

机器学习算法案例:泰坦尼克号乘客生存预测
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
学习目标
- 通过案例进一步掌握决策树算法api的具体使用
1 案例背景
泰坦尼克号沉没是历史上最臭名昭着的沉船之一。1912年4月15日,在她的处女航中,泰坦尼克号在与冰山相撞后沉没,在2224名乘客和机组人员中造成1502人死亡。这场耸人听闻的悲剧震惊了国际社会,并为船舶制定了更好的安全规定。 造成海难失事的原因之一是乘客和机组人员没有足够的救生艇。尽管幸存下沉有一些运气因素,但有些人比其他人更容易生存,例如妇女,儿童和上流社会。 在这个案例中,我们要求您完成对哪些人可能存活的分析。特别是,我们要求您运用机器学习工具来预测哪些乘客幸免于悲剧。
案例:https://www.kaggle.com/c/titanic/overview
我们提取到的数据集中的特征包括票的类别,是否存活,乘坐班次,年龄,登陆home.dest,房间,船和性别等。
数据:http://biostat.mc.vanderbilt.edu/wiki/pub/Main/DataSets/titanic.txt

经过观察数据得到:
- 1 乘坐班是指乘客班(1,2,3),是社会经济阶层的代表。
- 2 其中age数据存在缺失。
2 步骤分析
- 1.获取数据
- 2.数据基本处理
- 2.1 确定特征值,目标值
- 2.2 缺失值处理
- 2.3 数据集划分
- 3.特征工程(字典特征抽取)
- 4.机器学习(决策树)
- 5.模型评估
3 代码实现
- 导入需要的模块
- 1.获取数据
- 2.数据基本处理
- 2.1 确定特征值,目标值
- 2.2 缺失值处理
- 2.3 数据集划分
- 3.特征工程(字典特征抽取)
特征中出现类别符号,需要进行one-hot编码处理(DictVectorizer)
x.to_dict(orient="records") 需要将数组特征转换成字典数据
- 4.决策树模型训练和模型评估
决策树API当中,如果没有指定max_depth那么会根据信息熵的条件直到最终结束。这里我们可以指定树的深度来进行限制树的大小
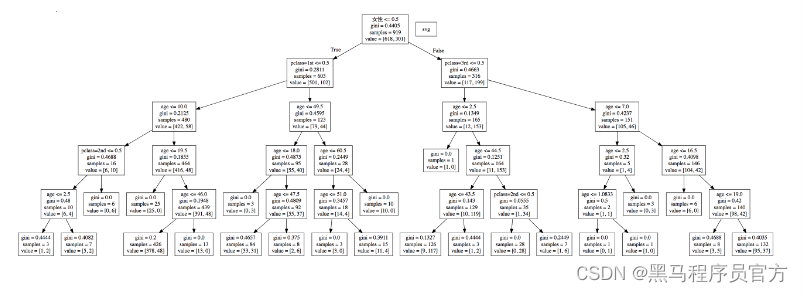
决策树的结构是可以直接显示
4 决策树可视化
4.1 保存树的结构到dot文件
- sklearn.tree.export_graphviz() 该函数能够导出DOT格式
- tree.export_graphviz(estimator,out_file='tree.dot’,feature_names=[‘’,’’])
dot文件当中的内容如下
那么这个结构不能看清结构,所以可以在一个网站上显示
4.2 网站显示结构

将dot文件内容复制到该网站当中显示:
5 决策树总结
- 优点:
- 简单的理解和解释,树木可视化。
- 缺点:
- 决策树学习者可以创建不能很好地推广数据的过于复杂的树,容易发生过拟合。
- 改进:
- 减枝cart算法
- 随机森林(集成学习的一种)
注:企业重要决策,由于决策树很好的分析能力,在决策过程应用较多, 可以选择特征
6 小结
- 案例流程分析【了解】
- 1.获取数据
- 2.数据基本处理
- 2.1 确定特征值,目标值
- 2.2 缺失值处理
- 2.3 数据集划分
- 3.特征工程(字典特征抽取)
- 4.机器学习(决策树)
- 5.模型评估
- 决策树可视化【了解】
- sklearn.tree.export_graphviz()
- 决策树优缺点总结【知道】
- 优点:
- 简单的理解和解释,树木可视化。
- 缺点:
- 决策树学习者可以创建不能很好地推广数据的过于复杂的树,容易发生过拟合。
- 改进:
- 减枝cart算法
- 随机森林(集成学习的一种)
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |