

分词算法----正向和逆向最大匹配算法(含Python代码实现)
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
文章目录
分词算法(Segmentation Method)
在文本处理流程中对语句进行分词Segmentation操作对于计算机认识并理解人类语言是基础且重要的。
对于中文来讲不同于英文直接采用空格符进行分隔并且中文词语内涵丰厚语义丰富所以只有采用合适的分词算法才能准确迅速地向计算机表达原有的意思提高工作效率。
最大匹配算法(Maximum Matching)
最大匹配算法是基于词表进行分词操作的主要包括正向正向最大匹配算法、逆向最大匹配算法、双向最大匹配算法等。 其主要原理都是切分出单字串(词语)然后和词库进行比对如果对比成功就记录下来从整句切除下来 否则减少一个单字继续比较直到字符串全部切除完毕即分词成功数组中的所有词语即是分词结果。
以下详细介绍算法的主要思想及具体代码实现。
需要的前提
进行匹配算法的执行前一定自己要设定一个字典库通常作为测试即可。
这里我自己使用
字典库
ch_dict = [‘我们’,‘经常’,‘有’,‘有意见’,‘意见’,‘分歧’]
测试语句
sentence = ‘我们经常有意见分歧’
最大匹配值
max_match_len = 5
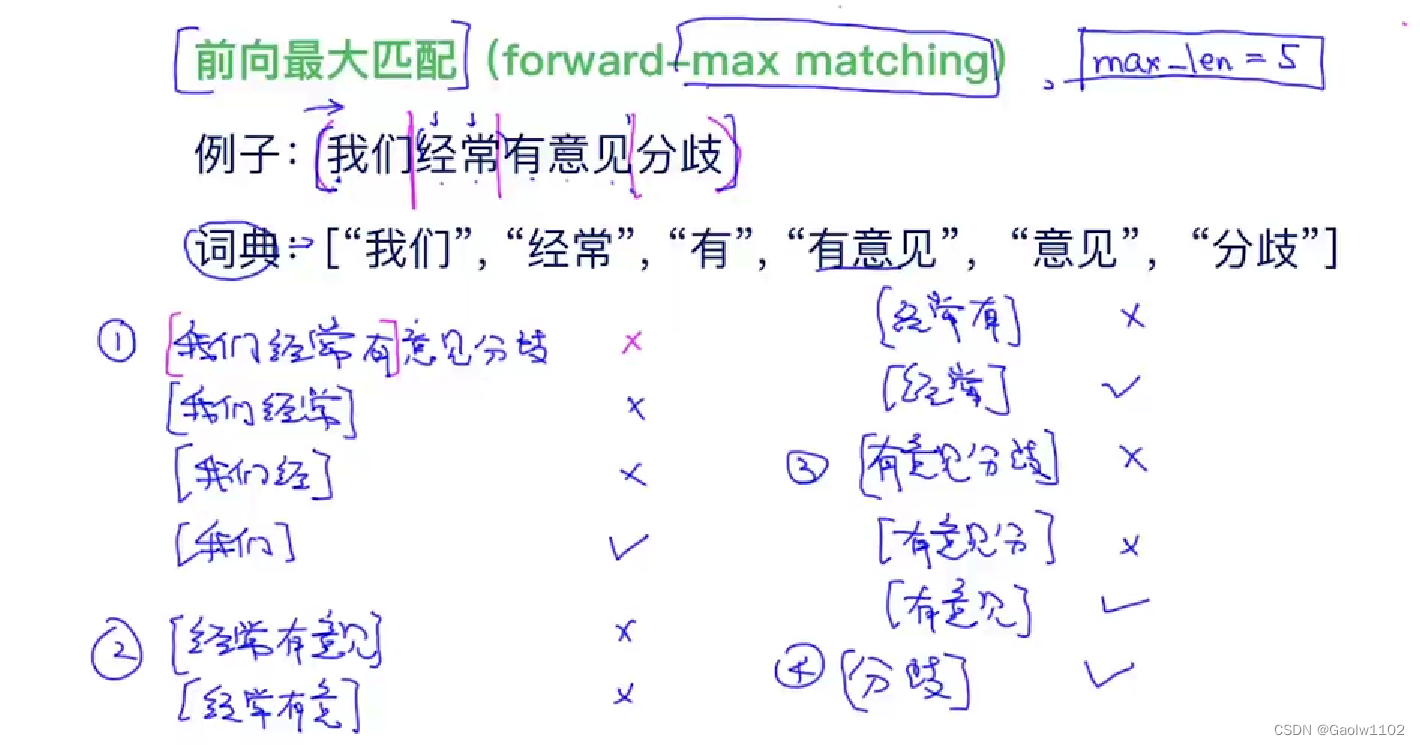
正向最大匹配算法(Forwards Maximum MatchFMM)
算法主要思想
从字符串的正方向出发先截取前5个字符与词典库中的词语进行对比。若比对不成功则截取前4个字符进行对比依次类推直到仅剩第一个字符自动进行截取此次截取结束若对比成功则将该词语记录下来并从句子中截取下来。直至句子全部被拆分为词语以数组进行存储。
算法思想示意图
具体代码实现
'''
(分词算法)正向最大匹配算法
'''
if __name__ == '__main__':
ch_dict = ['我们','经常','有','有意见','意见','分歧'] #中文的词典库用于匹配句子中的词语
sentence = '我们经常有意见分歧' #例句需要进行分词
segment_list = [] #存放分词后的分词词组
#例句不为空时循环地进行分词操作
while len(sentence) >= 1:
# 最大匹配单词的长度为5当然实际意义从3开始即可因为词典最大单词长度为3
max_match_len = 5
#当匹配单词长度大于1时循环判断分词
while max_match_len > 1:
#判断前 max_match_len 个字符是否存在于字典
if sentence[0:max_match_len] in ch_dict:
segment_list.append(sentence[0:max_match_len]) #追加到分词词组中
sentence = sentence[max_match_len:len(sentence)] #将符合的词语从原例句中截取
break #退出循环重新从max_match_len最长匹配数开始匹配截取
max_match_len -= 1 #max_match_len累减开始匹配4个字符3个字符
#只剩下一个汉字时说明当前不再存在任何符合的词语直接截取一个汉字作为词组
if max_match_len == 1:
segment_list.append(sentence[0:1]) #追加单个汉字词语
sentence = sentence[1:len(sentence)] #截取例句
#输出存放分词的列表
print(segment_list)
#输出进行分词后的例句
print('/'.join(segment_list)) #我们/经常/有意见/分歧
运行结果
['我们', '经常', '有意见', '分歧']
我们/经常/有意见/分歧
Process finished with exit code 0
逆向最大匹配算法(Reverse Maximum MatchRMM)
算法主要思想
刚好与正向最大匹配算法相反该算法旨在从句子末尾对句子进行分词操作基本原理同正向最大匹配算法。
算法思想示意图

具体代码实现
'''
(分词算法)后向最大匹配算法
'''
if __name__ == '__main__':
ch_dict = ['我们','经常','有','有意见','意见','分歧'] #中文的词典库用于匹配句子中的词语
sentence = '我们经常有意见分歧' #例句需要进行分词
segment_list = [] #存放分词后的分词词组
#例句不为空时循环地进行分词操作
while len(sentence) >= 1:
# 最大匹配单词的长度为5当然实际意义从3开始即可因为词典最大单词长度为3
max_match_len = 5
#当匹配单词长度大于1时循环判断分词
while max_match_len > 1:
#判断前 max_match_len 个字符是否存在于字典
if sentence[-max_match_len:] in ch_dict:
segment_list.append(sentence[-max_match_len:]) #追加到分词词组中
sentence = sentence[:-max_match_len] #将符合的词语从原例句中截取
break #退出循环重新从max_match_len最长匹配数开始匹配截取
max_match_len -= 1 #max_match_len累减开始匹配4个字符3个字符
#只剩下一个汉字时说明当前不再存在任何符合的词语直接截取一个汉字作为词组
if max_match_len == 1:
segment_list.append(sentence[-1:]) #追加单个汉字词语
sentence = sentence[:-1] #截取例句
# 输出进行分词后的例句
print('/'.join(segment_list)) #分歧/有意见/经常/我们
#对分词列表进行倒序
segment_list = segment_list[::-1]
#再次输出进行分词后的例句
print('/'.join(segment_list)) # 我们/经常/有意见/分歧
运行结果
分歧/有意见/经常/我们
我们/经常/有意见/分歧
Process finished with exit code 0
双向最大匹配算法
算法的主要思想
双向最大匹配算法是同时采用正向最大匹配算法和逆向最大匹配算法根据对比不同的执行结果选择最优解。
有以下几种选择方案
- 如果分词数量结果不同选择数量较少的那个。
- 如果分词数量结果相同。
A. 分词结果相同返回任意一个。
B. 分词结果不同返回单个字数较少的一个。
C. 若单个字数也相同任意返回一个。
小结
最大匹配算法在简单场景往往能够发挥出较好的分词效果但其算法的时间复杂度较高理解中文歧义问题不够准确故存在一定的局限性仅作为低级的分词算法使用。
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |