ P(X1,X2,…|Y)*P(Y) ]/P(X1,X2,…)
- 简单理解一下:在已知特征信息X1,X2,...的条件下,事件Y发生的概率,等于在事件Y发生的条件下这些特征信息的联合概率(所有特征信息都成立的概率),乘以在这个样本中事件Y发生的概率,再去除以在整个样本中这些特征信息的联合概率。
1.3 朴素贝叶斯分类算法原理
朴素 + 贝叶斯
- 朴素:假设特征信息X1,X2,…之间是相互独立的。即P(X1,X2,…)=P(X1) * P(X2)*…
- 贝叶斯:P(Y|X1,X2,…) = [ P(X1,X2,…|Y)*P(Y) ] / P(X1,X2,…)
- 朴素贝叶斯:P(Y|X1,X2,…)=P(X1,X2,…|Y)* P(Y) / P(X1,X2,…) = P(X1|Y)* P(X2|Y)…P(Xn|Y) * P(Y) / P(X1)P(X2)…P(Xn)
- 简单理解一下:在已知相互独立的特征信息X1,X2,...的条件下,事件Y发生的概率,等于在事件Y发生的条件下每个独立特征信息发生的概率乘积,乘以在这个样本中事件Y发生的概率,再去除以在整个样本中这些特征信息的联合概率(这些特征信息发生的概率乘积)。
1.4 算法改进
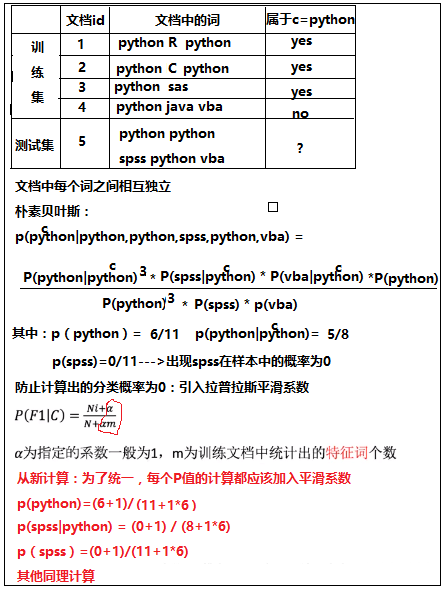
目的:防止计算出的分类概率为0
- 不管是贝叶斯公式还是朴素贝叶斯公式,我们发现都是概率的乘法和除法,所以一旦有某个概率为0,就会导致结果概率为0的错误结果。
- 所以在实际的算法中我们需要引入拉普拉斯平滑系数,解决这一问题。
- 拉普拉斯平滑系数 :p(Fi|C)=(Ni+alpha)/(N+alpha*m)
- alpha是指定的系数一般是1,m是训练文档中统计出来的特征词的个数。
1.5 案例说明
1.6 应用场景
- 应用场景:如文本分类(关键词之间是相互独立的),垃圾邮件的分类,信用评估,钓鱼网站检测等。
- 优缺点:优点对缺失值不敏感。缺点特征变量(特征值,特征信息)间需要相互独立。
二、pyhon实现朴素贝叶斯分类
2.1 pyhon的朴素贝叶斯API
- from sklearn.naive_bayes import MultinomialNB #朴素贝叶斯库
- MultinomialNB(alpha=1.0) #朴素贝叶斯分类,ealpha:拉普拉斯平滑系数
python进行文本分类分析案例
# 1 获取数据----对新闻分类
from sklearn.datasets import fetch_20newsgroups
news=fetch_20newsgroups(data_home=r'D:\Case_data\fetch_20newsgroups',subset='all') #将数据下载到本地# 2 数据处理(略),查验数据
# display(news.data[0]) #返回特征值(自变量)列表,每个元素是一篇新闻
print(len(news.data)) #查看有多数篇新闻
# display(news.target) #返回目标值(因变量)数组,用数字表示的每篇新闻的分类
# display(news.target_names) #返回目标值数字对应的解释#3 数据集的划分
from sklearn.model_selection import train_test_split
#语法:x_train,x_test,y_train,y_test = sklearn.model_selection.train_test_split(x,y,test_size=,random_state=)
#解释:训练的特征值(自变量),测试的特征值,训练的目标值,测试的目标值= 划分函数(x特征值,y目标值,test_size=测试集比例,随机种子)
#datasets.base.Bunch(继承自字典)类
x_train,x_test,y_train,y_test = train_test_split(news.data,news.target,test_size=0.25,random_state=11)
print(len(x_train),len(x_test),len(y_train),len(y_test))# 4 特征工程 -- 文本特征抽取
import pandas as pd
import numpy as np
from sklearn.feature_extraction.text import TfidfVectorizer
import jieba #(jieba 分词,安装:pip install jieba)
#数据
#x_train,x_test
#分词 --英文文档不需要分词操作
# cut_data=[]
# for s in data:
# cut_s=jieba.cut(s)
# l_cut_s=' '.join(list(cut_s))
# cut_data.append(l_cut_s)
# print(cut_data)
#TF-IDF
transfer = TfidfVectorizer() #实例化一个文本处理转换器类
x_train = transfer.fit_transform(x_train) #调用fit_transform() ,先转化训练集
#print(x_train) #非零值的坐标 值
#print(transfer.get_feature_names())
#print(x_train.toarray())
x_test = transfer.transform(x_test) #这里其实使用了训练集的fit,调用transform() 转化测试集
#print(x_test) #非零值的坐标 值
#print(transfer.get_feature_names())
#print(x_test.toarray())# 5 朴素贝叶斯预估器流程
#语法:sklearn.naive_bayes.MultinomiaNB(alpha=1.0) #朴素贝叶斯分类
# 模型调优(略)
from sklearn.naive_bayes import MultinomialNB #朴素贝叶斯
from sklearn.model_selection import GridSearchCV #网格搜索和交叉验证
#estimator = MultinomialNB(alpha=1.0) #实例化一个转换器类,不进行模型调优的时候用
#加入模型选择与调优,网格搜索和交叉验证
estimator = MultinomialNB()
#准备参数
param_dict = {"alpha":[1,2,3]} #ealpha:拉普拉斯平滑系数值设定的可能取值
estimator = GridSearchCV(estimator,param_grid=param_dict,cv=4) #cv=4是4折交叉验证(实际中经常用10)
#执行预估器,训练模型
estimator.fit(x_train,y_train)# 6 模型评估选择
#6.1:比对真实值和预测值
y_predict = estimator.predict(x_test) #计算预测值
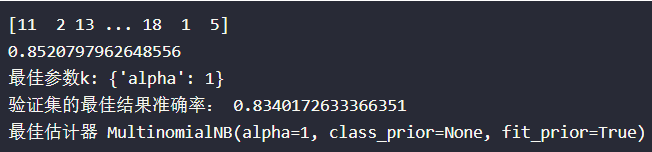
print(y_predict)
b = y_test == y_predict #比对真实值和预测值,相同的返回True
coun = y_test[b].count()[0] #统计正确的个数
scale = coun/y_test.count() #计算正确的比例
display(scale)
#6.2:直接计算准确率
accuracy=estimator.score(x_test,y_test)
print(accuracy)
# 3、查看网格搜索和交叉验证返回结果
# 最佳参数:best_params_
print("最佳参数k:",estimator.best_params_)
# 验证集的最佳结果:best_score_
print("验证集的最佳结果准确率:",estimator.best_score_)
# 最佳估计器:best_estimator_
print("最佳估计器",estimator.best_estimator_)
# 交叉验证结果:cv_results_
#print(estimator.cv_results_) #比较长这里就不输出了结果如下:
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |