

Yolov5训练自己的数据集(详细完整版)_yolov5训练自己的数据集
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
最近在网上看到有与本博客一模一样的连图片都一样。
特此声明这是原版转载请附原文链接谢谢。
这次我将大部分图片添加了水印
文章目录
推荐下本人另一篇博客
一. 环境不能含有中文路径
本教程使用环境
-
pytorch: 1.10.0
-
python: 3.9
-
yolov5 v6.0
ps: 如果要使用GPUcuda版本要 >=10.1
下载安装yolov5
yolov5 v6.0官方要求 Python>=3.6 and PyTorch>=1.7
yolov5源码下载https://github.com/ultralytics/yolov5
下载后进入pytorch环境进入yolov5文件夹使用换源的方法安装依赖。
如果你前面安装时没有换源我强烈建议你使用换源的方法在安装一次
安装过的模块不会在安装以防缺少模块影响后续程序运行以及模型训练。
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
因为本教程主详细讲解训练自己的数据集避免篇幅过多因此这里不详细说明了。
二. 准备工作文件夹及视频转图片
因为这篇文章主要是给小白提供所以数据集文件夹以及代码文件命名不是很标准标准的自行去搜索查看coco数据集就行了。
为了排除一些意外情况路径中就不要有短横杠-以及空格等等特殊字符。中文更不能要有。
- 在 yolov5目录下 新建文件夹 VOCData可以自定义命名
| Model | size (pixels) | mAPval 0.5:0.95 | mAPval 0.5 | Speed CPU b1 (ms) | Speed V100 b1 (ms) | Speed V100 b32 (ms) | params (M) | FLOPs @640 (B) |
|---|---|---|---|---|---|---|---|---|
| YOLOv5n | 640 | 28.4 | 46.0 | 45 | 6.3 | 0.6 | 1.9 | 4.5 |
| YOLOv5s | 640 | 37.2 | 56.0 | 98 | 6.4 | 0.9 | 7.2 | 16.5 |
| YOLOv5m | 640 | 45.2 | 63.9 | 224 | 8.2 | 1.7 | 21.2 | 49.0 |
| YOLOv5l | 640 | 48.8 | 67.2 | 430 | 10.1 | 2.7 | 46.5 | 109.1 |
| YOLOv5x | 640 | 50.7 | 68.9 | 766 | 12.1 | 4.8 | 86.7 | 205.7 |
这里选用 yolov5s.yaml
使用记事本打开 yolov5s.yaml。
修改参数。
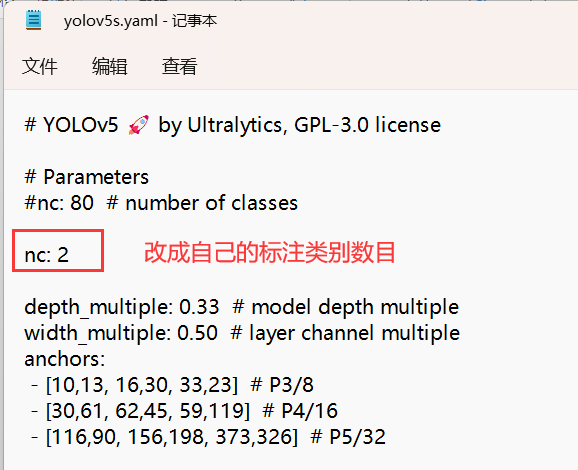
- 采用自动法获取anchors只需更改nc 标注类别数不用更改anchors
按理应该是不需修改anchors的我在前面自动法那里提过如果后续训练时自动计算出了anchors后暂停了训练那么应该是需要我们根据生成的anchors来修改。
- 手动法获取anchors需要更改两个参数
把 nc 改成自己的标注类别数
修改anchors根据 anchors.txt 中的 Best Anchors 修改需要取整四舍五入、向上、向下都可以。
保持yaml中的anchors格式不变按顺序一对一即可。

五. 模型训练
1. 开始训练
打开yolov5 目录下的 train.py 程序我们可以多看看这些参数使用。
常用参数解释如下
这个大部分借鉴了参考链接。
weights权重文件路径
cfg存储模型结构的配置文件
data存储训练、测试数据的文件
epochs指的就是训练过程中整个数据集将被迭代训练了多少次显卡不行你就调小点。
batch-size训练完多少张图片才进行权重更新显卡不行就调小点。
img-size输入图片宽高显卡不行就调小点。
devicecuda device, i.e. 0 or 0,1,2,3 or cpu。选择使用GPU还是CPU
workers线程数。默认是8。
其它参数解释
noautoanchor不自动检验更新anchors
rect进行矩形训练resume恢复最近保存的模型开始训练
nosave仅保存最终checkpoint
notest仅测试最后的epoch
evolve进化超参数
bucketgsutil bucket
cache-images缓存图像以加快训练速度
name 重命名results.txt to results_name.txt
adam使用adam优化
multi-scale多尺度训练img-size +/- 50%
single-cls单类别的训练集
进入pytorch环境进入yolov5文件夹
训练命令如下
如果出现问题查看后面问题说明
python train.py --weights weights/yolov5s.pt --cfg models/yolov5s.yaml --data data/myvoc.yaml --epoch 200 --batch-size 8 --img 640 --device cpu
–weights weights/yolov5s.pt 这个也许你需要更改路径。我是将yolov5的pt文件都放在weights目录下你可能没有需要更改路径。
–epoch 200 训练200次
–batch-size 8训练8张图片后进行权重更新
–device cpu使用CPU训练。
如果采用手动法获取anchors可以选择补充添加参数 --noautoanchor也可以不添加解释如下
参数解释在上面。如果是自动法这个参数不要加
如果是手动获取并更改了anchors的而且没有添加参数 --noautoanchor训练时会计算BPR并且得到的BPR应该是为1的或者极为接近1所以不会更新anchors。因此手动法的话这个参数添不添加无所谓的。
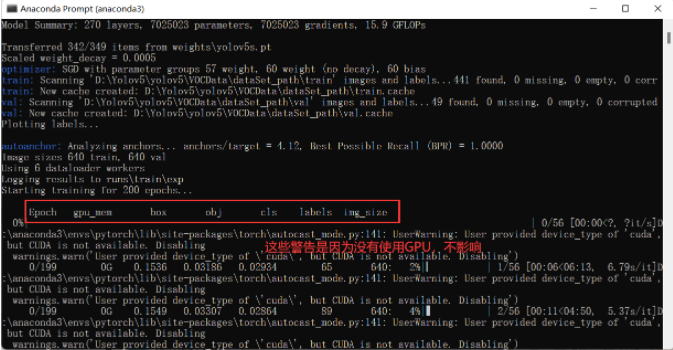
2. 训练过程
如果你不想看到这些警告网上是有办法消除的自行寻找了。
如果你使用GPU训练也有类似下面这个那是你 cuda 版本不对不是>=10.1的版本版本不对无法使用cuda。
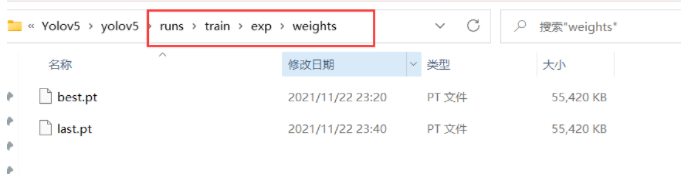
训练好的模型会被保存在 yolov5 目录下的 runs/train/weights/ 下
3. 训练时间
- 我这里四百多张图片使用CPU训练了一百二十几次虽然设的200次但我中途终止了大概花了5、6个小时吧时间比较久了忘了。
- 我同学 70张图片训练70次使用CPU训练花了 一个多小时。
上述时间只限于电脑风扇转动的情况下如果你电脑限制性能风扇不转动那时间将会是个未知一般是好几倍
4. 相关问题
如果出现缺少模块的情况no module named
回到博客最开始部分使用换源的方法补充安装yolov5的依赖。
如果出现 页面太小无法完成操作的相关问题
那是虚拟内存不足重新打开页面或者重启电脑试试这个方法解决的可能性比较低降低线程 --workes (默认是8) 。最后再试试调小 --batch-size降低 --epoch
我有几个同学 --workers指定为0才成功。
如果都不行可以看看这个链接 https://product.pconline.com.cn/itbk/software/dnyw/1707/9679137.html
如果训练过程中出现 memory error
那是内存超了减小 --batch-size 试试如果还不行降低 --epoch。
我同学将 --epoch 设为100次–batch-size设为3才成功。
–epoch建议尽量在100次往上吧
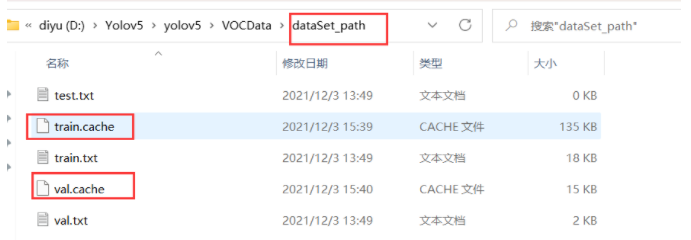
重复训练的话你也许需要将这两个缓存清除掉。
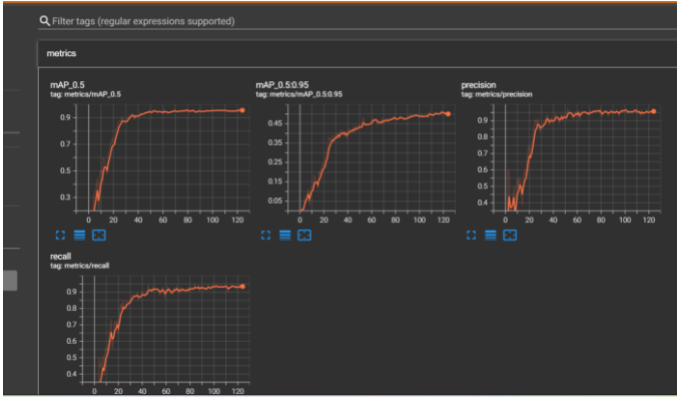
5. 训练可视化
训练时或者训练后可以利用 tensorboard 查看训练可视化
tensorboard --logdir=runs
与训练一样进入pytorch环境进入yolov5文件夹执行。

六. 检测效果
python detect.py --source 0 # webcam 自带摄像头
file.jpg # image 图片
file.mp4 # video 视频
path/ # directory
path/*.jpg # glob
'https://youtu.be/NUsoVlDFqZg' # YouTube
'rtsp://example.com/media.mp4' # RTSP, RTMP, HTTP stream
我们使用刚刚训练出的最好的模型 best.pt 来测试在yolov5目录下的 runs/train/exp/weights 。
python detect.py --weights runs/train/exp/weights/best.pt --source ../data/video/tram.mp4
../ 代表当前目录的上一级目录
测试结果保存在 yolov5/runs/detect 目录下

七. 模型评估与推理
这个就请查看第一个参考链接了我就不说明了注意下版本问题哈
八. 参考链接感谢
有帮助的话不求一键三连点个赞还是可以的吧笔芯
这些问题都是在我朋友身上遇到的各种纷杂问题都有这里只保留了部分问题。