

HBase基于HDFS上是如何完成增删改查功能的
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
HDFS只支持文件append操作, 而依赖HDFS的HBase如何完成增删改查功能
1.如何理解?
-
1.这句话有个更专业的说法
HDFS 采用数据流方式来访问文件只支持单个客户端向一个文件追加数据. -
2 上半句话访问文件不外乎读和写需要读写时调用函数
FileSystem&open()和FileSystem&create()返回的对象是FSDataInputStream和FSDataOutputStream。 data直译成中文就是数据stream直译成中文就是流。 这两个对象分别继承于java.io.DataInputStream和java.io.DataOutputStream 是java的常用的文件读写类。 需要读时用DataInputStream的函数readInt(), readFloat()…写时也差不多。 -
3 下半句话两个关键词
”单个客户“和”追加“。单个客户指不能有两个线程同时写追加指写的形式只能是在文件后加内容(append)不能覆盖(overwrite)。 这两个限制都是设计上简化考虑。多个线程同时append时由于hdfs是一份文件存于多个机器保证在每台机器上两个线程写的顺序一致(从而结果一致)是一个很难的问题当然不是做不到出于简单考虑 就不这么做了。 多个线程同时overwrite就更麻烦。
2.HDFS的文件append功能
-
1 早期版本的HDFS不支持任何的文件更新操作一旦一个文件创建、写完数据、并关闭之后这个文件就再也不能被改变了。为什么这么设计是为了与MapReduce完美配合MapReduce的工作模式是接受一系列输入文件经过map和reduce处理直接产生一系列输出文件而不是在原来的输入文件上做原位更新。为什么这么做因为直接输出新文件比原位更新一个旧文件高效的多。
-
2 在HDFS上一个文件一直到它的
close方法成功执行之后才会存在才能被其他的client端所看见。如果某个client端在写文件时或者在close文件时失败了那么这个文件就不会存在就好像这个文件从来没写过唯一恢复这个文件的方法就是从头到尾重新再写一遍。 -
3 Hadoop1.x版本一直都不支持文件的append功能
一直到Hadoop 2.x版本append 功能才被添加到Hadoop Core中允许向HDFS文件中追加写数据。为此HDFS Core 也作出了一些重大的改变以支持这一操作。append功能添加到HDFS经历了一番曲折和一段很长的时间具体可以参考http://blog.cloudera.com/blog/2009/07/file-appends-in-hdfs/和 https://issues.apache.org/jira/browse/HADOOP-8230)
2.HBase 如何完成数据更新和删除操作
HBase依赖于HDFS来存储数据(具体如下图)。HBase作为数据库必须提供对HBase表中数据的增删改查而HDFS的文件只支持append操作、不支持删除和更新操作那么HBase如何依赖HDFS完成更新以及删除操作呢
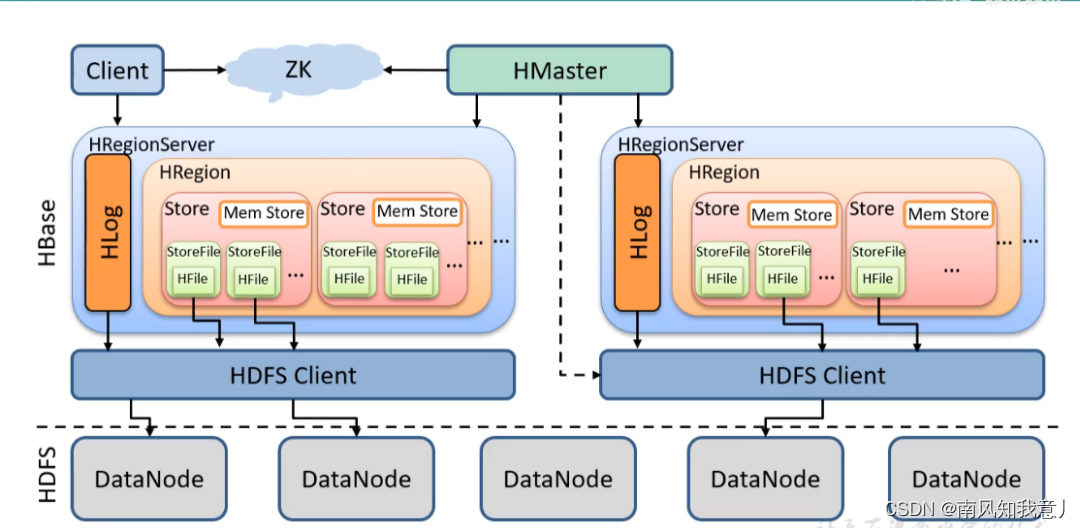
-
2.1 更新操作
HBase表中的数据当存放到HDFS中时在HDFS看来已经可以简单的理解成key-value对其中key可以理解成是由rowkey + column family + column qualifier + timestamp + type 组成。HBase 对新增的数据以及要更新的数据理解成key-value对都直接先写入MemStore结构中MemStore是完全的内存结构且是key有序的。当MemStore达到一定大小后该MemStore一次性从内存flush到HDFS中磁盘中生成一个HFile文件HFile文件同样是key有序的并且是持久化的位于HDFS系统中的。通过这种机制HBase对表的所有的插入和更新都转换成对HDFS的HFile文件的创建。你可能会迅速的想到那查询怎么办是的这种方式解决了插入和更新的问题而查询就变得相对麻烦。而这也正是HBase设计之初的想法以查询性能的下降来换取更新性能的提升。
事实上查询是按照如下来完成的。每当MemStore结构flush到HDFS上时就会产生一个新的HFile文件随着时间的推移会产生一连串的HFile文件这些HFile文件产生的先后顺序非常的重要可以想象成他们按创建时间排成一个队列
最近产生的在最前面较早产生的在最后面。当HBase执行查询操作时可以理解为给出key要找到value首先查询内存中的MemStroe结构如果命中就返回结果因为MemStore中的数据永远是最新的如果不命中就从前到后遍历之前产生的HFile文件队列在每个HFile文件中查找key看是否命中如果命中即可返回最新的数据排在最前面如果不命中一直查找下去直到所有HFile文件被搜索完结束。由此可见
查询操作最坏情况下可能要遍历所有HFile文件最好情况下在内存中MemStore即可命中这也是为什么HBase查询性能波动大的原因。当然HBase也不会真的很傻的去遍历每个HFile文件中的内容这个性能是无法忍受的它采取了一些优化的措施1、引入bloomfilter对HFile中的key进行hash当查询时对查询key先过bloomfilter看查询key是否可能在该HFile中如果可能在则进入第2步不在则直接跳过该HFile
2、还记得吗HFile是key有序的具体实现是类SSTable结构在有序的key上查找就有各种优化技术了而不是单纯的遍历了。通过以上机制
HBase很好的解决了插入和更新、以及查找的问题但是问题还没有结束。细心的朋友很可能已经看出来上述过程中HFile文件一直在产生HFile文件组成的列表一直在增大而计算机资源是有限的并且查询的性能也依赖HFile队列的长度因此我们还需要一种合并HFile文件的机制以保持适度的HFile文件个数。HBase中实现这种机制采用的是LSM树一种NOSQL系统广泛使用的结构LSM能够将多个内部key有序的小HFile文件合并生成一个大的HFile文件当新的大的HFile文件生成后HBase就能够删除原有的一系列旧的小的HFile文件从而保持HFile队列不至于过长查询操作也不至于查询过多的HFile文件。在LSM合并HFile的时候HBase还会做很重要的两件事1、将更新过的数据的旧版本的数据删除掉只留下最新的版本
2、将标有删除标记下面一节会讲到的数据删除掉。 -
2.2 删除操作
有了以上机制HBase完成删除操作非常的简单对将要删除的key-value对进行打标通常是对key进行打标将key中的type字段打标成“删除”标记并将打标后的数据append到MemStore中MemStore再flush到HFile中HFile合并时检查这个标记所有带有“删除”标记的记录将被删除而不会合并到新的HFile中这样HBase就完成了数据的删除操作。
3. HBase 的WAL
HBase的WALWrite-Ahead-Log机制是必须的一个RegionServer通常与一个HLog一一对应数据写入Region之前先写HLog能够保障数据的安全。 HLog使用Hadoop的SequenceFile存储日志而HLog是一直连续不断追加写文件的它强烈依赖SequenceFile的append功能。事实上正是HLog对append功能的强烈需求或多或少推动了HDFS在最近的版本中添加了文件追加功能。