python爬虫电影数据抓取实战
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
想要了解最近电影院播放的都有什么影视电影,哪部值得推荐,如果单纯靠手动收搜不全面,下面我们就先使用urllib.request模块抓取整个网页,再使用re模块获取电影信息,做个简单的爬虫做个数据分析。
编写simpleCrawlerNowMoive.py代码如下
#!/usr/bin/env python
# coding: utf-8
__author__ = 'www.py3study.com'
import re
import urllib.request
class TodayMoive(object):
def __init__(self):
self.url = 'https://movie.douban.com/people/1166776/'
self.timeout = 3
self.filename = 'todaymoive.txt'
'''内部变量定义完毕'''
self.getmoiveinfo()
def getmoiveinfo(self):
response = urllib.request.urlopen(self.url, timeout=self.timeout)
content = response.read().decode('utf-8')
#findall匹配电影名字的段落
moivelist = re.findall('class="cover"><img alt="', '')
st = st.replace('"', '')
#split字符串切割,以' '空格为分隔符,取第0个值
st = st.split(' ')[0]
return st
if __name__ == '__main__':
tm = TodayMoive()
应该看到的结果
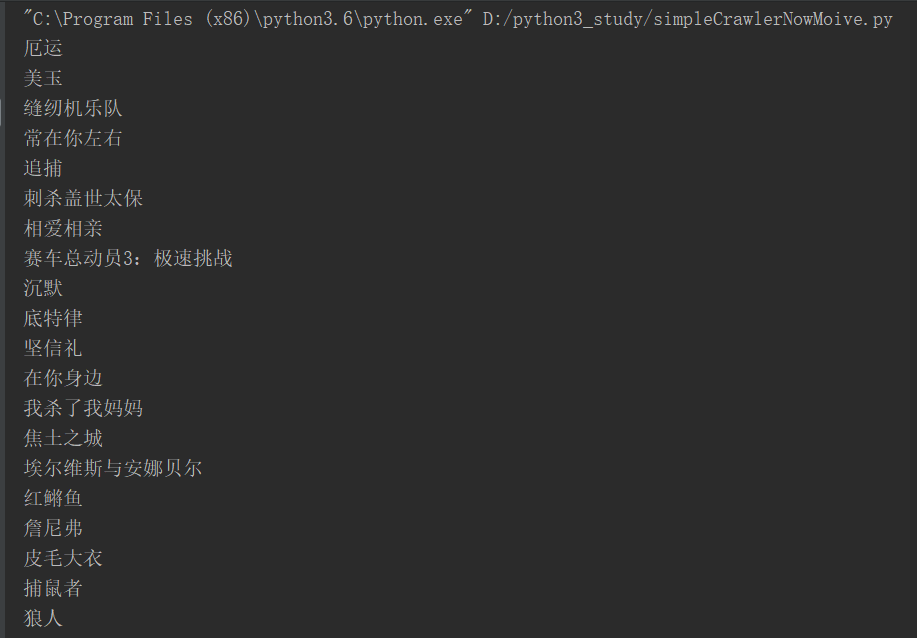
会在当前目录下生成一个todaymoive.txt文件,内容如下。

如果单从这些代码看起来是不是以为不是爬虫,其实严格意义上来说这个就是爬虫,只是相对来说内容简单,爬取的数据相对较少。大体上的爬虫框架是这么回事,如果用来爬取大型项目也是没有问题的。
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |

