

程序的编译与链接——ARM可执行文件ELF
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
读书《嵌入式C语言自我修养》笔记
目录
使用readelf命令查看ELF section header
ARM编译工具
linux安装gcc-arm-linux-gnueabi交叉编译器
apt-get install gcc-arm-linux-gnueabi-gcc //Ubuntu
yum install gcc-arm-linux-gnueabi gcc //Fedora使用ARM交叉编译器将C源程序编译生成ARM格式的二进制可执行文件a.out
arm-linux-gnueabi-gcc -o a.out main.c sub.c使用readelf命令查看ELF Header
readelf -h a.out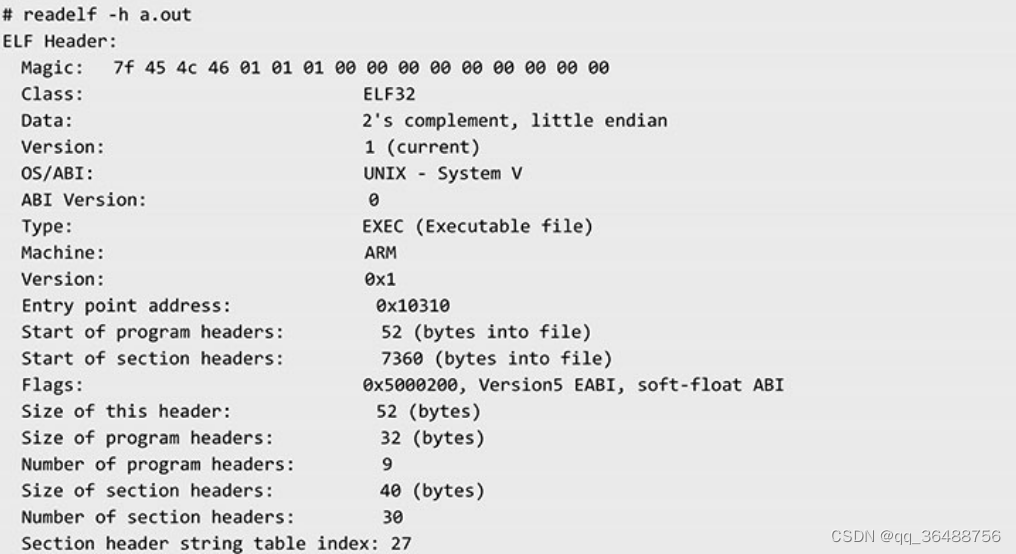
使用readelf命令查看ELF section header
readelf -S a.out
一个可执行文件通常由不同的段section构成代码段(.text)、数据段(.data)、BSS段、只读数据段等。每个section用一个section header来描述包括段名、段的类型、段的起始地址、段的偏移和段的大小等。一个可执行文件中的每一个section都有一个section header将这些section headers集中放到一起就是section header table
函数翻译成二进制指令放在代码段中
初始化的全局变量和静态局部变量放在数据段中。
BSS段比较特殊一般来讲未初始化的全局变量和静态变量会放置在BSS段中但是因为它们未初始化默认值全部是0其实没有必要再单独开辟空间存储为了节省存储空间所以在可执行文件中BSS段是不占用空间的。但是BSS段的大小、起始地址和各个变量的地址信息会分别保存在节头表section header table和符号表.symtab里当程序运行时加载器会根据这些信息在内存中紧挨着数据段的后面为BSS段开辟一片存储空间为各个变量分配存储单元。
程序编译
gcc在程序编译过程中会分别调用它们常见的工具有预处理器、编译器、汇编器、链接器。
● 预处理器将源文件main.c经过预处理变为main.i。
● 编译器将预处理后的main.i编译为汇编文件main.s。
● 汇编器将汇编文件main.s编译为目标文件main.o。
● 链接器将各个目标文件main.o、sub.o链接成可执行文件a.out。最后生成的可执行文件a.out其实也是目标文件object file
目标文件一般可以分为3种。
● 可重定位的目标文件relocatable files。
● 可执行的目标文件executable files。
● 可被共享的目标文件shared object files。
预处理器
预处理就是在编译源程序之前先处理源文件中的各种预处理命令。编译器是不认识预处理指令的。编译器一般为开发人员提供一些预处理命令使用#标识。我们常见的预处理命令如下。
● 头文件包含#include。 实现模块化编程
● 定义一个宏#define。 提高程序的可读性
● 条件编译#if、#else、#endif。 让代码兼容不同的处理器架构和平台以最大限度地复用公用代码
● 编译控制#pragma。 让代码兼容不同的处理器架构和平台以最大限度地复用公用代码
#pragma pack([n])指示结构体和联合成员的对齐方式。
#pragma message("string")在编译信息输出窗口打印自己的文本信息。
#pragma warning有选择地改变编译器的警告信息行为。
#pragma once在头文件中添加这条指令可以防止头文件多次编译。
预处理操作。
● 头文件展开将#include包含的头文件内容展开到当前位置。
● 宏展开展开所有的宏定义并删除#define。
● 条件编译根据宏定义条件选择要参与编译的分支代码其余的分支丢弃。
● 删除注释。
● 添加行号和文件名标识编译过程中根据需要可以显示这些信息。
● 保留#pragma命令该命令会在程序编译时指示编译器执行一些特定行为。
 预处理后
预处理后 
编译器
编译过程可以分为以下6步。
1词法分析。
词法分析是编译过程的第一步主要用来解析C程序语句。
词法分析一般会通过词法扫描器从左到右一个字符一个字符地读入源程序通过有限状态机解析并识别这些字符流将源程序分解为一系列不能再分解的记号单元——token。
token是字符流解析过程中有意义的最小记号单元常见的token如下。
● C语言的各种关键字int、float、for、while、break等。
● 用户定义的各种标识符函数名、变量名、标号等。
● 字面量数字、字符串等。
● 运算符C语言标准定义的40多个运算符。
● 分隔符程序结束符分号、for循环中的逗号等。
sum = a + b / c ; 👉 分解成了8个token“sum” “=” “a” “+” “b” “/” “c” “”
2语法分析。
对前一阶段产生的token序列进行解析看是否能构建成一个语法上正确的语法短语程序、语句、表达式等。语法短语用语法树表示是一种树型结构不再是线性序列。
语法分析工具在对token序列分析过程中如果发现不能构建语法上正确的语句或表达式就会报语法错误syntax error。

3语义分析。
语义分析主要对语法分析输出的各种表达式、语句进行检查看看有没有错误。如果你传递给函数的实参与函数声明的形参类型不匹配或者你使用了一个未声明的变量或者除数为零了break在循环语句或switch语句之外出现了或者在循环语句之外发现了continue语句一般都会报语义上的错误或警告。
4中间代码生成。
中间代码是编译过程中的一种临时代码常见的有三地址码、P-代码等
中间代码是一维线性序列结构类似伪代码编译器很容易将中间代码翻译成目标代码。
中间码一般和平台是无关的
生成三地址码
arm-linux-gnueabi-gcc -fdump-tree-gimple main.c 汇编器
5汇编代码生成。
汇编器的主要工作就是参考ISA指令集将汇编代码翻译成对应的二进制指令分析汇编语言中各个section的信息收集各种符号生成符号表将各个符号在section内的偏移地址也填充到符号表内以section的形式组装到可重定位目标文件(.o)中后面的链接过程会用到这些信息。
查看符号表信息
readelf -s sub.o符号表主要用来保存源程序中各种符号的信息包括符号的地址、类型、占用空间的大小等。这些信息一方面可以辅助编译器作语义检查看源程序是否有语义错误另一方面也可以辅助编译器编译代码的生成包括地址与空间的分配、符号决议、重定位等。符号表本质上是一个结构体数组在ARM平台下定义在Linux内核源码的/arch/arm/include/asm/elf.h文件中。
typedef struct elf32_sym{
Elf32_Word st_name; //符号名
Elf32_Addr st_value; //符号对应的值
Elf32_Word st_size; //符号大小
unsigned char st_info; //符号类型
unsigned char st_other;
Elf32_Half st_shndx; //符号所在段
} Elf32_Sym;符号的类型主要有以下几种。
● OBJECT对象类型一般用来表示我们在程序中定义的变量。
● FUNC关联的是函数名或其他可引用的可执行代码。
● FILE该符号关联的是当前目标文件的名称。
● SECTION表明该符号关联的是一个section主要用来重定位。
● COMMON表明该符号是一个公用块数据对象是一个全局弱符号在当前文件中未分配空间。
● TLS表明该符号对应的变量存储在线程局部存储中。
● NOTYPE未指定类型或者目前还不知道该符号类型
如果在当前文件中没有找到符号的定义也会将这些符号搜集在一起并保存到一个单独的符号表中以待后续填充这个符号表就是重定位符号表。如在main.o的符号表中会看到add和sub这两个符号的信息处于未定义状态NOTYPE需要后续填充。同时在main.o中会使用一个重定位表.rel.text来记录这些需要重定位的符号
查看重定位表
readelf -r main.o链接器
6目标代码生成。
分段组装
链接器将编译器生成的各个可重定位目标文件重新分解组装将各个目标文件的代码段放在一起作为最终生成的可执行文件的代码段将各个目标文件的数据段放在一起作为可执行文件的数据段。其他section也会按照同样的方法进行组装

段的组装顺序
何指定程序的链接地址和各个段的组装顺序呢很简单通过链接脚本就可以了。链接脚本本质上是一个脚本文件。在这个脚本文件里不仅规定了各个段的组装顺序、起始地址、位置对齐等信息同时对输出的可执行文件格式、运行平台、入口地址等信息做了详细的描述。链接器就是根据链接脚本定义的规则来组装可执行文件的并最终将这些信息以section的形式保存到可执行文件的ELF Header中。
可以使用下面的命令来查看链接器使用的默认链接脚本
arm-linux-gnueabi-ld --verbose在嵌入式裸机环境下编译程序尤其是编译ARM底层代码很多时候我们要根据开发版的不同硬件配置、内存大小和地址灵活指定链接地址或者显示指定链接脚本有时候甚至自己编写链接脚本。U-boot源码编译的链接脚本U-boot.lds一般放在U-boot源码的顶层目录下。Linux内核编译的链接脚本vmlinux.lds一般放在arch/arm/boot/compressed/目录下面。而对于ARM裸机程序开发大多数IDE都会提供一些设置接口。
符号决议
各个文件中定义了相同的全局变量名或函数名发生了符号冲突那么最终的可执行文件中到底该使用哪一个呢编译器为了解决这种符号冲突引入了强符号和弱符号的概念函数名、初始化的全局变量是强符号而未初始化的全局变量则是弱符号。在一个多文件的工程中强符号不允许多次定义否则就会发生重定义错误。强符号和弱符号可以在一个项目中共存当强弱符号共存时强符号会覆盖掉弱符号链接器会选择强符号作为可执行文件中的最终符号。链接器也允许一个项目中出现多个弱符号共存。在程序编译期间编译器在分析每个文件中未初始化的全局变量时并不知道该符号在链接阶段是被采用还是被丢弃因此在程序编译期间未初始化的全局变量并没有被直接放置在BSS段中而是将这些弱符号放到一个叫作COMMON的临时块中在符号表中使用一个未定义的COMMON来标记在目标文件中也没有给它们分配存储空间。在链接期间链接器会比较多个文件中的弱符号选择占用空间最大的那一个作为可执行文件中的最终符号此时弱符号的大小已经确定并被直接放到了可执行文件的BSS段中。
sub .c
int i=20;
int a;main.c
int i;
char a;
int main(void)
{
printf("i = %d\n",i);
return 0;
}编译并执行
#arm-linux-gnueabi-gcc main.c sub.c -o a.out
#./a.out
i=20
#arm-linux-gnueabi-gcc -c main.c sub.c -o a.out
#readelf -s main.o | grep i
8:00000001 1 OBJECT GLOBAL DEFAULT COM i
#readelf -s sub.o | grep i
7:00000004 4 OBJECT GLOBAL DEFAULT COM i
#readelf -s main.o | grep i
63:00804a04 4 OBJECT GLOBAL DEFAULT 26 i通过readelf命令分别查看目标文件main.o和sub.o中的符号i你会发现它们都被放置在了COMMON块中大小分别标记为1和4而最终生成的可执行文件a.out中变量i则被放置在.bss段中大小标记为4字节。
GNU C编译器在ANSI C语法标准的基础上扩展了一系列C语言语法如提供了一个__attribute__关键字用来声明符号的属性。通过下面的命令可以将一个强符号转化为弱符号。
__attribute__((weak)) int n = 100;重定位
解决了多文件符号冲突的问题可执行文件的符号表中的每个符号虽然都确定下来了但是符号表中的每个符号值也就是每个函数、全局变量的地址还是原来各个目标文件中的值还都是基于零地址的偏移。链接器将各个目标文件重新分解组装后各个段的起始地址都发生了变化。
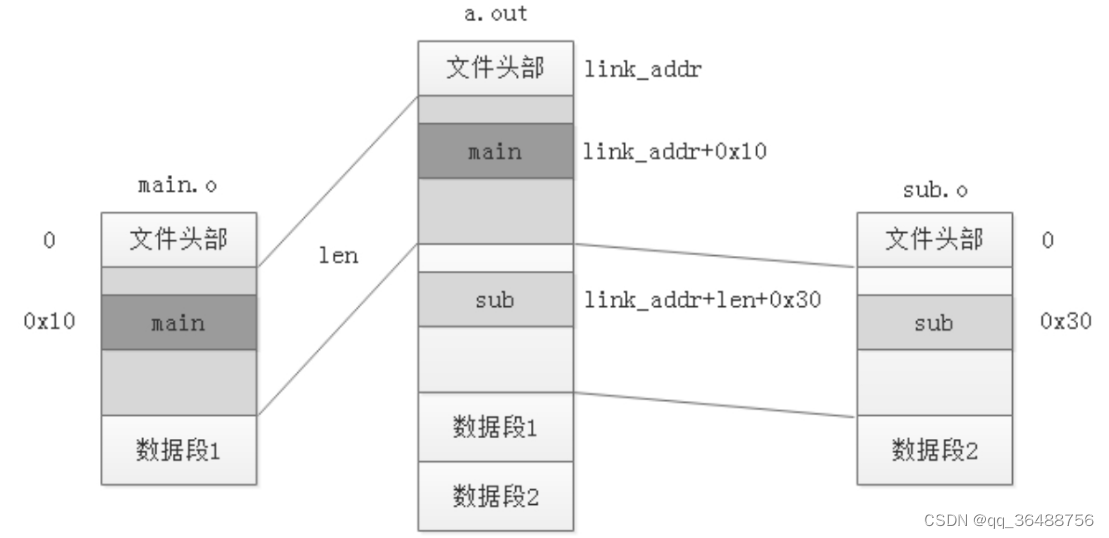
链接器怎么知道哪些符号需要重定位呢在各个目标文件中还有一个重定位表专门记录各个文件中需要重定位的符号。重定位的核心工作就是修正指令中的符号地址
无论是代码段还是数据段只要这个段中有需要重定位的符号编译器都会生成一个重定位表与其对应.rel.text或.rel.data。这些重定位表记录各个段中需要重定位的各种符号并以section的形式保存在各个目标文件中。我们可以通过readelf或objdump命令来查看一个目标文件中的重定位表信息
查看重定位表
#arm-linux-gnueabi-readelf -r main.o重新定位新地址 = 新的段基址 + 段内偏移
不同的编译器有不同的链接起始地址。在Linux环境下GCC链接时一般以0x08040000为起始地址开始存放代码段而ARM GCC交叉编译器一般以0x10000为链接起始地址。那每个进程的指令代码在编译时都是采用同一个链接地址的在运行时它们会被加载到内存中的同一个地址吗会不会产生地址冲突并不会因为程序链接时的链接地址其实都是虚拟地址。
程序运行时虽然每个进程的地址空间都是一样的但是每个进程都有自己的页表页表里的每一个条目叫页表项页表项里存储的是虚拟地址和物理地址之间的映射关系相同的虚拟地址经过MMU硬件转换后会分别映射到物理内存的不同区域彼此相互隔离和独立不会起冲突。

当Linux环境下有多个进程并发运行时C源程序、可执行文件、进程和物理内存之间的对应关系
