

吴恩达《机器学习》——神经网络与反向传播
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
神经网络与反向传播
数据集、源文件可以在Github项目中获得
链接: https://github.com/Raymond-Yang-2001/AndrewNg-Machine-Learing-Homework
1. 神经网络
回顾我们在上一篇博客当中使用到的神经网络结构
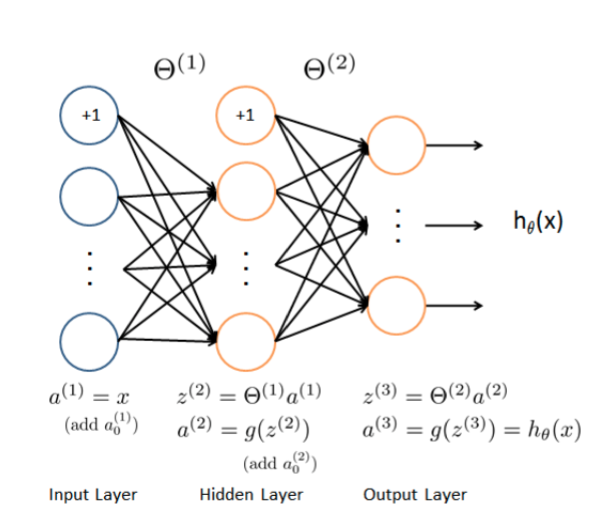
这是一个较为简单的三层神经网络输入层、隐藏层、输出层的各个单元之间“全部相连”我们也称这样的神经网络叫做多层感知机Multilayer Perceptrons, MLP。
MLP在很多领域都有运用经常被用来拟合一些不是十分负责的映射关系。除去单独作为一个模型进行使用外还经常被用在大型的网络和算法当中负责一部分功能。例如在元学习算法中可以用MLP来拟合某些超参。
接下来我们会对这个三层MLP进行正向和逆向传播的分析。
1.1 神经网络的前馈传播
相对于反向传播求梯度神经网络的前馈传播并不复杂。利用前馈传播我们可以从输入获得输出。
在输入层设
a
(
1
)
=
x
a^{(1)}=x
a(1)=x添加
a
0
(
1
)
=
0
a^{(1)}_{0}=0
a0(1)=0使得偏置项的计算更加方便。
在隐藏层有
z
(
2
)
=
θ
(
1
)
a
(
1
)
z^{(2)}=\theta^{(1)}a^{(1)}
z(2)=θ(1)a(1)
a
(
2
)
=
σ
(
z
(
2
)
)
a^{(2)}=\sigma(z^{(2)})
a(2)=σ(z(2))这相当于做了一次线性运算并使用激励函数进行非线性的变换。同时也在这里添加
a
0
(
2
)
=
0
a^{(2)}_{0}=0
a0(2)=0。
在输出层
z
(
3
)
=
θ
(
2
)
a
(
2
)
z^{(3)}=\theta^{(2)}a^{(2)}
z(3)=θ(2)a(2)
a
(
3
)
=
σ
(
z
(
3
)
)
=
h
(
θ
;
x
)
a^{(3)}=\sigma(z^{(3)})=h(\theta;x)
a(3)=σ(z(3))=h(θ;x)得到网络的输出。
1.2 利用反向传播求梯度
在训练神经网络的时候我们需要对每一层求得梯度矩阵并以此来更新参数。
对于最后一层的梯度因为最后一层相当于对输入的
a
(
2
)
a^{(2)}
a(2)做了一个Logistic回归运算所以我们可以直接使用在Logistic回归中的梯度公式具体推导在https://blog.csdn.net/d33332/article/details/128511062。有
∂
J
∂
θ
i
,
j
(
2
)
=
(
a
(
3
)
−
y
)
a
i
,
j
(
2
)
\frac{\partial{J}}{\partial{\theta^{(2)}_{i,j}}}=(a^{(3)}-y)a^{(2)}_{i,j}
∂θi,j(2)∂J=(a(3)−y)ai,j(2)
但是对于其他层的梯度就不能套用这个公式了。下面将给出更一般的求梯度过程
设 z ( k ) = θ ( k − 1 ) a ( k − 1 ) z^{(k)}=\theta^{(k-1)}a^{(k-1)} z(k)=θ(k−1)a(k−1)则有 ∂ z ( k ) ∂ θ i , j ( k − 1 ) = a j ( k − 1 ) \frac{\partial{z^{(k)}}}{\partial{\theta^{(k-1)}_{i,j}}}=a^{(k-1)}_{j} ∂θi,j(k−1)∂z(k)=aj(k−1)。
另有 a ( k ) = σ ( z ( k ) ) a^{(k)}=\sigma{(z^{(k)})} a(k)=σ(z(k))。
根据链式法则
∂
J
∂
θ
i
,
j
(
k
−
1
)
=
∂
J
∂
z
i
(
k
)
∂
z
i
(
k
)
∂
θ
i
,
j
(
k
−
1
)
\frac{\partial{J}}{\partial{\theta^{(k-1)}_{i,j}}}=\frac{\partial{J}}{\partial{z^{(k)}_{i}}}\frac{\partial{z^{(k)}_{i}}}{\partial{\theta^{(k-1)}_{i,j}}}
∂θi,j(k−1)∂J=∂zi(k)∂J∂θi,j(k−1)∂zi(k)
现在需要求J对z的偏导过程如下以输入一个样本为例设
∂
J
∂
z
(
k
)
=
δ
(
k
)
=
[
∂
J
∂
z
1
(
k
)
∂
J
∂
z
2
(
k
)
⋯
]
\frac{\partial{J}}{\partial{z^{(k)}}}=\delta^{(k)}=\left[ \begin{matrix} \frac{\partial{J}}{\partial{z^{(k)}_{1}}} & \frac{\partial{J}}{\partial{z^{(k)}_{2}}} & \cdots \end{matrix} \right]
∂z(k)∂J=δ(k)=[∂z1(k)∂J∂z2(k)∂J⋯]
则有
∂
J
∂
z
i
(
k
)
=
δ
i
(
k
)
\frac{\partial{J}}{\partial{z^{(k)}_{i}}}=\delta^{(k)}_{i}
∂zi(k)∂J=δi(k)
δ
i
(
k
)
=
∂
J
∂
a
i
(
k
)
⋅
∂
a
i
(
k
)
∂
z
i
(
k
)
=
(
∂
J
∂
z
1
(
k
+
1
)
⋅
∂
z
1
(
k
+
1
)
∂
a
i
(
k
)
+
∂
J
∂
z
2
(
k
+
1
)
⋅
∂
z
2
(
k
+
1
)
∂
a
i
(
k
)
+
⋯
)
(
σ
′
(
z
i
(
k
)
)
)
=
(
∑
j
=
1
D
k
+
1
∂
J
∂
z
j
(
k
+
1
)
⋅
∂
z
j
(
k
+
1
)
∂
a
i
(
k
)
)
(
σ
′
(
z
i
(
k
)
)
)
=
(
∑
j
=
1
D
k
+
1
∂
J
∂
z
j
(
k
+
1
)
⋅
∂
∑
m
=
1
D
k
θ
j
,
m
(
k
)
⋅
a
m
(
k
)
∂
a
i
(
k
)
)
(
σ
′
(
z
i
(
k
)
)
)
=
(
∑
j
=
1
D
k
+
1
∂
J
∂
z
j
(
k
+
1
)
⋅
θ
j
,
i
(
k
)
)
(
σ
′
(
z
i
(
k
)
)
)
=
(
∑
j
=
1
D
k
+
1
δ
j
(
k
+
1
)
⋅
θ
j
,
i
(
k
)
)
(
σ
′
(
z
i
(
k
)
)
)
\begin{aligned} \delta^{(k)}_{i}&=\frac{\partial{J}}{\partial{a^{(k)}_{i}}}\cdot \frac{\partial{a^{(k)}_{i}}}{\partial{z^{(k)}_{i}}} \\ &=\left(\frac{\partial{J}}{\partial{z^{(k+1)}_{1}}}\cdot\frac{\partial{z^{(k+1)}_{1}}}{\partial{a^{(k)}_{i}}}+\frac{\partial{J}}{\partial{z^{(k+1)}_{2}}}\cdot\frac{\partial{z^{(k+1)}_{2}}}{\partial{a^{(k)}_{i}}}+\cdots\right)(\sigma^{\prime}(z^{(k)}_{i})) \\ &=\left(\sum_{j=1}^{D_{k+1}}{\frac{\partial{J}}{\partial{z^{(k+1)}_{j}}}\cdot\frac{\partial{z^{(k+1)}_{j}}}{\partial{a^{(k)}_{i}}}}\right)(\sigma^{\prime}(z^{(k)}_{i}))\\ &=\left(\sum_{j=1}^{D_{k+1}}{\frac{\partial{J}}{\partial{z^{(k+1)}_{j}}}\cdot\frac{\partial{\sum_{m=1}^{D_{k}}{\theta^{(k)}_{j,m}\cdot a_{m}^{(k)}}}}{\partial{a^{(k)}_{i}}}}\right)(\sigma^{\prime}(z^{(k)}_{i}))\\ &=\left(\sum_{j=1}^{D_{k+1}}{\frac{\partial{J}}{\partial{z^{(k+1)}_{j}}}}\cdot\theta^{(k)}_{j,i}\right)(\sigma^{\prime}(z^{(k)}_{i}))\\ &=\left(\sum_{j=1}^{D_{k+1}}{\delta^{(k+1)}_{j}}\cdot\theta^{(k)}_{j,i}\right)(\sigma^{\prime}(z^{(k)}_{i}))\\ \end{aligned}
δi(k)=∂ai(k)∂J⋅∂zi(k)∂ai(k)=(∂z1(k+1)∂J⋅∂ai(k)∂z1(k+1)+∂z2(k+1)∂J⋅∂ai(k)∂z2(k+1)+⋯)(σ′(zi(k)))=(j=1∑Dk+1∂zj(k+1)∂J⋅∂ai(k)∂zj(k+1))(σ′(zi(k)))=(j=1∑Dk+1∂zj(k+1)∂J⋅∂ai(k)∂∑m=1Dkθj,m(k)⋅am(k))(σ′(zi(k)))=(j=1∑Dk+1∂zj(k+1)∂J⋅θj,i(k))(σ′(zi(k)))=(j=1∑Dk+1δj(k+1)⋅θj,i(k))(σ′(zi(k)))
其中k指明了网络的第几层
D
k
D_{k}
Dk则是第k层的单元数量。
到这一步实际上是两个向量做内积。
δ
i
(
k
)
=
(
(
δ
(
k
+
1
)
⋅
θ
:
,
i
(
k
)
)
(
σ
′
(
z
i
(
k
)
)
)
\delta^{(k)}_{i}=((\delta^{(k+1)}\cdot\theta^{(k)}_{:,i})(\sigma^{\prime}(z^{(k)}_{i}))
δi(k)=((δ(k+1)⋅θ:,i(k))(σ′(zi(k)))
现在有
∂
J
∂
θ
i
,
j
(
k
−
1
)
=
δ
i
(
k
)
a
j
(
k
−
1
)
\frac{\partial{J}}{\partial{\theta^{(k-1)}_{i,j}}}=\delta^{(k)}_{i}a^{(k-1)}_{j}
∂θi,j(k−1)∂J=δi(k)aj(k−1)
此时以题目为例
δ
(
3
)
=
[
10
,
n
]
\delta^{(3)}=[10,n]
δ(3)=[10,n]
θ
(
2
)
=
[
10
,
26
]
\theta^{(2)}=[10,26]
θ(2)=[10,26]保证按样本维度对齐做向量内积需要转置
δ
(
3
)
\delta^{(3)}
δ(3)结果为维度为
[
n
,
26
]
[n,26]
[n,26]
z
(
2
)
=
[
25
,
n
]
z^{(2)}=[25,n]
z(2)=[25,n]按样本维度对齐再做一次转置。
δ
(
k
)
=
(
δ
(
k
+
1
)
)
⊤
⋅
θ
(
k
)
)
⊤
.
∗
(
σ
′
(
z
(
k
)
)
)
\delta^{(k)}=(\delta^{(k+1)})^{\top}\cdot\theta^{(k)})^{\top}.*(\sigma^{\prime}(z^{(k)}))
δ(k)=(δ(k+1))⊤⋅θ(k))⊤.∗(σ′(z(k)))
其中
.
∗
.*
.∗是逐元素乘法。
由线性代数知识可得
δ
(
k
)
=
(
(
θ
(
k
)
)
⊤
⋅
δ
(
k
+
1
)
)
.
∗
(
σ
′
(
z
(
k
)
)
)
\delta^{(k)}=((\theta^{(k)})^{\top}\cdot\delta^{(k+1)}).*(\sigma^{\prime}(z^{(k)}))
δ(k)=((θ(k))⊤⋅δ(k+1)).∗(σ′(z(k)))
这里
θ
(
2
)
=
[
10
,
26
]
\theta^{(2)}=[10,26]
θ(2)=[10,26]
a
(
2
)
=
[
26
,
n
]
a^{(2)}=[26,n]
a(2)=[26,n]
∂ z ( k ) ∂ θ i , j ( k − 1 ) = a j , : ( k − 1 ) \frac{\partial{z^{(k)}}}{\partial{\theta^{(k-1)}_{i,j}}}=a^{(k-1)}_{j,:} ∂θi,j(k−1)∂z(k)=aj,:(k−1)形状为 [ n , ] [n,] [n,]
带入链式法则,注意矩阵运算要按照样本维度对齐
∂
J
∂
θ
(
k
−
1
)
=
∂
J
∂
z
(
k
)
∂
z
(
k
)
∂
θ
(
k
−
1
)
=
δ
(
k
)
(
a
(
k
−
1
)
)
⊤
/
N
\frac{\partial{J}}{\partial{\theta^{(k-1)}}}=\frac{\partial{J}}{\partial{z^{(k)}}}\frac{\partial{z^{(k)}}}{\partial{\theta^{(k-1)}}}=\delta^{(k)}(a^{(k-1)})^{\top}/N
∂θ(k−1)∂J=∂z(k)∂J∂θ(k−1)∂z(k)=δ(k)(a(k−1))⊤/N
在最后除以样本数量N得到每个参数对每个样本的平均梯度。其中 δ ( k ) \delta^{(k)} δ(k)是递归计算得到的。为此我们规定最后一层的 δ ( K ) = h ( θ ; x ) − y \delta^{(K)}=h(\theta;x)-y δ(K)=h(θ;x)−y。
到这里也很容易理解求梯度的算法为什么被叫做反向传播了。因为我们需要从最后一层开始逐次向前求得每一层参数的梯度。
1.2.1 正则化梯度
正则化后的梯度公式如下
∂
J
∂
θ
(
k
−
1
)
R
E
G
=
δ
(
k
)
(
a
(
k
−
1
)
)
⊤
/
N
+
λ
N
θ
k
−
1
\frac{\partial{J}}{\partial{\theta^{(k-1)}}}_{REG}=\delta^{(k)}(a^{(k-1)})^{\top}/N+\frac{\lambda}{N}\theta^{k-1}
∂θ(k−1)∂JREG=δ(k)(a(k−1))⊤/N+Nλθk−1
2. 目标函数损失函数
对于神经网络多分类问题我们仍然使用交叉熵函数作为损失函数。但是吴恩达老师所讲解的函数和常规意义上的交叉熵函数并不完全相同接下来我们将对此进行分析。
2.1 PyTorch官方文档版本
L
o
s
s
=
−
∑
k
=
1
K
q
(
k
∣
x
)
log
p
(
k
∣
x
)
Loss = -\sum_{k=1}^{K}{ q(k|x)\log{p(k|x)}}
Loss=−k=1∑Kq(k∣x)logp(k∣x)
这实际上就是标准数学意义上的交叉熵能够衡量目标分布
q
q
q和既有分布
p
p
p之间的差异。
2.2 吴恩达讲解版本
L
o
s
s
=
−
[
∑
k
=
1
K
q
(
k
∣
x
)
log
p
(
k
∣
x
)
+
(
1
−
q
(
k
∣
x
)
)
(
1
−
log
p
(
k
∣
x
)
)
]
Loss = -[\sum_{k=1}^{K}{ q(k|x)\log{p(k|x) + (1-q(k|x))(1-\log{p(k|x))}}}]
Loss=−[k=1∑Kq(k∣x)logp(k∣x)+(1−q(k∣x))(1−logp(k∣x))]
与PyTorch版本相比这种损失多添加了一项
(
1
−
q
(
k
∣
x
)
)
(
1
−
log
p
(
k
∣
x
)
)
(1-q(k|x))(1-\log{p(k|x))}
(1−q(k∣x))(1−logp(k∣x))。
2.3 两种版本的区别在哪
PyTorch官方版本只关注正确分类的能力对于不是目标类的误分类概率不考虑吴恩达版本同时更倾向于使得每个类误分类的概率最小。
例如存在一个标签
[
1
0
0
]
\left[ \begin{matrix} 1 \\ 0 \\ 0 \end{matrix} \right]
100
给出两种预测的分布 [ 0.8 0.2 0 ] \left[ \begin{matrix} 0.8 \\ 0.2 \\ 0 \end{matrix} \right] 0.80.20 和 [ 0.8 0.1 0.1 ] \left[ \begin{matrix} 0.8 \\ 0.1 \\ 0.1 \end{matrix} \right] 0.80.10.1
对于PyTorch版本两种损失计算得到均为 − log 0.8 -\log{0.8} −log0.8
对于吴恩达版本第一种预测的损失为 − ( log 0.8 + log 0.8 + log 1 ) ≈ 0.1938 -(\log{0.8}+\log{0.8}+\log{1})\approx 0.1938 −(log0.8+log0.8+log1)≈0.1938第二种预测的损失为 − ( log 0.8 + log 0.9 + log 0.9 ) ≈ 0.1884 -(\log{0.8}+\log{0.9}+\log{0.9}) \approx 0.1884 −(log0.8+log0.9+log0.9)≈0.1884。
设预测正确类的概率为
p
p
p则在误分类概率均匀分布的时候损失的附加项为
−
log
(
1
−
1
−
p
K
−
1
)
K
−
1
-\log{(1-\frac{1-p}{K-1})^{K-1}}
−log(1−K−11−p)K−1(对数运算加变乘)误分类概率集中在一个类的时候损失的附加项为
−
log
(
1
−
(
1
−
p
)
)
=
−
log
p
-\log{(1-(1-p))}=-\log{p}
−log(1−(1−p))=−logp。其中K是总类别个数。
二者函数曲线图如下所示

数学推导
−
log
x
-\log{x}
−logx是关于x的递减函数只需比较x
(
1
−
1
−
p
K
−
1
)
K
−
1
(1-\frac{1-p}{K-1})^{K-1}
(1−K−11−p)K−1 VS
p
p
p
K
=
2
K=2
K=2两项均为
p
p
p事实上在二分类的情况下两种版本的损失函数相等。
( 1 − 1 − p K − 1 ) K − 1 = ( K − 2 + p K − 1 ) K − 1 (1-\frac{1-p}{K-1})^{K-1} = (\frac{K-2+p}{K-1})^{K-1} (1−K−11−p)K−1=(K−1K−2+p)K−1设 α = K − 1 > 1 \alpha =K-1>1 α=K−1>1 β = K − 2 > 0 \beta =K-2>0 β=K−2>0
( ( β + p ) α α α ) (\frac{(\beta+p)^{\alpha}}{\alpha^{\alpha}}) (αα(β+p)α) VS p p p
( β + p ) α (\beta+p)^{\alpha} (β+p)α VS α α p \alpha^{\alpha} p ααp
(
β
+
p
)
α
<
p
α
<
α
p
<
α
α
p
p
∈
(
0
,
1
)
(\beta+p)^{\alpha} < p^{\alpha} < \alpha p < \alpha^{\alpha} p \qquad p\in(0,1)
(β+p)α<pα<αp<ααpp∈(0,1)
由此可得
(
1
−
1
−
p
K
−
1
)
K
−
1
<
−
log
p
(1-\frac{1-p}{K-1})^{K-1}<-\log{p}
(1−K−11−p)K−1<−logp
2.4 正则化目标函数
J ( θ ) R E G = J ( θ ) + λ 2 m ∣ ∣ θ ∣ ∣ 2 2 J(\theta)_{REG}=J(\theta)+\frac{\lambda}{2m}||\theta||_{2}^{2} J(θ)REG=J(θ)+2mλ∣∣θ∣∣22
3. Python实现
3.1 梯度校验
进行梯度校验
f
′
(
θ
)
≈
J
(
θ
+
ϵ
)
−
J
(
θ
−
ϵ
)
2
×
ϵ
f^{\prime}(\theta) \approx \frac{J(\theta+\epsilon) - J(\theta-\epsilon)}{2\times\epsilon}
f′(θ)≈2×ϵJ(θ+ϵ)−J(θ−ϵ)
对于
θ
\theta
θ的每一项单独进行
ϵ
\epsilon
ϵ的加减根据公式求其导数随后和相对的梯队比较随后求相对误差
d
i
f
f
=
∥
g
r
a
d
−
g
r
a
d
a
p
p
r
o
x
∥
2
/
(
∥
g
a
r
d
∥
2
+
∥
g
r
a
d
a
p
p
r
o
x
∥
2
)
diff = \Vert grad - grad_{approx}\Vert_2 / (\Vert gard \Vert_2 + \Vert grad_{approx} \Vert_2)
diff=∥grad−gradapprox∥2/(∥gard∥2+∥gradapprox∥2)
e = 1e-4
regularized = False
theta = np.concatenate((theta1.flatten(),theta2.flatten()))
theta_matrix = np.array(np.matrix(np.ones(theta.shape[0])).T @ np.matrix(theta))
epsilon_matrix = np.identity(len(theta)) * e
plus_matrix = theta_matrix + epsilon_matrix
minus_matrix = theta_matrix - epsilon_matrix
from BackwardPropagation import BackPropModel, gradient, loss
model_g = BackPropModel()
g1 = []
for i in range(len(theta)):
theta_p1 = plus_matrix[i][:401*25].reshape(401,25)
theta_p2 = plus_matrix[i][401*25:].reshape(26,10)
model_g.load_parameters([theta_p1,theta_p2])
output_g = model_g(x)
plus_g = loss(output_g, y_onehot) / output_g.shape[0]
theta_m1 = minus_matrix[i][:401*25].reshape(401,25)
theta_m2 = minus_matrix[i][401*25:].reshape(26,10)
model_g.load_parameters([theta_m1,theta_m2])
output_g = model_g(x)
minus_g = loss(output_g, y_onehot) / output_g.shape[0]
g1.append((plus_g - minus_g) / (2 * e))
g1 = np.array(g1)
model = BackPropModel()
model.load_parameters([theta1, theta2])
out = model(x)
g = gradient(model, out, y_onehot)
g2 = np.concatenate((g[0].flatten(), g[1].flatten()))
diff = np.linalg.norm(g1 - g2) / (np.linalg.norm(g1) + np.linalg.norm(g2))
print("Gradient Check Result (Regularized: {}):\n"
"The relative difference is {:e}, assuming epsilon is {}".format(regularized, diff, e))
最后得到结果为
Gradient Check Result (Regularized: False):
The relative difference is 2.145756e-09, assuming epsilon is 0.0001
相对误差在 1 0 − 9 10^{-9} 10−9数量级上可以认为梯度有正确的。
3.2 封装类
import numpy as np
from LogisticRegression.LogisticRegression import sigmoid
def g_sigmoid(x):
"""
Derivative of sigmoid function
g'(x) = g(x)(1 - g(x)),
where g() is the sigmoid function
:param x: input with any shape
:return: Derivative value of sigmoid
"""
return np.multiply(sigmoid(x), (1 - sigmoid(x)))
def loss(pred, target):
"""
Loss function
Loss = -target * log(pred) - (1 - target) * log(1-pred),
where target in a one-hot vector
:param pred: predicted distribution with shape of (n, 10)
:param target: target distribution with shape of (n, 10)
:return: loss
"""
return np.sum(-np.multiply(target, np.log(pred)) - np.multiply((1 - target), np.log(1 - pred)))
def gradient(model, output, target):
"""
Get gradient of model
:param model: NN model
:param output: shape of (n, 10)
:param target: shape of (n, 10)
:return: gradient with shape of parameters' shape
"""
# theta1 (401, 25); theta2 (26, 10)
n = output.shape[0]
# d3 (n, 10)
d3 = output - target
# t (n, 1)
t = np.ones(shape=(n, 1))
# z2 (n, 25); z2_ (n, 26)
z2_ = np.concatenate((t, model.z2), axis=1)
# g_prime_z2 (n, 26)
g_prime_z2 = g_sigmoid(z2_)
# d3 @ model.theta2.T (n, 26)
# skip d2_0, d2 (n, 25)
d2 = np.multiply(d3 @ model.theta2.T, g_prime_z2)[:, 1:]
# (n, 26).T @ (n, 10) = (26, 10)
delta2 = model.a2.T @ d3
# (n, 401).T @ (n, 25) = (401, 25)
delta1 = model.a1.T @ d2
return delta1 / n, delta2 / n
def regularized_gradient(model, output, target, scale):
"""
Get regularized("L2") gradient of model
Don't regularize the bias term of parameters
:param model: NN model
:param output: Output of model with shape of (n, 10)
:param target: target distribution with shape of (n, 10)
:param scale: scale for regularization
:return: regularized gradient with shape of parameters' shape
"""
# delta1 (401, 25); delta2 (26, 10)
delta1, delta2 = gradient(model=model, output=output, target=target)
n = output.shape[0]
theta1 = model.theta1
theta1[0, :] = 0
reg_term_d1 = (scale / n) * theta1
delta1 = delta1 + reg_term_d1
theta2 = model.theta2
theta2[0, :] = 0
reg_term_d2 = (scale / n) * theta2
delta2 = delta2 + reg_term_d2
return delta1, delta2
def regularized_loss(pred, target, theta, scale):
"""
Regularized loss function
Regularized_loss = Loss + lambda / (2 * m) * (square_sum(theta1) + square_sum(theta2)),
where theta1 and theta2 exclude the bias term
:param pred: predicted distribution with shape of (n, 1)
:param target: target distribution with shape of (n, 1)
:param theta: parameters list of model with shape of (2, parameter_shape)
:param scale: scale for regularize term
:return: regularized loss
"""
m = pred.shape[0]
# theta1 (401, 25)
theta1 = theta[0]
# theta2 (26, 10)
theta2 = theta[1]
reg_1 = scale / (2 * m) * (theta1[1:, :] ** 2).sum()
reg_2 = scale / (2 * m) * (theta2[1:, :] ** 2).sum()
row_loss = loss(pred=pred, target=target) / m
return row_loss + reg_1 + reg_2
class BackPropModel:
"""
BackPropagation Model
parameter shape: (401, 25) and (26, 10)
"""
def __init__(self, penalty="L2", scale=0):
"""
Initialize Function
:param penalty: Regularization
:param scale: Lambda for regularization
"""
self.theta1 = None
self.theta2 = None
self.penalty = penalty
self.scale = scale
self.a1 = None
self.z2 = None
self.a2 = None
self.z3 = None
def load_parameters(self, parameters):
"""
Load parameters
:param parameters: shape of [2, parameters_shape]
:return:
"""
self.theta1 = parameters[0]
self.theta2 = parameters[1]
def init_parameters(self, l_in, l_out):
"""
Initialize parameters with uniform distribution in [-epsilon, epsilon]
epsilon = np.sqrt(6 / (l_in+l_out))
:param l_in: Number of unit of input layer
:param l_out: Number of unit of output layer
:return:
"""
epsilon = np.sqrt(6 / (l_in + l_out))
parameters = np.random.uniform(low=-epsilon, high=epsilon, size=401 * 25 + 26 * 10)
self.theta1 = parameters[:401 * 25].reshape(401, 25)
self.theta2 = parameters[401 * 25:].reshape(26, 10)
def optimize(self, g, lr=0.01):
"""
Optimize parameters via Batch Gradient Descent
theta = theta - alpha * gradient
:param lr: learning rate with default 0.01
:param g: gradient list for parameters with shape of [2, parameters_shape]
:return:
"""
# gradient[0] (401, 25); gradient[1] (26, 10)
self.theta1 = self.theta1 - lr * g[0]
self.theta2 = self.theta2 - lr * g[1]
def __call__(self, x, *args, **kwargs):
"""
Forward Propagation
:param x: Input of model with shape of (n, 400)
:return: Calculation result for each layer
"""
# x (n, 400)
t = np.ones(shape=(x.shape[0], 1))
# x (n, 401)
self.a1 = np.concatenate((t, x), axis=1)
# z2 (n, 25); a2 (n, 25)
self.z2 = np.matmul(self.a1, self.theta1)
a2 = sigmoid(self.z2)
# a2 (n, 26
self.a2 = np.concatenate((t, a2), axis=1)
# z3 (n, 10
self.z3 = np.matmul(self.a2, self.theta2)
# a3 (n, 10)
a3 = sigmoid(self.z3)
return a3
3.3 实验结果
同样使用10000张手写数字图像进行分类任务。
from BackwardPropagation import BackPropModel, regularized_loss, regularized_gradient
model = BackPropModel()
model.init_parameters(400, 10)
train_loss = []
val_loss = []
epochs = 1500
lr = 2
scale = 1
for epoch in range(epochs):
output = model(train_x)
g_1, g_2 = regularized_gradient(model, output, train_y, scale=scale)
model.optimize([g_1, g_2],lr=lr)
loss = regularized_loss(output, train_y, [model.theta1, model.theta2], scale=scale)
train_loss.append(loss)
_loss = regularized_loss(model(val_x), val_y, [model.theta1,model.theta2], scale=scale)
val_loss.append(_loss)
print("Epoch: {}\tTrain Loss: {:.4f}\tVal Loss: {:.4f}".format(epoch, loss, _loss))
查看训练过程
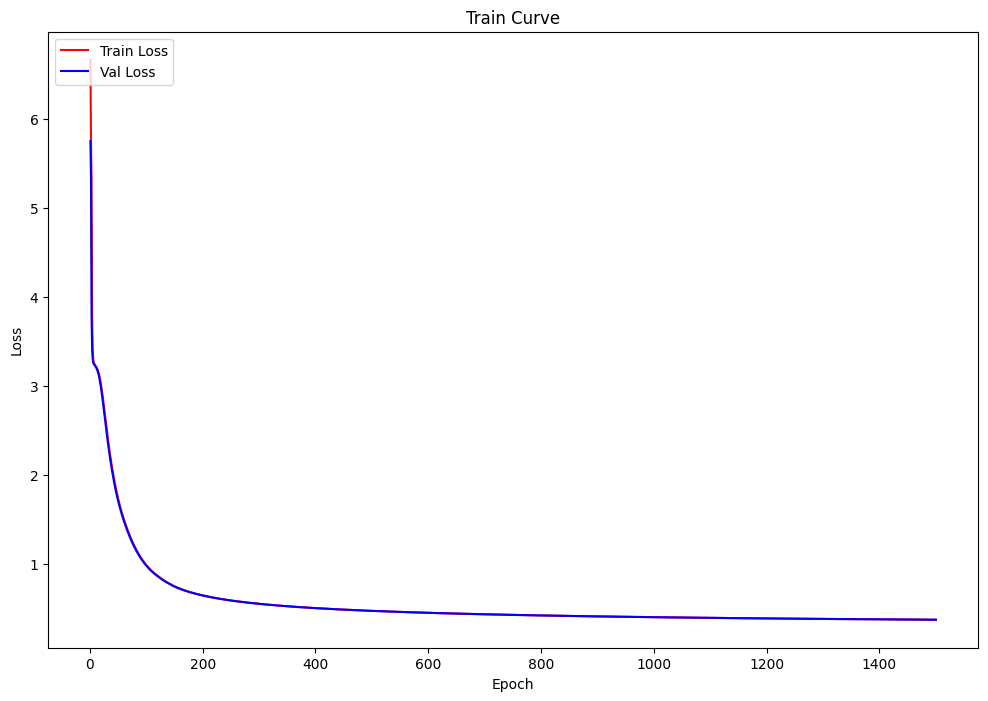
查看训练结果
pred_prob = model(val_x)
pred = np.argmax(pred_prob,axis=1) + 1
from sklearn.metrics import classification_report
target =np.argmax(val_y, axis=1) + 1
report = classification_report(pred, target, digits=4)
print(report)
precision recall f1-score support
1 0.9860 0.9782 0.9821 504
2 0.9800 0.9761 0.9780 502
3 0.9600 0.9776 0.9687 491
4 0.9740 0.9819 0.9779 496
5 0.9800 0.9800 0.9800 500
6 0.9860 0.9860 0.9860 500
7 0.9740 0.9760 0.9750 499
8 0.9840 0.9743 0.9791 505
9 0.9680 0.9661 0.9670 501
10 0.9900 0.9861 0.9880 502
accuracy 0.9782 5000
macro avg 0.9782 0.9782 0.9782 5000
weighted avg 0.9783 0.9782 0.9782 5000
3.3 隐藏层可视化
def plot_hidden_layer(theta):
"""
:param theta: with shape of (401, 25)
"""
hidden_layer = theta[1:, :]
fig, ax_array = plt.subplots(nrows=5, ncols=5, sharey=True, sharex=True, figsize=(5, 5))
for r in range(5):
for c in range(5):
ax_array[r, c].matshow(hidden_layer[:,5 * r + c].reshape((20, 20)), cmap=matplotlib.cm.gray)
plt.xticks(np.array([]))
plt.yticks(np.array([]))
plot_hidden_layer(model.theta1)

这实际上就是神经网络对图像提取出来的的“特征”。