

Spring Cloud Gateway 之限流
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
文章目录
话说在 Spring Cloud Gateway 问世之前Spring Cloud 的微服务世界里网关一定非 Netflix Zuul 莫属。但是由于 Zuul 1.x 存在的一些问题比如阻塞式的 API不支持 WebSocket 等一直被人所诟病而且 Zuul 升级新版本依赖于 Netflix 公司经过几次跳票之后Spring 开源社区决定推出自己的网关组件替代 Netflix Zuul。
从 18 年 6 月 Spring Cloud 发布的 Finchley 版本开始Spring Cloud Gateway 逐渐崭露头角它基于 Spring 5.0、Spring Boot 2.0 和 Project Reactor 等技术开发不仅支持响应式和无阻塞式的 API而且支持 WebSocket和 Spring 框架紧密集成。尽管 Zuul 后来也推出了 2.x 版本在底层使用了异步无阻塞式的 API大大改善了其性能但是目前看来 Spring 并没有打算继续集成它的计划。
根据官网的描述Spring Cloud Gateway 的主要特性如下
- Built on Spring Framework 5, Project Reactor and Spring Boot 2.0
- Able to match routes on any request attribute (能够匹配任何请求属性的路由)
- Predicates and filters are specific to routes (谓词和过滤器是针对路由的)
- Hystrix Circuit Breaker integration (Hystrix断路器集成)
- Spring Cloud DiscoveryClient integration (Spring Cloud DiscoveryClient集成)
- Easy to write Predicates and Filters (易于编写谓词和过滤器)
- Request Rate Limiting (请求速率限制)
- Path Rewriting (路径重写)
可以看出 Spring Cloud Gateway 可以很方便的和 Spring Cloud 生态中的其他组件进行集成比如断路器和服务发现而且提供了一套简单易写的 断言Predicates有的地方也翻译成 谓词和 过滤器Filters机制可以对每个 路由Routes进行特殊请求处理。
最近在项目中使用了 Spring Cloud Gateway并在它的基础上实现了一些高级特性如限流和留痕在网关的使用过程中遇到了不少的挑战于是趁着项目结束抽点时间系统地学习并总结下。这篇文章主要学习限流技术首先我会介绍一些常见的限流场景和限流算法然后介绍一些关于限流的开源项目学习别人是如何实现限流的最后介绍我是如何在网关中实现限流的并分享一些实现过程中的经验和遇到的坑。
一、常见的限流场景
缓存、降级 和 限流 被称为高并发、分布式系统的三驾马车网关作为整个分布式系统中的第一道关卡限流功能自然必不可少。通过限流可以控制服务请求的速率从而提高系统应对突发大流量的能力让系统更具弹性。限流有着很多实际的应用场景比如双十一的秒杀活动 12306 的抢票等。
1.1 限流的对象
通过上面的介绍我们对限流的概念可能感觉还是比较模糊到底限流限的是什么顾名思义限流就是限制流量但这里的流量是一个比较笼统的概念。如果考虑各种不同的场景限流是非常复杂的而且和具体的业务规则密切相关可以考虑如下几种常见的场景
- 限制某个接口一分钟内最多请求 100 次
- 限制某个用户的下载速度最多 100KB/S
- 限制某个用户同时只能对某个接口发起 5 路请求
- 限制某个 IP 来源禁止访问任何请求
从上面的例子可以看出根据不同的请求者和请求资源可以组合出不同的限流规则。可以根据请求者的 IP 来进行限流或者根据请求对应的用户来限流又或者根据某个特定的请求参数来限流。而限流的对象可以是请求的频率传输的速率或者并发量等其中最常见的两个限流对象是请求频率和并发量他们对应的限流被称为 请求频率限流Request rate limiting和 并发量限流Concurrent requests limiting。传输速率限流 在下载场景下比较常用比如一些资源下载站会限制普通用户的下载速度只有购买会员才能提速这种限流的做法实际上和请求频率限流类似只不过一个限制的是请求量的多少一个限制的是请求数据报文的大小。这篇文章主要介绍请求频率限流和并发量限流。
1.2 限流的处理方式
在系统中设计限流方案时有一个问题值得设计者去仔细考虑当请求者被限流规则拦截之后我们该如何返回结果。一般我们有下面三种限流的处理方式
- 拒绝服务
- 排队等待
- 服务降级
最简单的做法是拒绝服务直接抛出异常返回错误信息比如返回 HTTP 状态码 429 Too Many Requests或者给前端返回 302 重定向到一个错误页面提示用户资源没有了或稍后再试。但是对于一些比较重要的接口不能直接拒绝比如秒杀、下单等接口我们既不希望用户请求太快也不希望请求失败这种情况一般会将请求放到一个消息队列中排队等待消息队列可以起到削峰和限流的作用。第三种处理方式是服务降级当触发限流条件时直接返回兜底数据比如查询商品库存的接口可以默认返回有货。
1.3 限流的架构
针对不同的系统架构需要使用不同的限流方案。如下图所示服务部署的方式一般可以分为单机模式和集群模式
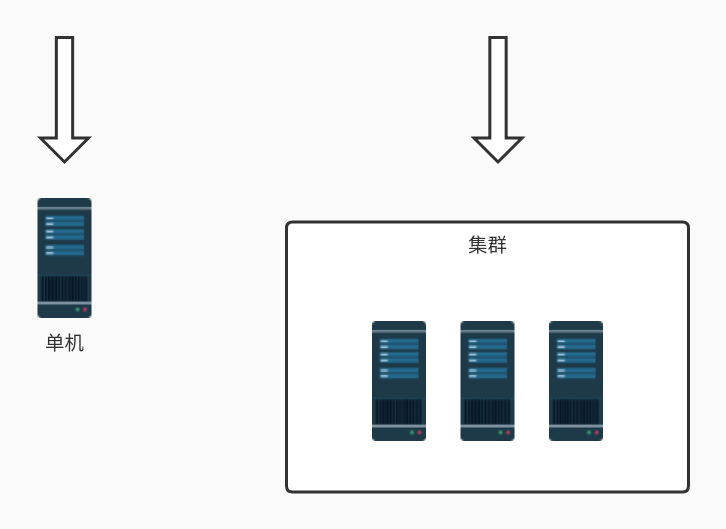 单机模式的限流非常简单可以直接基于内存就可以实现而集群模式的限流必须依赖于某个“中心化”的组件比如网关或 Redis从而引出两种不同的限流架构网关层限流 和 中间件限流。
单机模式的限流非常简单可以直接基于内存就可以实现而集群模式的限流必须依赖于某个“中心化”的组件比如网关或 Redis从而引出两种不同的限流架构网关层限流 和 中间件限流。
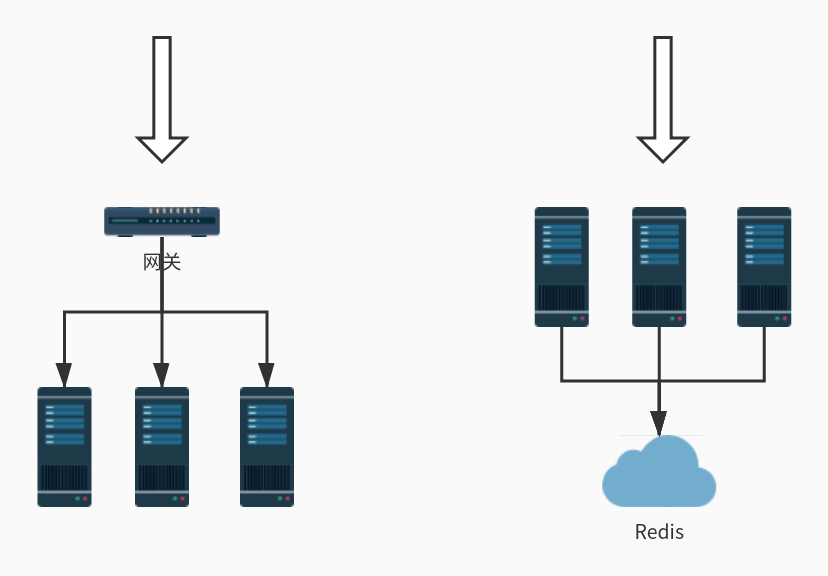
网关作为整个分布式系统的入口承担了所有的用户请求所以在网关中进行限流是最合适不过的。网关层限流有时也被称为 接入层限流。除了我们使用的 Spring Cloud Gateway最常用的网关层组件还有 Nginx可以通过它的 ngx_http_limit_req_module 模块使用 limit_conn_zone、limit_req_zone、limit_rate 等指令很容易的实现并发量限流、请求频率限流和传输速率限流。这里不对 Nginx 作过多的说明关于这几个指令的详细信息可以 参考 Nginx 的官方文档。
另一种限流架构是中间件限流可以将限流的逻辑下沉到服务层。但是集群中的每个服务必须将自己的流量信息统一汇总到某个地方供其他服务读取一般来说用 Redis 的比较多Redis 提供的过期特性和 lua 脚本执行非常适合做限流。除了 Redis 这种中间件还有很多类似的分布式缓存系统都可以使用如 Hazelcast、Apache Ignite、Infinispan 等。
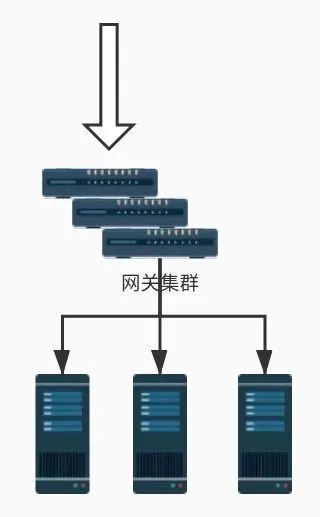
我们可以更进一步扩展上面的架构将网关改为集群模式虽然这还是网关层限流架构但是由于网关变成了集群模式所以网关必须依赖于中间件进行限流这和上面讨论的中间件限流没有区别。
二、常见的限流算法
通过上面的学习我们知道限流可以分为请求频率限流和并发量限流根据系统架构的不同又可以分为网关层限流和分布式限流。在不同的应用场景下我们需要采用不同的限流算法。这一节将介绍一些主流的限流算法。
有一点要注意的是利用池化技术也可以达到限流的目的比如线程池或连接池但这不是本文的重点。
2.1 固定窗口算法Fixed Window
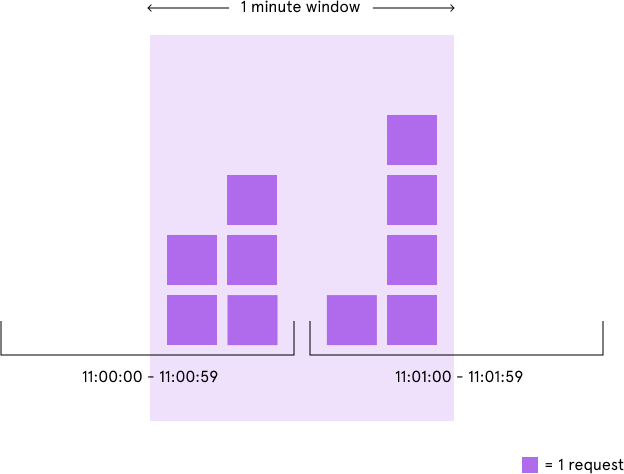
固定窗口算法是一种最简单的限流算法它根据限流的条件将请求时间映射到一个时间窗口再使用计数器累加访问次数。譬如限流条件为每分钟 5 次那么就按照分钟为单位映射时间窗口假设一个请求时间为 11:00:45时间窗口就是 11:00:00 ~ 11:00:59在这个时间窗口内设定一个计数器每来一个请求计数器加一当这个时间窗口的计数器超过 5 时就触发限流条件。当请求时间落在下一个时间窗口内时11:01:00 ~ 11:01:59上一个窗口的计数器失效当前的计数器清零重新开始计数。
计数器算法非常容易实现在单机场景下可以使用 AtomicLong、LongAdder 或 Semaphore 来实现计数而在分布式场景下可以通过 Redis 的 INCR 和 EXPIRE 等命令并结合 EVAL 或 lua 脚本来实现Redis 官网提供了几种简单的实现方式。无论是请求频率限流还是并发量限流都可以使用这个算法。
不过这个算法的缺陷也比较明显那就是存在严重的临界问题。由于每过一个时间窗口计数器就会清零这使得限流效果不够平滑恶意用户可以利用这个特点绕过我们的限流规则。如下图所示我们的限流条件本来是每分钟 5 次但是恶意用户在 11:00:00 ~ 11:00:59 这个时间窗口的后半分钟发起 5 次请求接下来又在 11:01:00 ~ 11:01:59 这个时间窗口的前半分钟发起 5 次请求这样我们的系统就在 1 分钟内承受了 10 次请求。
2.2 滑动窗口算法Rolling Window 或 Sliding Window
为了解决固定窗口算法的临界问题可以将时间窗口划分成更小的时间窗口然后随着时间的滑动删除相应的小窗口而不是直接滑过一个大窗口这就是滑动窗口算法。我们为每个小时间窗口都设置一个计数器大时间窗口的总请求次数就是每个小时间窗口的计数器的和。如下图所示我们的时间窗口是 5 秒可以按秒进行划分将其划分成 5 个小窗口时间每过一秒时间窗口就滑过一秒
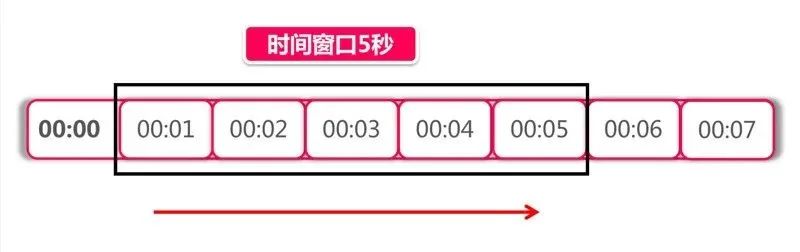
每次处理请求时都需要计算所有小时间窗口的计数器的和考虑到性能问题划分的小时间窗口不宜过多譬如限流条件是每小时 N 个可以按分钟划分为 60 个窗口而不是按秒划分成 3600 个。当然如果不考虑性能问题划分粒度越细限流效果就越平滑。相反如果划分粒度越粗限流效果就越不精确出现临界问题的可能性也就越大当划分粒度为 1 时滑动窗口算法就退化成了固定窗口算法。由于这两种算法都使用了计数器所以也被称为 计数器算法Counters。
进一步思考我们发现如果划分粒度最粗也就是只有一个时间窗口时滑动窗口算法退化成了固定窗口算法那如果我们把划分粒度调到最细又会如何呢那么怎样才能让划分的时间窗口最细呢时间窗口细到一定地步时意味着每个时间窗口中只能容纳一个请求这样我们可以省略计数器只记录每个请求的时间然后统计一段时间内的请求数有多少个即可。具体的实现可以参考Redis sorted set 技巧 和Sliding window log 算法。
2.3 漏桶算法Leaky Bucket
除了计数器算法另一个很自然的限流思路是将所有的请求缓存到一个队列中然后按某个固定的速度慢慢处理这其实就是漏桶算法Leaky Bucket。漏桶算法假设将请求装到一个桶中桶的容量为 M当桶满时请求被丢弃。在桶的底部有一个洞桶中的请求像水一样按固定的速度每秒 r 个漏出来。我们用下面这个形象的图来表示漏桶算法
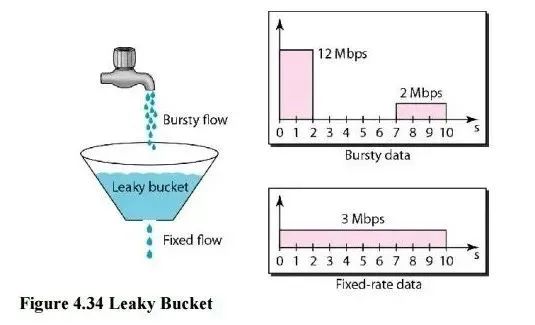
桶的上面是个水龙头我们的请求从水龙头流到桶中水龙头流出的水速不定有时快有时慢这种忽快忽慢的流量叫做 Bursty flow。如果桶中的水满了多余的水就会溢出去相当于请求被丢弃。从桶底部漏出的水速是固定不变的可以看出漏桶算法可以平滑请求的速率。
漏桶算法可以通过一个队列来实现如下图所示
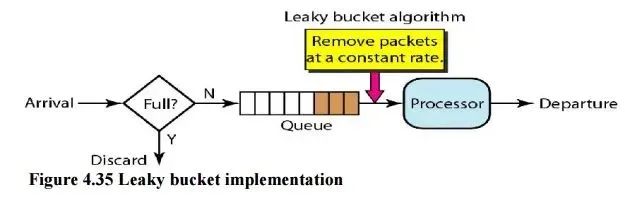
当请求到达时不直接处理请求而是将其放入一个队列然后另一个线程以固定的速率从队列中读取请求并处理从而达到限流的目的。注意的是这个队列可以有不同的实现方式比如设置请求的存活时间或将队列改造成 PriorityQueue根据请求的优先级排序而不是先进先出。当然队列也有满的时候如果队列已经满了那么请求只能被丢弃了。漏桶算法有一个缺陷在处理突发流量时效率很低于是人们又想出了下面的令牌桶算法。
2.4 令牌桶算法Token Bucket
令牌桶算法Token Bucket是目前应用最广泛的一种限流算法它的基本思想由两部分组成生成令牌 和 消费令牌。
- 生成令牌假设有一个装令牌的桶最多能装 M 个然后按某个固定的速度每秒 r 个往桶中放入令牌桶满时不再放入
- 消费令牌我们的每次请求都需要从桶中拿一个令牌才能放行当桶中没有令牌时即触发限流这时可以将请求放入一个缓冲队列中排队等待或者直接拒绝
令牌桶算法的图示如下
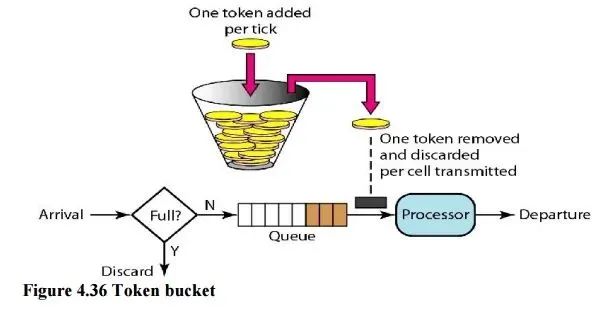
在上面的图中我们将请求放在一个缓冲队列中可以看出这一部分的逻辑和漏桶算法几乎一模一样只不过在处理请求上一个是以固定速率处理一个是从桶中获取令牌后才处理。
仔细思考就会发现令牌桶算法有一个很关键的问题就是桶大小的设置正是这个参数可以让令牌桶算法具备处理突发流量的能力。譬如将桶大小设置为 100生成令牌的速度设置为每秒 10 个那么在系统空闲一段时间的之后桶中令牌一直没有消费慢慢的会被装满突然来了 50 个请求这时系统可以直接按每秒 50 个的速度处理随着桶中的令牌很快用完处理速度又会慢慢降下来和生成令牌速度趋于一致。这是令牌桶算法和漏桶算法最大的区别漏桶算法无论来了多少请求只会一直以每秒 10 个的速度进行处理。当然处理突发流量虽然提高了系统性能但也给系统带来了一定的压力如果桶大小设置不合理突发的大流量可能会直接压垮系统。
通过上面对令牌桶的原理分析一般会有两种不同的实现方式。第一种方式是启动一个内部线程不断的往桶中添加令牌处理请求时从桶中获取令牌和上面图中的处理逻辑一样。第二种方式不依赖于内部线程而是在每次处理请求之前先实时计算出要填充的令牌数并填充然后再从桶中获取令牌。下面是第二种方式的一种经典实现其中 capacity 表示令牌桶大小refillTokensPerOneMillis 表示填充速度每毫秒填充多少个availableTokens 表示令牌桶中还剩多少个令牌lastRefillTimestamp 表示上一次填充时间。
public class TokenBucket {
private final long capacity;
private final double refillTokensPerOneMillis;
private double availableTokens;
private long lastRefillTimestamp;
public TokenBucket(long capacity, long refillTokens, long refillPeriodMillis) {
this.capacity = capacity;
this.refillTokensPerOneMillis = (double) refillTokens / (double) refillPeriodMillis;
this.availableTokens = capacity;
this.lastRefillTimestamp = System.currentTimeMillis();
}
synchronized public boolean tryConsume(int numberTokens) {
refill();
if (availableTokens < numberTokens) {
return false;
} else {
availableTokens -= numberTokens;
return true;
}
}
private void refill() {
long currentTimeMillis = System.currentTimeMillis();
if (currentTimeMillis > lastRefillTimestamp) {
long millisSinceLastRefill = currentTimeMillis - lastRefillTimestamp;
double refill = millisSinceLastRefill * refillTokensPerOneMillis;
this.availableTokens = Math.min(capacity, availableTokens + refill);
this.lastRefillTimestamp = currentTimeMillis;
}
}
}
可以像下面这样创建一个令牌桶桶大小为 100且每秒生成 100 个令牌:
TokenBucket limiter = new TokenBucket(100, 100, 1000);
从上面的代码片段可以看出令牌桶算法的实现非常简单也非常高效仅仅通过几个变量的运算就实现了完整的限流功能。核心逻辑在于 refill() 这个方法在每次消费令牌时计算当前时间和上一次填充的时间差并根据填充速度计算出应该填充多少令牌。在重新填充令牌后再判断请求的令牌数是否足够如果不够返回 false如果足够则减去令牌数并返回 true。
在实际的应用中往往不会直接使用这种原始的令牌桶算法一般会在它的基础上作一些改进比如填充速率支持动态调整令牌总数支持透支基于 Redis 支持分布式限流等不过总体来说还是符合令牌桶算法的整体框架我们在后面学习一些开源项目时对此会有更深的体会。
三、一些开源项目
有很多开源项目中都实现了限流的功能这一节通过一些开源项目的学习了解限流是如何实现的。
3.1 Guava 的 RateLimiter
Google Guava 是一个强大的核心库包含了很多有用的工具类例如集合、缓存、并发库、字符串处理、I/O 等等。其中在并发库中Guava 提供了两个和限流相关的类RateLimiter 和 SmoothRateLimiter。Guava 的 RateLimiter 基于令牌桶算法实现不过在传统的令牌桶算法基础上做了点改进支持两种不同的限流方式平滑突发限流SmoothBursty 和 平滑预热限流SmoothWarmingUp。
下面的方法可以创建一个平滑突发限流器SmoothBursty
RateLimiter limiter = RateLimiter.create(5);
RateLimiter.create(5) 表示这个限流器容量为 5并且每秒生成 5 个令牌也就是每隔 200 毫秒生成一个。我们可以使用 limiter.acquire() 消费令牌如果桶中令牌足够返回 0如果令牌不足则阻塞等待并返回等待的时间。我们连续请求几次
System.out.println(limiter.acquire());
System.out.println(limiter.acquire());
System.out.println(limiter.acquire());
System.out.println(limiter.acquire());
输出结果如下
10.0
20.198239
30.196083
40.200609
可以看出限流器创建之后初始会有一个令牌然后每隔 200 毫秒生成一个令牌所以第一次请求直接返回 0后面的请求都会阻塞大约 200 毫秒。另外SmoothBursty 还具有应对突发的能力而且 还允许消费未来的令牌比如下面的例子
RateLimiter limiter = RateLimiter.create(5);
System.out.println(limiter.acquire(10));
System.out.println(limiter.acquire(1));
System.out.println(limiter.acquire(1));
会得到类似下面的输出
10.0
21.997428
30.192273
40.200616
限流器创建之后初始令牌只有一个但是我们请求 10 个令牌竟然也通过了只不过看后面请求发现第二次请求花了 2 秒左右的时间把前面的透支的令牌给补上了。
Guava 支持的另一种限流方式是平滑预热限流器SmoothWarmingUp可以通过下面的方法创建
RateLimiter limiter = RateLimiter.create(2, 3, TimeUnit.SECONDS);
System.out.println(limiter.acquire(1));
System.out.println(limiter.acquire(1));
System.out.println(limiter.acquire(1));
System.out.println(limiter.acquire(1));
System.out.println(limiter.acquire(1));
第一个参数还是每秒创建的令牌数量这里是每秒 2 个也就是每 500 毫秒生成一个后面的参数表示从冷启动速率过渡到平均速率的时间间隔也就是所谓的热身时间间隔warm up period。我们看下输出结果
10.0
21.329289
30.994375
40.662888
50.501287
第一个请求还是立即得到令牌但是后面的请求和上面平滑突发限流就完全不一样了按理来说 500 毫秒就会生成一个令牌但是我们发现第二个请求却等了 1.3s而不是 0.5s后面第三个和第四个请求也等了一段时间。不过可以看出等待时间在慢慢的接近 0.5s直到第五个请求等待时间才开始变得正常。从第一个请求到第五个请求这中间的时间间隔就是热身阶段可以算出热身的时间就是我们设置的 3 秒。
3.2 Bucket4j
Bucket4j是一个基于令牌桶算法实现的强大的限流库它不仅支持单机限流还支持通过诸如 Hazelcast、Ignite、Coherence、Infinispan 或其他兼容 JCache API (JSR 107) 规范的分布式缓存实现分布式限流。
在使用 Bucket4j 之前我们有必要先了解 Bucket4j 中的几个核心概念
- Bucket
- Bandwidth
- Refill
Bucket 接口代表了令牌桶的具体实现也是我们操作的入口。它提供了诸如 tryConsume 和 tryConsumeAndReturnRemaining 这样的方法供我们消费令牌。可以通过下面的构造方法来创建Bucket:
Bucket bucket = Bucket4j.builder().addLimit(limit).build();
if(bucket.tryConsume(1)) {
System.out.println("ok");
} else {
System.out.println("error");
}
Bandwidth 的意思是带宽 可以理解为限流的规则。Bucket4j 提供了两种方法来创建 Bandwidthsimple 和 classic。下面是 simple 方式创建的 Bandwidth表示桶大小为 10填充速度为每分钟 10 个令牌:
Bandwidth limit = Bandwidth.simple(10, Duration.ofMinutes(1));
simple方式桶大小和填充速度是一样的classic 方式更灵活一点可以自定义填充速度下面的例子表示桶大小为 10填充速度为每分钟 5 个令牌:
Refill filler = Refill.greedy(5, Duration.ofMinutes(1));
Bandwidth limit = Bandwidth.classic(10, filler);
其中Refill 用于填充令牌桶可以通过它定义填充速度Bucket4j 有两种填充令牌的策略间隔策略intervally 和 贪婪策略greedy。在上面的例子中我们使用的是贪婪策略如果使用间隔策略可以像下面这样创建 Refill
Refill filler = Refill.intervally(5, Duration.ofMinutes(1));
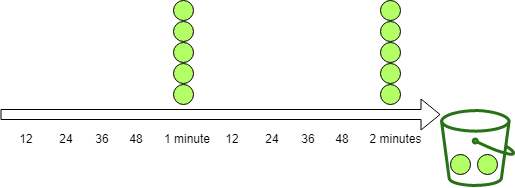
所谓间隔策略指的是每隔一段时间一次性的填充所有令牌比如上面的例子会每隔一分钟填充 5 个令牌如下所示
而贪婪策略会尽可能贪婪的填充令牌同样是上面的例子会将一分钟划分成 5 个更小的时间单元每隔 12 秒填充 1 个令牌如下所示
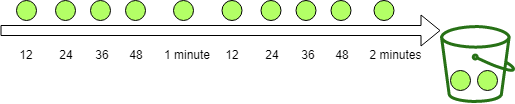
在了解了 Bucket4j 中的几个核心概念之后我们再来看看官网介绍的一些特性
- 基于令牌桶算法
- 高性能无锁实现
- 不存在精度问题所有计算都是基于整型的
- 支持通过符合 JCache API 规范的分布式缓存系统实现分布式限流
- 支持为每个 Bucket 设置多个 Bandwidth
- 支持同步和异步 API
- 支持可插拔的监听 API用于集成监控和日志
- 不仅可以用于限流还可以用于简单的调度
Bucket4j 提供了丰富的文档推荐在使用 Bucket4j 之前先把官方文档中的 基本用法 和 高级特性 仔细阅读一遍。另外关于 Bucket4j 的使用推荐这篇文章 Rate limiting Spring MVC endpoints with bucket4j这篇文章详细的讲解了如何在 Spring MVC 中使用拦截器和 Bucket4j 打造业务无侵入的限流方案另外还讲解了如何使用 Hazelcast 实现分布式限流另外Rate Limiting a Spring API Using Bucket4j 这篇文章也是一份很好的入门教程介绍了 Bucket4j 的基础知识在文章的最后还提供了 Spring Boot Starter 的集成方式结合 Spring Boot Actuator 很容易将限流指标集成到监控系统中。
和 Guava 的限流器相比Bucket4j 的功能显然要更胜一筹毕竟 Guava 的目的只是用作通用工具类而不是用于限流的。使用 Bucket4j 基本上可以满足我们的大多数要求不仅支持单机限流和分布式限流而且可以很好的集成监控搭配 Prometheus 和 Grafana 简直完美。值得一提的是有很多开源项目譬如 JHipster API Gateway 就是使用 Bucket4j 来实现限流的。
Bucket4j 唯一不足的地方是它只支持请求频率限流不支持并发量限流另外还有一点虽然 Bucket4j 支持分布式限流但它是基于 Hazelcast 这样的分布式缓存系统实现的不能使用 Redis这在很多使用 Redis 作缓存的项目中就很不爽所以我们还需要在开源的世界里继续探索。
3.3 Resilience4j
Resilience4j 是一款轻量级、易使用的高可用框架。用过 Spring Cloud 早期版本的同学肯定都听过 Netflix HystrixResilience4j 的设计灵感就来自于它。自从 Hystrix 停止维护之后官方也推荐大家使用 Resilience4j 来代替 Hystrix。

翻译上图
Hystrix状态Hystrix不再处于活跃的开发阶段目前处于维护模式。Hystrix(版本1.5.18)足够稳定可以满足Netflix对我们现有应用程序的需求。与此同时我们的重点已经转移到对应用程序的实时性能做出反应的更自适应的实现而不是预先配置的设置(例如通过自适应并发限制)。对于Hystrix之类的东西有意义的情况我们打算继续在现有的应用程序中使用Hystrix并在新的内部项目中利用开放和活跃的项目如弹性4j。我们开始建议其他国家也这样做。
Resilience4j 的底层采用 Vavr这是一个非常轻量级的 Java 函数式库使得 Resilience4j 非常适合函数式编程。Resilience4j 以装饰器模式提供对函数式接口或 lambda 表达式的封装提供了一波高可用机制重试Retry、熔断Circuit Breaker、限流Rate Limiter、限时Timer Limiter、隔离Bulkhead、缓存Caceh 和 降级Fallback。我们重点关注这里的两个功能限流Rate Limiter 和 隔离BulkheadRate Limiter 是请求频率限流Bulkhead 是并发量限流。
Resilience4j 提供了两种限流的实现SemaphoreBasedRateLimiter 和 AtomicRateLimiter。SemaphoreBasedRateLimiter 基于信号量实现用户的每次请求都会申请一个信号量并记录申请的时间申请通过则允许请求申请失败则限流另外有一个内部线程会定期扫描过期的信号量并释放很显然这是令牌桶的算法。AtomicRateLimiter 和上面的经典实现类似不需要额外的线程在处理每次请求时根据距离上次请求的时间和生成令牌的速度自动填充。关于这二者的区别可以参考文章 Rate Limiter Internals in Resilience4j。
Resilience4j 也提供了两种隔离的实现SemaphoreBulkhead 和 ThreadPoolBulkhead通过信号量或线程池控制请求的并发数具体的用法参考官方文档这里不再赘述。
下面是一个同时使用限流和隔离的例子
// 创建一个 Bulkhead最大并发量为 150
BulkheadConfig bulkheadConfig = BulkheadConfig.custom()
.maxConcurrentCalls(150)
.maxWaitTime(100)
.build();
Bulkhead bulkhead = Bulkhead.of("backendName", bulkheadConfig);
// 创建一个 RateLimiter每秒允许一次请求
RateLimiterConfig rateLimiterConfig = RateLimiterConfig.custom()
.timeoutDuration(Duration.ofMillis(100))
.limitRefreshPeriod(Duration.ofSeconds(1))
.limitForPeriod(1)
.build();
RateLimiter rateLimiter = RateLimiter.of("backendName", rateLimiterConfig);
// 使用 Bulkhead 和 RateLimiter 装饰业务逻辑
Supplier<String> supplier = () -> backendService.doSomething();
Supplier<String> decoratedSupplier = Decorators.ofSupplier(supplier)
.withBulkhead(bulkhead)
.withRateLimiter(rateLimiter)
.decorate();
// 调用业务逻辑
Try<String> try = Try.ofSupplier(decoratedSupplier);
assertThat(try.isSuccess()).isTrue();
Resilience4j 在功能特性上比 Bucket4j 强大不少而且还支持并发量限流。不过最大的遗憾是Resilience4j 不支持分布式限流。
3.4 其他
网上还有很多限流相关的开源项目不可能一一介绍这里列出来的只是冰山之一角
- https://github.com/mokies/ratelimitj
- https://github.com/wangzheng0822/ratelimiter4j
- https://github.com/wukq/rate-limiter
- https://github.com/marcosbarbero/spring-cloud-zuul-ratelimit
- https://github.com/onblog/SnowJena
- https://gitee.com/zhanghaiyang/spring-boot-starter-current-limiting
- https://github.com/Netflix/concurrency-limits
可以看出限流技术在实际项目中应用非常广泛大家对实现自己的限流算法乐此不疲新算法和新实现层出不穷。但是找来找去目前还没有找到一款开源项目完全满足我的需求。
我的需求其实很简单需要同时满足两种不同的限流场景请求频率限流和并发量限流并且能同时满足两种不同的限流架构单机限流和分布式限流。下面我们就开始在 Spring Cloud Gateway 中实现这几种限流通过前面介绍的那些项目我们取长补短基本上都能用比较成熟的技术实现只不过对于最后一种情况分布式并发量限流网上没有搜到现成的解决方案在和同事讨论了几个晚上之后想出一种新型的基于双窗口滑动的限流算法我在这里抛砖引玉欢迎大家批评指正如果大家有更好的方法也欢迎讨论。
四、在网关中实现限流
在文章一开始介绍 Spring Cloud Gateway 的特性时我们注意到其中有一条 Request Rate Limiting说明网关自带了限流的功能但是 Spring Cloud Gateway 自带的限流有很多限制譬如不支持单机限流不支持并发量限流而且它的请求频率限流也是不尽人意这些都需要我们自己动手来解决。
4.1 实现单机请求频率限流
Spring Cloud Gateway 中定义了关于限流的一个接口 RateLimiter如下
public interface RateLimiter<C> extends StatefulConfigurable<C> {
Mono<RateLimiter.Response> isAllowed(String routeId, String id);
}
这个接口就一个方法 isAllowed第一个参数 routeId 表示请求路由的 ID根据 routeId 可以获取限流相关的配置第二个参数 id 表示要限流的对象的唯一标识可以是用户名也可以是 IP或者其他的可以从 ServerWebExchange 中得到的信息。我们看下 RequestRateLimiterGatewayFilterFactory 中对 isAllowed 的调用逻辑
@Override
public GatewayFilter apply(Config config) {
// 从配置中得到 KeyResolver
KeyResolver resolver = getOrDefault(config.keyResolver, defaultKeyResolver);
// 从配置中得到 RateLimiter
RateLimiter<Object> limiter = getOrDefault(config.rateLimiter,
defaultRateLimiter);
boolean denyEmpty = getOrDefault(config.denyEmptyKey, this.denyEmptyKey);
HttpStatusHolder emptyKeyStatus = HttpStatusHolder
.parse(getOrDefault(config.emptyKeyStatus, this.emptyKeyStatusCode));
return (exchange, chain) -> resolver.resolve(exchange).defaultIfEmpty(EMPTY_KEY)
.flatMap(key -> {
// 通过 KeyResolver 得到 key作为唯一标识 id 传入 isAllowed() 方法
if (EMPTY_KEY.equals(key)) {
if (denyEmpty) {
setResponseStatus(exchange, emptyKeyStatus);
return exchange.getResponse().setComplete();
}
return chain.filter(exchange);
}
// 获取当前路由 ID作为 routeId 参数传入 isAllowed() 方法
String routeId = config.getRouteId();
if (routeId == null) {
Route route = exchange
.getAttribute(ServerWebExchangeUtils.GATEWAY_ROUTE_ATTR);
routeId = route.getId();
}
return limiter.isAllowed(routeId, key).flatMap(response -> {
for (Map.Entry<String, String> header : response.getHeaders()
.entrySet()) {
exchange.getResponse().getHeaders().add(header.getKey(),
header.getValue());
}
// 请求允许直接走到下一个 filter
if (response.isAllowed()) {
return chain.filter(exchange);
}
// 请求被限流返回设置的 HTTP 状态码默认是 429
setResponseStatus(exchange, config.getStatusCode());
return exchange.getResponse().setComplete();
});
});
}
从上面的的逻辑可以看出通过实现 KeyResolver 接口的 resolve 方法就可以自定义要限流的对象了。
public interface KeyResolver {
Mono<String> resolve(ServerWebExchange exchange);
}
比如下面的 HostAddrKeyResolver 可以根据 IP 来限流
public interface KeyResolver {
Mono<String> resolve(ServerWebExchange exchange);
}
// 比如下面的 HostAddrKeyResolver 可以根据 IP 来限流
public class HostAddrKeyResolver implements KeyResolver {
@Override
public Mono<String> resolve(ServerWebExchange exchange) {
return Mono.just(exchange.getRequest().getRemoteAddress().getAddress().getHostAddress());
}
}
我们继续看 Spring Cloud Gateway 的代码发现RateLimiter 接口只提供了一个实现类 RedisRateLimiter
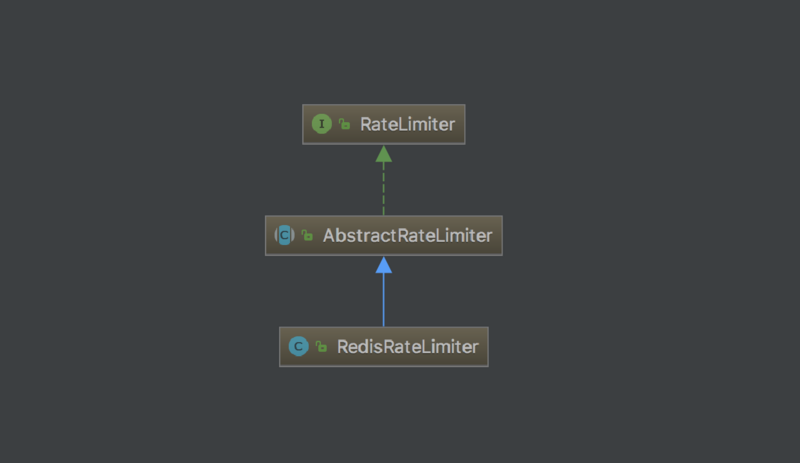
很显然是基于 Redis 实现的限流虽说通过 Redis 也可以实现单机限流但是总感觉有些大材小用而且对于那些没有 Redis 的环境很不友好。所以我们要实现真正的本地限流。
我们从 Spring Cloud Gateway 的 pull request 中发现了一个新特性 Feature/local-rate-limiter而且看提交记录这个新特性很有可能会合并到 3.0.0 版本中。我们不妨来看下这个 local-rate-limiter 的实现LocalRateLimiter.java可以看出它是基于 Resilience4有意思的是这个类 还有一个早期版本是基于 Bucket4j 实现的
public Mono<Response> isAllowed(String routeId, String id) {
Config routeConfig = loadConfiguration(routeId);
// How many requests per second do you want a user to be allowed to do?
int replenishRate = routeConfig.getReplenishRate();
// How many seconds for a token refresh?
int refreshPeriod = routeConfig.getRefreshPeriod();
// How many tokens are requested per request?
int requestedTokens = routeConfig.getRequestedTokens();
final io.github.resilience4j.ratelimiter.RateLimiter rateLimiter = RateLimiterRegistry
.ofDefaults()
.rateLimiter(id, createRateLimiterConfig(refreshPeriod, replenishRate));
final boolean allowed = rateLimiter.acquirePermission(requestedTokens);
final Long tokensLeft = (long) rateLimiter.getMetrics().getAvailablePermissions();
Response response = new Response(allowed, getHeaders(routeConfig, tokensLeft));
return Mono.just(response);
}
有意思的是这个类 还有一个早期版本是基于 Bucket4j 实现的
public Mono<Response> isAllowed(String routeId, String id) {
Config routeConfig = loadConfiguration(routeId);
// How many requests per second do you want a user to be allowed to do?
int replenishRate = routeConfig.getReplenishRate();
// How much bursting do you want to allow?
int burstCapacity = routeConfig.getBurstCapacity();
// How many tokens are requested per request?
int requestedTokens = routeConfig.getRequestedTokens();
final Bucket bucket = bucketMap.computeIfAbsent(id,
(key) -> createBucket(replenishRate, burstCapacity));
final boolean allowed = bucket.tryConsume(requestedTokens);
Response response = new Response(allowed,
getHeaders(routeConfig, bucket.getAvailableTokens()));
return Mono.just(response);
}
实现方式都是类似的在上面对 Bucket4j 和 Resilience4j 已经作了比较详细的介绍这里不再赘述。不过从这里也可以看出 Spring 生态圈对 Resilience4j 是比较看好的我们也可以将其引入到我们的项目中。
4.2 实现分布式请求频率限流
上面介绍了如何实现单机请求频率限流接下来再看下分布式请求频率限流。这个就比较简单了因为上面说了Spring Cloud Gateway 自带了一个限流实现就是 RedisRateLimiter可以用于分布式限流。它的实现原理依然是基于令牌桶算法的不过实现逻辑是放在一段 lua 脚本中的我们可以在 src/main/resources/META-INF/scripts 目录下找到该脚本文件 request_rate_limiter.lua
local tokens_key = KEYS[1]
local timestamp_key = KEYS[2]
local rate = tonumber(ARGV[1])
local capacity = tonumber(ARGV[2])
local now = tonumber(ARGV[3])
local requested = tonumber(ARGV[4])
local fill_time = capacity/rate
local ttl = math.floor(fill_time*2)
local last_tokens = tonumber(redis.call("get", tokens_key))
if last_tokens == nil then
last_tokens = capacity
end
local last_refreshed = tonumber(redis.call("get", timestamp_key))
if last_refreshed == nil then
last_refreshed = 0
end
local delta = math.max(0, now-last_refreshed)
local filled_tokens = math.min(capacity, last_tokens+(delta*rate))
local allowed = filled_tokens >= requested
local new_tokens = filled_tokens
local allowed_num = 0
if allowed then
new_tokens = filled_tokens - requested
allowed_num = 1
end
if ttl > 0 then
redis.call("setex", tokens_key, ttl, new_tokens)
redis.call("setex", timestamp_key, ttl, now)
end
return { allowed_num, new_tokens }
这段代码和上面介绍令牌桶算法时用 Java 实现的那段经典代码几乎是一样的。这里使用 lua 脚本主要是利用了 Redis 的单线程特性以及执行 lua 脚本的原子性避免了并发访问时可能出现请求量超出上限的现象。想象目前令牌桶中还剩 1 个令牌此时有两个请求同时到来判断令牌是否足够也是同时的两个请求都认为还剩 1 个令牌于是两个请求都被允许了。
有两种方式来配置 Spring Cloud Gateway 自带的限流。第一种方式是通过配置文件比如下面所示的代码可以对某个 route 进行限流
spring:
cloud:
gateway:
routes:
- id: test
uri: http://httpbin.org:80/get
filters:
- name: RequestRateLimiter
args:
key-resolver: '#{@hostAddrKeyResolver}'
redis-rate-limiter.replenishRate: 1
redis-rate-limiter.burstCapacity: 3
其中key-resolver 使用 SpEL 表达式 #{@beanName} 从 Spring 容器中获取 hostAddrKeyResolver 对象burstCapacity 表示令牌桶的大小replenishRate 表示每秒往桶中填充多少个令牌也就是填充速度。
第二种方式是通过下面的代码来配置
@Bean
public RouteLocator myRoutes(RouteLocatorBuilder builder) {
return builder.routes()
.route(p -> p
.path("/get")
.filters(filter -> filter.requestRateLimiter()
.rateLimiter(RedisRateLimiter.class, rl -> rl.setBurstCapacity(3).setReplenishRate(1)).and())
.uri("http://httpbin.org:80"))
.build();
}
这样就可以对某个 route 进行限流了。但是这里有一点要注意Spring Cloud Gateway 自带的限流器有一个很大的坑replenishRate 不支持设置小数也就是说往桶中填充的 token 的速度最少为每秒 1 个所以如果我的限流规则是每分钟 10 个请求按理说应该每 6 秒填充一次或每秒填充 1/6 个 token这种情况 Spring Cloud Gateway 就没法正确的限流。网上也有人提了 issuesupport greater than a second resolution for the rate limiter但还没有得到解决。
4.3 实现单机并发量限流
上面学习 Resilience4j 的时候我们提到了 Resilience4j 的一个功能特性叫 隔离Bulkhead。Bulkhead 这个单词的意思是船的舱壁利用舱壁可以将不同的船舱隔离起来这样如果一个船舱破损进水那么只损失这一个船舱其它船舱可以不受影响。借鉴造船行业的经验这种模式也被引入到软件行业我们把它叫做 舱壁模式Bulkhead pattern。舱壁模式一般用于服务隔离对于一些比较重要的系统资源如 CPU、内存、连接数等可以为每个服务设置各自的资源限制防止某个异常的服务把系统的所有资源都消耗掉。这种服务隔离的思想同样可以用来做并发量限流。
正如前文所述Resilience4j 提供了两种 Bulkhead 的实现SemaphoreBulkhead 和 ThreadPoolBulkhead这也正是舱壁模式常见的两种实现方案一种是带计数的信号量一种是固定大小的线程池。考虑到多线程场景下的线程切换成本默认推荐使用信号量。
在操作系统基础课程中我们学习过两个名词互斥量Mutex 和 信号量Semaphores。互斥量用于线程的互斥它和临界区有点相似只有拥有互斥对象的线程才有访问资源的权限由于互斥对象只有一个因此任何情况下只会有一个线程在访问此共享资源从而保证了多线程可以安全的访问和操作共享资源。而信号量是用于线程的同步这是由荷兰科学家 E.W.Dijkstra 提出的概念它和互斥量不同信号允许多个线程同时使用共享资源但是它同时设定了访问共享资源的线程最大数目从而可以进行并发量控制。
下面是使用信号量限制并发访问的一个简单例子
public class SemaphoreTest {
private static ExecutorService threadPool = Executors.newFixedThreadPool(100);
private static Semaphore semaphore = new Semaphore(10);
public static void main(String[] args) {
for (int i = 0; i < 100; i++) {
threadPool.execute(new Runnable() {
@Override
public void run() {
try {
semaphore.acquire();
System.out.println("Request processing ...");
semaphore.release();
} catch (InterruptedException e) {
e.printStack();
}
}
});
}
threadPool.shutdown();
}
}
这里我们创建了 100 个线程同时执行但是由于信号量计数为 10所以同时只能有 10 个线程在处理请求。说到计数实际上在 Java 里除了 Semaphore 还有很多类也可以用作计数比如 AtomicLong 或 LongAdder这在并发量限流中非常常见只是无法提供像信号量那样的阻塞能力
public class AtomicLongTest {
private static ExecutorService threadPool = Executors.newFixedThreadPool(100);
private static AtomicLong atomic = new AtomicLong();
public static void main(String[] args) {
for (int i = 0; i < 100; i++) {
threadPool.execute(new Runnable() {
@Override
public void run() {
try {
if(atomic.incrementAndGet() > 10) {
System.out.println("Request rejected ...");
return;
}
System.out.println("Request processing ...");
atomic.decrementAndGet();
} catch (InterruptedException e) {
e.printStack();
}
}
});
}
threadPool.shutdown();
}
}
4.4 实现分布式并发量限流
通过在单机实现并发量限流我们掌握了几种常用的手段信号量、线程池、计数器这些都是单机上的概念。那么稍微拓展下如果能实现分布式信号量、分布式线程池、分布式计数器那么实现分布式并发量限流不就易如反掌了吗
关于分布式线程池是我自己杜撰的词在网上并没有找到类似的概念比较接近的概念是资源调度和分发但是又感觉不像这里直接忽略吧。
关于分布式信号量还真有这样的东西比如 Apache Ignite 就提供了 IgniteSemaphore 用于创建分布式信号量它的使用方式和 Semaphore 非常类似。使用 Redis 的 ZSet 也可以实现分布式信号量比如 这篇博客介绍的方法还有《Redis in Action》这本电子书中也提到了这样的例子教你如何实现 Counting semaphores。另外Redisson 也实现了基于 Redis 的分布式信号量 RSemaphore用法也和 Semaphore 类似。使用分布式信号量可以很容易实现分布式并发量限流实现方式和上面的单机并发量限流几乎是一样的。
最后关于分布式计数器实现方案也是多种多样。比如使用 Redis 的 INCR 就很容易实现更有甚者使用 MySQL 数据库也可以实现。只不过使用计数器要注意操作的原子性每次请求时都要经过这三步操作取计数器当前的值、判断是否超过阈值超过则拒绝、将计数器的值自增。这其实和信号量的 P 操作是一样的而释放就对应 V 操作。
所以利用分布式信号量和计数器就可以实现并发量限流了吗问题当然没有这么简单。实际上上面通过信号量和计数器实现单机并发量限流的代码片段有一个严重 BUG
semaphore.acquire();
System.out.println("Request processing ...");
semaphore.release();
想象一下如果在处理请求时出现异常了会怎么样很显然信号量被该线程获取了但是却永远不会释放如果请求异常多了这将导致信号量被占满最后一个请求也进不来。在单机场景下这个问题可以很容易解决加一个 finally 就行了
try {
semaphore.acquire();
System.out.println("Request processing ...");
} catch (InterruptedException e) {
e.printStack();
} finally {
semaphore.release();
}
由于无论出现何种异常finally 中的代码一定会执行这样就保证了信号量一定会被释放。但是在分布式系统中就不是加一个 finally 这么简单了。这是因为在分布式系统中可能存在的异常不一定是可被捕获的代码异常还有可能是服务崩溃或者不可预知的系统宕机就算是正常的服务重启也可能导致分布式信号量无法释放。
对于这个问题我和几个同事连续讨论了几个晚上想出了两种解决方法第一种方法是使用带 TTL 的计数器第二种方法是基于双窗口滑动的一种比较 tricky 的算法。
第一种方法比较容易理解我们为每个请求赋予一个唯一 ID并在 Redis 里写入一个键值对key 为 requests_xxxxxx 为请求 IDvalue 为 1并给这个 key 设置一个 TTL如果你的应用中存在耗时非常长的请求譬如对于一些 WebSockket 请求可能会持续几个小时还需要开一个线程定期去刷新这个 key 的 TTL。然后在判断并发量时使用 KEYS 命令查询 requests_* 开头的 key 的个数就可以知道当前一共有多少个请求如果超过并发量上限则拒绝请求。这种方法可以很好的应对服务崩溃或重启的问题由于每个 key 都设置了 TTL所以经过一段时间后这些 key 就会自动消失就不会出现信号量占满不释放的情况了。但是这里使用 KEYS 命令查询请求个数是一个非常低效的做法在请求量比较多的情况下网关的性能会受到严重影响。我们可以把 KEYS 命令换成 SCAN性能会得到些许提升但总体来说效果还是很不理想的。
针对第一种方法我们可以进一步优化不用为每个请求写一个键值对而是为每个分布式系统中的每个实例赋予一个唯一 ID并在 Redis 里写一个键值对key 为 instances_xxxxxx 为实例 IDvalue 为这个实例当前的并发量。同样的我们为这个 key 设置一个 TTL并且开启一个线程定期去刷新这个 TTL。每接受一个请求后计数器加一请求结束计数器减一这和单机场景下的处理方式一样只不过在判断并发量时还是需要使用 KEYS 或 SCAN 获取所有的实例并计算出并发量的总和。不过由于实例个数是有限的性能比之前的做法有了明显的提升。
第二种方法我称之为 双窗口滑动算法结合了 TTL 计数器和滑动窗口算法。我们按分钟来设置一个时间窗口在 Redis 里对应 202009051130 这样的一个 keyvalue 为计数器表示请求的数量。当接受一个请求后在当前的时间窗口中加一当请求结束在当前的时间窗口中减一注意接受请求和请求结束的时间窗口可能不是同一个。另外我们还需要一个本地列表来记录当前实例正在处理的所有请求和请求对应的时间窗口并通过一个小于时间窗口的定时线程如 30 秒来迁移过期的请求所谓过期指的是请求的时间窗口和当前时间窗口不一致。那么具体如何迁移呢我们首先需要统计列表中一共有多少请求过期了然后将列表中的过期请求时间更新为当前时间窗口并从 Redis 中上一个时间窗口移动相应数量到当前时间窗口也就是上一个时间窗口减 X当前时间窗口加 X。由于迁移线程定期执行所以过期的请求总是会被移动到当前窗口最终 Redis 中只有当前时间窗口和上个时间窗口这两个时间窗口中有数据再早一点的窗口时间中的数据会被往后迁移所以可以给这个 key 设置一个 3 分钟或 5 分钟的 TTL。判断并发量时由于只有两个 key只需要使用 MGET 获取两个值相加即可。下面的流程图详细描述了算法的运行过程
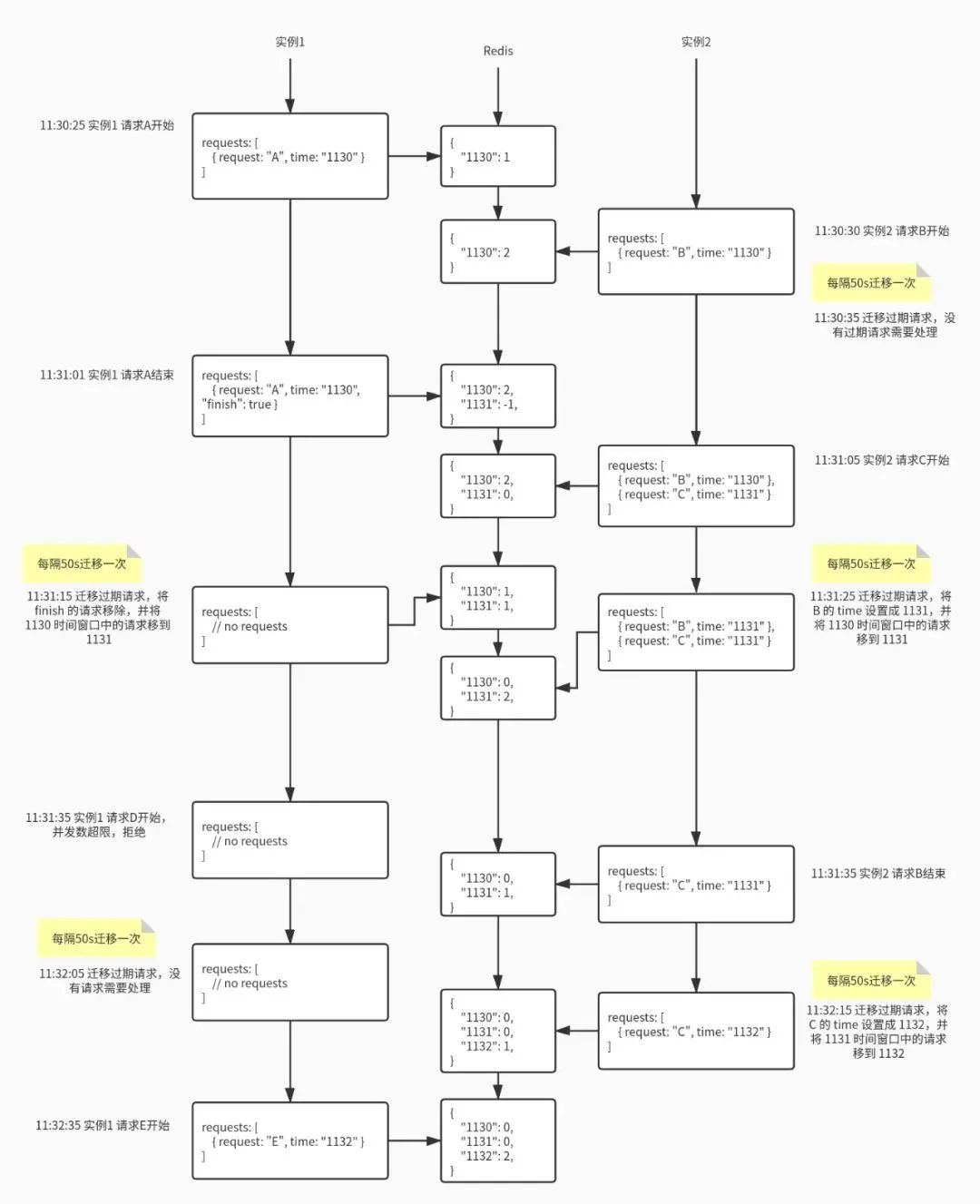
其中有几个需要注意的细节
- 请求结束时直接在 Redis 中当前时间窗口减一即可就算是负数也没关系。请求列表中的该请求不用急着删除可以打上结束标记在迁移线程中统一删除当然如果请求的开始时间和结束时间在同一个窗口可以直接删除
- 迁移的时间间隔要小于时间窗口一般设置为 30s
- Redis 中的 key 一定要设置 TTL时间至少为 2 个时间窗口一般设置为 3 分钟
- 迁移过程涉及到“从上一个时间窗口减”和“在当前时间窗口加”两个操作要注意操作的原子性
- 获取当前并发量可以通过 MGET 一次性读取两个时间窗口的值不用 GET 两次
- 获取并发量和判断并发量是否超限这个过程也要注意操作的原子性。
总结
网关作为微服务架构中的重要一环充当着一夫当关万夫莫开的角色所以对网关服务的稳定性要求和性能要求都非常高。为保证网关服务的稳定性一代又一代的程序员们前仆后继想出了十八般武艺限流、熔断、隔离、缓存、降级、等等等等。这篇文章从限流入手详细介绍了限流的场景和算法以及源码实现和可能踩到的坑。尽管限流只是网关的一个非常小的功能但却影响到网关的方方面面在系统架构的设计中至关重要。虽然我试着从不同的角度希望把限流介绍的更完全但终究是管中窥豹只见一斑还有很多的内容没有介绍到比如阿里开源的 Sentinel 组件也可以用于限流因为篇幅有限未能展开。另外前文提到的 Netflix 不再维护 Hystrix 项目这是因为他们把精力放到另一个限流项目 concurrency-limits 上了这个项目的目标是打造一款自适应的极具弹性的限流组件它借鉴了 TCP 拥塞控制的算法TCP congestion control algorithm实现系统的自动限流感兴趣的同学可以去它的项目主页了解更多内容。
本文篇幅较长难免疏漏如有问题还望不吝赐教。