

云服务器搭建flink集群-CSDN博客
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
文章目录
1.集群配置
| 节点服务器 | s1 | s2 | s3 | s4 | gracal |
|---|---|---|---|---|---|
| 角色 | JobManager TaskManager | TaskManager | TaskManager | TaskManager | TaskManager |
2.修改集群配置
-
配置flink-conf.yaml
[gaochuchu@s1 conf]$ vim flink-conf.yaml jobmanager.rpc.address:s1 jobmanager.bind-host: 0.0.0.0 taskmanager.bind-host: 0.0.0.0 taskmanager.host: s1 rest.address: s1 rest.bind-address: 0.0.0.0 -
配置workersTaskManager角色的服务器
[gaochuchu@s1 conf]$ vim workers s1 s2 s3 s4 gracal -
配置masters,Master角色的服务器
[gaochuchu@s1 conf]$ vim masters s1:8081 -
分发配置,并且修改其他服务器的taskmanager节点地址为当前主机名
[gaochuchu@s1 module]$ xsync flink-1.17.0/ [gaochuchu@s2 conf]$ vim flink-conf.yaml taskmanager.host: s2 [gaochuchu@s3 conf]$ vim flink-conf.yaml taskmanager.host: s3 [gaochuchu@s4 conf]$ vim flink-conf.yaml taskmanager.host: s4 [gaochuchu@gracal conf]$ vim flink-conf.yaml taskmanager.host: gracal -
启动和停止集群
[gaochuchu@s1 flink-1.17.0]$ bin/start-cluster.sh [gaochuchu@s1 flink-1.17.0]$ bin/stop-cluster.sh发现所有节点的TaskManager都没启动起来查看日志发现问题
at org.apache.flink.runtime.taskexecutor.TaskManagerRunner.main(TaskManagerRunner.java:468) [flink-dist-1.17.0.jar:1.17.0] Caused by: org.apache.flink.util.ConfigurationException: Config parameter 'Key: 'jobmanager.rpc.address' , default: null (fallback keys: [])' is missing (hostname/address of JobManager to connect to). at org.apache.flink.runtime.highavailability.HighAvailabilityServicesUtils.getJobManagerAddress(HighAvailabilityServicesUtils.java:192) ~[flink-dist-1.17.0.jar:1.17.0] at org.apache.flink.runtime.highavailability.HighAvailabilityServicesUtils.createHighAvailabilityServices(HighAvailabilityServicesUtils.java:114) ~[flink-dist-1.17.0.jar:1.17.0] at org.apache.flink.runtime.taskexecutor.TaskManagerRunner.startTaskManagerRunnerServices(TaskManagerRunner.java:195) ~[flink-dist-1.17.0.jar:1.17.0] at org.apache.flink.runtime.taskexecutor.TaskManagerRunner.start(TaskManagerRunner.java:293) ~[flink-dist-1.17.0.jar:1.17.0] at org.apache.flink.runtime.taskexecutor.TaskManagerRunner.runTaskManager(TaskManagerRunner.java:486) ~[flink-dist-1.17.0.jar:1.17.0] ... 5 more解决编写配置文件的时候的key的":"之后需要增加空格没有加
3. 访问Web UI
-
启动成功后通过http://s1:8081对flink集群和任务进行监管。
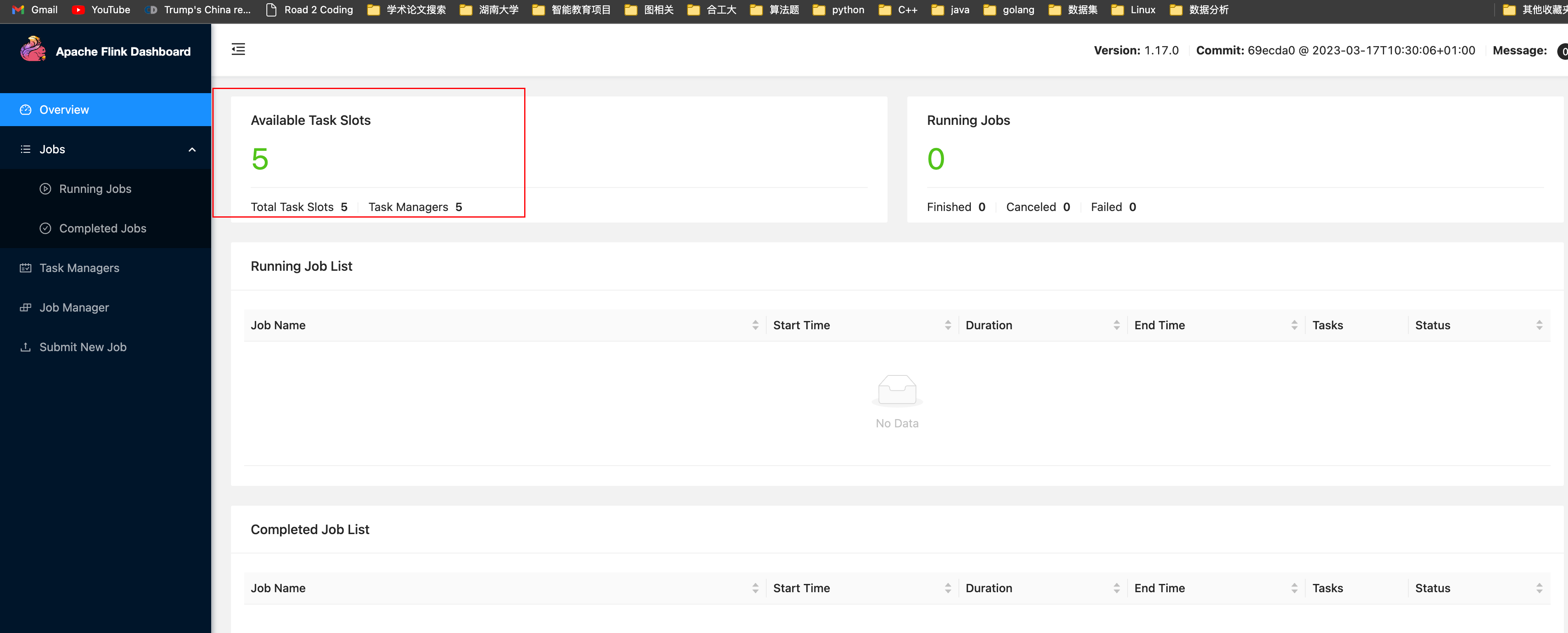
这里可以明显看到当前集群的TaskManager数量为5由于默认每个TaskManager的Slot数量为1所以总Slot数和可用Slot数都为5。
4. 提交作业方式
-
可以通过Web UI向集群提交jar包作业
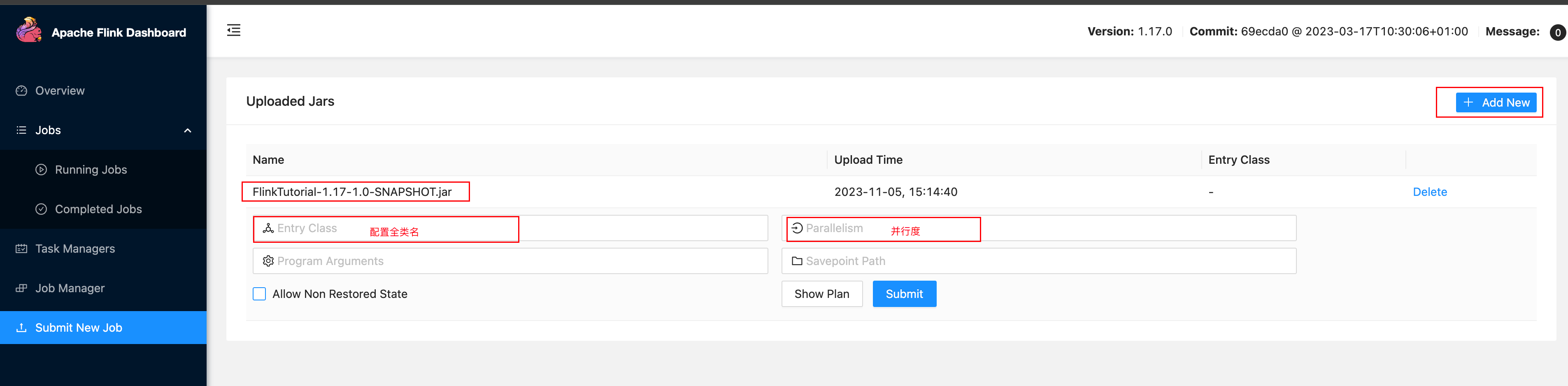
-
也可以通过命令行提交作业
首先启动集群
#s1中启动netcat [gaochuchu@s1 flink-1.17.0]$ nc -lk 7777 #在flink的安装路径下命令行使用flink run命令提交作业 bin/flink run -m s1:8081 -c com.gcc.wc.SocketStreamWordCount ./FlinkTutorial-1.0-SNAPSHOT.jar
5.Yarn部署模式配置
YARN上部署的过程是客户端把Flink应用提交给Yarn的ResourceManagerYarn的ResourceManager会向Yarn的NodeManager申请容器。在这些容器上Flink会部署JobManager和TaskManager的实例从而启动集群。Flink会根据运行在JobManger上的作业所需要的Slot数量动态分配TaskManager资源。
-
配置环境变量/etc/profile.d/my_env.sh
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop export HADOOP_CLASSPATH=`hadoop classpath` -
启动hadoop集群
-
在s1上启动netcat
[gaochuchu@s1 flink-1.17.0]$ nc -lk 7777
5.1 会话模式部署Session Mode
-
YARN的会话模式与独立集群略有不同需要首先申请一个YARN会话YARN Session来启动Flink集群。具体步骤如下
-
启动集群HDFS、Yarn
-
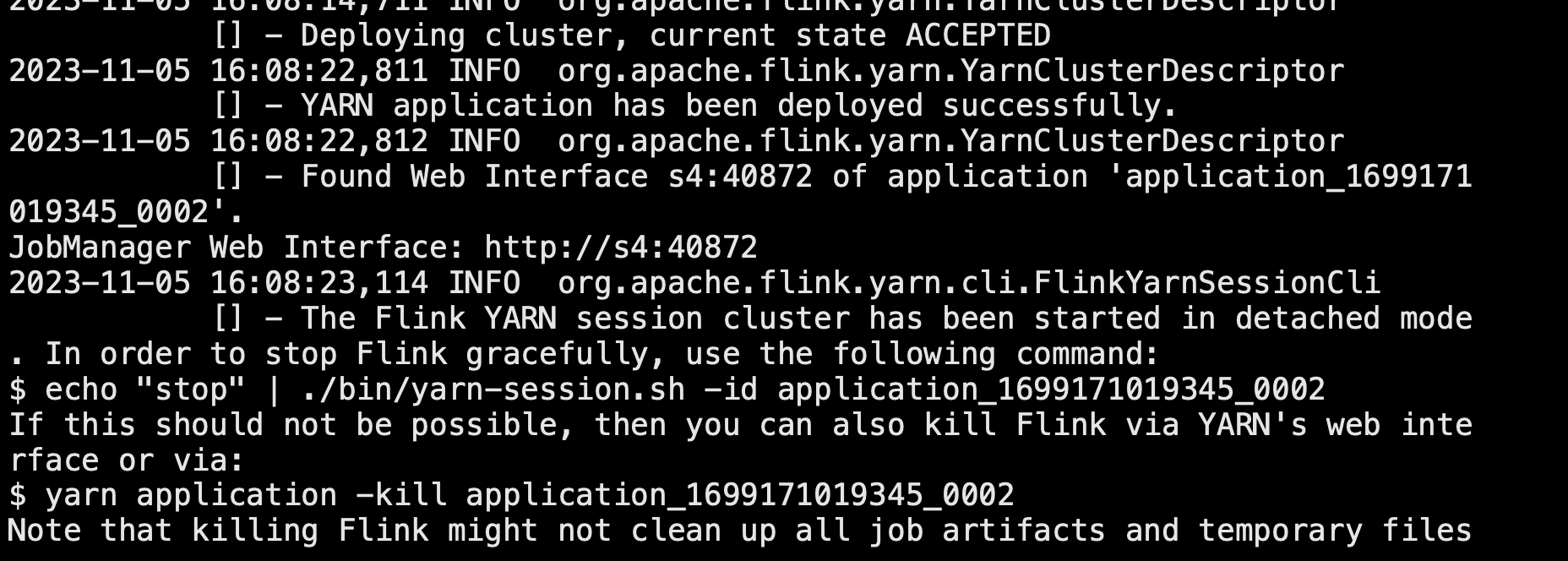
执行脚本命令向YARN集群申请资源开启一个YARN会话启动Flink集群。
bin/yarn-session.sh -nm test可用参数解读
-d分离模式如果你不想让Flink YARN客户端一直前台运行可以使用这个参数即使关掉当前对话窗口YARN session也可以后台运行。
-jm–jobManagerMemory配置JobManager所需内存默认单位MB。
-nm–name配置在YARN UI界面上显示的任务名。
-qu–queue指定YARN队列名。
-tm–taskManager配置每个TaskManager所使用内存。
注意Flink1.11.0版本不再使用-n参数和-s参数分别指定TaskManager数量和slot数量YARN会按照需求动态分配TaskManager和slot。所以从这个意义上讲YARN的会话模式也不会把集群资源固定同样是动态分配的。
-
-
会话模式作业的提交
-
1.通过如上的JobManager Web分配的Web UI提交作业即与StandLone部署模式基本相同
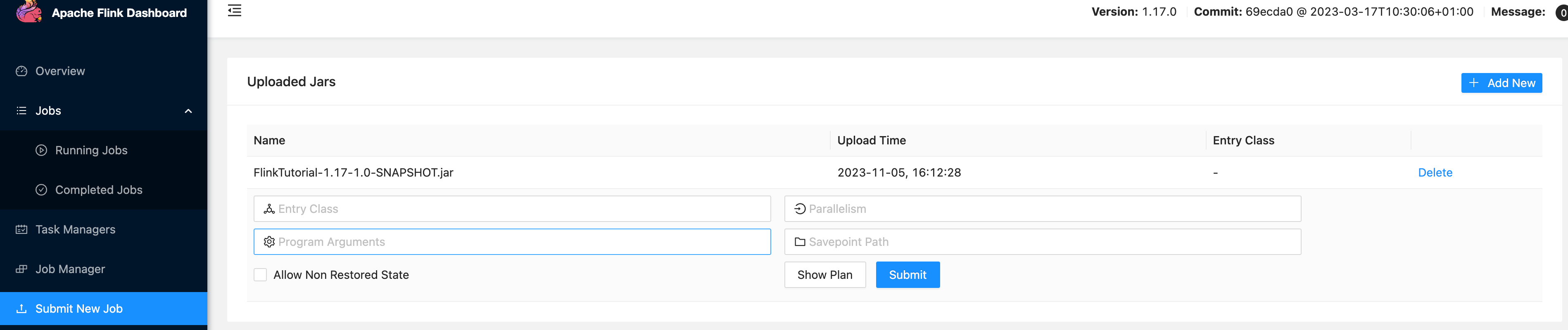
-
2.通过命令行将该任务提交到已经开启的Yarn-Session中运行
[gaochuchu@s1 flink-1.17.0]$ bin/flink run -c com.gcc.wc.SocketStreamWordCount FlinkTutorial-1.0-SNAPSHOT.jar客户端可以自行确定JobManager的地址也可以通过-m或者-jobmanager参数指定JobManager的地址JobManager的地址在YARN Session的启动页面中可以找到。如果不设置-m,默认提交任务到Yarn
-
提交任务成功可以在Yarn的Web UI页面查看任务的运行情况
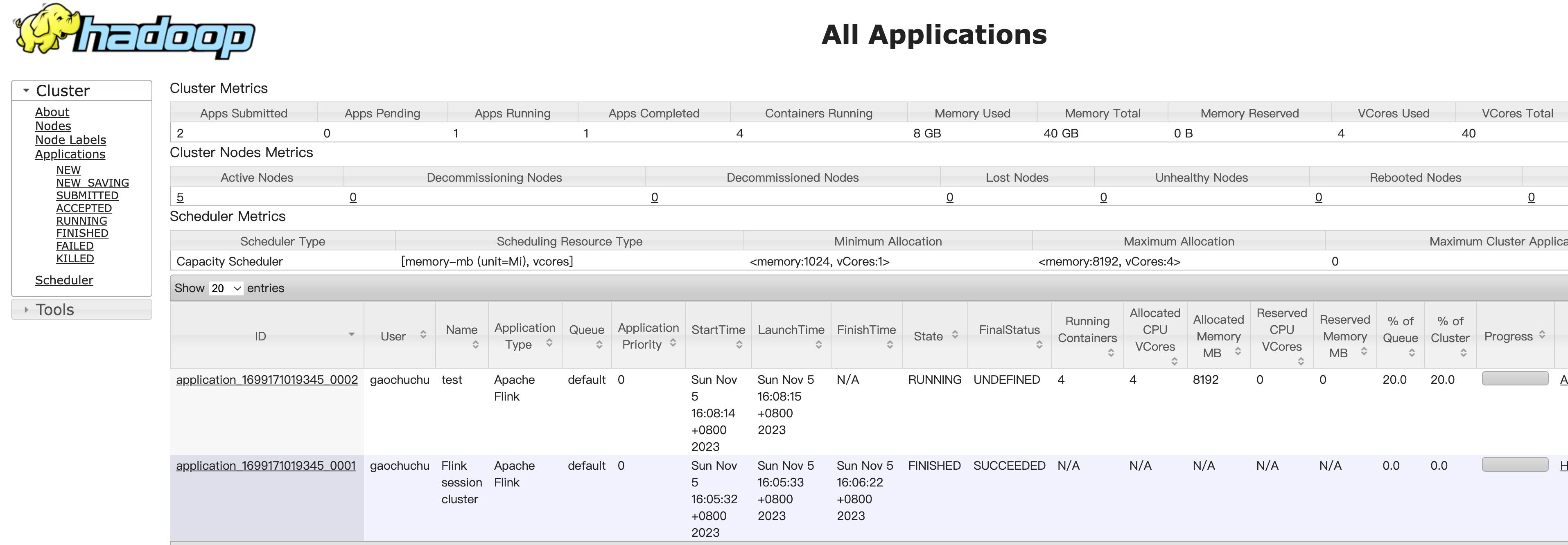
-
-
会话模式的停止
-
通过yarn的web ui上直接kill application
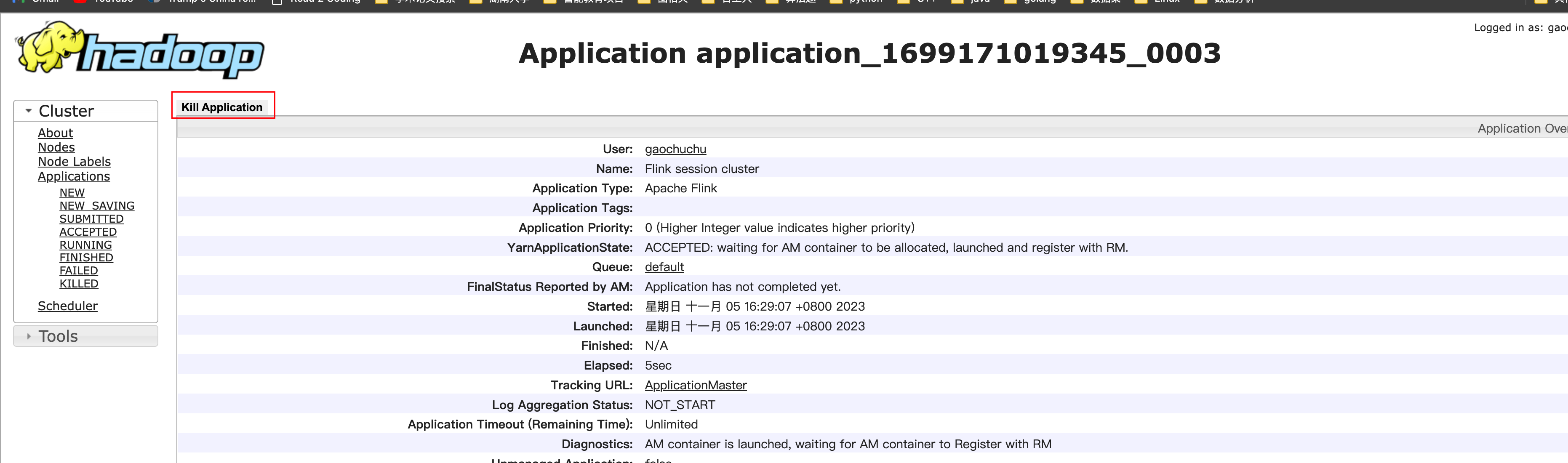
-
通过命令行关闭会话
echo "stop" | ./bin/yarn-session.sh -id application_1699171019345_0003
-
5.2 单作业模式(Per-job Mode)
-
在YARN环境中由于有了外部平台做资源调度所以我们也可以直接向YARN提交一个单独的作业从而启动一个Flink集群。
-
命令行提交 -t是单作业模式下必须的
[gaochuchu@s1 flink-1.17.0]$ bin/flink run -d -t yarn-per-job -c com.atguigu.wc.WordCountStreamUnboundedDemo lib/FlinkTutorial-1.17-1.0-SNAPSHOT.jar报错
Exception in thread "Thread-5" java.lang.IllegalStateException: Trying to access closed classloader. Please check if you store classloaders directly or indirectly in static fields. If the stacktrace suggests that the leak occurs in a third party library and cannot be fixed immediately, you can disable this check with the configuration 'classloader.check-leaked-classloader'. at org.apache.flink.util.FlinkUserCodeClassLoaders$SafetyNetWrapperClassLoader.ensureInner(FlinkUserCodeClassLoaders.java:184) at org.apache.flink.util.FlinkUserCodeClassLoaders$SafetyNetWrapperClassLoader.getResource(FlinkUserCodeClassLoaders.java:208) at org.apache.hadoop.conf.Configuration.getResource(Configuration.java:2780) at org.apache.hadoop.conf.Configuration.getStreamReader(Configuration.java:3036) at org.apache.hadoop.conf.Configuration.loadResource(Configuration.java:2995) at org.apache.hadoop.conf.Configuration.loadResources(Configuration.java:2968) at org.apache.hadoop.conf.Configuration.getProps(Configuration.java:2848) at org.apache.hadoop.conf.Configuration.get(Configuration.java:1200) at org.apache.hadoop.conf.Configuration.getTimeDuration(Configuration.java:1812) at org.apache.hadoop.conf.Configuration.getTimeDuration(Configuration.java:1789) at org.apache.hadoop.util.ShutdownHookManager.getShutdownTimeout(ShutdownHookManager.java:183) at org.apache.hadoop.util.ShutdownHookManager.shutdownExecutor(ShutdownHookManager.java:145) at org.apache.hadoop.util.ShutdownHookManager.access$300(ShutdownHookManager.java:65) at org.apache.hadoop.util.ShutdownHookManager$1.run(ShutdownHookManager.java:102)解决flink-conf.xml中添加配置
[gaochuchu@s1 flink-1.17.0]$ vim conf/flink-conf.yaml classloader.check-leaked-classloader: false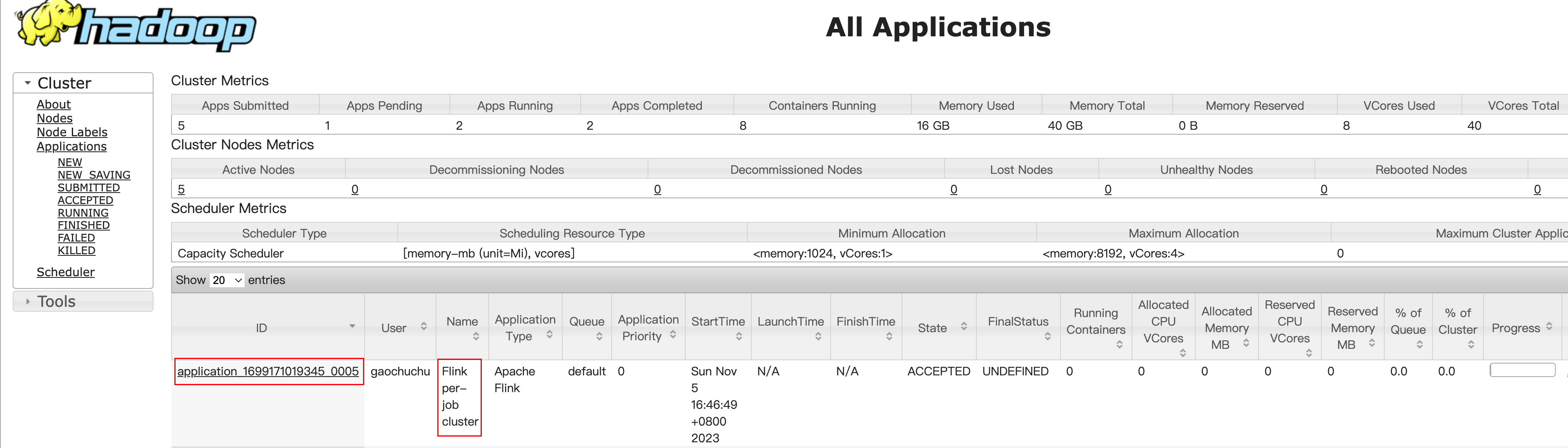
-
取消作业
-
yarn的web ui进行取消
-
flink的web ui中进行取消
-
命令行取消
#查看作业 显示jobid [gaochuchu@s1 flink-1.17.0]$ bin/flink list -t yarn-per-job -Dyarn.application.id=application_XXXX_YY #停止作业 需要应用id和jobid [gaochuchu@s1 flink-1.17.0]$ bin/flink cancel -t yarn-per-job -Dyarn.application.id=application_XXXX_YY <jobId>
-
5.3 应用模式部署推荐
应用模式与单作业模式类似直接执行flink run-applications命令即可
-
执行命令行提交作业
[gaochuchu@s1 flink-1.17.0]$ bin/flink run-application -t yarn-application -c com.atguigu.wc.WordCountStreamUnboundedDemo ./FlinkTutorial-1.17-1.0-SNAPSHOT.jar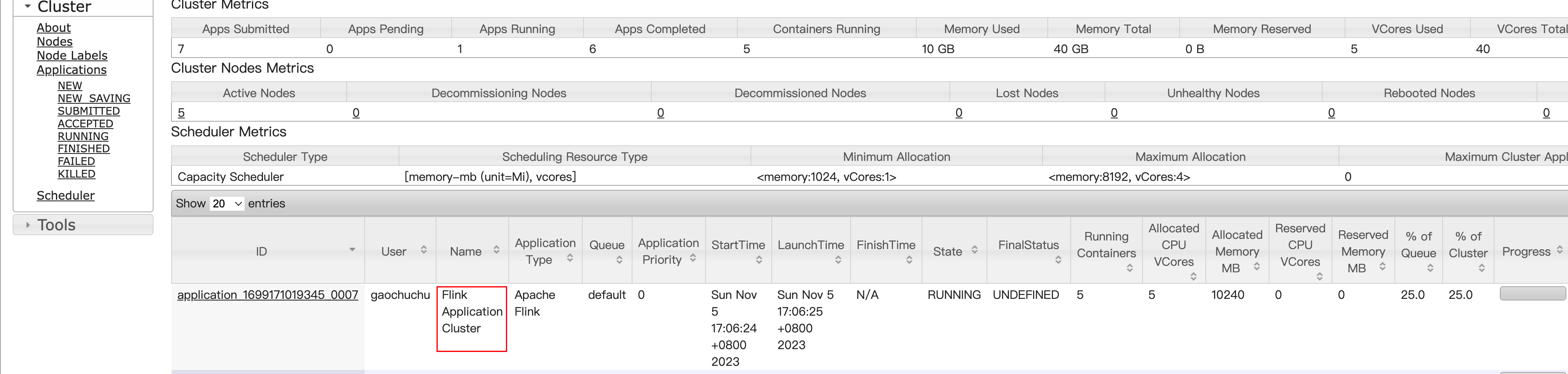
-
取消作业
-
通过flink的web ui取消作业
-
通过yarn的web ui kill applications
-
在命令行查看或者取消作业
#查看作业 [gaochuchu@s1 flink-1.17.0]$ bin/flink list -t yarn-per-job -Dyarn.application.id=application_1699171019345_0007 #取消作业 [gaochuchu@s1 flink-1.17.0]$ bin/flink cancel -t yarn-per-job -Dyarn.application.id=application_1699171019345_0007 c3aa3f94f9b2c758041a72c724aa6acf
-
5.3.1 上传HDFS提交推荐
-
yarn模式下每次都需要上传Flink自身的依赖到HDFS若是能够将Flink的依赖提前上传到HDFS或者将运行的jar包提交上传到HDFS可以对提交节点带宽不会占用过多
-
上传HDFS提交
-
上传flink的lib和plugins到HDFS上
[gaochuchu@s1 flink-1.17.0]$ hadoop fs -mkdir /flink-dist [gaochuchu@s1 flink-1.17.0]$ hadoop fs -put lib/ /flink-dist [gaochuchu@s1 flink-1.17.0]$ hadoop fs -put plugins/ /flink-dist -
将运行的jar包也上传到HDFS
[gaochuchu@s1 flink-1.17.0]$ hadoop fs -mkdir /flink-jars [gaochuchu@s1 flink-1.17.0]$ hadoop fs -put FlinkTutorial-1.17-1.0-SNAPSHOT.jar /flink-jars -
执行作业使得依赖的jar包和运行的jar包都在hdfs上
[gaochuchu@s1 flink-1.17.0]$ bin/flink run-application -t yarn-application -Dyarn.provided.lib.dirs="hdfs://s1:8020/flink-dist" -c com.atguigu.wc.WordCountStreamUnboundedDemo hdfs://s1:8020/flink-jars/FlinkTutorial-1.17-1.0-SNAPSHOT.jar
-
-
5.4 历史服务器
-
运行 Flink job 的集群一旦停止只能去 yarn 或本地磁盘上查看日志不再可以查看作业挂掉之前的运行的 Web UI很难清楚知道作业在挂的那一刻到底发生了什么。如果我们还没有 Metrics 监控的话那么完全就只能通过日志去分析和定位问题了所以如果能还原之前的 Web UI我们可以通过 UI 发现和定位一些问题。
Flink提供了历史服务器用来在相应的 Flink 集群关闭后查询已完成作业的统计信息。我们都知道只有当作业处于运行中的状态才能够查看到相关的WebUI统计信息。通过 History Server 我们才能查询这些已完成作业的统计信息无论是正常退出还是异常退出。
此外它对外提供了 REST API它接受 HTTP 请求并使用 JSON 数据进行响应。Flink 任务停止后JobManager 会将已经完成任务的统计信息进行存档History Server 进程则在任务停止后可以对任务统计信息进行查询。比如最后一次的 Checkpoint、任务运行时的相关配置。
-
创建目录
[gaochuchu@s1 flink-1.17.0]$ hadoop fs -mkdir -p /logs/flink-job -
修改flink的配置文件
[gaochuchu@s1 flink-1.17.0]$ vim conf/flink-conf.yaml jobmanager.archive.fs.dir: hdfs://s1:8020/logs/flink-job historyserver.web.address: s1 historyserver.web.port: 8082 historyserver.archive.fs.dir: hdfs://s1:8020/logs/flink-job historyserver.archive.fs.refresh-interval: 5000 -
启动flink的历史服务器
[gaochuchu@s1 flink-1.17.0]$ bin/historyserver.sh start -
停止历史服务器
[gaochuchu@s1 flink-1.17.0]$ bin/historyserver.sh stop
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |