

OpenCV #以图搜图:均值哈希算法(Average Hash Algorithm)原理与实验-CSDN博客
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
1. 介绍
均值哈希算法Average Hash Algorithm 是哈希算法的一种主要用来做相似图片的搜索工作。
2. 原理
均值哈希算法aHash首先将原图像缩小成一个固定大小的像素图像然后将图像转换为灰度图像通过缩小图像的每个像素与平均灰度值的比较生成一组哈希值。最后利用两组图像的哈希值的汉明距离来评估图像的相似度。
魔法 概括地讲均值哈希算法一共可细分六步
- 缩小图像 将目标图像缩小为一个固定的大小通常为8x8像素总共64个像素。作用是去除各种图像尺寸和图像比例的差异只保留结构、明暗等基本信息目的是确保图像的一致性降低计算的复杂度。
- 图像灰度化 将缩小的图像转换为灰度图像。
- 灰度平均值 计算灰度图像的平均灰度值。减少计算量。
- 比较平均值 遍历灰度图像的每个像素比较每个像素的灰度值是否大于或小于平均值。对于大于等于平均值的像素将其表示为1对于小于平均值的像素将其表示为0。最后得到一个64位的二进制值8x8像素的图像。
- 生成哈希值 由于64位二进制值太长所以按每4个字符为1组由2进制转成16进制。这样就转为一个长度为16的字符串。这个字符串也就是这个图像可识别的哈希值也叫图像指纹即这个图像所包含的特征。
- 哈希值比较 通过比较两个图像的哈希值的汉明距离Hamming Distance就可以评估图像的相似度距离越小表示图像越相似。
3. 实验
第一步缩小图像
将目标图像缩小为一个固定的大小通常为8x8像素总共64个像素。作用是去除各种图像尺寸和图像比例的差异只保留结构、明暗等基本信息目的是确保图像的一致性降低计算的复杂度。
1读取原图
# 测试图片路径
img_path = 'img_test/apple-01.jpg'
# 通过OpenCV加载图像
img = cv2.imread(img_path)
# 通道重排从BGR转换为RGB
img_rgb = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
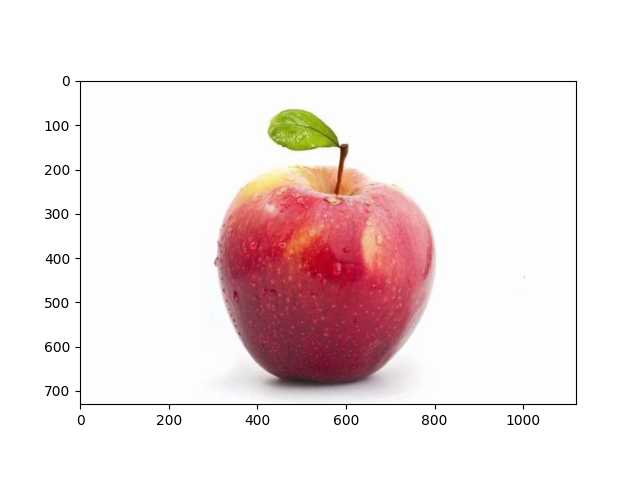
2缩小原图
# 缩小图像使用OpenCV的resize函数将图像缩放为8x8像素采用Cubic插值方法进行图像重采样
img_resize = cv2.resize(img, (8, 8), cv2.INTER_CUBIC)
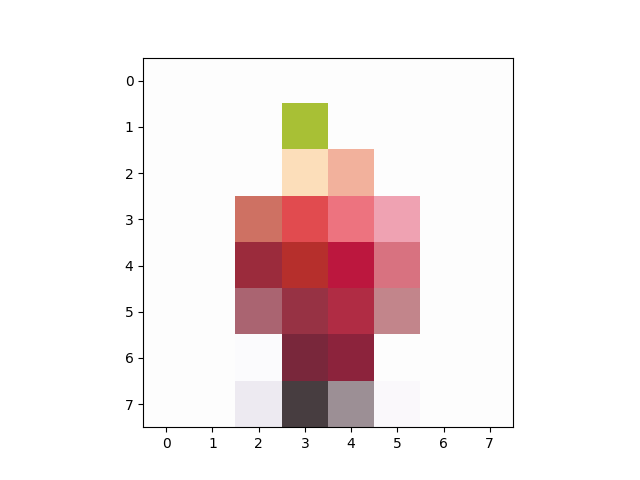
OpenCV 的 cv2.resize() 函数提供了4种插值方法以根据图像的尺寸变化来进行图像重采样。
- cv2.INTER_NEAREST 最近邻插值也称为最近邻算法。它简单地使用最接近目标像素的原始像素的值。虽然计算速度快但可能导致图像质量下降。
- cv2.INTER_LINEAR 双线性插值通过对最近的4个像素进行线性加权来估计目标像素的值。比最近邻插值更精确但计算成本略高。
- cv2.INTER_CUBIC 双三次插值使用16个最近像素的加权平均值来估计目标像素的值。通常情况下这是一个不错的插值方法适用于图像缩小。
- cv2.INTER_LANCZOS4 Lanczos插值一种高质量的插值方法使用Lanczos窗口函数。通常用于缩小图像以保留图像中的细节和纹理。
第二步图像灰度化
将缩小的图像转换为灰度图像。也就是说所有像素点总共只有64种灰度颜色。
# 图像灰度化将彩色图像转换为灰度图像。
img_gray = cv2.cvtColor(img_resize, cv2.COLOR_BGR2GRAY)
print(f"缩放8x8的图像中每个像素的颜色=\n{img_gray}")
输出打印
缩放8x8的图像中每个像素的颜色=
[[253 253 253 253 253 253 253 253]
[253 253 253 148 253 253 253 253]
[253 253 253 215 178 253 253 253]
[253 253 119 93 132 176 253 253]
[253 253 61 61 53 130 253 253]
[253 253 112 67 66 142 253 253]
[253 253 252 54 54 253 253 253]
[253 253 236 63 146 249 253 253]]

第三步灰度平均值
计算灰度图像的平均灰度值。减少计算量。
img_average = np.mean(img_gray)
print(f"灰度图像中所有像素的平均值={img_average}")
输出打印
灰度图像中所有像素的平均值=209.890625
第四步比较平均值
遍历灰度图像的每个像素比较每个像素的灰度值是否大于或小于平均值。对于大于等于平均值的像素将其表示为1对于小于平均值的像素将其表示为0。最后得到一组长64位的二进制字符串8x8像素的图像。因为对于机器而言只认识0和1所以这组64位的二进制就可以表示这张图像的结构和亮度分布。
# 遍历图像像素嵌套循环遍历图像的所有像素对比灰度图像的平均灰度值转换为二进制的图像哈希值
img_hash_binary = []
for i in range(img_gray.shape[0]):
for j in range(img_gray.shape[1]):
if img_gray[i,j] >= img_average:
img_hash_binary.append(1)
else:
img_hash_binary.append(0)
print(f"对比灰度图像的平均像素值降噪图像的二进制哈希值数组={img_hash_binary}")
# 将列表中的元素转换为字符串并连接起来形成一组64位的图像二进制哈希值字符串
img_hash_binary_str = ''.join(map(str, img_hash_binary))
print(f"对比灰度图像的平均像素值降噪图像的二进制哈希值={img_hash_binary_str}")
代码分解和含义如下
- 初始化空列表创建一个空的列表 img_hash_binary用于存储图像的哈希值。
- 遍历图像像素嵌套循环遍历图像的所有像素其中 img_gray 是输入的灰度图像img_gray.shape[0] 和 img_gray.shape[1] 分别表示图像的高度和宽度。
- 计算平均值代码中使用变量 img_average 存储了一个平均值用于与图像像素的灰度值进行比较。
- 根据亮度值生成哈希值对于每个像素代码比较像素的灰度值与平均值 (img_gray[i, j] >= img_average)。如果像素的灰度值大于或等于平均值就将数字1添加到 img_hash_binary 列表中表示该像素是亮的。如果像素的灰度值小于平均值就将数字0添加到 img_hash_binary 列表中表示该像素是暗的。
- 最终哈希值完成循环后img_hash_binary 列表将包含图像的二进制哈希值其中每个元素代表一个像素的明暗情况。
输出打印
对比灰度图像的平均像素值降噪图像的二进制形式数组=[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 1, 1, 1, 1, 1, 1, 1, 1, 0, 1, 1, 1, 1, 1, 0, 0, 0, 0, 1, 1, 1, 1, 0, 0, 0, 0, 1, 1, 1, 1, 0, 0, 0, 0, 1, 1, 1, 1, 1, 0, 0, 1, 1, 1, 1, 1, 1, 0, 0, 1, 1, 1]
对比灰度图像的平均像素值降噪图像的二进制形式=1111111111101111111101111100001111000011110000111110011111100111
或者使用等价的 lambda 表达式。效果一样。
# lambda表达式
img_hash_binary_str = ""
for i in range(8):
img_hash_binary_str += ''.join(map(lambda i: '0' if i < img_average else '1', img_gray[i]))
print(f"对比灰度图像的平均像素值降噪图像的二进制哈希值={img_hash_binary_str}")
输出打印
对比灰度图像的平均像素值降噪图像的二进制形式=1111111111101111111101111100001111000011110000111110011111100111
第五步生成哈希值
由于64位二进制值太长所以按每4个字符为1组由2进制转成16进制。这样就转为一个长度为16的字符串。这个字符串也就是这个图像可识别的哈希值也叫图像指纹即这个图像所包含的特征。
img_hash = ""
for i in range(0, 64, 4):
img_hash += "".join('%x' % int(img_hash_binary_str[i : i + 4], 2))
print(f"图像可识别的哈希值={img_hash}")
代码分解和含义如下
- 初始化为空字符串创建一个空的字符串 img_hash用于存储图像哈希值的十六进制表示。
- 遍历二进制哈希值通过循环代码以4位为一组遍历二进制哈希值 img_hash_binary_str。range(0, 64, 4) 确保代码在哈希值的每4位之间进行迭代。
- 将4位二进制转换为一个十六进制字符在每次循环中代码取出哈希值中的4位二进制例如img_hash_binary_str[i : i + 4]然后使用’%x’ % int(…, 2) 将这4位二进制转换为一个十六进制字符。int(…, 2) 将二进制字符串转换为整数‘%x’ 将整数转换为十六进制字符。
- 将十六进制字符追加到 img_hash在每次循环中得到的十六进制字符将被追加到 img_hash 字符串中。
- 最终哈希值完成循环后img_hash 将包含图像哈希值的十六进制表示其中每个字符表示4位二进制。
输出打印
图像可识别的哈希值=ffeff7c3c3c3e7e7
第六步哈希值比较
通过比较两个图像的哈希值的汉明距离Hamming Distance就可以评估图像的相似度距离越小表示图像越相似。
def hamming_distance(s1, s2):
# 检查这两个字符串的长度是否相同。如果长度不同它会引发 ValueError 异常因为汉明距离只适用于等长的字符串
if len(s1) != len(s2):
raise ValueError("Input strings must have the same length")
distance = 0
for i in range(len(s1)):
# 遍历两个字符串的每个字符比较它们在相同位置上的值。如果发现不同的字符将 distance 的值增加 1
if s1[i] != s2[i]:
distance += 1
return distance
4. 测试
我们来简单测试一下基于均值哈希算法的以图搜图 – 基于一张原图找最相似图片看看效果如何。
这里我准备了10张图片其中9张是苹果但形态不一1张是梨子。
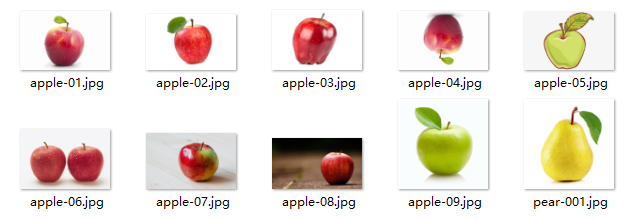
输出打印
图片名称img_test/apple-01.jpg图片HASHffeff7c3c3c3e7e7与图片1的近似值汉明距离0
图片名称img_test/apple-02.jpg图片HASHffcfc3e3e3e3e7ff与图片1的近似值汉明距离8
图片名称img_test/apple-03.jpg图片HASHffe7c3c3c3c7c7ff与图片1的近似值汉明距离7
图片名称img_test/apple-04.jpg图片HASHe7e7c3c3c3eff7ff与图片1的近似值汉明距离10
图片名称img_test/apple-05.jpg图片HASHf3f3e7c7c3c7c7e7与图片1的近似值汉明距离7
图片名称img_test/apple-06.jpg图片HASHffffd981818189dd与图片1的近似值汉明距离13
图片名称img_test/apple-07.jpg图片HASHfff7f3e3e3e3f0ff与图片1的近似值汉明距离10
图片名称img_test/apple-08.jpg图片HASH000006fdf171f9f8与图片1的近似值汉明距离16
图片名称img_test/apple-09.jpg图片HASHffcfe7c1c1c3e7ff与图片1的近似值汉明距离6
图片名称img_test/pear-001.jpg图片HASHfffbe5c1c3c3c3ef与图片1的近似值汉明距离8
耗时0.09571695327758789
汉明距离两个长度相同的字符串在相同位置上的字符不同的个数。

简单的测试分析
| 原图 | 相似图片 | 相似值汉明距离 | 相似图片特点 | 相似图片与原图Hash对比结果 |
|---|---|---|---|---|
| 图片01 | 图片01 | 0 | 自己 | 自己与自己相似度100% |
| 图片01 | 图片09 | 6 | 青苹果 | 最相似。相同背景相同物体位置下最相似。 |
| 图片01 | 图片03、图片05 | 7 | 红蛇果苹果、青苹果2D | 次相似。同上单物体对比时背景、物体位置越近越相似。 |
| 图片01 | 图片02 | 8 | 两者几乎相似 | 比较相似。影响相似距离的似乎是苹果下方的阴影有无。 |
| 图片01 | 图片pear-001 | 8 | 黄色的梨子 | 意外相似。相似搜索并不能识别物体/内容因为工作原理是通过图片灰度后的灰色像素点位置与对比。 |
| 图片01 | 图片04 | 10 | 原图像的180度旋转图 | 相差甚远。对于原图旋转变换相对不敏感因为均值哈希算法只捕获了图像的平均亮度和粗略结构。 |
| 图片01 | 图片06、07、08 | 10以上 | 复杂、多主体、多色调 | 较难分辨。复杂、多主体、多色调的图片较难与原图相似。 |
10张测试图片中汉明距离在5以内1张汉明距离在5以外9张。
从抽样简单测试结果看平均哈希简单且计算速度快但它对图像的细节变化比较敏感容易受到局部图像的特性的干扰。
备注如果汉明距离0则表示这两张图片非常相似如果汉明距离小于5则表示有些不同但比较相近如果汉明距离大于10则表明是完全不同的图片。
5. 总结
经过实验和测试平均哈希算法优缺点明显。
特点 传统
优点 简单、计算效率高适用于快速图像相似性比较。
缺点 对于图片的旋转和主体内容变换相对不敏感对于复杂、多主体、多色调的图片较难相似因为它只捕获了图片的平均亮度和粗略结构。
6. 实验代码
"""
以图搜图均值哈希算法Average Hash Algorithm的原理与实现
测试环境win10 | python 3.9.13 | OpenCV 4.4.0 | numpy 1.21.1
实验时间2023-10-20
"""
import cv2
import time
import numpy as np
import matplotlib.pyplot as plt
def get_hash(img_path):
# 读取图像通过OpenCV的imread加载图像
# 缩小图像使用OpenCV的resize函数将图像缩放为8x8像素采用Cubic插值方法进行图像重采样
img_rgb = cv2.cvtColor(cv2.imread(img_path), cv2.COLOR_BGR2RGB)
# 使用OpenCV的resize函数将图像缩放为8x8像素采用Cubic插值方法进行图像重采样
img_resize = cv2.resize(img_rgb, (8, 8), cv2.INTER_CUBIC)
# 图像灰度化将彩色图像转换为灰度图像。较少计算量。
img_gray = cv2.cvtColor(img_resize, cv2.COLOR_BGR2GRAY)
# print(f"缩放8x8的图像中每个像素的颜色=\n{img_gray}")
# 灰度平均值计算灰度图像的平均灰度值
img_average = np.mean(img_gray)
# print(f"灰度图像中所有像素的平均值={img_average}")
"""
# # 比较平均值嵌套循环遍历图像的所有像素对比灰度图像的平均灰度值转换为二进制的图像哈希值
# # img_gray是灰度图像
# # img_gray.shape[0] 和 img_gray.shape[1] 分别表示图像的高度和宽度
# img_hash_binary = []
# for i in range(img_gray.shape[0]):
# for j in range(img_gray.shape[1]):
# if img_gray[i,j] >= img_average:
# img_hash_binary.append(1)
# else:
# img_hash_binary.append(0)
# print(f"对比灰度图像的平均像素值降噪图像的二进制哈希值数组={img_hash_binary}")
# # 将列表中的元素转换为字符串并连接起来形成一组64位的图像二进制哈希值字符串
# img_hash_binary_str = ''.join(map(str, img_hash_binary))
# print(f"对比灰度图像的平均像素值降噪图像的二进制哈希值={img_hash_binary_str}")
# # 生成哈希值
# img_hash = ""
# # 遍历二进制哈希值通过循环代码以4位为一组遍历二进制哈希值 img_hash_binary_str。
# # range(0, 64, 4) 确保代码在哈希值的每4位之间进行迭代。
# for i in range(0, 64, 4):
# # 将4位二进制转换为一个十六进制字符
# # 在每次循环中代码取出哈希值中的4位二进制例如img_hash_binary_str[i : i + 4]
# # 然后使用'%x' % int(..., 2)将这4位二进制转换为一个十六进制字符。
# # int(..., 2)将二进制字符串转换为整数'%x'将整数转换为十六进制字符。
# # 将十六进制字符追加到 img_hash在每次循环中得到的十六进制字符将被追加到 img_hash 字符串中。
# img_hash += "".join('%x' % int(img_hash_binary_str[i : i + 4], 2))
# print(f"图像可识别的哈希值={img_hash}")
"""
# 图像二进制哈希值
img_hash_binary_str = ''
for i in range(8):
img_hash_binary_str += ''.join(map(lambda i: '0' if i < img_average else '1', img_gray[i]))
# print(f"对比灰度图像的平均像素值降噪图像的二进制哈希值={img_hash_binary_str}")
# 图像可识别哈希值
img_hash = ''.join(map(lambda x:'%x' % int(img_hash_binary_str[x : x + 4], 2), range(0, 64, 4)))
# print(f"图像可识别的哈希值={img_hash}")
return img_hash
# 汉明距离计算两个等长字符串通常是二进制字符串或位字符串之间的汉明距离。用于确定两个等长字符串在相同位置上不同字符的数量。
def hamming_distance(s1, s2):
# 检查这两个字符串的长度是否相同。如果长度不同它会引发 ValueError 异常因为汉明距离只适用于等长的字符串
if len(s1) != len(s2):
raise ValueError("Input strings must have the same length")
distance = 0
for i in range(len(s1)):
# 遍历两个字符串的每个字符比较它们在相同位置上的值。如果发现不同的字符将 distance 的值增加 1
if s1[i] != s2[i]:
distance += 1
return distance
# --------------------------------------------------------- 测试 ---------------------------------------------------------
time_start = time.time()
img_1 = 'img_test/apple-01.jpg'
img_2 = 'img_test/apple-02.jpg'
img_3 = 'img_test/apple-03.jpg'
img_4 = 'img_test/apple-04.jpg'
img_5 = 'img_test/apple-05.jpg'
img_6 = 'img_test/apple-06.jpg'
img_7 = 'img_test/apple-07.jpg'
img_8 = 'img_test/apple-08.jpg'
img_9 = 'img_test/apple-09.jpg'
img_10 = 'img_test/pear-001.jpg'
img_hash1 = get_hash(img_1)
img_hash2 = get_hash(img_2)
img_hash3 = get_hash(img_3)
img_hash4 = get_hash(img_4)
img_hash5 = get_hash(img_5)
img_hash6 = get_hash(img_6)
img_hash7 = get_hash(img_7)
img_hash8 = get_hash(img_8)
img_hash9 = get_hash(img_9)
img_hash10 = get_hash(img_10)
distance1 = hamming_distance(img_hash1, img_hash1)
distance2 = hamming_distance(img_hash1, img_hash2)
distance3 = hamming_distance(img_hash1, img_hash3)
distance4 = hamming_distance(img_hash1, img_hash4)
distance5 = hamming_distance(img_hash1, img_hash5)
distance6 = hamming_distance(img_hash1, img_hash6)
distance7 = hamming_distance(img_hash1, img_hash7)
distance8 = hamming_distance(img_hash1, img_hash8)
distance9 = hamming_distance(img_hash1, img_hash9)
distance10 = hamming_distance(img_hash1, img_hash10)
time_end = time.time()
print(f"图片名称{img_1}图片HASH{img_hash1}与图片1的近似值汉明距离{distance1}")
print(f"图片名称{img_2}图片HASH{img_hash2}与图片1的近似值汉明距离{distance2}")
print(f"图片名称{img_3}图片HASH{img_hash3}与图片1的近似值汉明距离{distance3}")
print(f"图片名称{img_4}图片HASH{img_hash4}与图片1的近似值汉明距离{distance4}")
print(f"图片名称{img_5}图片HASH{img_hash5}与图片1的近似值汉明距离{distance5}")
print(f"图片名称{img_6}图片HASH{img_hash6}与图片1的近似值汉明距离{distance6}")
print(f"图片名称{img_7}图片HASH{img_hash7}与图片1的近似值汉明距离{distance7}")
print(f"图片名称{img_8}图片HASH{img_hash8}与图片1的近似值汉明距离{distance8}")
print(f"图片名称{img_9}图片HASH{img_hash9}与图片1的近似值汉明距离{distance9}")
print(f"图片名称{img_10}图片HASH{img_hash10}与图片1的近似值汉明距离{distance10}")
print(f"耗时{time_end - time_start}")
7. 疑难杂症
问题1 为什么通过 cv2.imread(img_path) 加载的图像显示出来之后原图由红色变成了蓝色
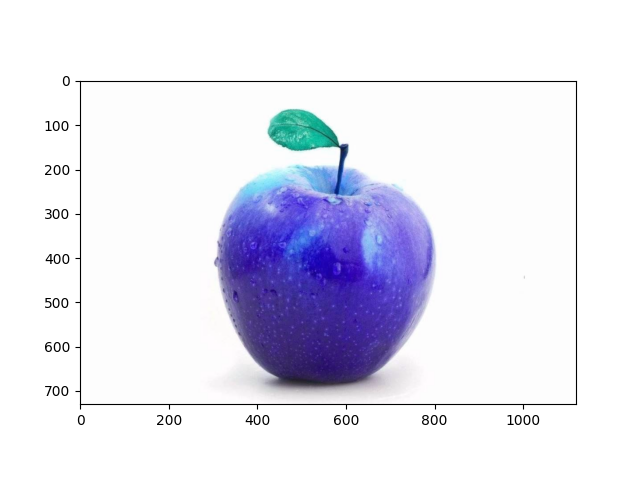
问题原因 如果原图是红色的但通过OpenCV加载显示的图像是蓝色的这可能是由于图像的通道顺序不同导致的。在OpenCV中图像的通道顺序通常是BGR蓝绿红而在一些其他库如matplotlib中通常使用RGB红绿蓝通道顺序。
解决方案 使用OpenCV的通道重排功能将图像的通道顺序从BGR转换为RGB然后再显示图像。以下是修改后的代码
# 通过OpenCV加载图像
img = cv2.imread(img_path)
# 通道重排从BGR转换为RGB
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
问题2 为什么使用了 cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) 但显示出来图像是彩色的
问题原因 这可能是由于你使用了 matplotlib 来显示图像而 matplotlib 默认将灰度图像显示为伪彩色图像。Matplotlib会将单通道的灰度图像每个像素只有一个亮度值显示为伪彩色图像以便于可视化。
解决方案 在使用 imshow 函数显示图像时添加 cmap 参数并将其设置为 ‘gray’以确保图像以灰度形式显示。例如
# 测试图片路径
img_path = 'img_test/apple-01.jpg'
# 通过OpenCV加载图像
img = cv2.imread(img_path)
# 通道重排从BGR转换为RGB
img_rgb = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# 使用OpenCV的resize函数将图像缩放为8x8像素采用Cubic插值方法
img_resize = cv2.resize(img_rgb, (8, 8), cv2.INTER_CUBIC)
# 灰度化将彩色图像转换为灰度图像。
img_gray = cv2.cvtColor(img_resize, cv2.COLOR_BGR2GRAY)
# 灰度形式查看图像
plt.imshow(img_gray, cmap='gray')
# 显示图像
plt.show()
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |