

【Python学习】字典和集合
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
前言
往期文章
【Python学习】列表和元组
字典和集合
字典是一系列无序元素的组合其长度大小可变元素可以任意地删减和改变。不过要注意这里的元素是一对键key和值value
相比于列表和元组字典的性能更优特别是对于查找、添加和删除字典都能在常数的时间复杂度内完成
而集合和字典基本相同唯一的区别就是集合没有键和值的配对是一系列无序的、唯一的元素组合。
d1 = {'name': 'jason', 'age': 20, 'gender': 'male'}
d2 = dict({'name': 'jason', 'age': 20, 'gender': 'male'})
d3 = dict([('name', 'jason'), ('age', 20), ('gender', 'male')])
d4 = dict(name='jason', age=20, gender='male')
d1 == d2 == d3 ==d4
True
s1 = {1, 2, 3}
s2 = Set([1, 2, 3])
s1 == s2
True
集合并不支持索引操作因为集合本质上是一个哈希表和列表不一样
s = {1, 2, 3}
s[0]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'set' object does not support indexing
想要判断一个元素在不在字典或集合内我们可以用 value in dict/set
s = {1, 2, 3}
1 in s
True
10 in s
False
d = {'name': 'Runsen', 'age': 20}
'name' in d
True
'location' in d
False
字典的增删改
In [1]: d = {'name': 'Runsen', 'age': 20}^M
...:
In [2]: d['gender'] = 'male'
In [3]: d['birthday'] = '1999-10-01'
In [4]: d
Out[4]: {'name': 'Runsen', 'age': 20, 'gender': 'male', 'birthday': '1999-10-01'}
In [5]: d['birthday'] = '1999/10/01'
In [6]: d.pop('birthday')
Out[6]: '1999/10/01'
In [8]: d
Out[8]: {'name': 'Runsen', 'age': 20, 'gender': 'male'}
In [9]: s = {1, 2, 3}^M
...:
In [10]: s.add(4)
In [11]: s
Out[11]: {1, 2, 3, 4}
In [12]: s.remove(4)
In [13]: s
Out[13]: {1, 2, 3}****
字典的升序和降序排序
d = {'b': 1, 'a': 2, 'c': 10}
d_sorted_by_key = sorted(d.items(), key=lambda x: x[0]) # 根据字典键的升序排序
d_sorted_by_value = sorted(d.items(), key=lambda x: x[1]) # 根据字典值的升序排序
d_sorted_by_key
[('a', 2), ('b', 1), ('c', 10)]
d_sorted_by_value
[('b', 1), ('a', 2), ('c', 10)]
增删查找
字典和集合是进行过性能高度优化的数据结构特别是对于查找、添加和删除操作
列表的做法
# list version
def find_unique_price_using_list(products):
unique_price_list = []
for _, price in products: # A
if price not in unique_price_list: #B
unique_price_list.append(price)
return len(unique_price_list)
# products id 和 price
products = [
(143121312, 100),
(432314553, 30),
(32421912367, 150),
(937153201, 30)
]
print('number of unique price is: {}'.format(find_unique_price_using_list(products)))
# 输出
number of unique price is: 3
集合的做法
# set version
def find_unique_price_using_set(products):
unique_price_set = set()
for _, price in products:
unique_price_set.add(price)
return len(unique_price_set)
products = [
(143121312, 100),
(432314553, 30),
(32421912367, 150),
(937153201, 30)
]
print('number of unique price is: {}'.format(find_unique_price_using_set(products)))
# 输出
number of unique price is: 3
比较运行的时间也就是性能
import time
id = [x for x in range(0, 100000)]
price = [x for x in range(200000, 300000)]
products = list(zip(id, price))
# 计算列表版本的时间
start_using_list = time.perf_counter()
find_unique_price_using_list(products)
end_using_list = time.perf_counter()
print("time elapse using list: {}".format(end_using_list - start_using_list))
## 输出
time elapse using list: 41.61519479751587
# 计算集合版本的时间
start_using_set = time.perf_counter()
find_unique_price_using_set(products)
end_using_set = time.perf_counter()
print("time elapse using set: {}".format(end_using_set - start_using_set))
# 输出
time elapse using set: 0.008238077163696289
在性能上集合完爆列表
对于字典哈希表存储了哈希值键和值这桑三个元素
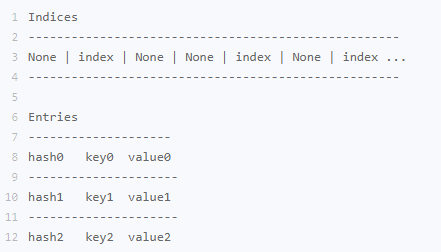
字典和集合都是无序的数据结构其内部的哈希表存储结构保证了查找插入删除操作的高效性。所以字典和集合通常运用在对元素的查找去重
初始化字典的方式有两种方法比较下哪一种更高效
In [20]: timeit a ={'name':"runsen",'age':20}
127 ns ± 0.8 ns per loop (mean ± std. dev. of 7 runs, 10000000 loops each)
In [21]: timeit b =dict({'name':"runsen",'age':20})
438 ns ± 3.41 ns per loop (mean ± std. dev. of 7 runs, 1000000 loops each)
第一种因为不用调用相关的函数
字典的键可以是一个列表吗下面这段代码中字典的初始化是否正确
In [22]: d = {'name': 'Runsen', ['education']: [' primary school', 'junior middle school']}^M
...:
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-22-13cd196aef11> in <module>
----> 1 d = {'name': 'Runsen', ['education']: [' primary school', 'junior middle school']}
TypeError: unhashable type: 'list'
In [23]: d = {'name': 'Runsen', ('education'): [' primary school', 'junior middle school']}^M
...:
...:
In [24]: d
Out[24]: {'name': 'Runsen', 'education': [' primary school', 'junior middle school']}
用列表作为 Key 在这里是不被允许的因为列表是一个动态变化的数据结构字典当中的 key 要求是不可变的原因也很好理解.
key 首先是不重复的如果 Key 是可以变化的话那么随着 Key 的变化这里就有可能就会有重复的 Key那么这就和字典的定义相违背如果把这里的列表换成之前我们讲过的元组是可以的因为元组不可变。
最后
刚开始接触Python的宝子有什么不懂的都可以私信我哦
我还准备了大量的免费视频教程PDF电子书籍以及源代码直接在文末名片自取即可哦