

Hive的Rank排名(rank函数,dense
阿里云国际版折扣https://www.yundadi.com |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
一、区别
三者通常都会配合窗口函数over()并结合partition by order by xxx来分组排序即形式使用function_name over(partition by xxx order by xxx)。首先三者都是产生一个自增序列不同的是
row_number() 排序的字段值相同时序列号不会重复如1、2、(2)3、4、5出现两个2第二个2继续编号3
rank() 排序的字段值相同时序列号会重复且下一个序列号跳过重复位如1、2、2、4、5出现两个2跳过序号3继续编号4
dense_rank() 排序的字段值相同时序列号会重复且下一个序列号继续序号自增如1、2、2、3、4出现两个2继续按照3编号
二、举例介绍
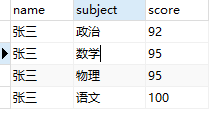
有如下学生成绩表student_score假设只有一个学生多门课程
统计每个学生各科成绩由高到低排序语句如下
SELECT
row_number() over(partition by name order by score DESC) AS row_number,
rank() over(partition by name order by score DESC) AS rank,
dense_rank() over(partition by name order by score DESC) AS dense_rank,
name,
subject,
score
FROM统计结果如下图所示
从上图结果可以看出区别
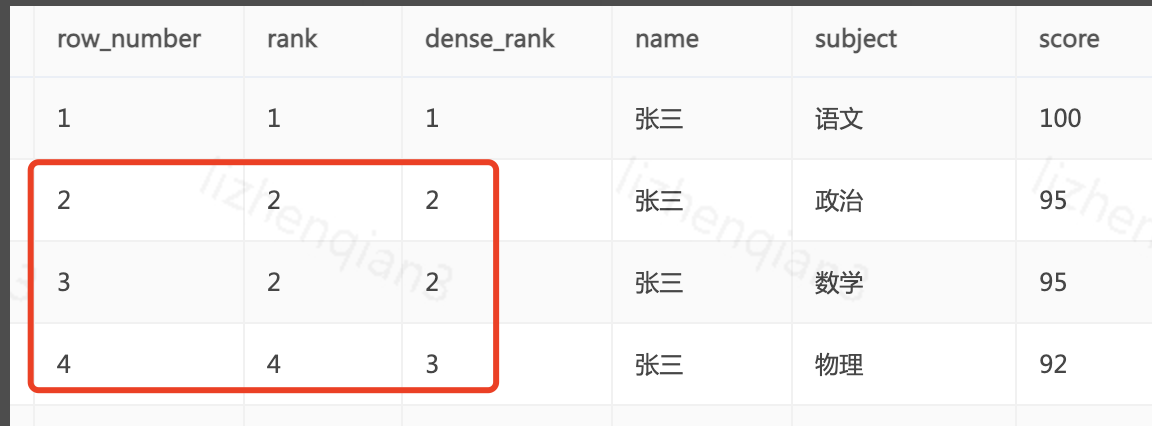
row_number 排序字段值相同时序号不同下一个序号顺序自增
rank 排序字段值相同时序号相同下一个序号跳跃自增
dense_rank 排序字段值相同时序号相同下一个序号顺序自增