

大数据学习(12)-join优化common join
阿里云国际版折扣https://www.yundadi.com |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
&&大数据学习&&
系列专栏 哲学语录: 承认自己的无知乃是开启智慧的大门
如果觉得博主的文章还不错的话请点赞+收藏⭐️+留言支持一下博>主哦
Join算法概述
Hive拥有多种join算法包括Common JoinMap JoinBucket Map JoinSort Merge Buckt Map Join等下面对每种join算法做简要说明
1Common Join
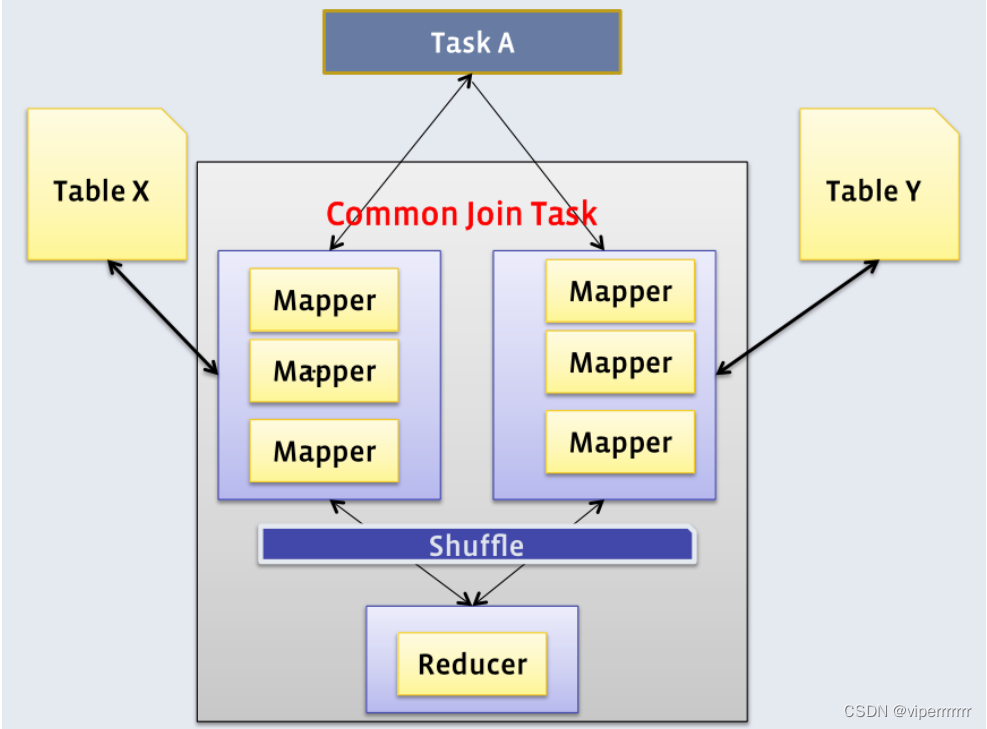
Common Join是Hive中最稳定的join算法其通过一个MapReduce Job完成一个join操作。Map端负责读取join操作所需表的数据并按照关联字段进行分区通过Shuffle将其发送到Reduce端相同key的数据在Reduce端完成最终的Join操作。如下图所示
需要注意的是sql语句中的join操作和执行计划中的Common Join任务并非一对一的关系一个sql语句中的相邻的且关联字段相同的多个join操作可以合并为一个Common Join任务。
例如
hive (default)>
select
a.val,
b.val,
c.val
from a
join b on (a.key = b.key1)
join c on (c.key = b.key1)上述sql语句中两个join操作的关联字段均为b表的key1字段则该语句中的两个join操作可由一个Common Join任务实现也就是可通过一个Map Reduce任务实现。
hive (default)>
select
a.val,
b.val,
c.val
from a
join b on (a.key = b.key1)
join c on (c.key = b.key2)上述sql语句中的两个join操作关联字段各不相同则该语句的两个join操作需要各自通过一个Common Join任务实现也就是通过两个Map Reduce任务实现。