

从零搭建完整python自动化测试框架(UI自动化和接口自动化 )——持续更新_python自动化测试
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
本自动化测试框架采用python + unittest 的基础来搭建采用PO模式、数据驱动的思想通过selenium来实现WEB UI自动化通过request来实现接口自动化。移动终端的自动化也可在该框架基础上去构建补充。
目录
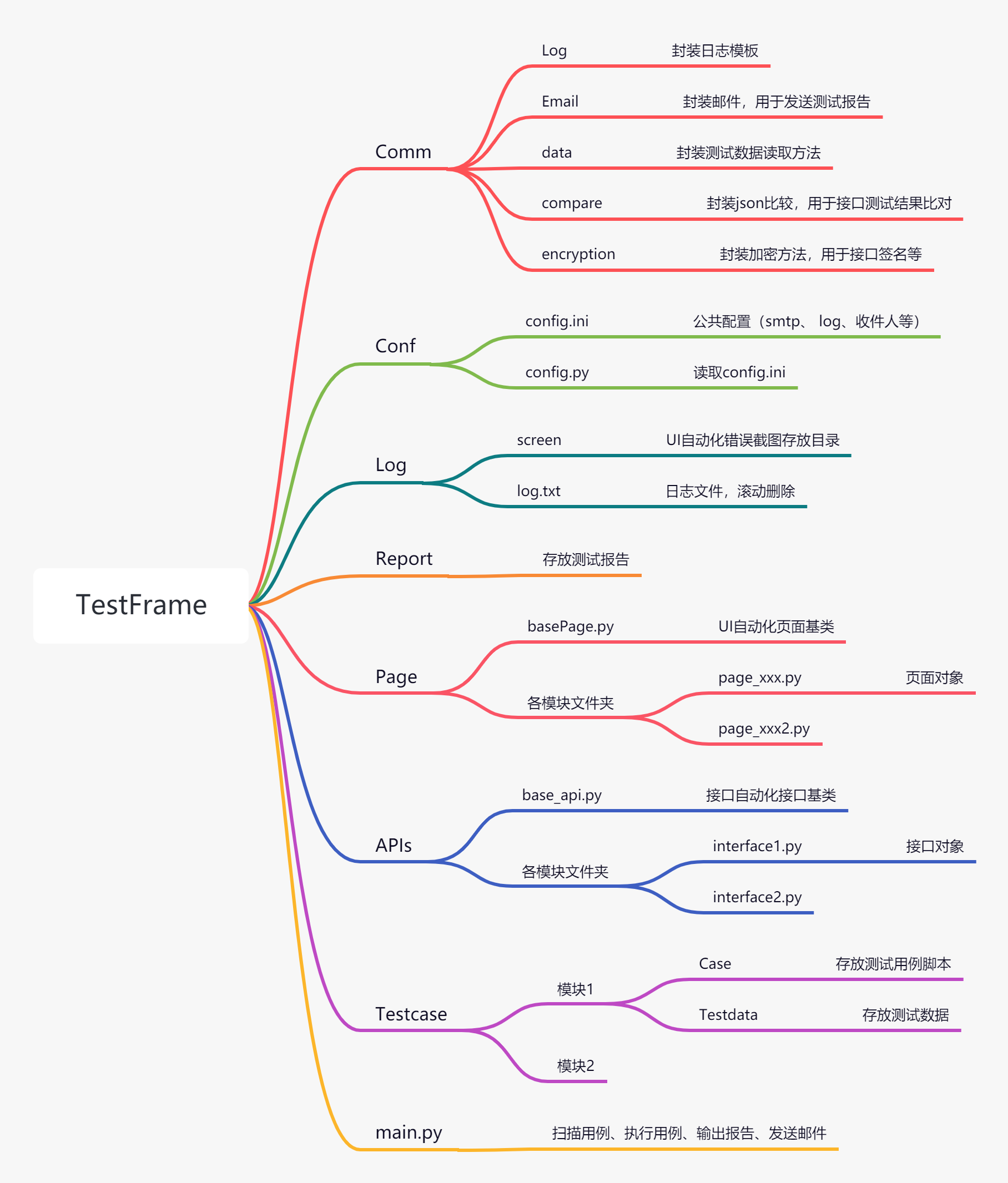
总体框架
总体框架如下图
测试执行结果
3个脚本每个脚本2条测试数据共6个用例。运行main.py执行测试测试结果如下3个失败的是故意修改了测试数据。
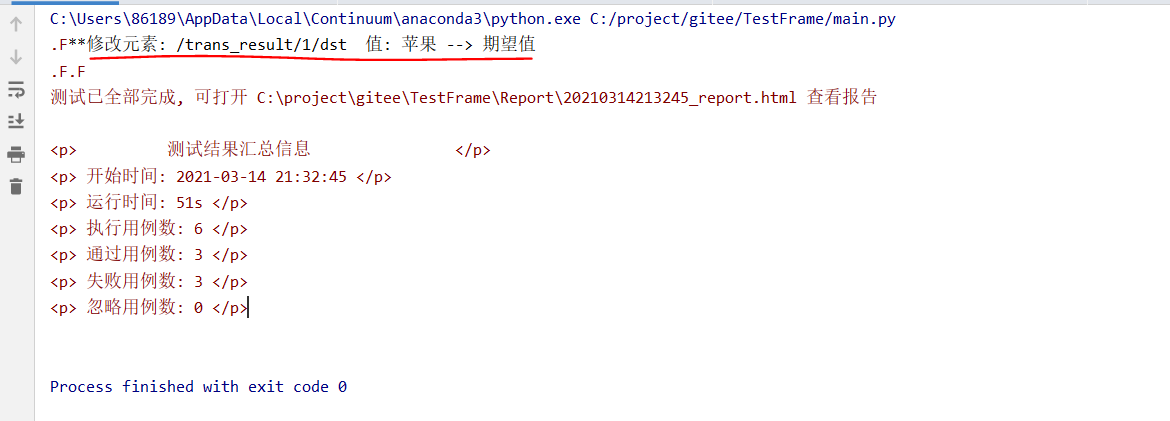
红线部分为接口测试时自动比对的json差异预期结果为“苹果”实际结果为“期望值”。
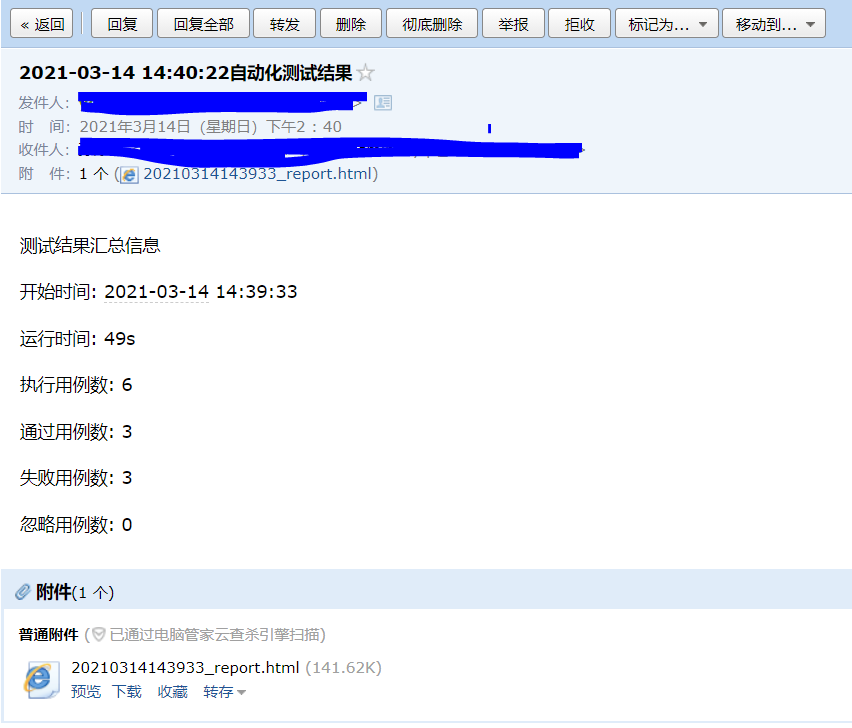
测试报告邮件
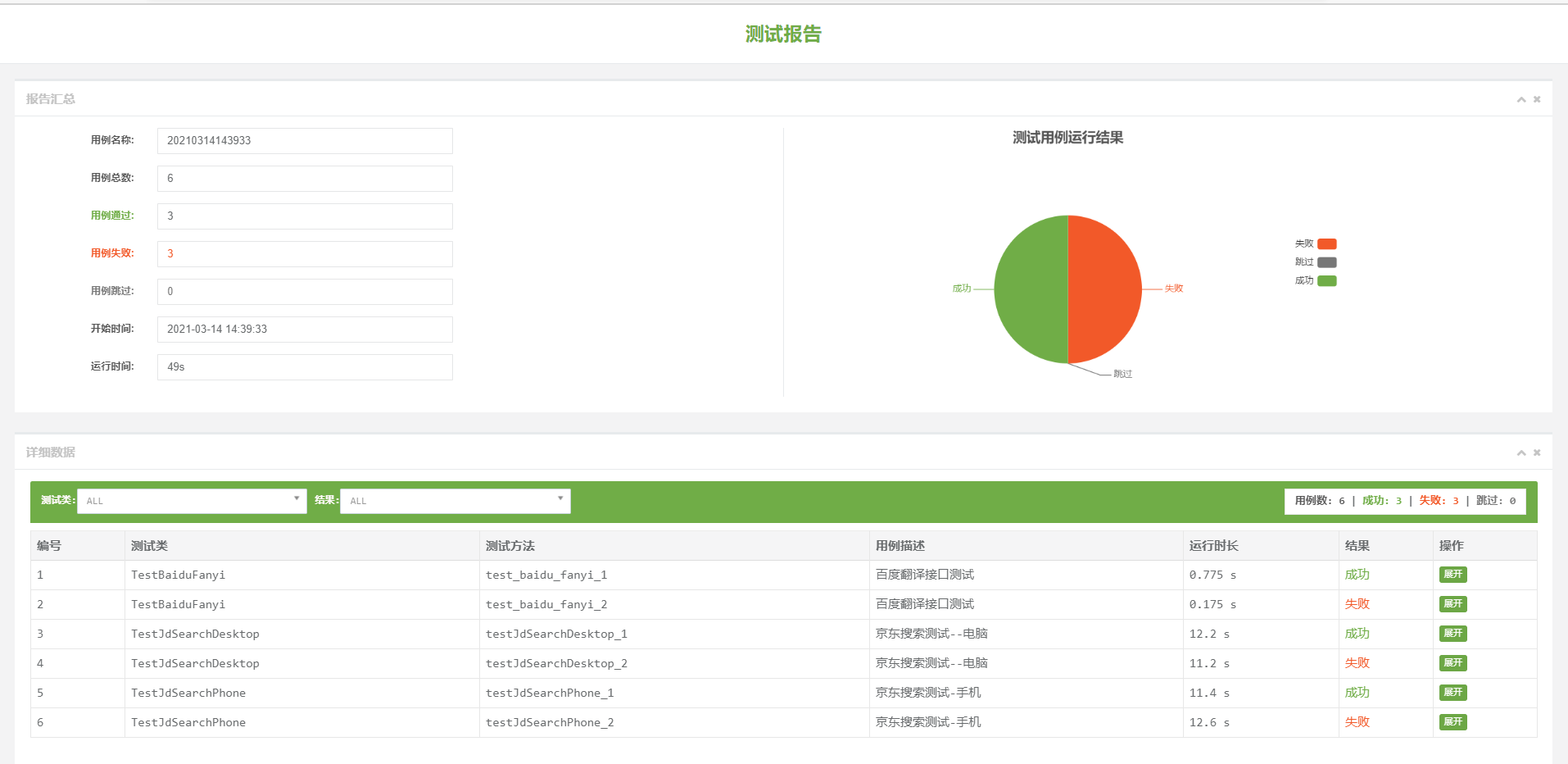
测试报告详情
从零开始搭建项目
一、开发环境搭建
pycharm、python、anaconda三者的关系添加链接描述
基本上都是直接上对应官网下载安装。准备好了以后直接开干。
二、新建项目
pycharm上新建项目TestFrame选择好存放目录并在TestFrame项目下新建各模块。注意除了Log和Report是新建Directory外其它的都是新建Python Package因为下面还要放py文件的。
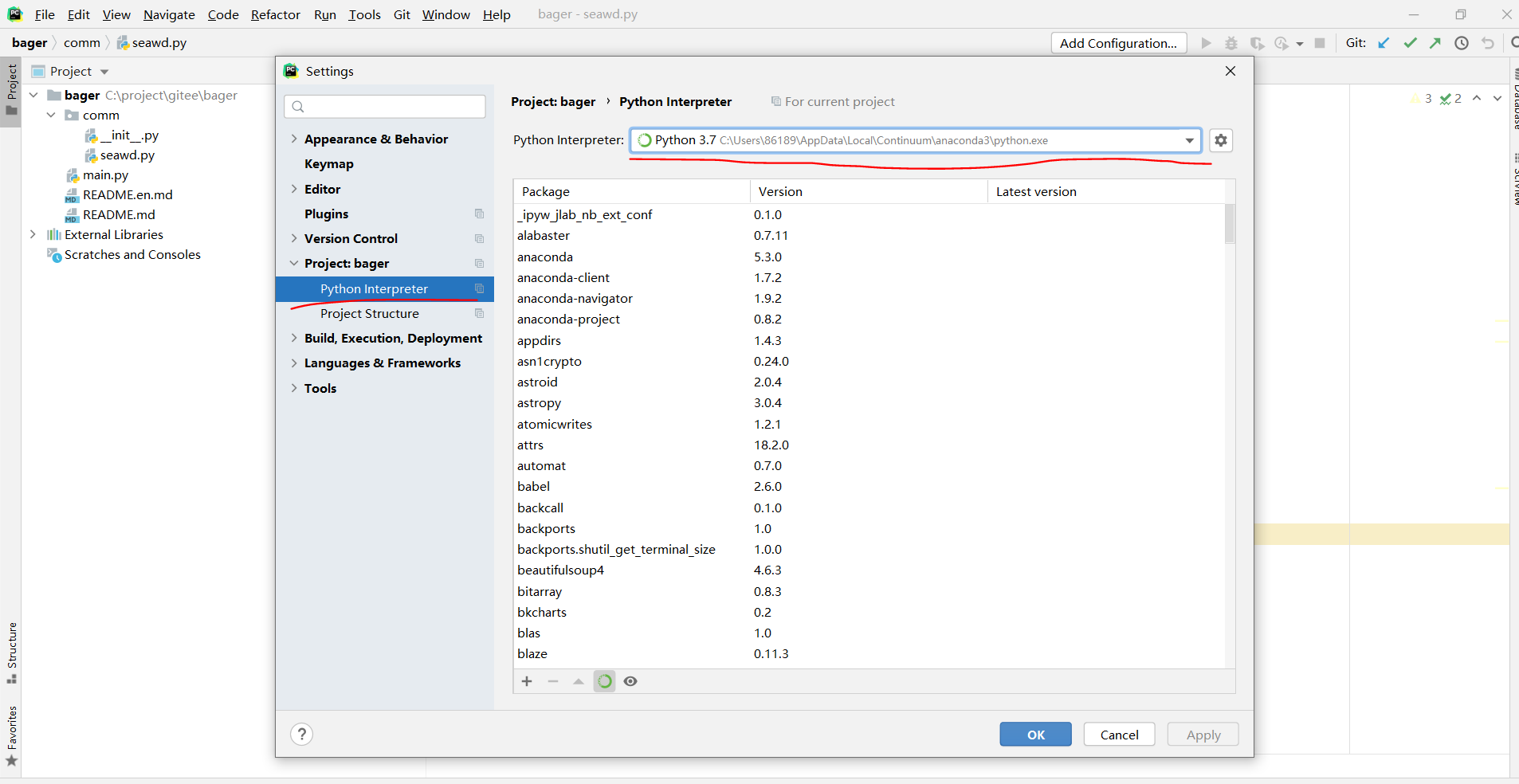
pycharm上切换项目的python环境为anacondaFile—>Settings—>Project下面切换如下图
三、基础功能实现
1. 配置功能实现Conf
配置功能是项目的基础所以先实现。在Conf目录下新建2个文件分别为config.ini和config.py。
config.ini内容如下
[sys]
base_url = https://www.jd.com
[smtp]
host = smtp.163.com
port = 465
user = example@163.com
passwd = password
暂时先加这么多后续需要再慢慢添加。
config.py文件实现config.ini文件的读取。
ini文件读取python有ConfigParser库可以使用那就直接用。
ConfigParser库传送门
但是每次取值都要用他的方法比较麻烦因此对它的方法进行了一个继承和改写直接将配置文件中所有内容读出来字典形式方便后续使用。
代码如下
import os
from configparser import ConfigParser
# 使用相对目录确定文件位置
_conf_dir = os.path.dirname(__file__)
_conf_file = os.path.join(_conf_dir, 'config.ini')
# 继承ConfigParser写一个将结果转为dict的方法
class MyParser(ConfigParser):
def as_dict(self):
d = dict(self._sections)
for k in d:
d[k] = dict(d[k])
return d
# 读取所有配置以字典方式输出结果
def _get_all_conf():
_config = MyParser()
result = {}
if os.path.isfile(_conf_file):
try:
_config.read(_conf_file, encoding='UTF-8')
result = _config.as_dict()
except OSError:
raise ValueError("Read config file failed: %s" % OSError)
return result
# 将各配置读取出来放在变量中后续其它文件直接引用这个这些变量
config = _get_all_conf()
sys_cfg = config['sys']
smtp_cfg = config['smtp']
print(sys_cfg)
print(smtp_cfg)
print(smtp_cfg['host'])
运行结果
{'base_url': 'https://www.jd.com'}
{'host': 'smtp.163.com', 'port': '465', 'user': 'example@163.com', 'passwd': 'password'}
smtp.163.com
后续其它文件就可以直接使用 sys_cfg 和 smtp_cfg 这两个字典以key的方式访问需要的配置内容。
2. 日志功能实现Log
日志在项目中也是基础功能所以接着做日志。
python自带logging库可以定制日志的格式就直接使用该库实现没必要自己造。
先去我们的配置文件中config.ini添加日志相关的配置这里先定义3个配置日志级别、日志格式、日志路径。
[log]
log_level = logging.DEBUG
log_format = %(asctime)s - %(name)s - %(filename)s[line:%(lineno)d] - %(levelname)s - %(message)s
log_path = Log
再在config.py中最后面添加一行代码把log相关的配置放在一个变量中好直接使用。
log_cfg = config['log']
print(smtp_cfg)
打印出来看一下结果
{'log_level': 'logging.DEBUG', 'log_format': '%(asctime)s - %(name)s - %(filename)s[line:%(lineno)d] - %(levelname)s - %(message)s', 'log_path': 'Log'}
日志级别有DEBUG、INFO、WARN、ERROR、FATAL。一般调试都是DEBUG上线就改为INFO。
这里简单介绍一下日志格式log_format的内容
| 参数 | 意义 | 说明 |
|---|---|---|
| asctime | 时间 | 格式2021-03-14 09:37:40,258 |
| name | logger的名称 | 简单理解就是将来把模块名称填到这里区分是谁打的日志 |
| filename | 文件名 | 哪个文件打印的这条日志 |
| line | 行号 | 哪一行打印的这条日志 |
| levelname | 级别 | 日志的级别注意是级别的name |
| message | 内容 | 我们打印的日志内容 |
| log_path | 日志文件 | 保存到哪个日志文件 |
再接着在Comm目录下新建一个Log.py开始定制日志。定制日志还有几个问题要提前考虑
一是存放目录问题我们这里使用了固定目录所以问题不大。
二是日志分割、滚动问题每天跑持续集成大量用例生成大量日志日志堆成山。如果觉得日志有用呢就搞个ELK把日志取走存放起来做分析。如果觉得日志没用呢保存几天后就删除掉。无论怎么讲都要实现日志的分割和滚动。
幸好你想到的大佬们早就想到了logging模块就有这个功能只要配置一下就可以了。
下面开搞引入logging库把项目的根路径取出来把上面config.ini中的日志配置取过来最后拼接好日志文件存放的绝对路径
import os
import logging
from Conf.Config import log_cfg
_BaseHome = os.path.abspath(os.path.dirname(os.path.dirname(__file__)))
_log_level = eval(log_cfg['log_level'])
_log_path = log_cfg['log_path']
_log_format = log_cfg['log_format']
_log_file = os.path.join(_BaseHome, _log_path, 'log.txt')
注意上面log_level的写法这里用了个eval如果不加这个函数log_level取过来是个字符串没法直接用通过eval执行后就变成了logging定义的对象了。
再配置日志引入TimedRotatingFileHandler这个东东这是实现滚动日志的。
from logging.handlers import TimedRotatingFileHandler
def log_init():
logger = logging.getLogger('main')
logger.setLevel(level=_log_level)
formatter = logging.Formatter(_log_format)
handler = TimedRotatingFileHandler(filename=_log_file, when="D", interval=1, backupCount=7)
handler.setLevel(_log_level)
handler.setFormatter(formatter)
logger.addHandler(handler)
console = logging.StreamHandler()
console.setLevel(_log_level)
console.setFormatter(formatter)
logger.addHandler(console)
这个日志里面加了两个输出handler用于向日志文件打印日志console 用于向终端打印日志两个的定义方式不同。
TimedRotatingFileHandler的参数简介
| 参数 | 意义 | 说明 |
|---|---|---|
| filename | 日志文件 | 没啥好说的 |
| when | 切割条件 | 按周(W)、天(D)、时(H)、分(M)、秒(S)切割 |
| interval | 间隔 | 就是几个when切割一次。when是Winterval是3的话就代表3周切割一次 |
| backupCount | 日志备份数量 | 就是保留几个日志文件起过这个数量就把最早的删除掉从而滚动删除 |
我这里配置的是每天生成1个日志文件保留7天的日志。
日志就做好了试一下效果。
log_init()
logger = logging.getLogger('main')
logger.info('log test----------')
运行结果
2021-03-15 21:53:41,972 - main - Log.py[line:49] - INFO - log test----------
其它文件使用日志
先在main.py里面引入这个log_init()在最开始的时候初始化一下日志就配置好了。
再在各个要使用日志的文件中直接按下面这种方式使用
import logging
logger = logging.getLogger('main.jd')
注意各个模块自己getLogger的时候直接main后面加上“.模块名”就能使用同一个logger区分模块了。
到这里日志功能就完成了。
顺手做个截图的功能供大家使用。截图可以直接在用例里面用selenium提供的截图功能也可以自己做一个公共的。下面是用PIL里面的功能做的截图。
from PIL import ImageGrab
# 先定义截图文件的存放路径这里在Log目录下建个Screen目录按天存放截图
_today = time.strftime("%Y%m%d")
_screen_path = os.path.join(_BaseHome, _log_path, 'Screen', _today)
#再使用PIL的ImageGrab实现截图
def screen(name):
t = time.time()
png = ImageGrab.grab()
if not os.path.exists(_screen_path):
os.makedirs(_screen_path)
image_name = os.path.join(_screen_path, name)
png.save('%s_%s.png' % (image_name, str(round(t * 1000)))) # 文件名后面加了个时间戳避免重名
运行这个方法就能截图了大功告成。截图文件其实也需要一个滚动删除后面有时间再写吧。
3. 读取EXCEL实现data
接着写一个读取EXCEL文件数据的功能吧这个项目里面主要是用来读测试数据以实现数据驱动。
python读取excel数据我看大家都喜欢用xlrd和xlwt还有用openpyxl的对于我这种懒人来讲都太麻烦了。
我们用pandas来干一句话的事情搞那么多干吗用python就是要快。
在Comm目录下新建一个data.py专门来处理数据。引入pandas直接用pandas的read_excel读excel而且支持它原始的其它参数只是最后将结果转了字典方便使用
import pandas as pd
def read_excel(file, **kwargs):
data_dict = []
try:
data = pd.read_excel(file, **kwargs)
data_dict = data.to_dict('records')
finally:
return data_dict
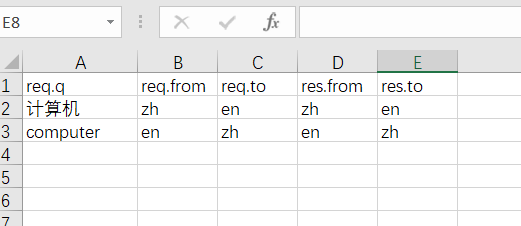
随便放一个excel在同一个目录下填上数据试一下效果。excel里面2页数据Sheet1如下

Sheet2如下
调用我们写好的方法打印数据
sheet1 = read_excel('baidu_fanyi.xlsx')
sheet2 = read_excel('baidu_fanyi.xlsx', sheet_name='Sheet2')
print(sheet1)
print(sheet2)
运行结果如下
[{'req.q': '计算机\n计算机', 'req.from': 'zh', 'req.to': 'en', 'res.from': 'zh', 'res.to': 'en', 'res.trans_result.0.src': '计算机', 'res.trans_result.0.dst': 'computer', 'res.trans_result.1.src': '计算机', 'res.trans_result.1.dst': 'computer'},
{'req.q': 'computer\nexpected value', 'req.from': 'en', 'req.to': 'zh', 'res.from': 'en', 'res.to': 'zh', 'res.trans_result.0.src': 'computer', 'res.trans_result.0.dst': '计算机', 'res.trans_result.1.src': 'expected value', 'res.trans_result.1.dst': '苹果'}]
[{'req.q': '计算机', 'req.from': 'zh', 'req.to': 'en', 'res.from': 'zh', 'res.to': 'en'},
{'req.q': 'computer', 'req.from': 'en', 'req.to': 'zh', 'res.from': 'en', 'res.to': 'zh'}]
每页数据都读出来了而且每一行都是字典形式直接通过key就可以方便的使用。
pandas还能直接计算数据如通过几个列算加密签名写动态cookie等使用方法也很简单。比如在数据中增加一列sign 让它简单等于 req.from列 + ‘.aaaa.’ + req.to列给大家演示一下。
data = pd.read_excel('baidu_fanyi.xlsx')
data['sign'] = data["req.from"] +'.aaaaa.' + data["req.to"]
data_dict = data.to_dict('records')
print(data_dict)
运行结果
[{'req.q': '计算机\n计算机', 'req.from': 'zh', 'req.to': 'en', 'res.from': 'zh', 'res.to': 'en', 'res.trans_result.0.src': '计算机', 'res.trans_result.0.dst': 'computer', 'res.trans_result.1.src': '计算机', 'res.trans_result.1.dst': 'computer', 'sign': 'zh.aaaaa.en'},
{'req.q': 'computer\nexpected value', 'req.from': 'en', 'req.to': 'zh', 'res.from': 'en', 'res.to': 'zh', 'res.trans_result.0.src': 'computer', 'res.trans_result.0.dst': '计算机', 'res.trans_result.1.src': 'expected value', 'res.trans_result.1.dst': '苹果', 'sign': 'en.aaaaa.zh'}]
我们可以看到多了一列sign值就是自动根据每一行的数据算出来的这对于我们数据驱动来讲去计算一些动态值非常有用。我这里没有用到动态的只是读而已。大家如果要计算就要自己写计算方法。
pandas还支持直接读各种主流数据库后面扩展也很方便我们一直都用它。
4. 邮件发送实现Email
实现邮件功能用于发送测试报告。使用python的smtplib模块实现。
先在Conf目录下的config.ini中添加好邮件相关的配置
[smtp]
host = smtp.163.com
port = 465
user = example@163.com
passwd = password
[email]
sender = example@163.com
receivers = example@qq.com, example@163.com
再在Config.py中将它们取到变量中放好
smtp_cfg = config['smtp']
email_cfg = config['email']
然后在Comm目录下新建Email.py开始撸代码。邮件支持了定义主题、正文和多个附件控制了单个附件大小和附件总数。代码如下
import smtplib
import os
import logging
from email.mime.text import MIMEText
from email.mime.application import MIMEApplication
from email.mime.multipart import MIMEMultipart
from email.header import Header
from Conf.Config import smtp_cfg, email_cfg
_FILESIZE = 20 # 单位M 单个附件大小
_FILECOUNT = 10 # 附件个数
_smtp_cfg = smtp_cfg
_email_cfg = email_cfg
_logger = logging.getLogger('main.email')
class Email:
def __init__(self, subject, context=None, attachment=None):
self.subject = subject
self.context = context
self.attachment = attachment
self.message = MIMEMultipart()
self._message_init()
def _message_init(self):
if self.subject:
self.message['subject'] = Header(self.subject, 'utf-8') # 邮件标题
else:
raise ValueError("Invalid subject")
self.message['from'] = _email_cfg['sender'] # from
self.message['to'] = _email_cfg['receivers'] # to
if self.context:
self.message.attach(MIMEText(self.context, 'html', 'utf-8')) # 邮件正文内容
# 邮件附件
if self.attachment:
if isinstance(self.attachment, str):
self._attach(self.attachment)
if isinstance(self.attachment, list):
count = 0
for each in self.attachment:
if count <= _FILECOUNT:
self._attach(each)
count += 1
else:
_logger.warning('Attachments is more than ', _FILECOUNT)
break
def _attach(self, file):
if os.path.isfile(file) and os.path.getsize(file) <= _FILESIZE * 1024 * 1024:
attach = MIMEApplication(open(file, 'rb').read())
attach.add_header('Content-Disposition', 'attachment', filename=os.path.basename(file))
attach["Content-Type"] = 'application/octet-stream'
self.message.attach(attach)
else:
_logger.error('The attachment is not exist or more than %sM: %s' % (_FILESIZE, file))
def send_mail(self):
s = smtplib.SMTP_SSL(_smtp_cfg['host'], int(_smtp_cfg['port']))
result = True
try:
s.login(self._smtp_cfg['user'], self._smtp_cfg['passwd'])
s.sendmail(self._smtp_cfg['sender'], self._smtp_cfg['receivers'], self.message.as_string())
except smtplib.SMTPException as e:
result = False
_logger.error('Send mail failed', exc_info=True)
finally:
s.close()
return result
邮件初始化发送时的调用方式如下
mail = Email(title, context, file)
send = mail.send_mail()
print(send)
返回结果为True则发送成功否则发送失败。
四、WEB UI自动化
WEB UI自动化采用 selenium来完成。通过PO对象、测试数据、业务逻辑三者分离的方式来实现。
另外一个主旨是尽量让测试人员使用selenium原生的各种方法而不要做过多封装。原因很简单不要让测试人员来学这个框架而是去学selenium这样以后他出去换工作才有饭吃。如果过度封装就会让测试人员来学这个框架他以后出去selenium都不会用这不是害了别人么。框架的目的只是把对象、数据、业务逻辑三者驱动起来让测试人员工作起来更快。
我们以京东搜索爬虫为例来看如何构建这三者的关系在京东主页面搜索“电脑”再获取搜索结果保存。
1. 页面PO对象配置
打开京东商城主页找到搜索框元素、和搜索按钮元素分别确定他们的定位方式以及元素对应的操作。
然后建立这个页面对象在Page下新建一个名为"jd"的python package再在这个package下新建一个jd.py用来定义京东商城的主页面对象。
from selenium.webdriver.common.by import By
page_url = 'https://www.jd.com'
elements = [
{'name': 'search_ipt', 'desc': '搜索框点击', 'by': (By.ID, u'key'), 'ec': 'presence_of_element_located', 'action': 'send_keys()'},
{'name': 'search_btn', 'desc': '搜索按钮点击', 'by': (By.CLASS_NAME, u'button'), 'ec': 'presence_of_element_located', 'action': 'click()'},
]
name: 每个元素+操作的唯一标识。一个元素可能由于操作不同而要定义多个但大部分只要定义一个。
desc:元素+操作的描述。
by:元素的定位方式使用selenium的原生定位方式不自己定义封装。
ec: 等待元素出现的方式这个暂时未用。
action:元素的对应操作。使用原生的selenium动作方法不自己定义封装。
京东商城主页面现在只用到这两个就只定义这两个。
搜索结果页面定义如下
from selenium.webdriver.common.by import By
page_url = 'https://search.jd.com/'
elements = [
{'name': 'result_list', 'desc': '结果列表', 'by': (By.CLASS_NAME, u'gl-item'), 'ec': 'presence_of_all_elements_located', 'action': None},
{'name': 'price', 'desc': '价格', 'by': (By.XPATH, u".//div[@class='p-price']/strong/i"), 'ec': 'presence_of_element_located', 'action': 'text'},
{'name': 'pname', 'desc': '描述', 'by': (By.XPATH, u".//div[@class='p-name p-name-type-2']/a/em"), 'ec': 'presence_of_element_located', 'action': 'text'}
]
2. 实现basePage基类
basePage基类的实现思想是不做过多的封装尽量让测试人员直接使用selenium原装的方法而不像其它框架一样什么都封装在这里面。
所以我对basePage的定义是根据业务逻辑测试用例指定的元素输入的数据协助它完成元素定位和操作仅此而已。
当然如果去封装各种东西也是可以的直接在里面加就行了。
在Page目录下新建basePage.py开始撸代码
from selenium.webdriver.common.by import By
from selenium import webdriver
import os
import importlib
import logging
SimpleActions = ['clear()', 'send_keys()', 'click()', 'submit()', 'size', 'text', 'is_displayed()', 'get_attribute()']
logger = logging.getLogger('main.page')
class Page(object):
def __init__(self, driver, page):
self.driver = driver
self.page = page
self.elements = get_page_elements(page)
self.by = ()
self.action = None
def _get_page_elem(self, elem):
# 获取定位元素的 by以及操作action
for each in self.elements:
if each['name'] == elem:
self.by = each['by']
if 'action' in each and each['action'] is not None:
self.action = each['action']
else:
self.action = None
def oper_elem(self, elem, args=None):
self._get_page_elem(elem)
cmd = self._selenium_cmd('find_element', args)
return eval(cmd)
def oper_elems(self, elem, args=None):
self._get_page_elem(elem)
cmd = self._selenium_cmd('find_elements', args)
return eval(cmd)
def _selenium_cmd(self, find_type='find_element', args=None):
# 拼接 selenium 查找命令 查找单个元素时find_type为'find_element'多个元素时为'find_elements'
cmd = 'self.driver.' + find_type + '(*self.by)'
if self.action:
if self.action in SimpleActions:
cmd = cmd + '.' + self.action
if args:
cmd = cmd[:-1] + 'args' + ')'
return cmd
def get_page_elements(page):
"""动态加载页面定义文件获取文件中定义的元素列表elements"""
elements = None
if page:
try:
m = importlib.import_module(page)
elements = m.elements
except Exception as e:
logger.error('error info : %s' %(e))
return elements
这里面主要的只包含3个方法一个是动态加载指定的PO对象获取元素列表一个是在获取的元素列表中去找到当前要操作的元素最后一个就是拼接原生的selenium命令将测试数据插入到动作里面去。
其它的就简单了直接调用selenium运行拼接出来的命令把结果返回出去。
这里要注意的是有些复杂的selenium操作不能这么简单的拼命令要特殊处理这里暂时没弄简单的命令也没有列全。后面再慢慢加。
3. 写业务测试用例
下面开始写测试用例。
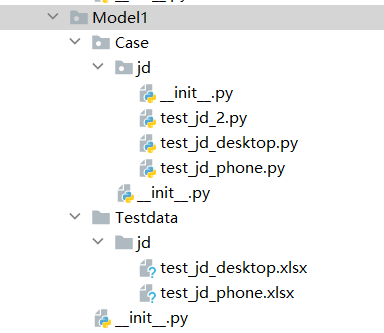
在Testcase目录下新建一个python packageModel1。在Model1下面再建一个目录Testdata用于放测试数据建一个python packageCase用于放用例脚本。目录结构如下
准备测试数据
准备一份excel数据test_jd_desktop.xlsx存放在Model1/Testdata/jd下
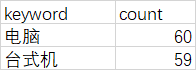
keyword:搜索的关键字
count:搜索结果总数只抓了一页应该是60个
实现业务用例
在Model1/Case/jd下新建一个文件test_jd_desktop.py开始写用例脚本。
用例使用unittest结合DDT来实现具体代码如下
import os
import unittest
import ddt
import logging
from selenium import webdriver
from time import sleep
from Page.basePage import Page
from Comm.Log import screen
from Comm.data import read_excel
from main import TestCasePath
logger = logging.getLogger('main.jd')
# 读取测试数据
file = os.path.join(TestCasePath, 'Model1/Testdata/jd/test_jd_desktop.xlsx')
test_data = read_excel(file)
PO_jd = 'Page.jd.jd'
PO_search = 'Page.jd.search_jd'
@ddt.ddt # 数据驱动
class TestJdSearchDesktop(unittest.TestCase):
"""京东搜索测试"""
def setUp(self):
self.driver = webdriver.Chrome()
self.count = 0
self.result = []
@ddt.data(*test_data) # 数据驱动传具体数据
def testJdSearchDesktop(self, test_data):
"""京东搜索测试--电脑"""
url = 'https://www.jd.com'
keyword = test_data['keyword']
wait = self.driver.implicitly_wait(5)
try:
self.driver.get(url)
# 实例化jd主页面
jd = Page(self.driver, PO_jd)
# 实例化jd搜索结果页面
jd_search = Page(self.driver, PO_search)
wait
# jd主页面的搜索框元素中输入关键字
jd.oper_elem('search_ipt', keyword)
wait
# 操作jd主页面的搜索按钮元素
jd.oper_elem('search_btn')
sleep(1)
self.driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
sleep(1)
# jd搜索结果页面获取结果列表
lis = jd_search.oper_elems('result_list')
# 在取到的结果列表中循环获取商品价格和商品名称结果存EXCEL就没写了
for each in lis:
self.count += 1
page_each = Page(each, PO_search)
price = page_each.oper_elem('price')
name = page_each.oper_elem('pname')
self.result.append([name, price])
sleep(1)
except Exception as E:
logger.error('error info : %s' % (E))
screen(test_data['keyword'])
# 判断是不是取到了60个商品
self.assertEqual(test_data['count'], self.count)
def tearDown(self):
self.driver.quit()
五、实现主程序
主程序的主要作用是 组织用例执行用例生成报告发送测试报告邮件。
组织用例和执行用例都直接用unittest
生成报告采用BeautifulReport
下面开始撸main.py的代码
import unittest
import os
import time
import logging
from Comm.Email import Email
from Comm.Log import log_init
from BeautifulReport import BeautifulReport
# 定义各目录
ProjectHome = os.path.split(os.path.realpath(__file__))[0]
PageObjectPath = os.path.join(ProjectHome, "Page")
TestCasePath = os.path.join(ProjectHome, "Testcase")
ReportPath = os.path.join(ProjectHome, "Report")
#对测试结果关键信息进行汇总做为邮件正文
def summary_format(result):
summary = "\n" + u"<p> 测试结果汇总信息 </p>" + "\n" + \
u"<p> 开始时间: " + result['beginTime'] + u" </p>" + "\n" + \
u"<p> 运行时间: " + result['totalTime'] + u" </p>" + "\n" + \
u"<p> 执行用例数: " + str(result['testAll']) + u" </p>" + "\n" + \
u"<p> 通过用例数: " + str(result['testPass']) + u" </p>" + "\n" + \
u"<p> 失败用例数: " + str(result['testFail']) + u" </p>" + "\n" + \
u"<p> 忽略用例数: " + str(result['testSkip']) + u" </p>" + "\n"
return summary
# 发送邮件
def send_email(file, context):
title = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()) + '自动化测试结果'
mail = Email(title, context, file)
send = mail.send_mail()
if send:
print('测试报告邮件发送成功')
else:
print('测试报告邮件发送失败')
# 加载测试用例
def get_suite(case_path=TestCasePath, rule="test_*.py"):
"""加载所有的测试用例"""
unittest_suite = unittest.TestSuite()
discover = unittest.defaultTestLoader.discover(case_path, pattern=rule, top_level_dir=None)
for each in discover:
unittest_suite.addTests(each)
return unittest_suite
# 执行用例生成测试报告并返回报告附件路径、邮件正文内容
def suite_run(unittest_suite):
"""执行所有的用例, 并把结果写入测试报告"""
run_result = BeautifulReport(unittest_suite)
now = time.strftime("%Y%m%d%H%M%S", time.localtime())
filename = now + '_report.html'
run_result.report(filename=filename, description=now, report_dir=ReportPath)
rpt_summary = summary_format(run_result.fields)
return os.path.join(ReportPath, filename), rpt_summary
# 主程序加载用例执行用例发送邮件
if __name__ == "__main__":
suite = get_suite()
report_file, report_summary = suite_run(suite)
print(report_summary)
send_email(report_file, report_summary)
运行主程序就可以把WEB UI自动化跑起来了。
六、API 自动化
API自动化采用 request库来完成。还是通过PO对象、测试数据、业务逻辑三者分离的方式来实现。
这里以百度通用翻译接口为例这个接口对个人用户是免费的大家可以自己去申请。
1. API对象配置
在APIs下面新建python packagefanyi再在fanyi下面建baidu.py。
将百度通用翻译接口定义在这里面直接采用大家熟悉的json格式
"""百度通用翻译接口"""
API_NAME = 'fanyi'
# 地址信息
uri_scheme = 'http'
endpoint = 'api.fanyi.baidu.com'
resource_path = '/api/trans/vip/translate'
url = uri_scheme + u'://' + endpoint + resource_path
# 保持不变的参数
_from = 'en'
_to = 'zh'
# 请求消息参数
req_param = {
"q": "", # 请求翻译 query, UTF-8
"from": _from, # 翻译源语言
"to": _to, # 翻译目标语言
"appid": "", # APP ID
"salt": "", # 随机数
"sign": "", # 签名appid+q+salt+密钥 的MD5值
}
# 响应消息参数
res_param = {
"from": _from,
"to": _to,
"trans_result": [
{
"src": "Hello World! This is 1st paragraph.",
"dst": "你好世界这是第一段。"
},
{
"src": "This is 2nd paragraph.",
"dst": "这是第二段。"
}
]
}
2.实现base_api基类
base_api基类主要是将数据、API对象、测试用例三者连起来
在APIs目录下新建base_api.py代码如下
import logging
import random
import importlib
import copy
import json
import unittest
from hashlib import md5
from ipaddress import ip_address
from Comm.compare import json_compare
logger = logging.getLogger('main.api')
req_prefix = 'req.'
res_prefix = 'res.'
def _separate_data(data, prefix='req.'):
pfx = prefix
result = {}
for key, value in data.items():
if key.startswith(pfx):
req_key = key[len(pfx):]
result[req_key] = value
return result
def _get_cmd(key, dict_name='payload'):
separator = '.'
cmd = dict_name
if separator in key:
data_key = key.split(separator)
for each in data_key:
if each.isdigit():
cmd = cmd + '[' + each + ']'
else:
cmd = cmd + '[\'' + each + '\']'
cmd = cmd + ' = value'
else:
cmd = cmd + '[key] = value'
return cmd
def check_result(unittest_testcase, x, y):
# 只有x,y完全相同才能通过任意不同则返回失败。建议自己在用例中做结果检查
testcase = unittest_testcase
diff = json_compare(x, y)
testcase.assertEqual(x, y)
class BaseAPI(object):
def __init__(self, api):
self.api = api
self.api_name = None
self.url = ''
self.req_template = {}
self.res_template = {}
self._get_api_param()
def _get_api_param(self):
"""动态加载API定义文件获取文件中定义的API参数"""
try:
m = importlib.import_module(self.api)
self.api_name = m.API_NAME
self.url = m.url
self.req_template = m.req_param
self.res_template = m.res_param
except Exception as e:
logger.error('error info : %s' % e)
def payload(self, data=None):
payload = copy.deepcopy(self.req_template)
if data:
req_pre = '.'.join([self.api_name, req_prefix])
req_data = _separate_data(data, req_pre)
for key, value in req_data.items():
cmd = _get_cmd(key, 'payload')
exec(cmd)
return payload
def load_expected(self, data=None):
expected = copy.deepcopy(self.res_template)
if data:
res_pre = '.'.join([self.api_name, res_prefix])
res_data = _separate_data(data, res_pre)
for key, value in res_data.items():
cmd = _get_cmd(key, 'expected')
exec(cmd)
return expected
这里面的思路是
- 动态加载API对象获取API请求参数模板、和响应参数模板
- payload的时候从测试数据中取出API请求相关的数据以API名.req开头如fanyi.req.q填入模板没有的就用模板数据
- 加载预期结果的时候从测试数据中取出API响应相关的数据以API名.res开头如fanyi.res.trans_result.0.src填入模板没有的就用模板数据。
- 提供json比较的方法
- 提供了一个随机handers。
具体的大家看一下就明白了。想进一步封装的还可以继续封装比如生成hearders数据配完了直接发送取到结果直接比对什么的。但是建议不要过度封装。
附json比较的方法
import json_tools
def json_compare(x, y):
diff = json_tools.diff(x, y)
if diff:
for action in diff:
if 'add' in action:
print('++增加元素:', action['add'], ' 值:', action['value'])
elif 'remove' in action:
print('--删除元素:', action['remove'], ' 值:', action['prev'])
elif 'replace' in action:
print('**修改元素:', action['replace'], ' 值:', action['prev'], '-->', action['value'])
return diff
3.测试用例
在Testcase下建API模块API模块下建Case和Testdata分别放用例和数据目录如下
定义测试数据
测试数据需要按一定的格式处理即每个参数以api名称开头用“.”连接然后用res和req来区分响应还是请求后面就是具体的参数了多级参数以“.”连接。具体如下

测试用例脚本
仍然用unittest和ddt来实现。
import os
import unittest
import ddt
import random
import json
import requests
from time import sleep
from Comm.data import read_excel
from Comm.encryption import make_md5
from main import TestCasePath
from APIs.base_api import BaseAPI, check_result
# 开通普通个人的百度翻译接口设置appid和appkey.
app_id = your appid
app_key = your appkey
# 获取测试数据
file = os.path.join(TestCasePath, 'API/TestData/baidu_fanyi.xlsx')
test_data = read_excel(file)
api = 'APIs.fanyi.baidu'
@ddt.ddt
class TestBaiduFanyi(unittest.TestCase):
"""百度翻译接口测试"""
def setUp(self):
self.api = BaseAPI(api)
@ddt.data(*test_data)
def test_baidu_fanyi(self, test_data):
"""百度翻译接口测试"""
api = self.api
# Build test_data这是些动态参数在这里计算
test_data['fanyi.req.appid'] = app_id
salt = random.randint(32768, 65536)
test_data['fanyi.req.salt'] = salt
sign = make_md5(app_id + test_data['fanyi.req.q'] + str(salt) + app_key)
test_data['fanyi.req.sign'] = sign
# Build request
headers = {'Content-Type': 'application/x-www-form-urlencoded'}
payload = api.payload(test_data )
# Send request
r = requests.post(api.url, params=payload, headers=headers)
result = r.json()
expected = api.load_expected(test_data)
self.assertEqual(r.status_code, 200)
check_result(self, expected, result) # 简单的模板验证大家最好自己写验证。
sleep(0.5)
然后运行主程序API自动化测试也就可以跑起来了。
补MD5函数
from hashlib import md5
def make_md5(s, encoding='utf-8'):
return md5(s.encode(encoding)).hexdigest()