

决策树应用
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
使用Python中的sklearn中自带的决策树分类器DecisionTreeClassifier
import sklearn
clf = sklearn.tree.DecisionTreeClassifier(criterion='entropy')
sklearn中只实现了ID3与CART决策树所以我们暂时只能使用这两种决策树在构造DecisionTreeClassifier类的时候其中一个参数criterion,是设置标准这里我们可以设置分类树采用那种算法进行构造我这里使用的是ID3分类树entropy,当然我们也可以使用CART分类树ginin.
- entropy: 基于信息熵也就是 ID3 算法实际结果与 C4.5 相差不大
- gini默认参数基于基尼系数。CART 算法是基于基尼系数做属性划分的所以 criterion=gini 时实际上执行的是 CART 算法。
应用流程
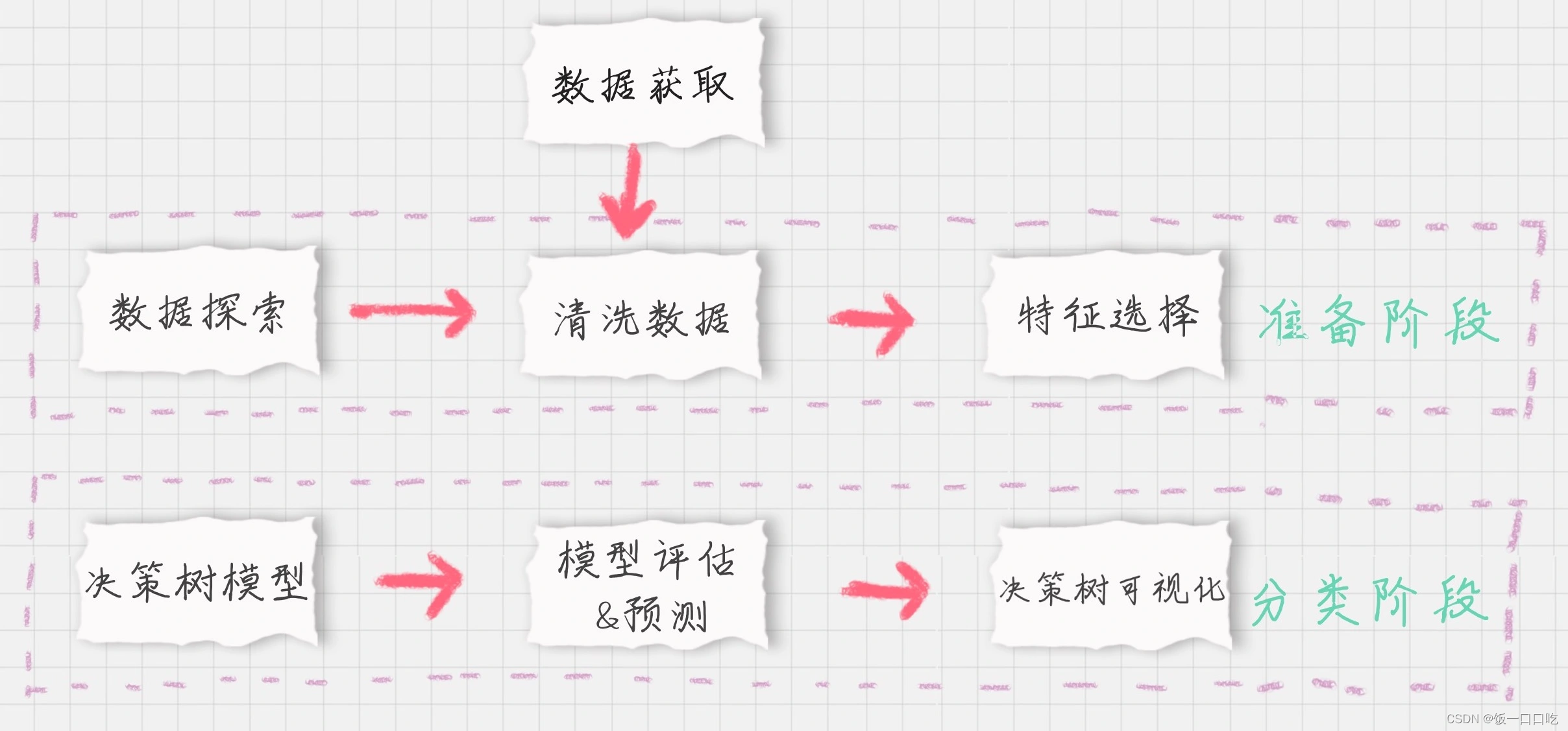
数据探索
python使用pandas
- 使用 info() 了解数据表的基本情况行数、列数、每列的数据类型、数据完整度
- 使用 describe() 了解数据表的统计情况总数、平均值、标准差、最小值、最大值等
- 使用 describe(include=[‘O’]) 查看字符串类型非数字的整体情况
- 使用 head 查看前几行数据默认是前 5 行
- 使用 tail 查看后几行数据默认是最后 5 行。
需要使用到两个文件这两个为泰坦尼克号的生存数据集
train.csvtest.csv
import pandas as pd
train_data = pd.read_csv('train.csv')
test_data = pd.read_csv('test.csv')
# 数据探索
# print(train_data.info())
# print('-'*30)
# print(train_data.describe())
# print('-'*30)
# # print(train_data.describe(include=['0']))
# # print('-'*30)
# print(train_data.head())
# print('-'*30)
# print(train_data.tail())
数据清洗
我们简单探索为响应数据发现AgeFare、Cabin这三个字段的数据有所缺失。其中Age为年龄字段是数值类型我们可以通过平均值帮助他进行补齐Fare为船票价格是数值类型我们也可以通过其他人购买的船票平均值给她进行补齐。
数据可视化展现
使用Graphviz进行数据可视化展现
全部完整代码
import pandas as pd
import numpy as np
from sklearn.feature_extraction import DictVectorizer
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import cross_val_score
from sklearn import tree
import graphviz
# 数据加载
train_data = pd.read_csv('D:/workspace/study/python/Titanic_Data/train.csv')
test_data = pd.read_csv('D:/workspace/study/python/Titanic_Data/test.csv')
# 数据探索
print(train_data.info())
print('-'*30)
print(train_data.describe())
print('-'*30)
print(train_data.describe(include=['O']))
print('-'*30)
print(train_data.head())
print('-'*30)
print(train_data.tail())
# 数据清洗
# 使用平均年龄来填充年龄中的 nan 值
train_data['Age'].fillna(train_data['Age'].mean(), inplace=True)
test_data['Age'].fillna(test_data['Age'].mean(), inplace=True)
# 使用票价的均值填充票价中的 nan 值
train_data['Fare'].fillna(train_data['Fare'].mean(), inplace=True)
test_data['Fare'].fillna(test_data['Fare'].mean(), inplace=True)
# 使用登录最多的港口来填充登录港口的 nan 值
train_data['Embarked'].fillna('S', inplace=True)
test_data['Embarked'].fillna('S', inplace=True)
# 特征选择
features = ['Pclass', 'Sex', 'Age', 'SibSp', 'Parch', 'Fare', 'Embarked']
train_features = train_data[features]
train_labels = train_data['Survived']
test_features = test_data[features]
dvec = DictVectorizer(sparse=False)
train_features = dvec.fit_transform(train_features.to_dict(orient='record'))
print(dvec.feature_names_)
# 决策树模型
# 构造 ID3 决策树
clf = DecisionTreeClassifier(criterion='entropy')
# 决策树训练
clf.fit(train_features, train_labels)
# 模型预测 & 评估
test_features=dvec.transform(test_features.to_dict(orient='record'))
# 决策树预测
pred_labels = clf.predict(test_features)
# 决策树准确率
acc_decision_tree = round(clf.score(train_features, train_labels), 6)
print(u'score 准确率为 %.4lf' % acc_decision_tree)
# K 折交叉验证统计决策树准确率
print(u'cross_val_score 准确率为 %.4lf' % np.mean(cross_val_score(clf, train_features, train_labels, cv=10)))
# 决策树可视化
dot_data = tree.export_graphviz(clf, out_file=None)
graph = graphviz.Source(dot_data)
graph.view()