

Hadoop3教程(三十四):(生产调优篇)MapReduce生产经验汇总-CSDN博客
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
文章目录
164MR跑得慢的原因
MR程序执行效率的瓶颈或者说当你觉得你的MR程序跑的比较慢的时候可以从以下两点来分析
- 计算机性能
节点的CPU、内存、磁盘、网络等这种属于硬件上的检查
- IO操作上的检查
- 是否发生了数据倾斜即单一reduce处理了绝大部分数据
- Map运行时间过长导致Reduce一直在等待
- 小文件过多。
165MR常用调优参数
Map阶段
Map阶段:
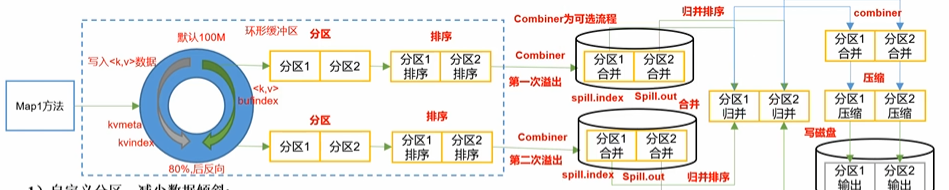
1自定义分区减少数据倾斜。即自定义分区类继承Partitioner接口重写getPartition()
2减少环形缓冲区溢写的次数
mapreduce.task.io.sort.mbshuffle的环形缓冲区大小默认是100M可以提高至200Mmapreduce.map.sort.spill.percent环形缓冲区的溢出阈值默认是80%可以提高至90%。即写到90%的时候才溢出。
这样做的目的是减少环形缓冲区溢写后形成的文件的个数减少后面步骤里分区合并的压力。
3增加每次Merge合并次数
mapreduce.task.io.sort.factor分区归并时每次归并的文件数量。默认是10可以提高到20如果你的内存足够支撑的话否则只能调小了
4在不影响业务结果的前提下可以开启Combiner:
job.setCombinerClass(xxxReducer.class);
5为了减少磁盘IO对于Map的输出文件可以采用snappy或者LZO压缩。
6提高MapTask的内存上限
mapreduce.map.memory.mb默认内存上限是1024MB。通常来讲1G内存用来处理128M数据是绰绰有余的可以根据128M数据对应1G内存的原则对应提高内存。
7调整MapTask的堆内存大小
mapreduce.map.java.opts跟上面的内存参数保持一致就可以。控制java用的内存
8增加MapTask的CPU核数。
mapreduce.map.cpu.vcores默认核数是1对于计算密集型任务可以增加CPU核数
9异常重试次数
mapreduce.map.maxattempts每个MapTask的最大重试次数一旦重试次数超过该值则认为MapTask运行失败默认值是4。可以根据实际情况做加减。
Reduce阶段
Reduce阶段
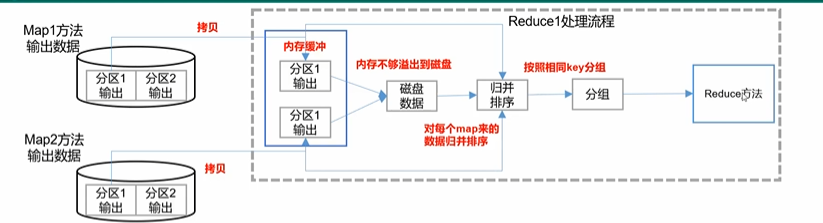
1调整每个Reduce一次性从多少个MapTask拉取数据。
mapreduce.reduce.shuffle.parallelecopies默认是5即每个Reduce一次最多拉5个MapTask里的数据如果内存足够支撑完全可以调成10
2调整所拉取数据在内存缓冲的占比。
mapreduce.reduce.shuffle.input.buffer.percent控制内存buffer大小占ReduceTask可用内存的比例。默认是0.7可以提高到0.8。毕竟在内存中缓存的数据越多整体计算速度就越快。
3控制归并排序时可以使用的内存比例
mapreduce.reduce.shuffle.merge.percent简单的说就是归并排序时可以使用的内存占Reduce总可用内存的比例超过这个比例就只能溢出到磁盘了。这个比例默认是0.66最高可以提高到0.75。
4调整ReduceTask的可用内存上限
mapreduce.reduce.memory.mb默认可用内存上限为1024MB。同样的128M数据对应1G内存原则。适当提升内存到4-6G。
5调整ReduceTask的堆内存
mapreduce.reduce.java.opts
6调整ReduceTask的CPU核数
mapreduce.reduce.cpu.vcores默认核数是1可以提高到2-4个
7最大重试次数
mapreduce.reduce.maxattemptsReduceTask的最大重试次数一旦重试次数超过该值则认为运行失败。默认是4。
8当MapTask的完成比例达到多少时才会为ReduceTask申请资源
mapreduce.job.reduce.slowstart.completedmaps默认是0.05即有5%的MapTask完成任务后就可以为ReduceTask申请资源。
9Task的超时时间
mapreduce.task.timeout控制task的超时时间默认是600000毫秒即10min。如果一个Task在10min内没有数据进入也没有数据输出则直接退出该任务。如果你的程序对每条输出数据的处理时间很长可适当调大这个参数。
10如果可以不用Reduce那就尽量不用。
166MR数据倾斜问题
直观来看就是在大部分任务都已经完成了的情况下还有少数任务仍在运行这时候大概率就是发生了数据倾斜分给那少数任务的数据太多了导致它们一直没有处理完。
当发生数据倾斜后我们可以从哪些角度考虑优化呢
- 首先是检查是否是由于空值过多key造成的数据倾斜
生产环境下可以选择过滤掉空值如果一定要保留空值的话可以自定义分区将空值加随机数打散分布。
- 能在Map阶段提前处理的就在Map阶段提前处理。比如说Map阶段的Combiner、MapJoin等
- 设置多个reduce个数
参考文献
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |