

Python爬虫入门(一)(适合初学者)
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
Python爬虫入门(一) 适合初学者
关于爬虫是什么怎样保证爬虫的合法性小编在这就不再过多的阐述从本章起小编将和大家一起分享在学习python爬虫中的所学希望可以和大家一起进步也希望各位可以关注一下我
首先我们来初步了解下如何使用开发者工具进行抓包。以 https://fanyi.baidu.com/ 为例。在网页界面右键点击检查或使用CTRL+SHIFT+I打开。
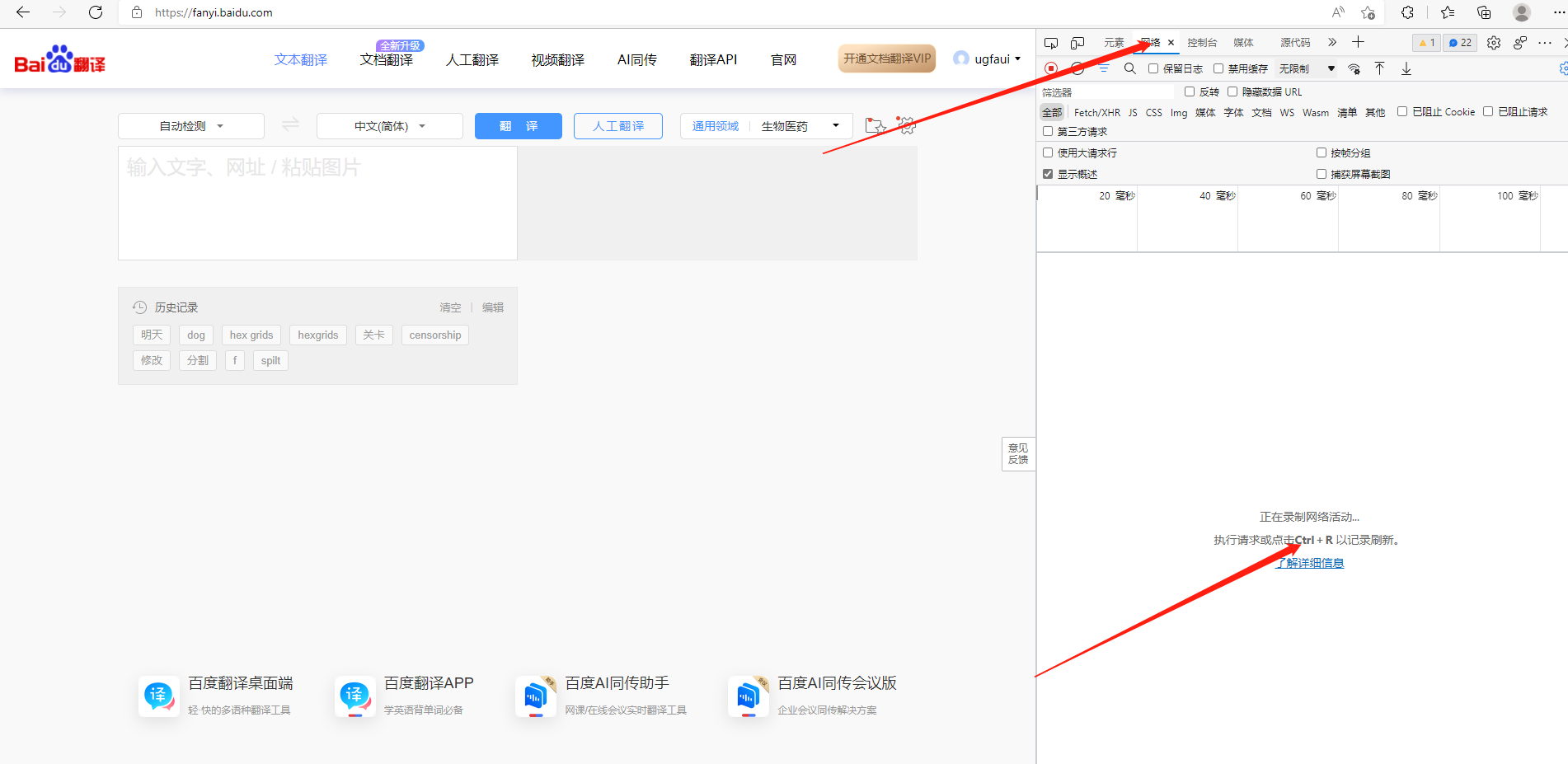
如图打开了开发者工具后我们点击网络得到如上界面。接着按照提示按CTRL+R进行刷新。刷新后如下图所示
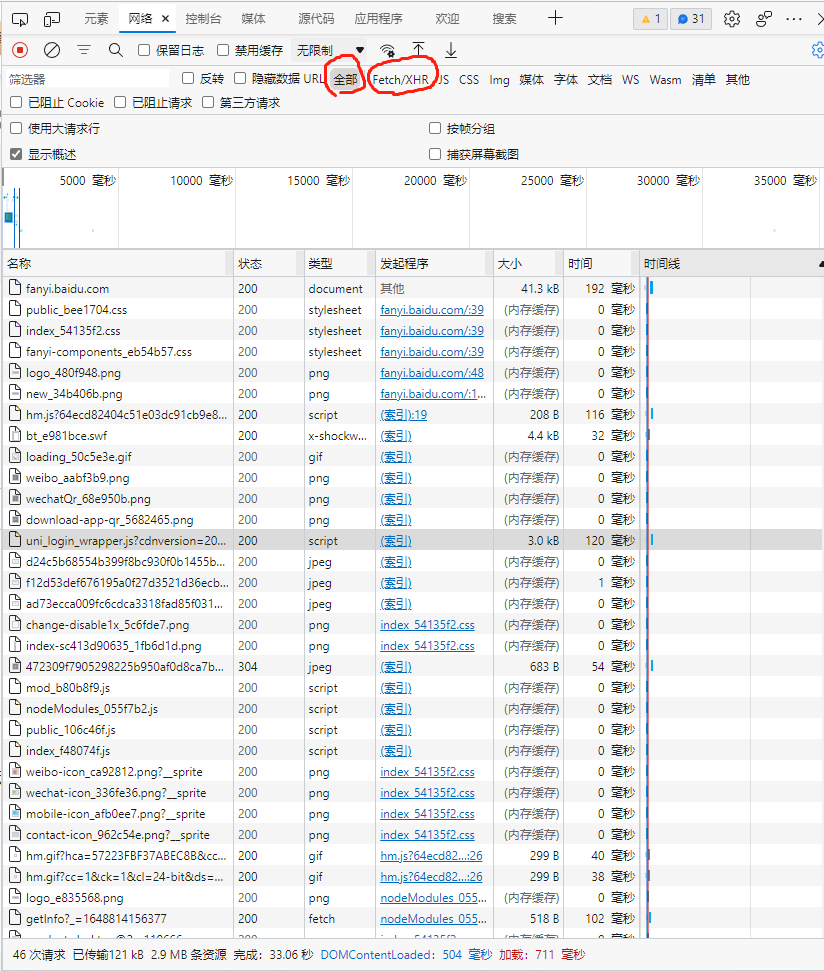
此时我们即可看到我们获取到了很多很多的数据包但是想要完成一个爬虫程序的第一步就是在这众多的包中找到正确的API数据接口。通俗点将就是你想要获得一个小球而这个小球藏在一个小箱子里而此时有很多很多个小箱子想要获得小球则需要找出小球究竟藏在哪个箱子里。一般在实际操作中我们只需要使用到上图小编圈出来的两个地方一个是全部、另一个是Fetch/XHR。在全部中会显示所有请求获取到的包其中包括网页源码、css、js、图片、ajax等。而在Fetch/XHR中则只能看到ajax请求所获得的数据包。ajax请求一般是对动态数据进行请求即前端向后端发起请求动态请求到后端数据库中的数据并将这些数据展示在前端网页中。可能会感觉听起来云里雾里没关系哦后面根据一个一个的例子可以更好的了解或者小编以后更新django框架时会细讲ajax请求
接下来我们进入爬虫的第一个程序(百度翻译的单词爬虫)
在百度翻译中我们可以输入一个单词然后网页会动态的在界面上给我们展示这个单词的意思因此我们可以非常非常非常自信的确定单词意思的数据是通过动态请求得到的既然说动态请求得到的那么又可以确定这八成就是一个ajax请求。因此我们选中Fetch/XHR。
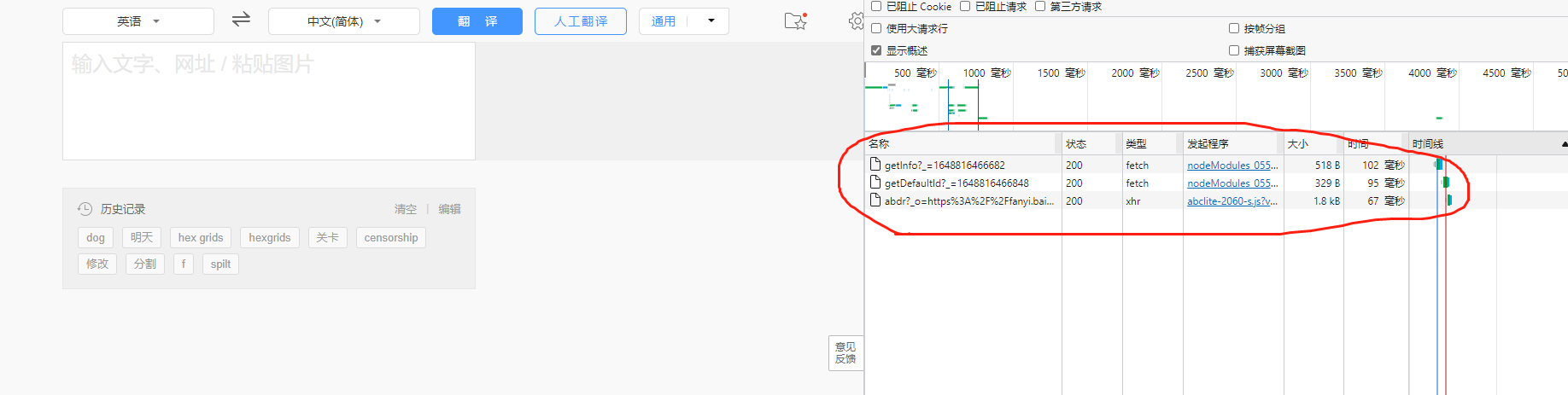
根据观察此时看到Fetch/XHR中只有这三个数据包但点开查看其响应即返回值时确发现好像没有我们需要的数据。这个什么呢不必慌张因为我们并还没有在左边输入单词的框中输入过单词于是我们可以在左边随意的输入一个英文单词进行测试

当我们输入完一个单词后发现右边又抓到了很包对这些抓到的包进行分析可以找到如下这个数据包

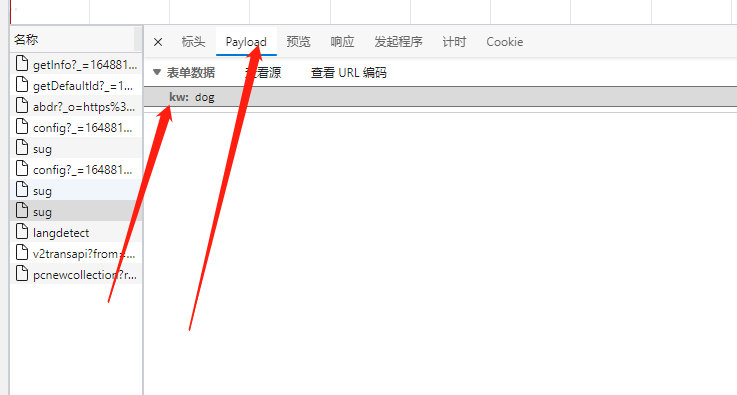
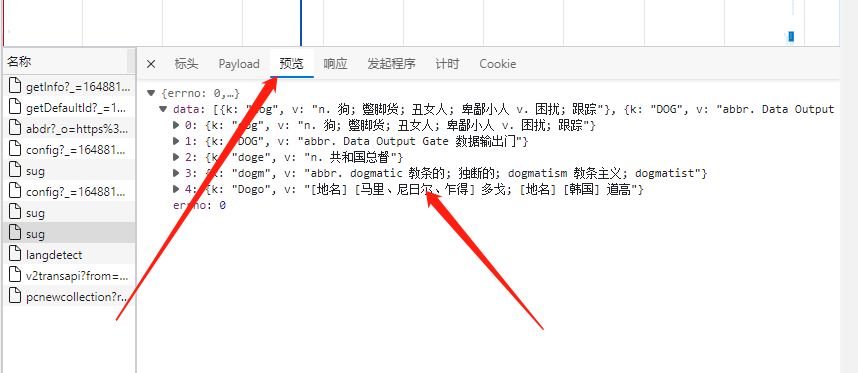
由上述三种图可以看出这个包中就藏着我们想要的数据。通过查看该包的标头可以确定请求数据的请求URL是https://fanyi.baidu.com/sug且发起的请求方式为POST且根据Content-Type: application/json可以得出请求的返回值为json格式在payload中可以分析出该POST请求需要携带一个名为kw的参数参数的值为我们需要查询的单词。这时我们即可以弄清楚该网站查询单词的运行机制了我们在查询框中输入英文单词网页前端拿到我们输入的单词通过ajax请求向https://fanyi.baidu.com/sug发起请求并将我们输入的英文单词作为表单数据传输给后端后端根据我们输入的单词在数据库中查询该单词拿到该单词的意思然后再次返回给前端并展示出来。接下来就进入令人激动的coding代码部分。
代码部分
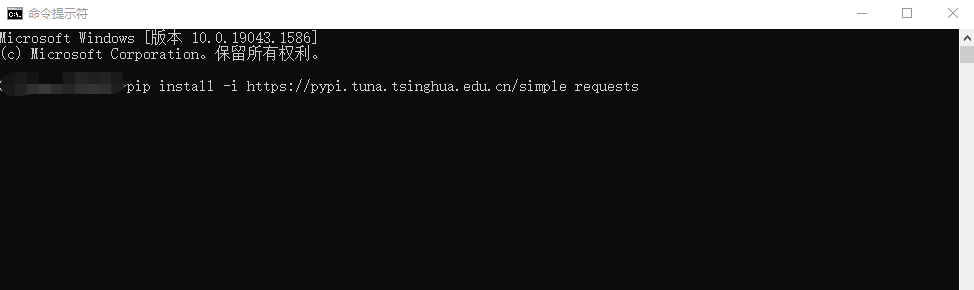
1、安装requests包在cmd命令行中输入以下语句进行自动下载安装
前提需要电脑上已经装有python且配置了环境变量
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple requests
2、导入requests包并确定url
import requests
url = 'https://fanyi.baidu.com/sug'
3、进行UA伪装
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36 Edg/98.0.1108.56'
}
UA伪装可以理解为将我们的爬虫程序伪装起来增加请求成功的可能性。
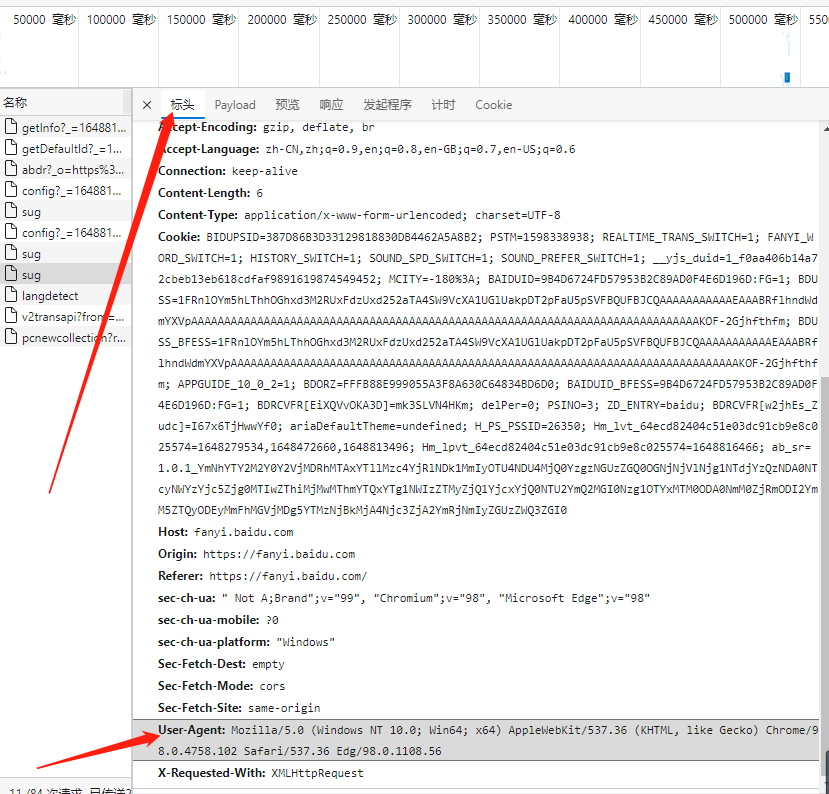
只需在数据包的标头中拉到最下面即可以找到这个User-Agent将其复制下来像小编一样在python用字典进行封装即可。
4、确定参数并对数据接口发起请求获得返回结果
data = { #post请求携带的参数
'kw':'dog'
}
#对目标url发起post请求
response = requests.post(url=url,headers=headers,data=data).json()
print(response)
结果如下

至此一个最最最简单的爬虫程序就写完了是不是很简单接下来我们对程序进行完善所有代码如下
import requests
def spider(url,headers,data):
response = requests.post(url=url, headers=headers, data=data).json() # 对目标url发起post请求
for key in response['data'][0]:
print(key,response['data'][0][key])
def main():
url = 'https://fanyi.baidu.com/sug' #需要请求的url
headers = { #进行UA伪装
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36 Edg/98.0.1108.56'
}
while True: #使程序进入死循环
kw = input("输入需要查询的单词")
data = { #post请求携带的参数
'kw':kw
}
spider(url=url,headers=headers,data=data) #调用自定义函数spider
if __name__ == '__main__':
main()
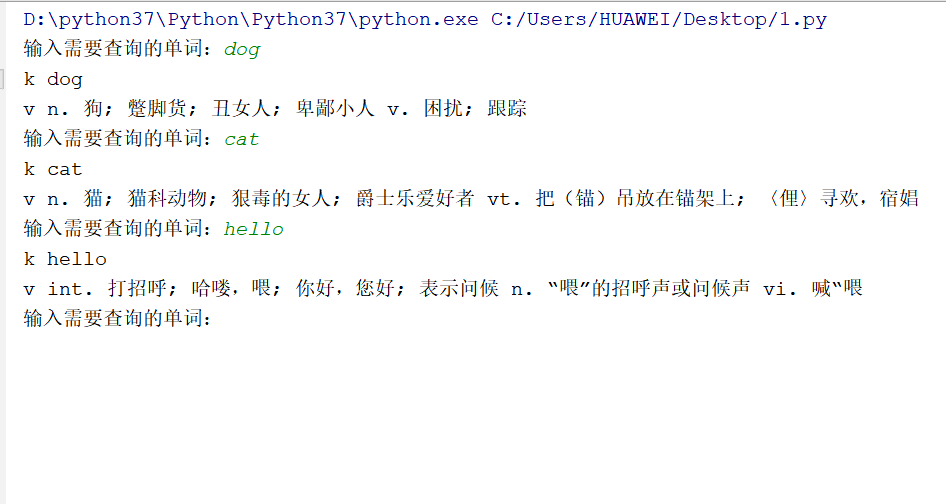
这样一个简单的基于爬虫的单词查询器就完成啦其中对json数据进行提取的代码如果有看不懂的小伙伴可以去学习一个python的字典。
希望该文章可以帮助到你如果觉得有用可以关注一下我哦后序会写更多的例子。