

python的webdriver应用
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
本文总结如何使用python的webdriver插件应用自动化测试以及爬虫抓取数据。
工具选择
webdriver版本http://npm.taobao.org/mirrors/chromedriver/
或https://chromedriver.storage.googleapis.com/index.html
webdriver和谷歌的版本需要对应比如谷歌的版本是109就得下载109版本的webdriver

vscode开发工具https://code.visualstudio.com/
python3.7https://www.python.org/downloads/
vscode的python插件
1、首先安装python3.7软件
window的cmd下输入python若出现以下的提示就是安装完成。

2、安装python插件
点击左侧栏Extension (或输入 Ctrl + shift + X) 进入插件面板。

3、创建venv虚拟目录
该目录下的文件独立存放python的第三方软件包。比如在D盘新建一个文件夹venv在vscode终端中运行以下命令。
D: #进入D盘
md venv #新建venv文件夹
python -m venv /venv #使用Python创建venv环境
cd /venv
source bin/activate #激活venv环境可以看到虚拟环境中的 Package 只有最基础的 pip、setuptools
cd /venv
deactivate #退出venv环境使用pyvenv.cfg简化venv的开关这样vscode在运行相关Python程序的时候就能自动开关venv环境了。
打开vscode使用快捷键ctrl+shift+' 或 菜单栏-terminal-new terminal打开终端
D:
cd /venv
source bin/activate
deactivate通常vscode就会在该目录下自动创建一个pyvenv.cfg文件。
今后只要用vscode打开这个目录直接运行Python程序就会自动切换到venv模式下运行。
到这里就可以使用python自带pip工具安装一个第三方软件selenium
pip3 install selenium第一支脚本
webdriver是selenium的组件Selenium 是一个 Web 的自动化测试工具最初是为网站自动化测试而开发的。Selenium 自己不带浏览器不支持浏览器的功能它需要与第三方浏览器结合在一起才能使用。它支持所有主流的浏览器包括 IE、Firefox、Safari、Opera 和 Chrome 等。
# -*- coding: utf-8 -*-
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
class testlogin:
def __init__(self):
self.driver = webdriver.Chrome()
self.driver.get("www.baidu.com")
if __name__ == "__main__":
test=testlogin()当然啦也可以使用无界面形态。Headless Chrome 是 Chrome 浏览器的无界面形态可以在不打开浏览器的前提下使用所有 Chrome 支持的特性运行你的程序。相比于现代浏览器Headless Chrome 更加方便测试 web 应用获得网站的截图做爬虫抓取信息等。相比于较早的 PhantomJS 等Headless Chrome 则更加贴近浏览器环境
# -*- coding: utf-8 -*-
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
class testlogin:
def __init__(self):
#=====改写部分====begin
chrome_options = webdriver.ChromeOptions()
# 增加无界面选项
chrome_options.add_argument('--headless')
# 如果不加这个选项有时定位会出现问题
chrome_options.add_argument('--disable-gpu')
#=====改写部分====end
self.driver = webdriver.Chrome(options=chrome_options)
self.driver.get("www.baidu.com")
if __name__ == "__main__":
test=testlogin()初识selenium
Selenium 提供了以下几种定位元素的方法
描述 | 查找一个元素 | 查找多个元素 |
通过 ID 定位元素 | find_element_by_id() | find_elements_by_id() |
通过 Name 定位元素 | find_element_by_name() | find_elements_by_name() |
通过 XPath 定位元素 | find_element_by_xpath() | find_elements_by_xpath() |
通过完整链接文本定位超链接 | find_element_by_link_text() | find_elements_by_link_text() |
通过部分链接文本定位超链接 | find_element_by_partial_link_text() | find_elements_by_partial_link_text() |
通过标签名定位元素 | find_element_by_tag_name() | find_elements_by_tag_name() |
通过类名定位元素 | find_element_by_class_name() | find_elements_by_class_name() |
通过CSS选择器定位元素 | find_element_by_css_selector() | find_elements_by_css_selector() |
也可以用find_element统一函数写法再在参数里声明通过什么方式定位元素比如
find_element(By.ID,'元素ID') 对应 find_element_by_id('元素ID')
如何找到元素
比如登录百度账号点击登录按钮在浏览器上按下F12按下图依次点击。
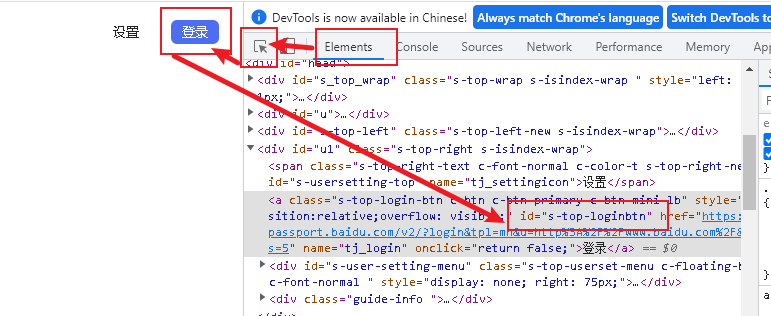
最后找到id=s-top-loginbtn就是需要找的id元素于是脚本就可以做以下的修改。
# -*- coding: utf-8 -*-
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
class testlogin:
def __init__(self):
chrome_options = webdriver.ChromeOptions()
# 增加无界面选项
chrome_options.add_argument('--headless')
# 如果不加这个选项有时定位会出现问题
chrome_options.add_argument('--disable-gpu')
self.driver = webdriver.Chrome(options=chrome_options)
self.driver.get("www.baidu.com")
#=====新增部分====begin
def loginClick(self):
loginbtn = self.driver.find_element(By.ID,'s-top-loginbtn')
loginbtn.click()
#=====新增部分====end
if __name__ == "__main__":
test=testlogin()
test.loginClick()一些高阶写法
1、如何跳转页面
需要准确跳转至页面才能取到元素。
第一种情况同一页面里有多个frame的话就得找到对应的frame才行。
# 转到页面
def switchIframe(self,src):
#返回到主窗体
self.driver.switch_to.default_content()
iframes = self.driver.find_elements(By.TAG_NAME,"iframe")
iframe = None
for frm in iframes:
if re.search(src,frm.get_attribute("src"))!=None:
iframe=frm
self.driver.switch_to.frame(iframe)第二种情况同时找开了多个页面
def switchWindow(self,url):
windows = self.driver.window_handles
for w in windows:
self.driver.switch_to.window(w)
if self.driver.current_url.startswith(url):
# print(self.driver.title)
break
#有时只需要找开最后一个页面。
self.driver.switch_to.window(self.driver.window_handles[-1])
self.driver.maximize_window()2、xpath写法详解
其实xpath用法比较复杂一般只会用到第123点。第456点需要的时候再查找的。
2.1基本用法
//tagname[@attribute=‘value’]
其中tagname表示标签名称@后面跟随属性名称等号后面是属性值。如果需要查找多重下级则在父级的xpath路径后继续追加定位例如//div[@id='car_genre_id']/div/div表示 id是car_genre_id的div元素的子节点div的子节点div。
2.2xpath的绝对路径和相对路径
1单斜线‘/’代表绝对路径表示该符号后面的元素是上一级节点的子节点的一个只能一级级按序向下查询不能跳级
2双斜线'//'代表相对路径表示下级任何子节点或者任何嵌套子节点中的一个可以跳级
举个栗子在路径//div[@id='root']/input中表示越过所有父节点直接在整个html页面中查找id是'root'的div元素因为div标签前是代表相对定位的双斜线'//'而对于input标签来说它必须是id是'root'的div的一级子节点它和div中间不能越过其他的层级因为input标签前是代表绝对路径的单斜线'/' 。
2.3如何获取元素的xpath路径
大多浏览器的开发者模式中都具备了输出元素xpath路径的功能。以chrome为例点击F12后在DOM树中选中元素右键> Copy > CopyXpath后在记事本上黏贴即可得到该元素的xpath路径。
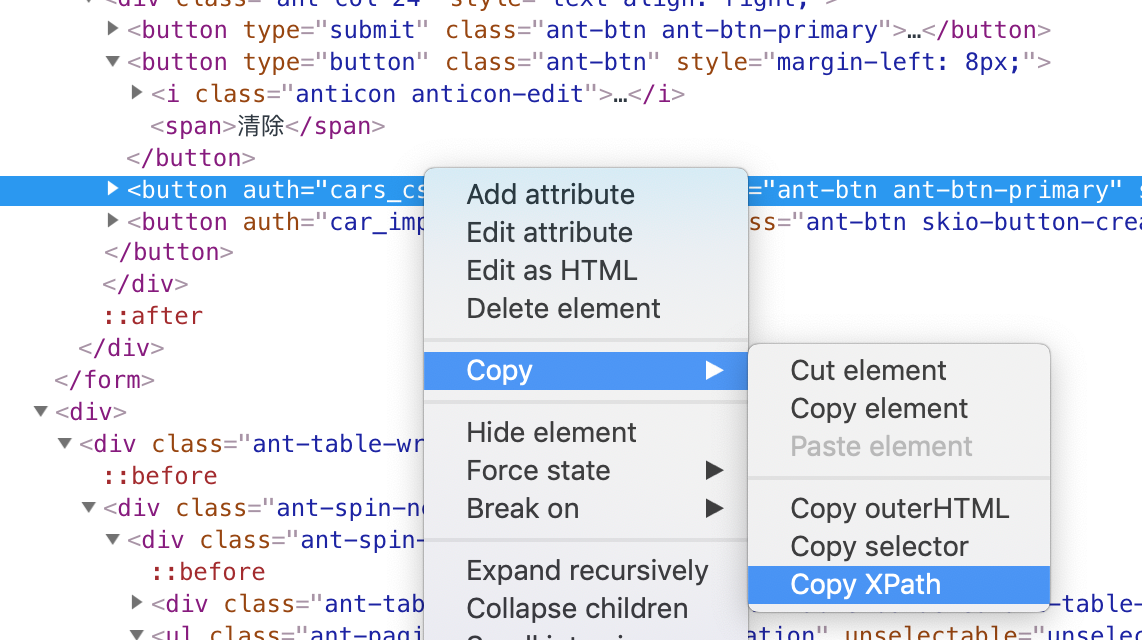
2.4使用contains属性查找元素
contains表示查找属性包含该属性值value的页面标签元素注意是包含并不是完全等于类似于sql查找语句中like的用法。
语法为 //tagname[contains(attribute1,'value1') and contains(attribute2,'value2') and ... ]
举个例子路径 //div[@id="root"]//div[contains(text(),'共'] 表示在id是'root'的div中越过层级关系查找文本信息包含"共"的div元素
路径//div[@id='root']//div[contains(className,'ant-Btn')] 表示在id是'root'的div中越过层级关系查找className属性中包含'ant-Btn'属性的元素
2.5 查找父级节点和平级节点
2.5.1父节点定位子节点
# 1.串联寻找
print driver.find_element_by_id('B').find_element_by_tag_name('div').text
# 2.xpath父子关系寻找
print driver.find_element_by_xpath("//div[@id='B']/div").text
# 3.css selector父子关系寻找
print driver.find_element_by_css_selector('div#B>div').text
# 4.css selector nth-child
print driver.find_element_by_css_selector('div#B div:nth-child(1)').text
# 5.css selector nth-of-type
print driver.find_element_by_css_selector('div#B div:nth-of-type(1)').text
# 6.xpath轴 child
print driver.find_element_by_xpath("//div[@id='B']/child::div").text driver.quit()2.5.2由子节点定位父节点
这里我们有两种办法第1种是 .. 的形式就像我们知道的. 表示当前节点.. 表示父节点第2种办法跟上面一样是xpath轴中的一个parent取当前节点的父节点。这里也是css selector的一个痛点因为css的设计不允许有能够获取父节点的办法至少目前没有
# 1.xpath: `.`代表当前节点; '..'代表父节点
print driver.find_element_by_xpath("//div[@id='C']/../..").text
# 2.xpath轴 parent
print driver.find_element_by_xpath("//div[@id='C']/parent::*/parent::div").text2.5.3由弟弟节点定位哥哥节点
# 1.xpath,通过父节点获取其哥哥节点
print driver.find_element_by_xpath("//div[@id='D']/../div[1]").text
# 2.xpath轴 preceding-sibling
print driver.find_element_by_xpath("//div[@id='D']/preceding-sibling::div[1]").text2.5.4由哥哥节点定位弟弟节点
# 1.xpath通过父节点获取其弟弟节点
print driver.find_element_by_xpath("//div[@id='D']/../div[3]").text
# 2.xpath轴 following-sibling
print driver.find_element_by_xpath("//div[@id='D']/following-sibling::div[1]").text
# 3.xpath轴 following
print driver.find_element_by_xpath("//div[@id='D']/following::*").text
# 4.css selector +
print driver.find_element_by_css_selector('div#D + div').text
# 5.css selector ~
print driver.find_element_by_css_selector('div#D ~ div').text2.6使用xpath定位元素时需要注意的地方
1保证xpath路径的唯一性。
一定要保证xpath路径在页面中是唯一的。如果不太确定可以在chrome的开发者工具打开的情况下点击ctrol+F在弹出的输入框中输入xpath
的路径观察当前页面下以该路径查找到的元素是不是只有一个
2尽量不要使用通配符*
*表示可以是当前页面中的任意标签这样在查找时会增大负载尽量准确地写出标签名称
3建议使用相对路径定位
如果前面页面的元素结构发生调整那么之前的绝对定位就会作废。而使用相对路径可以减少定位对页面HTML元素结构的依赖性且相对路径
往往长度较短更加准确美观。在优化定位方式时可以将此原则作为参考。
3、执行js脚本
有时直接用selenium接口操作元素失效不妨尝试直接执行js脚本。
def executeJs(self):
jsStr = "document.getElementById('append').getElementsByTagName('li')[0].click()"
self.driver.execute_script(jsStr)4、等待元素出现再操作
有时某个元素需等待一段时间才会出现如果用time.sleep(20000)等待20秒再执行点击操作也可以只是有点low有时网络没有延迟或页面响应较快不用等20秒而是等1秒就出现呢为了保证元素出现程序每次都会等待20秒这样等待时长也是挺难受的。
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions
# 设置等待20秒超时时间20秒内如果出现id='append'就直接执行点击操作
def waitForShow(self):
append = WebDriverWait(self.driver, 20).until(expected_conditions.presence_of_element_located((By.ID, "append")))
append.click()