

机器学习算法:特征工程-特征提取
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
学习目标
- 了解什么是特征提取
- 知道字典特征提取操作流程
- 知道文本特征提取操作流程
- 知道tfidf的实现思想
什么是特征提取呢?


1 特征提取
1.1 定义
将任意数据(如文本或图像)转换为可用于机器学习的数字特征
注:特征值化是为了计算机更好的去理解数据
- 特征提取分类:
- 字典特征提取(特征离散化)
- 文本特征提取
- 图像特征提取(深度学习将介绍)
1.2 特征提取API
2 字典特征提取
作用:对字典数据进行特征值化
- sklearn.feature_extraction.DictVectorizer(sparse=True,…)
- DictVectorizer.fit_transform(X)
- X:字典或者包含字典的迭代器返回值
- 返回sparse矩阵
- DictVectorizer.get_feature_names() 返回类别名称
2.1 应用
我们对以下数据进行特征提取

2.2 流程分析
- 实例化类DictVectorizer
- 调用fit_transform方法输入数据并转换(注意返回格式)
注意观察没有加上sparse=False参数的结果
这个结果并不是我们想要看到的,所以加上参数,得到想要的结果:
之前在学习pandas中的离散化的时候,也实现了类似的效果。
我们把这个处理数据的技巧叫做”one-hot“编码:
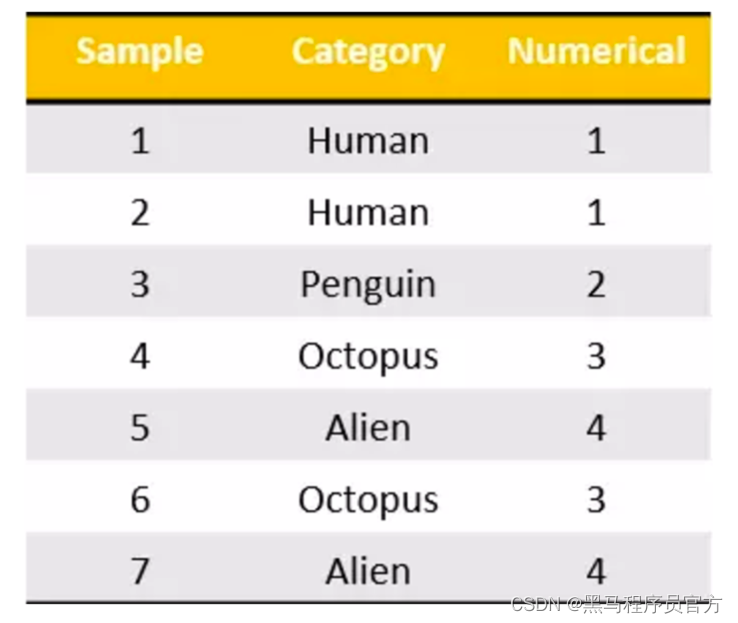
转化为:
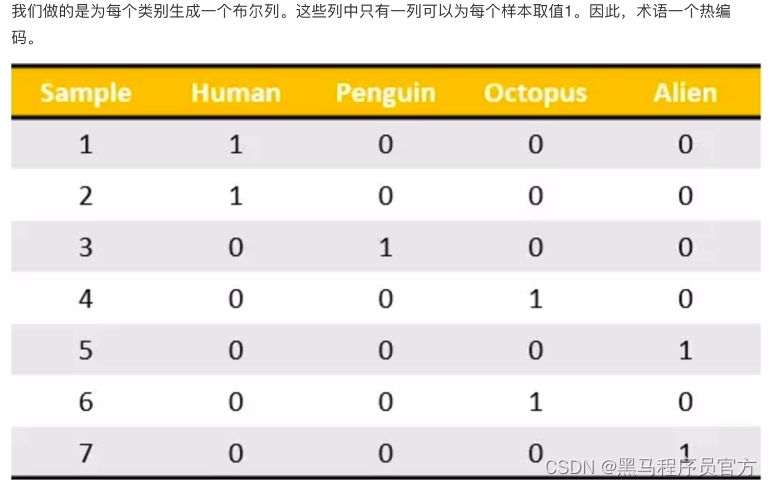
2.3 总结
对于特征当中存在类别信息的我们都会做one-hot编码处理
3 文本特征提取
作用:对文本数据进行特征值化
- sklearn.feature_extraction.text.CountVectorizer(stop_words=[])
- 返回词频矩阵
- CountVectorizer.fit_transform(X)
- X:文本或者包含文本字符串的可迭代对象
- 返回值:返回sparse矩阵
- CountVectorizer.get_feature_names() 返回值:单词列表
- sklearn.feature_extraction.text.TfidfVectorizer
3.1 应用
我们对以下数据进行特征提取

3.2 流程分析
- 实例化类CountVectorizer
- 调用fit_transform方法输入数据并转换 (注意返回格式,利用toarray()进行sparse矩阵转换array数组)
返回结果:
问题:如果我们将数据替换成中文?
那么最终得到的结果是
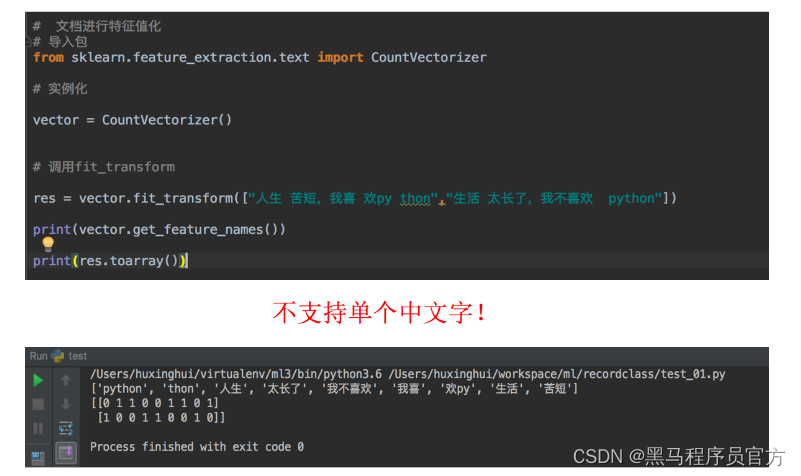
为什么会得到这样的结果呢,仔细分析之后会发现英文默认是以空格分开的。其实就达到了一个分词的效果,所以我们要对中文进行分词处理
3.3 jieba分词处理
- jieba.cut()
- 返回词语组成的生成器
需要安装下jieba库
3.4 案例分析
对以下三句话进行特征值化
- 分析
- 准备句子,利用jieba.cut进行分词
- 实例化CountVectorizer
- 将分词结果变成字符串当作fit_transform的输入值

返回结果:
但如果把这样的词语特征用于分类,会出现什么问题?
请看问题:
该如何处理某个词或短语在多篇文章中出现的次数高这种情况
3.5 Tf-idf文本特征提取
- TF-IDF的主要思想是:如果某个词或短语在一篇文章中出现的概率高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。
- TF-IDF作用:用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。
3.5.1 公式
- 词频(term frequency,tf)指的是某一个给定的词语在该文件中出现的频率
- 逆向文档频率(inverse document frequency,idf)是一个词语普遍重要性的度量。某一特定词语的idf,可以由总文件数目除以包含该词语之文件的数目,再将得到的商取以10为底的对数得到
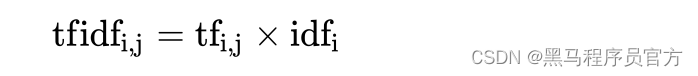
最终得出结果可以理解为重要程度。
3.5.2 案例
返回结果:
3.6 Tf-idf的重要性
分类机器学习算法进行文章分类中前期数据处理方式
4 小结
- 特征提取【了解】
- 将任意数据(如文本或图像)转换为可用于机器学习的数字特征
- 特征提取分类:【了解】
- 字典特征提取(特征离散化)
- 文本特征提取
- 图像特征提取
- 字典特征提取【知道】
- 字典特征提取就是对类别型数据进行转换
- api:sklearn.feature_extraction.DictVectorizer(sparse=True,…)
- aparse矩阵
- 1.节省内容
- 2.提高读取效率
- 注意:
- 对于特征当中存在类别信息的我们都会做one-hot编码处理
- 文本特征提取(英文)【知道】
- api:sklearn.feature_extraction.text.CountVectorizer(stop_words=[])
- stop_words -- 停用词
- 注意:没有sparse这个参数
- 单个字母,标点符号不做统计
- 文本特征提取(中文)【知道】
- 注意:
- 1.在中文文本特征提取之前,需要对句子(文章)进行分词(jieba)
- 2.里面依旧可以使用停用词,进行词语的限制
- tfidf【知道】
- 主要思想:
- 如果某个词或短语在一篇文章中出现的概率高,并且在其他文章中很少出现,则认为此词或者短语具有很好的
- 类别区分能力,适合用来分类
- tfidf
- tf -- 词频
- idf -- 逆向文档频率
- api:sklearn.feature_extraction.text.TfidfVectorizer
- 注意:
- 分类机器学习算法进行文章分类中前期数据处理方式
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |