

大数据技术之Hadoop集群配置
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |

作者简介大家好我是小唐同学(๑><๑好久不见为梦想而努力的小唐又回来了让我们一起加油
个人主页小唐同学(๑><๑的博客主页
目前再学习大数据现在在初级阶段-刚学Hadoop若有错误请指正

目录
一集群部署规划
1NameNode和SecondaryNameNode不要安装在同一台服务器
2ResourceManager也很消耗内存不要和NameNode,SecondaryNamenode配置在同一台机器上
二配置文件说明
置文件和自定义配置文件
1默认配置文件有四种对应Hadoop的四大组件

2自定义配置文件
core-site.xml , hdfs-site.xml , yarn-site.xml , mapred-site.xml
这四个配置文件存放在$HADOOP_HOME/etc/hadoop这个路径上用户可以根据项目需求重新进行修改配置。$HADOOP_HOME为Hadoop的安装路径



三配置集群
1配置核心文件
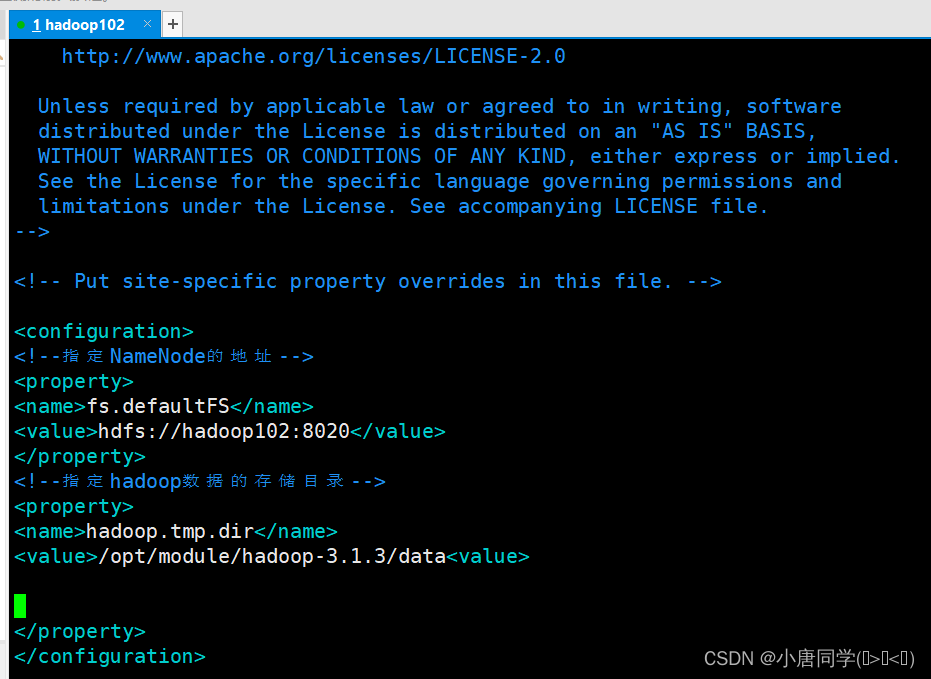
配置core-site.xml
<configuration>
<!--指定NameNode的地址-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop102:8020</value>
</property>
<!--指定hadoop数据的存储目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-3.1.3/data<value>
</property>
</configuration>
配置hdfs-site.xml
<configuration>
<!--nn web fangwen dizhi -->
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop102:9870</value>
</property>
<!--2nn web fangwen dizhi -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop104:9868</value>
</property>
</configuration>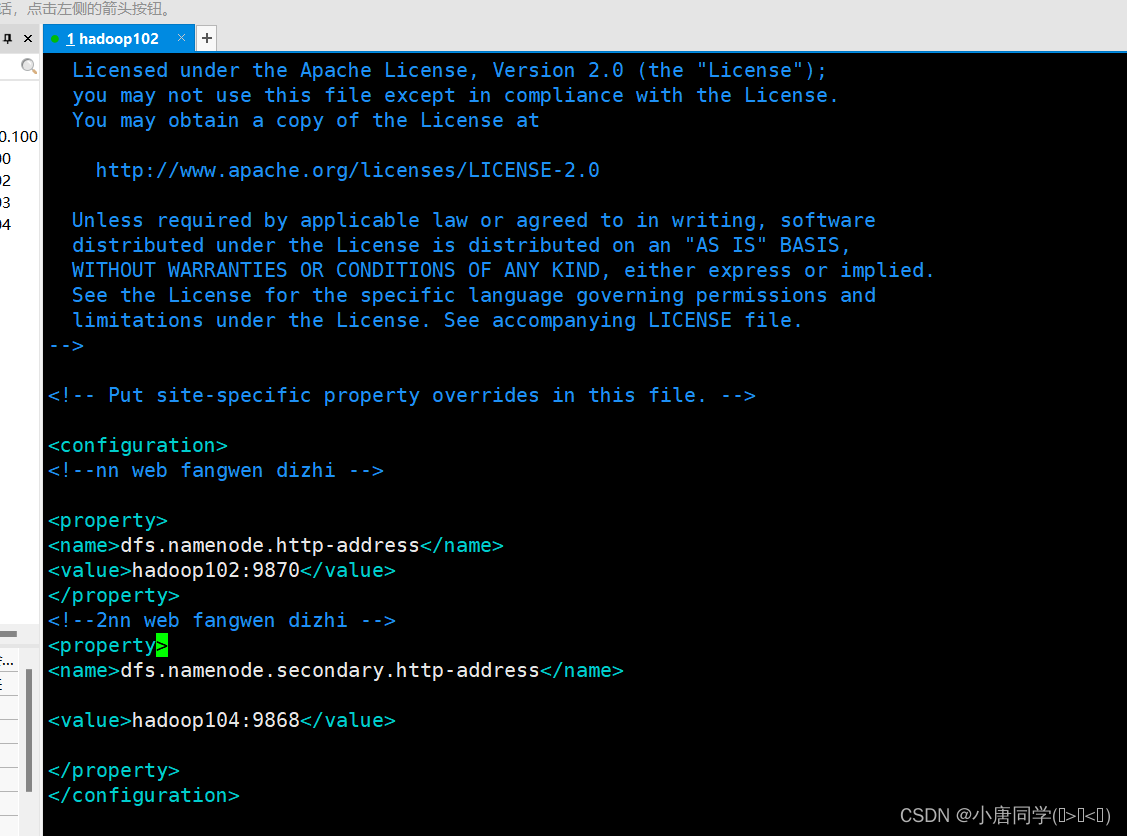
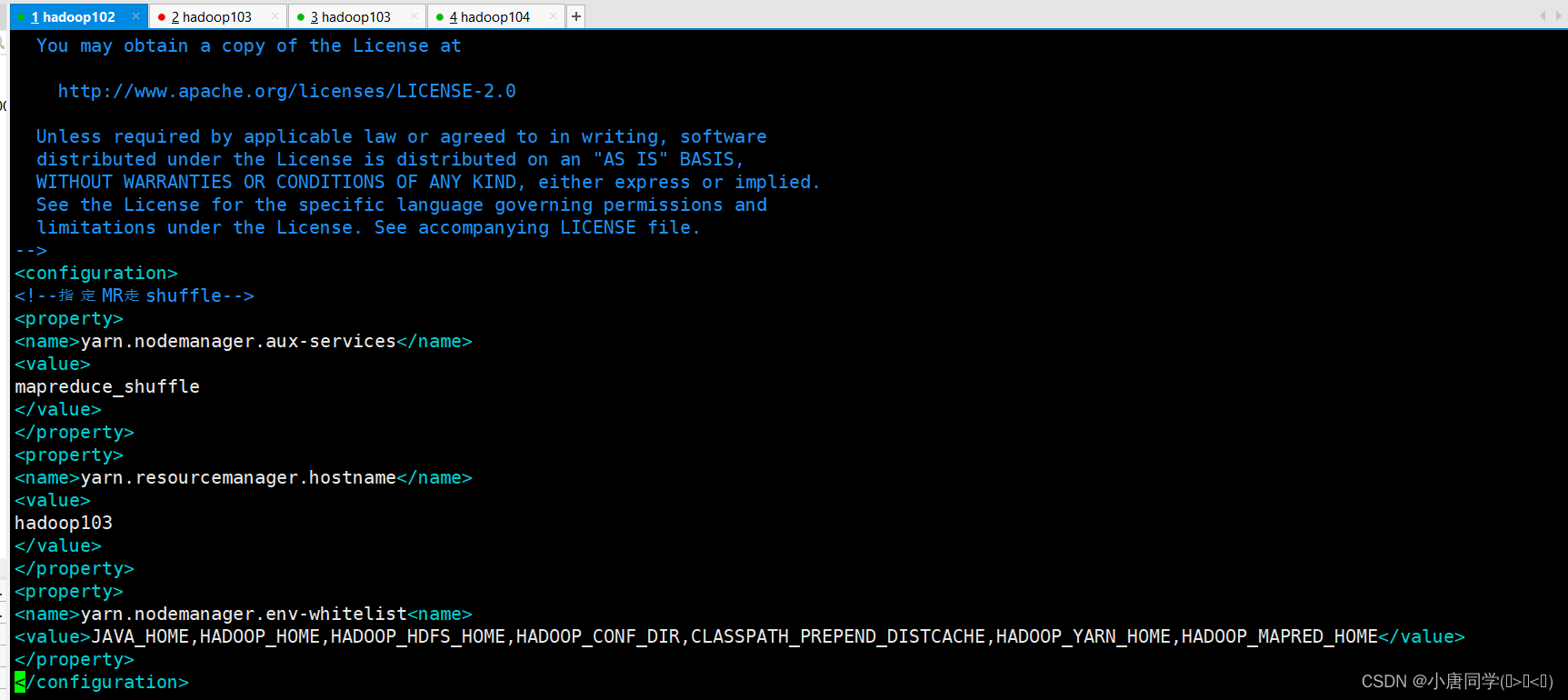
<configuration>
<!--指定MR走shuffle-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>
mapreduce_shuffle
</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>
hadoop103
</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist<name>
<value>JAVA_HOME,HADOOP_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
</configuration>
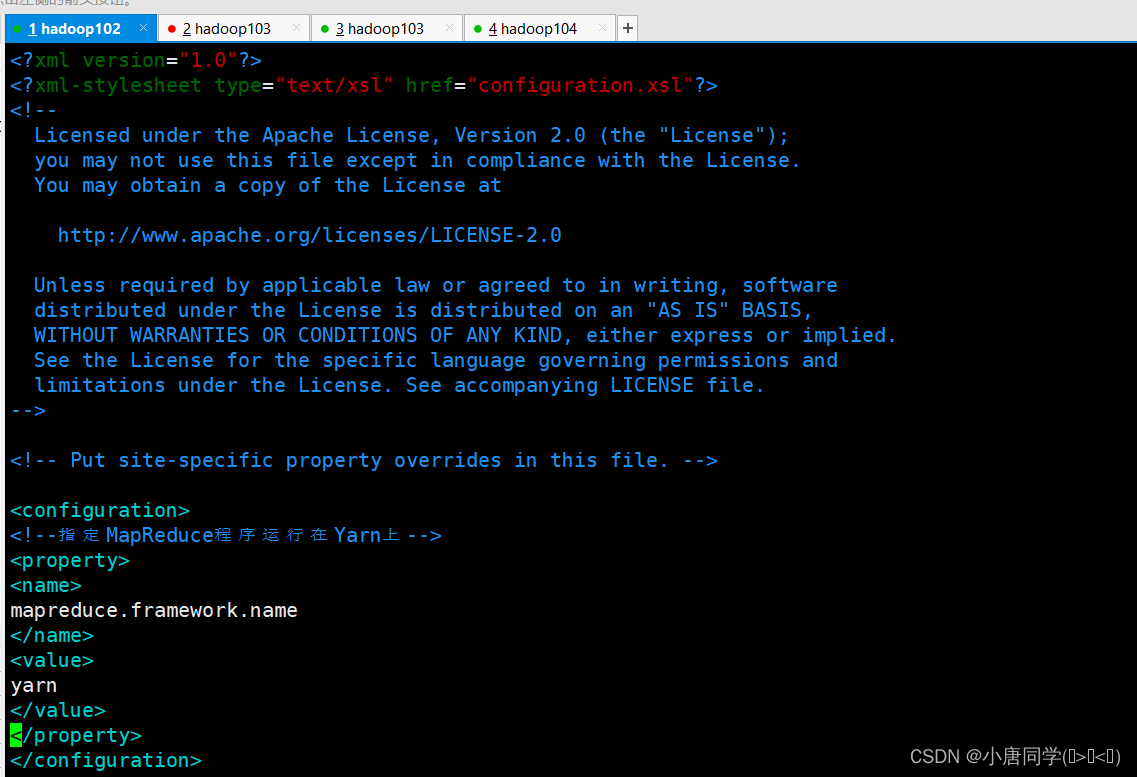
<configuration>
<!--指定MapReduce程序运行在Yarn上-->
<property>
<name>
mapreduce.framework.name
</name>
<value>
yarn
</value>
</property>
</configuration>
配置完成后在集群上分发配置好的Hadoop配置文件
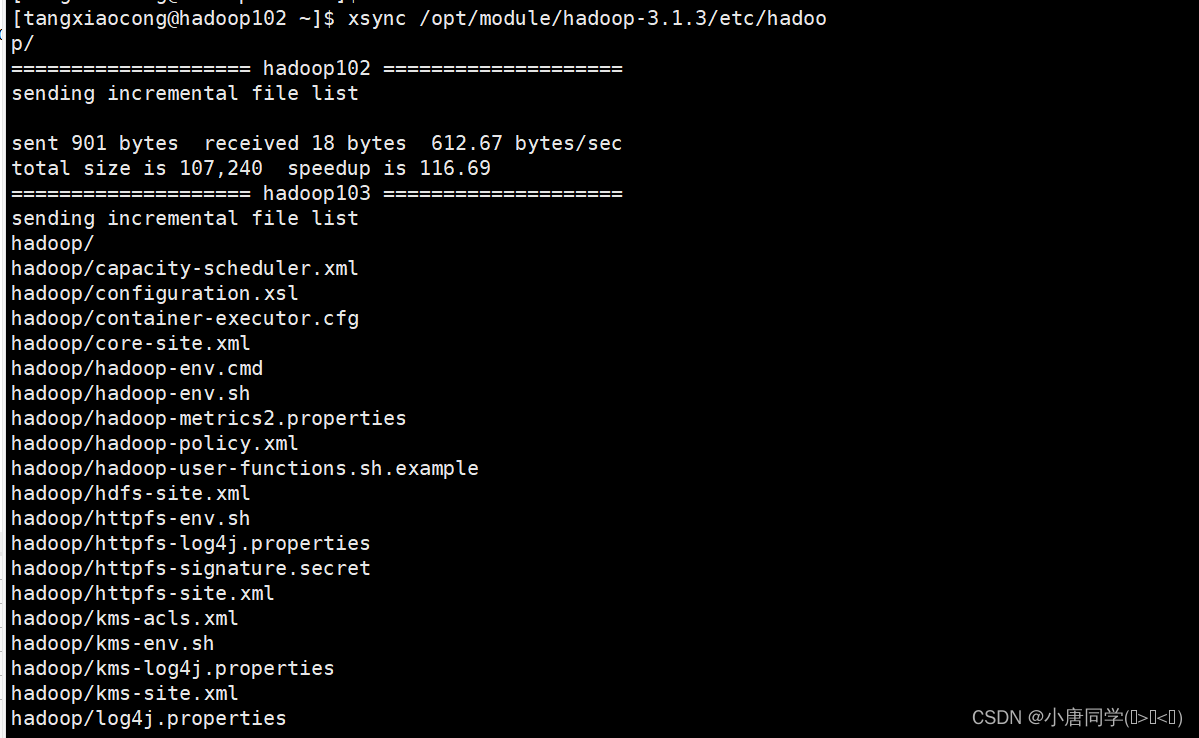
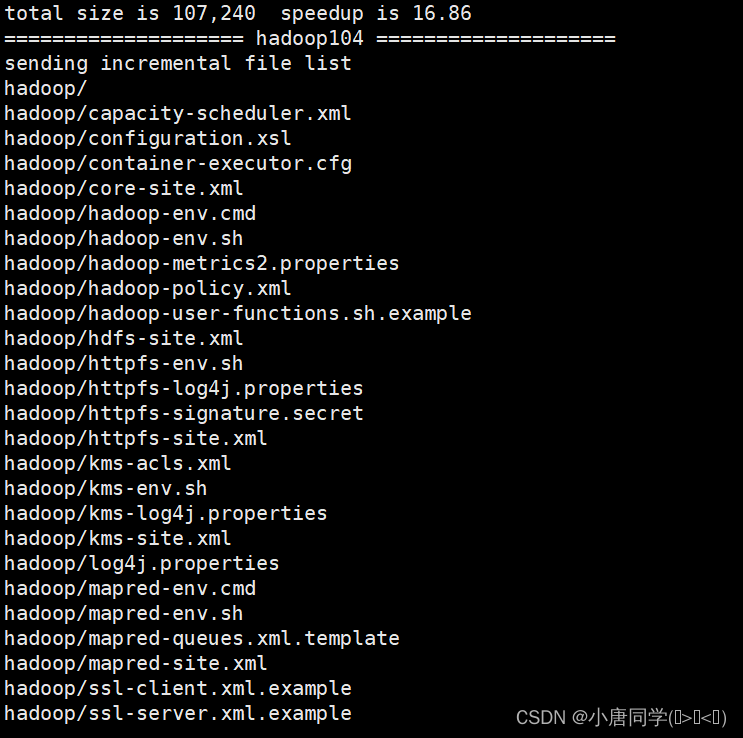
上述集群配置完成后在群起集群之前需要配置workers文件

先切换到Hadoop的目录下
cd /opt/module/hadoop-3.1.3
切换到Hadoop的文件夹下
cd etc/hadoop/vim workers上述命令进入workers文件下文件不允许有空格和空行
有几个节点就配置几个名称
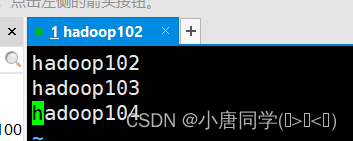
配置完毕后需要分发一下 分别配置给其他集群内部的服务器
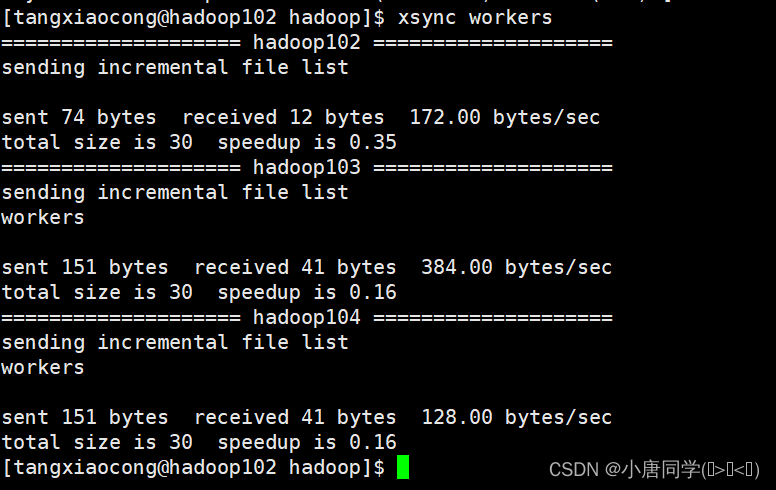
四格式化节点
1如果集群是第一次启动需要初始化格式化NameNode,在格式化的过程中我遇到了报错通过阅读报错信息重新配置了四个自定义配置文件建议报错先认真阅读
hdfs namenode -format
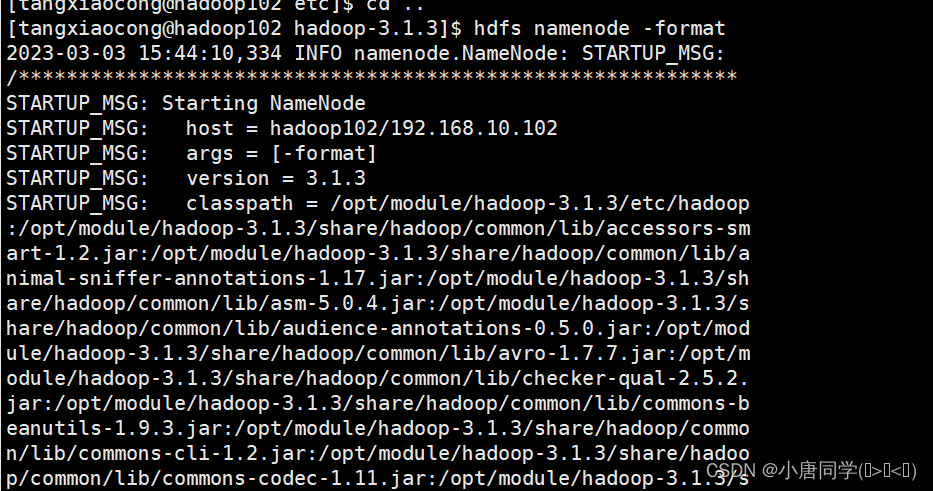
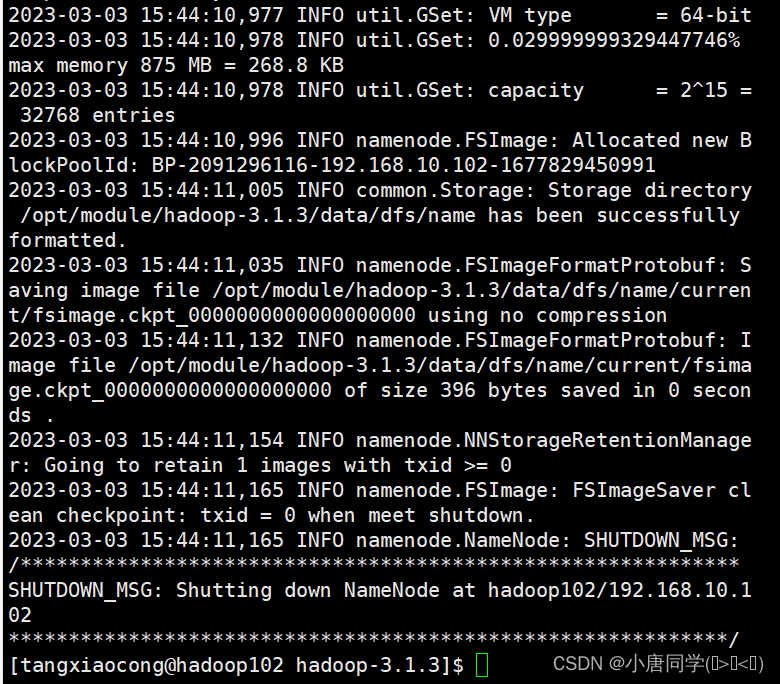
上述格式化完成
五启动集群
启动集群在sbin目录下在Hadoop的安装目录下

启动HDFS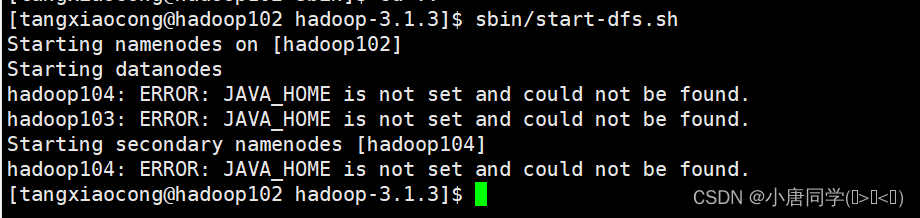
启动完毕后用命令jps(jps命令在Hadoop的安装路径下执行是java提供的一个显示当前所有java进程pid的命令)
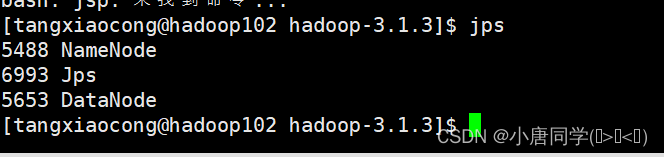


可以看到跟我们的集群规划相同
搜索 hadoop102:9870可以看到hdfs存储的数据信息
在配置了ResourceManager的节点hadoop103启动YARN

可以看到三个进程符合集群规划

搜素 hadoop103:8088可以看到yarn的资源调度网页
六测试集群
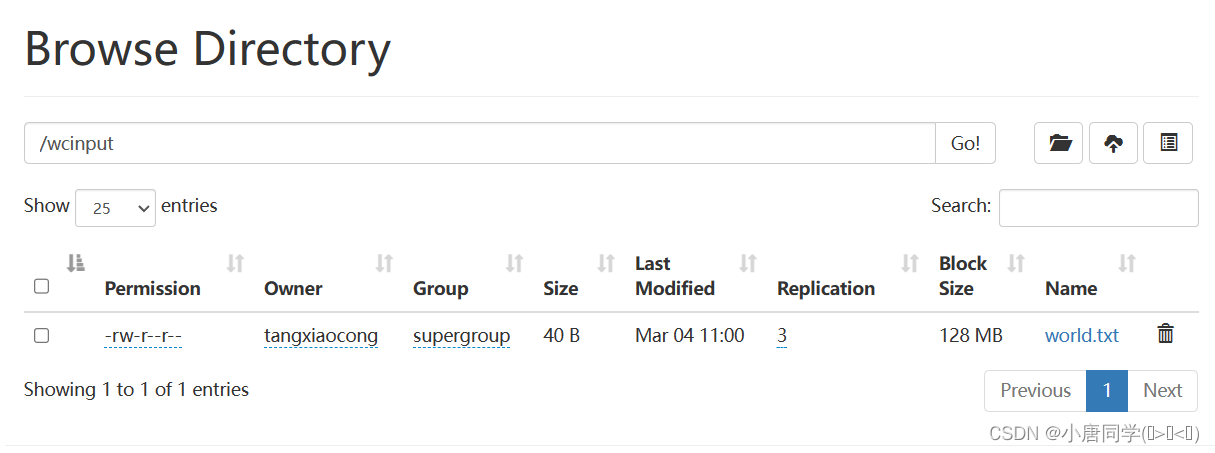
上传文件到集群
1上传小文件

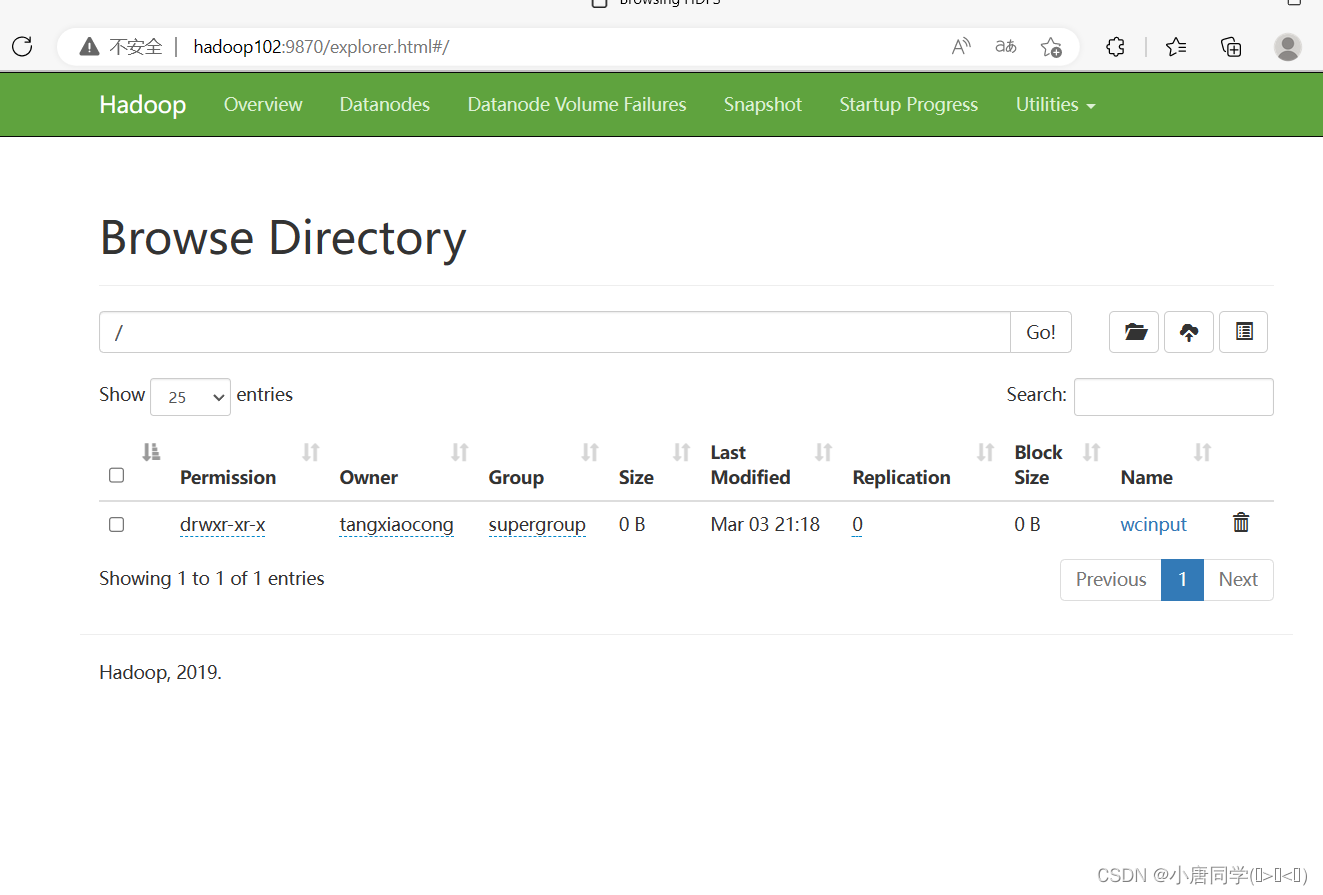
上传带内容的文件到wcinput


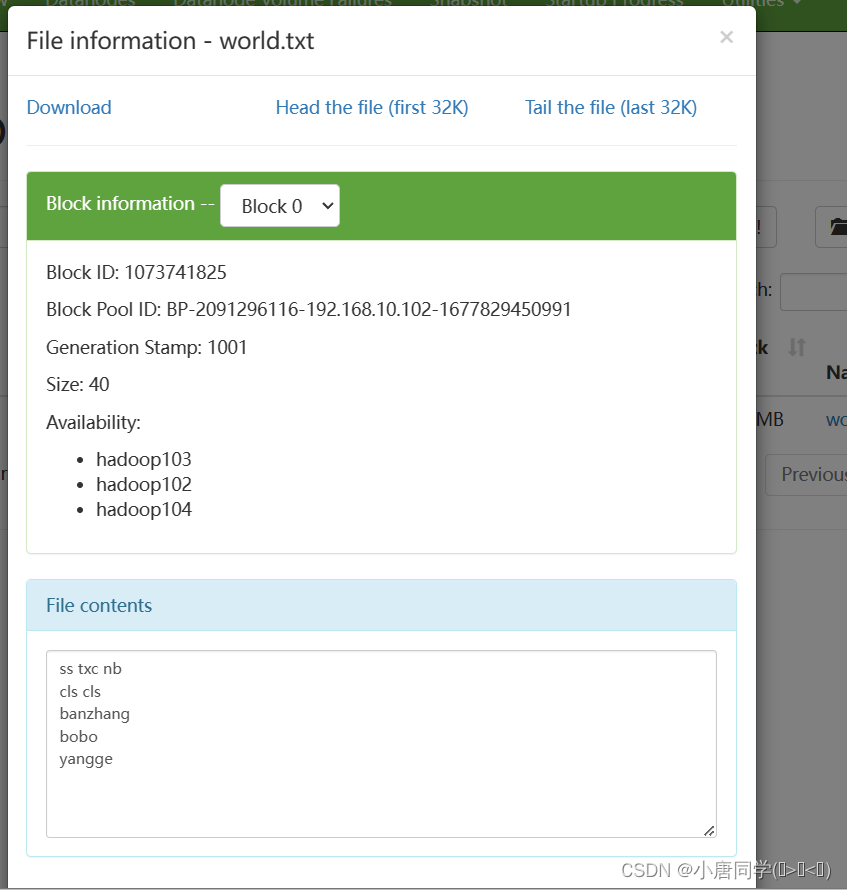
(2)上传大文件

回到根部录下可以看到有添加的数据但是这只是个链接方便展示实际存储在datanode节点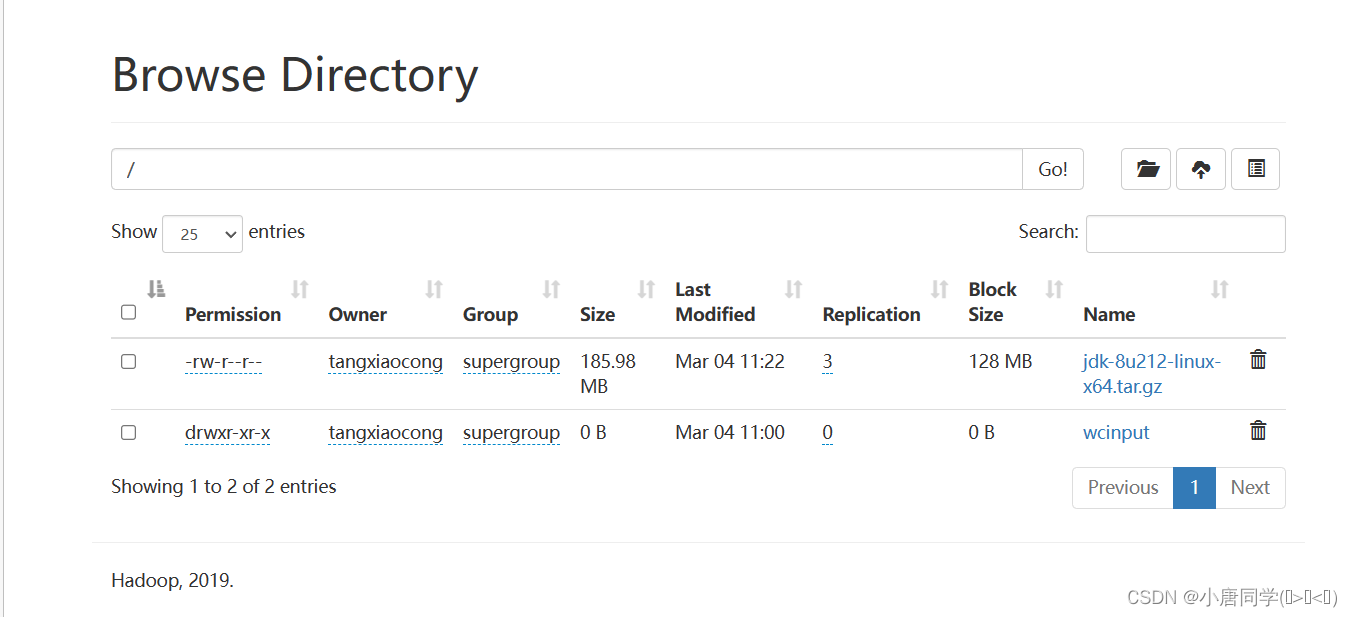

刚开始初始化节点的时候只有name现在存入数据后出现了data
数据存储的目录
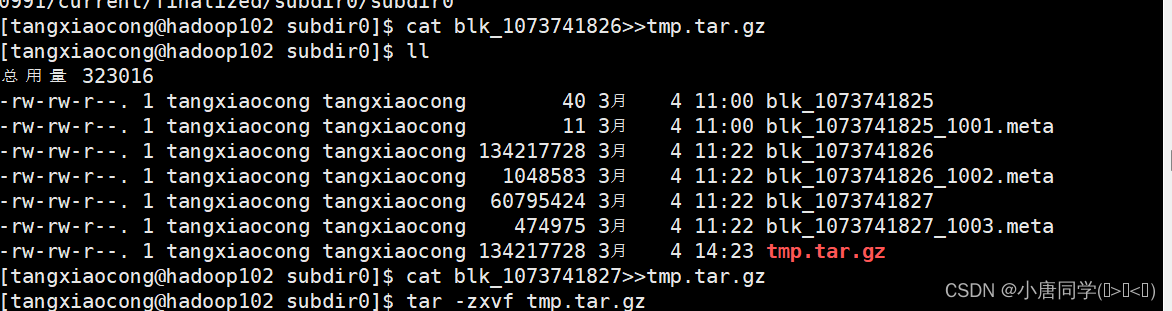
/opt/module/hadoop-3.1.3/data/dfs/data/current/BP-2091296116-192.168.10.102-1677829450991/current/finalized/subdir0/subdir0查看文件内容
查看小文件直接cat即可
查看大文件
cat blk_1073741826>>tmp.tar.gz和cat blk_1073741827>>tmp.tar.gz是把这两个拼接成一个jdk压缩包然后解压发现就是上传的jdk压缩包所以可以确定hdfs实际上内容存储的位置就是在这里。这里为什么会把jdk的压缩包分为两部分呢原因就是在hadoop里存储的容量是128MB为一个块然后jdk的压缩包有180MB所以一个块存不下需要两个块注意块的序号是从0开始的
Hadoop是具有高可用的所以会有多个备份不测试显示3分备份所以在hadoop103,hadoop104上同样的路径有同样的数据