

Auto-encoder(自编码器)的原理及最新的技术应用(李宏毅视频课整理和总结)_auto encoder
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
文章目录
0 前言
本节学习的是Auto-encoder这是一种无监督的学习算法主要用于数据的降维或者特征的抽取。自编码器是一种特殊的神经网络架构其的输入和输出是架构是相同的先获取输入数据的低维度表达然后在神经网络的后段重构回高维的数据表达在此基础还有诸多应用。本文由整理李宏毅老师视频课笔记和个人理解所得详细讲述了Auto-encoder的原理及最新的技术。我会及时回复评论区的问题如果觉得本文有帮助欢迎点赞 😃。
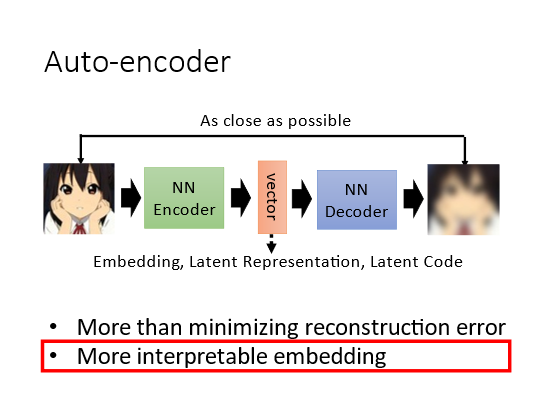
1 Auto-encoder
Auto-encoder是一个基本的生成模型更重要的是它提供了一种encoder-decoder的框架思想广泛的应用在了许多模型架构中。简单来说Auto-encoder可以看作是如下的结构
- Encoder(编码器)它可以把原先的图像压缩成更低维度的向量。
- Decoder(解码器)它可以把压缩后的向量还原成图像通常它们使用的都是神经网络。
Encoder接收一张图像(或是其他类型的数据(hidden layer输出一个低维的vector它也可称为Embedding或者code然后将vector输入到Decoder中就可以得到重建后的图像希望它和输入图像越接近越好即最小化重建误差(reconstruction error。Auto-encoder本质上就是一个自我压缩和解压的过程。具体如下图
第一个流程图假设输入是一张图片有784个像素输入一种network的Encoder(编码器后输出一组远小于784的code vector认为这是一种紧凑的表示。
第二个流程图输入是一组code vector经过network的Decoder(解码器之后可以输出原始图片。
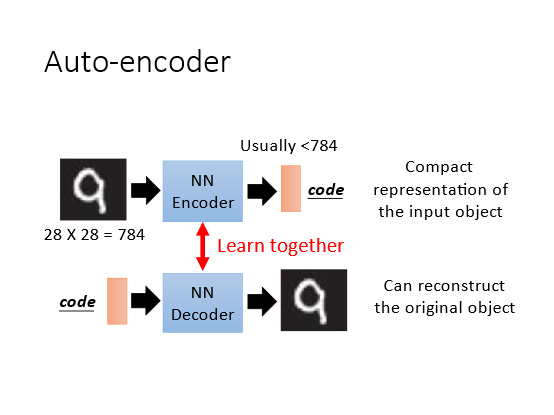
两者单独来看都是无监督学习不能独立训练因为不知道输出是什么。所以将两者结合起来训练。
1.1 PCA
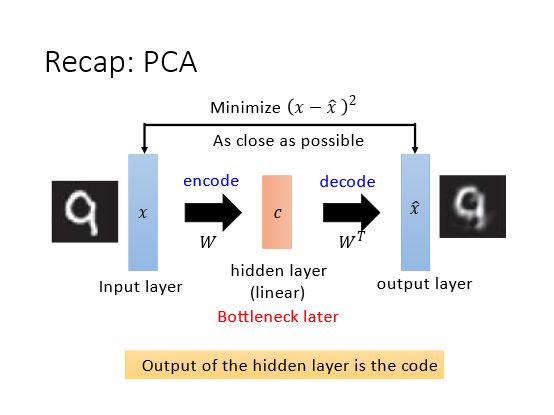
先回顾PCA的概念。PCA输入是 x x x乘上W的权值矩阵可以得到component c c c然后再乘上 W T W^T WT 可以得到 x ^ \hat{x} x^。目标函数即使得 x x x和 x ^ \hat{x} x^的差值最小Minimize ( x − x ^ ) 2 (x-\hat{x})^{2} (x−x^)2。
将PCA类比为network的话就可以分为input layerhidden layer和output layerhidden layer又称Bottleneck(瓶颈 layer。因为hidden layer的通常维数比output和input要小很多所以整体看来hidden layer形如瓶颈一般。 Hidden layer 的输出就可以等同于Auto-encoder的code vector。
1.2 Deep Auto-encoder
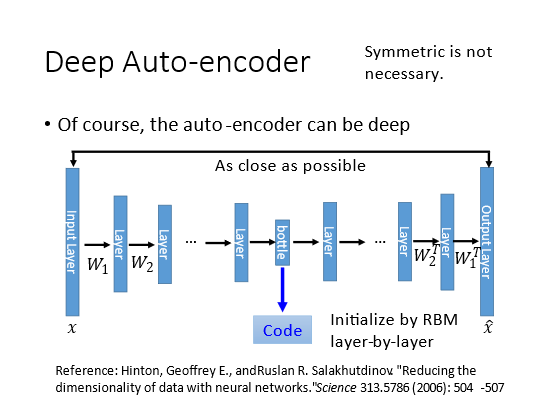
但是PCA只有一个hidden layer如果我们将hidden layer增加就变成了Deep Auto-encoder。目标函数也是Minimize ( x − x ^ ) 2 (x-\hat{x})^{2} (x−x^)2训练方法和训练一般的神经网络一样。
将中间最窄的hidden layer作为bottleneck layer其输出就是code。bottleneck layer之前的部分认为是encoder之后的部分认为是decoder。
可认为
W
1
W_1
W1和
W
1
T
W_1^T
W1T互为转置的关系参数的值是相同的但是实际上这种对称是没有必要的。直接训练就可以了。
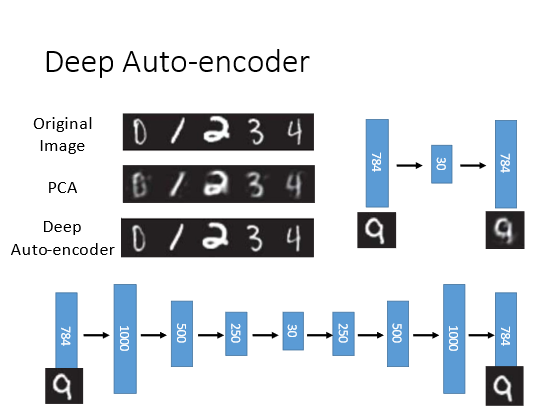
对比使用PCA和Deep Auto-encoder的结果可以发现后者的结果要好很多
为了可视化将bottleneck layer的输出降到2维后拿出来显示不同颜色代表不同的数字。PCA就比较混杂而Deep Auto-encoder分得比较开。
2 Some Applications
2.1 Text Retrieval(文字检索
一般的文字搜索的方法是Vector Space Model把每一篇文章表示为空间中的一个点将输入的查询词汇也变成空间中的一个点计算输出的查询词汇和文章在空间的距离比如内积和cosine similarity用距离来retrieve。
这个模型的核心是将一个document表示成一个vector假设我们有一个 bag of word假设所有的词汇有十万个那么这个document的维度就是十万维。涉及到某个词汇对应的维度就置为1。但是这样的模型无法知道具体的语义对它来说每一个词汇都是独立的忽略了相关性。
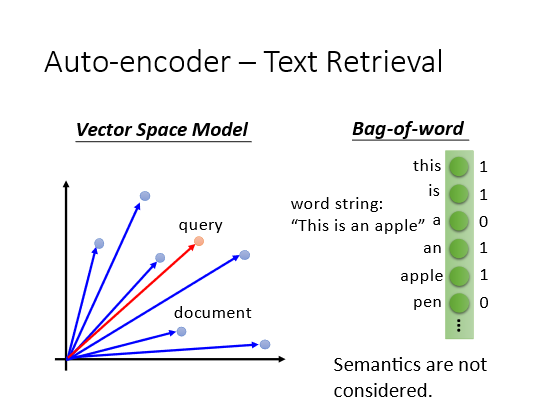
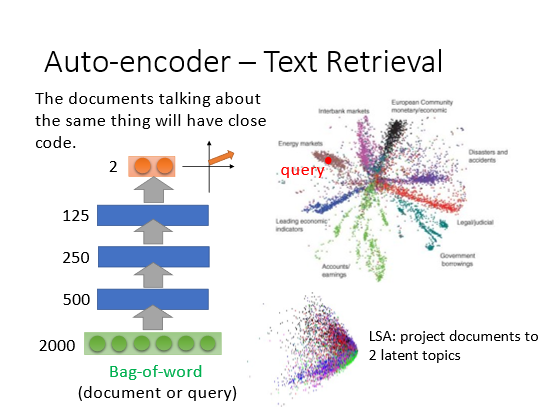
可以使用Auto-encoder来表示这种相关性。
降到2维后做可视化右上的每个点表示一个document可以发现同一类的document都分散在一起。如果用刚刚的LSA模型如右下就得不到类似的结果。
2.2 Similar Image Search(相似图片搜索
可以用在图片的搜索上面用图片来寻找类似的图片。如果使用欧式距离在像素密度空间去搜索的话结果如下效果不是很好。

Auto-encoder的方法就是将图片变成一个code在code空间去做搜索。变成code之后再通过一个decoderreconstruct回来可以得到下图的结果

如果在code上做搜索的话可以得到以下结果至少都是人脸。

2.3 Pre-training(预训练
在训练DNN的时候希望能选择好的初始值这类方法称为Pre-training。可以用Auto-encoder来做Pre-training假设目标是一个如下的network
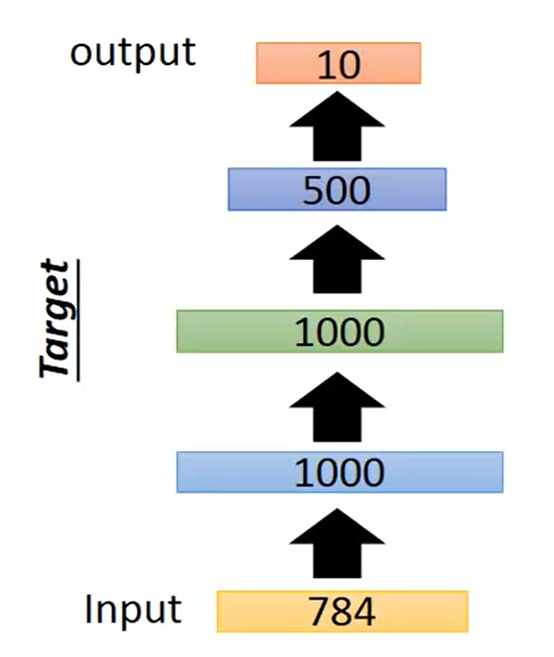
开始使用Auto-encoder对第一个hidden layer进行训练
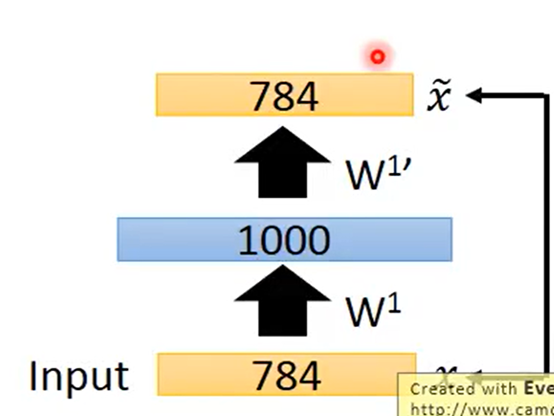
但是有个问题就是这里的hidden layer是1000维code比两边都大可能什么都learn不到直接把参数复制一遍就可以一模一样了。所以要加一个很强的regularization 来约束比如使得这1000维是稀疏(sparse的某几个维度才有值这样才能learn下去。
现在将学好的第一层的
W
1
W^1
W1固定下来再学习第二层hidden layer
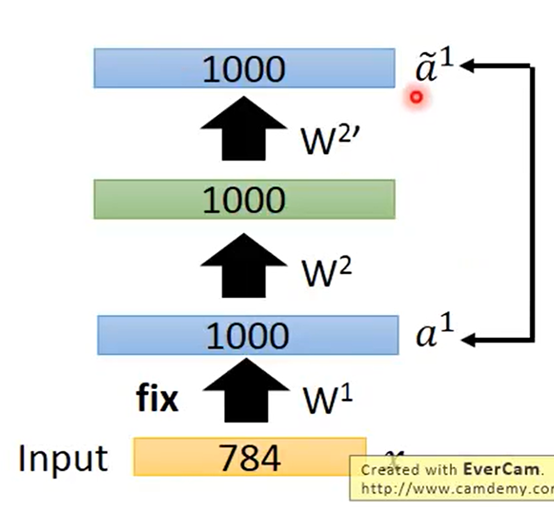
同理得到其他的W
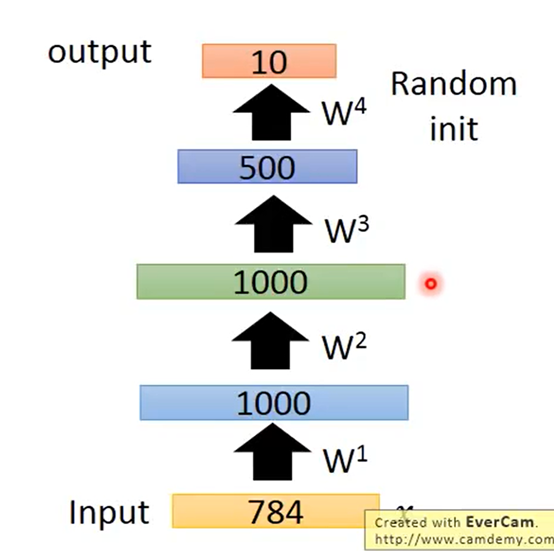
已经得到很好的W了最后使用BP(back propagation算法fine-tune微调一下即可。不过现在训练的技术进步Pre-training用的不多了但是如果你unlabeled data很多labeled data1很少那么可以使用这个方法。
3 De-noising Auto-encoder(加噪的自编码器
这是一种改进的Auto-encoder算法训练的时候在x输入前加入噪声。这样做的结果会使得学习的模型有更好的鲁棒性。
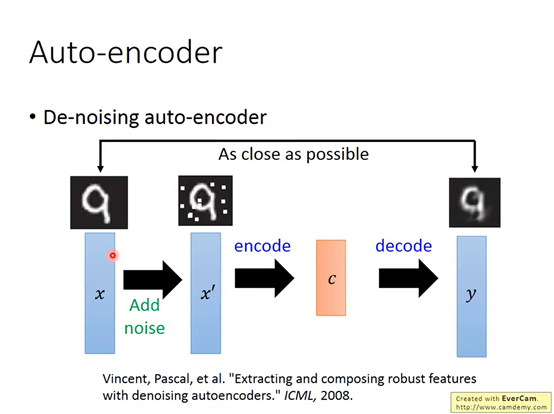
还有很多线性的降维法

深度信念网络

4 Auto-encoder for CNN
一般图像处理会使用CNN如果将Auto-encoder的思想用在CNN上那么encoder和decoder的卷积、池化和反卷积、池化将是一一对应的如下图所示
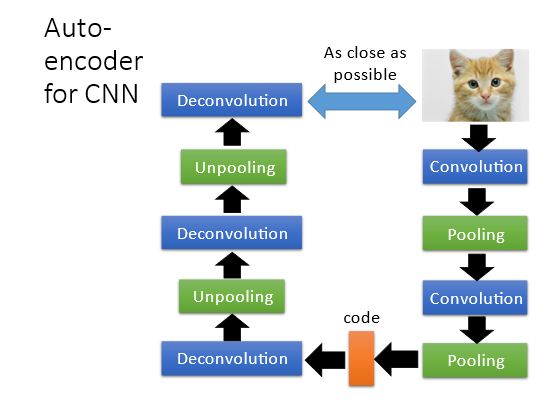
但是反卷积和反池化到底是什么呢?
4.1 Unpooling(反池化
首先看反池化的部分。池化的意思原本是对特征进行提取比如是在22的矩阵中选取一个作为特征那么此时使用一个Max location的层来记录筛选特征的位置在后面进行反池化(unpooling的时候就依据Max location的位置reconstruction这些特征。原本1414的数据经过unpooling之后就会变成28*28的数据。具体过程如下图所示
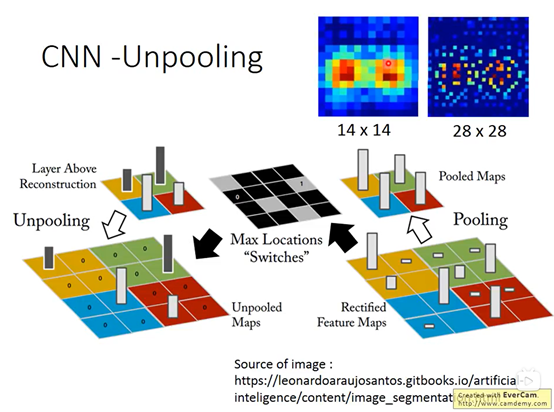
上述只是一种方式也有不管位置信息直接将特征复制4份的做法。
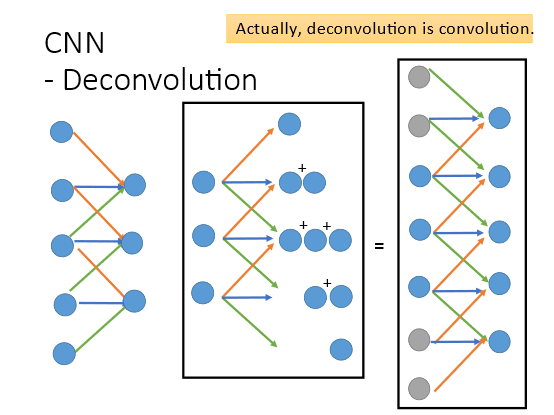
4.2 Deconvolution(反卷积
那对于反卷积来说本质上就是做卷积。我们知道卷积的本质就是相乘相加再移位后继续重复。用一维的卷积举例输入5个点卷积核为红色蓝色绿色的3个weight最后相加得到3个值。而Deconvolution 的就是反过来因为刚才是三个点乘上3个weight相加后变成1个值这里Deconvolution就需要从1个值乘3个weight变成3个值其他点操作一样产生在相同位置的值可以相加。最后初始的3个点就变成了5个点。这件事其实等价于padding后的convolution在3个点周围补上4个零仍然使用3个weight最后得到的结果是一模一样的。不同之处在于卷积核即weight的顺序是相反的
4.3 Generate Image
Decoder还有一个特别的用法因为已经训练好了整个模型将Decoder抽出来随机丢入一个二维的code希望可以输出一张图。李宏毅老师将图片通过hidden layer 投影到2维上然后再通过Decoder解成图片。2维是可以画图的分布如下图所示按照一定步长取红色方框中的code输入到decoder中可以解出如下图片
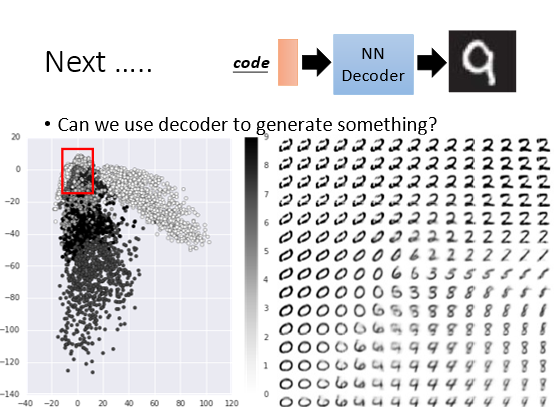
加上L1的正则项后数据分布向0靠拢。重新选取数据得到以下结果可以观察到这两个维度其实是有一定物理意义的反映了图片的变化规律

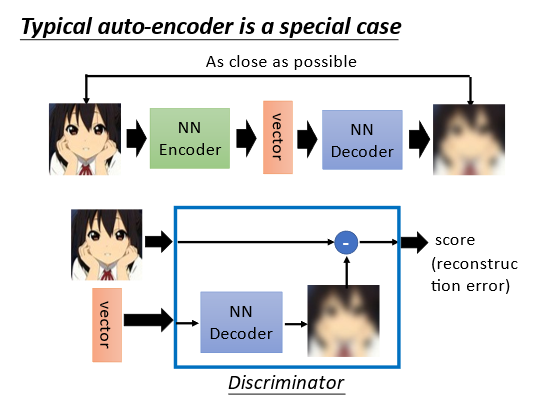
我们知道一般的Auto-encoder的目标函数是最小化重构误差(上文但是除此之外还有别的方法。
5 More Than Minimizing Reconstruction Error(其他计算Error的方法
5.1 Representative Embedding
先思考对Auto-encoder的目标来说什么样的embedding(嵌入这里可以理解为低维表示是好的呢?希望这个embedding可以代表原来的object。比如出现这个embedding就会联想到这个object。比如出现一个耳机就会想到“三玖”(动漫人物

这里涉及一点对抗生成网络的概念即使用一个二分类的判别器对结果进行判别如果觉得输入和输出是一对就是yes反之就是no。通过使得判别器的损失最小来训练这个网络
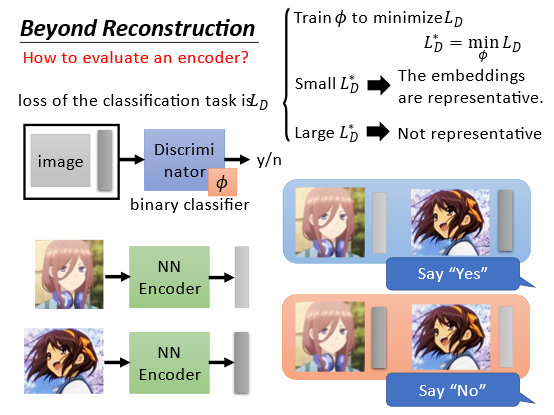
具体是首先通过训练判别器
L
D
∗
=
min
ϕ
L
D
L_{D}^{*}=\min _{\phi} L_{D}
LD∗=minϕLD 最小化损失函数
L
D
L_D
LD然后再训练encoder的
θ
∗
=
arg
min
θ
L
D
∗
=
arg
min
θ
min
ϕ
L
D
\begin{aligned} \theta^{*} &=\arg \min _{\theta} L_{D}^{*} =\arg \min _{\theta} \min _{\phi} L_{D} \end{aligned}
θ∗=argθminLD∗=argθminϕminLD。训练最好的encoder和最好的discriminator
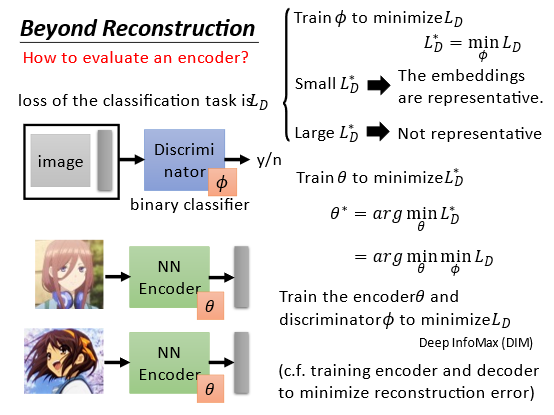
可以将这个过程类比如下
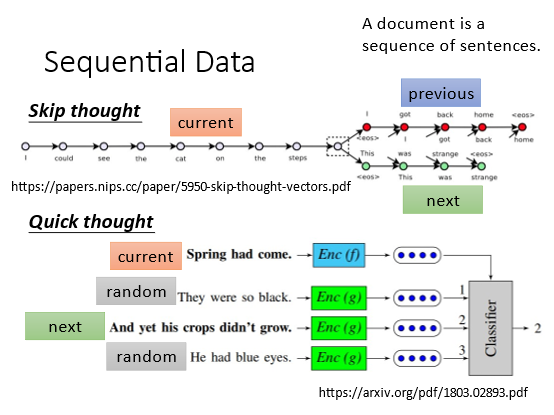
5.2 Sequential Data
也可以用于训练有顺序的数据
6 More Interpretable Embedding(更易解释
让encoder的output即code更容易被解释。
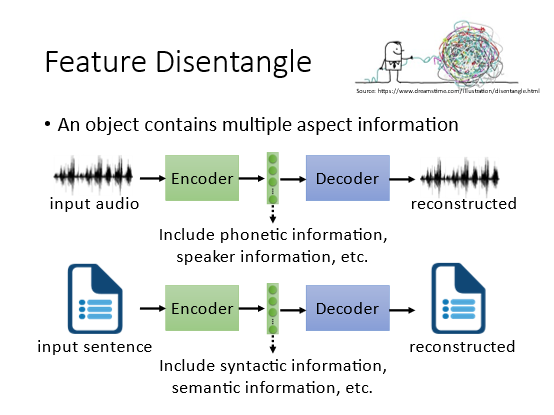
6.1 Feature Disentangle(特征解析
比如一段声音信号里面除了语义本身还包含了说话人的语音语调和环境噪声等信息。那么code vector中也含有以上所有信息但是我们不知道各个维度的具体含义。所以期望Encoder能指出维度和各类信息的对应关系。
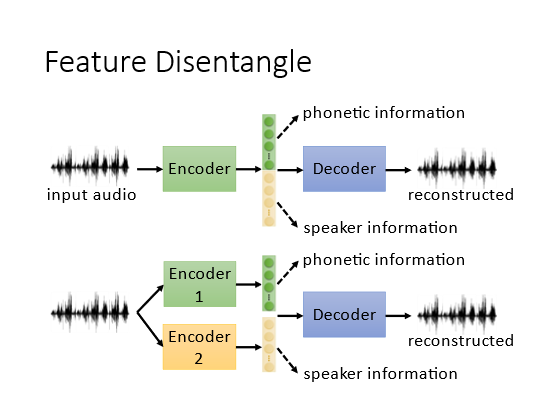
具体做法如下假设只有说话人和内容两种信息一种是将vector进行划分另外一种是直接就训练两个encoder处理不同的信息
可以将声音和语义分开
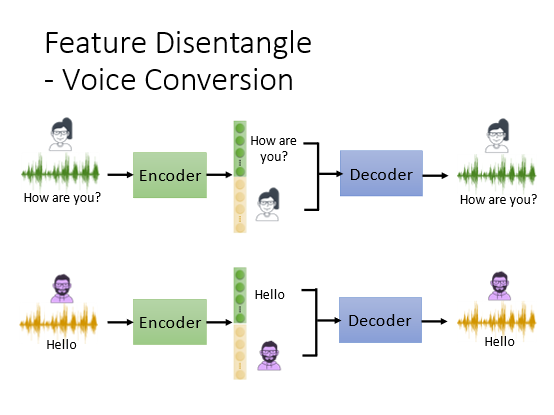
然后将不同的声音和语义组合得到完全不同的语音输出可以做成一个变声器
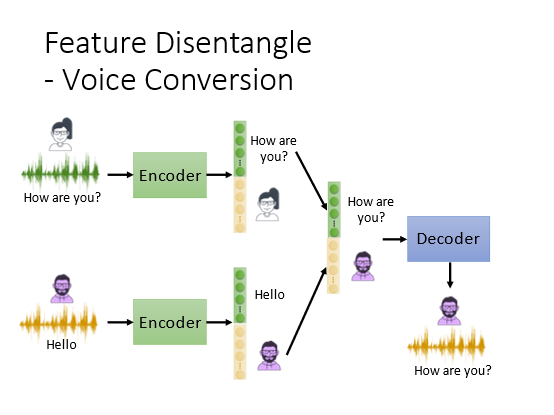
变声器的应用

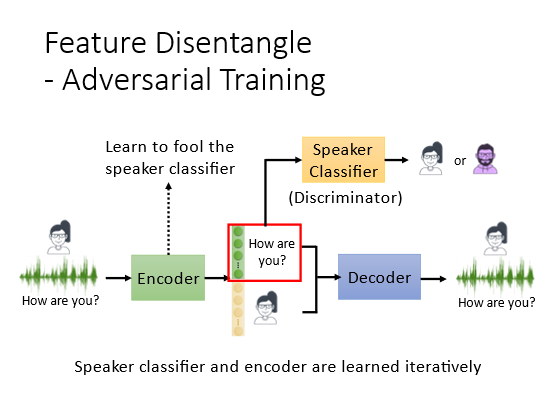
引入对抗训练的概念也就是在训练中加入了Discriminator。目的是训练让前面的维度是语义后面的维度代表男声还是女声。先训练一个语者的Classifier可以分辨男声女声但是encoder需要训练来骗过classifier让这个classifier不能区分男声还是女声正确率越低越好。这样就使得语者的信息从前部分的维度剔除了出来只剩下内容的信息语者信息都在了后部分的维度中
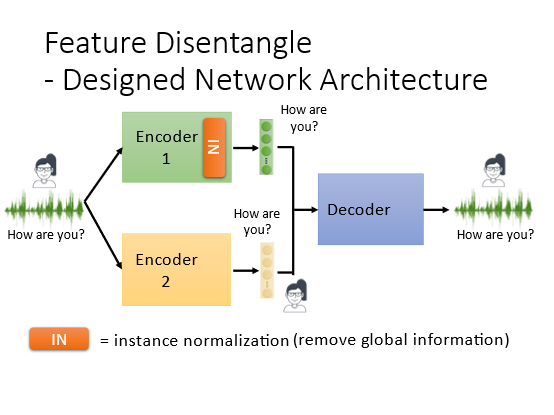
或者直接修改encoder的架构可以区分语者和语义信息。假设有一种特殊的layerinstance normalization可以抹除语者的信息
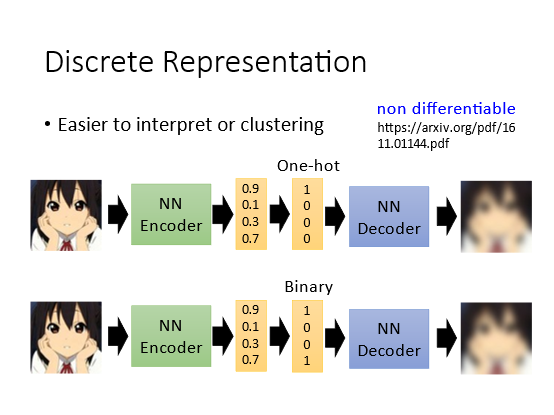
6.2 Discrete Representation(离散的表示
6.2.1 Base Method
我们之前讲的code都说是一个连续的vector如果Encoder能够输出离散的向量那么更有利于我们解读code的信息比如可以用一些聚类的方法将向量分成一些簇。可以将code直接变成One-hot或者Binary的形式取最大值或者设置阈值即可实现这样看维度信息就可以直接完成分类了。但是老师认为binary更好因为可表示的信息更大而one-hot过于稀疏。
6.2.2 Vector Quantized Variational Auto-encoder (向量量化变异的自编码器)
设置一个codebook里面是一排向量这个也是需要学习的。Encoder输出原始向量vector这是连续的。接下来用这个vector去计算和codebook里面的向量的相似度相似度最高的vector3作为decoder的输入。这样可以固定向量的类别相当于做了离散化。离散化之后信息 更易分类
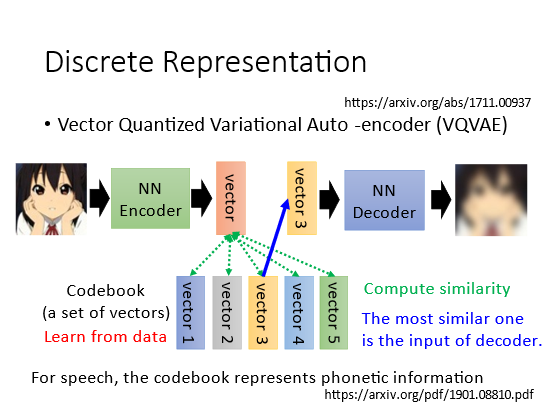
有一些trick来让你训练这些没办法微分的部分一般是用强化学习直接做。
6.2.3 Sequence as Embedding
可以让embedding不再是向量而是句子。比如一个 seq2seq2seq auto-encoder 模型使用这些sequence 作为code来还原文章。期待这些code可以就是原来那篇文章的摘要或者精简版本但是实际上由于encoder和decoder的存在这些code会参杂一些“暗号”虽然是文字的组合但没有实际含义。如果要让这些code有实际含义将会用到GAN的概念就是预先训练一个可以识别人类是否能读懂的句子的discriminator然后去训练这些code使得code具有可读性
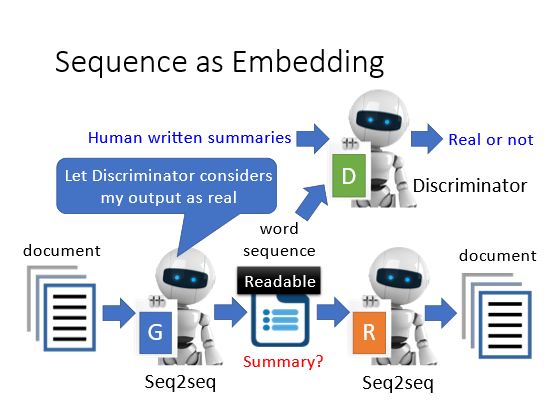
一些实验的例子

