

I.MX6ULL ARM驱动开发---网络设备驱动框架
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
引言
网络驱动是 linux 里面驱动三巨头之一linux 下的网络功能非常强大嵌入式 linux 中也常常用到网络功能。前面我们已经讲过了字符设备驱动和块设备驱动本章我们就来学习一下 linux 里面的网络设备驱动。
一、Linux网络设备驱动的结构
网络设备驱动程序的体系结构分为4层依次为网络协议驱动层、网络设备接口层、设备驱动功能层、网络设备与媒介层。
1网络协议接口层向网络层协议提供统一的数据包收发接口不论上层协议是ARP还是IP都通过dev_queue_xmit函数发送数据、并通过netif_rx函数接收数据。这一层的存在使得上层协议独立于具体的设备。
2网络设备接口层向协议接口层提供统一的用于描述具体网络设备属性和操作的结构体net_device,该结构体是设备驱动功能层中的各函数的容器。实际上网络设备接口层从宏观上规划了具体操作硬件的设备驱动功能层的结构。
3设备驱动功能层的各函数是网络设备接口层net_device数据结构的具体成员是驱使网络设备硬件完成相应动作的程序它通过hard_start_xmit函数启动发送操作并通过网络设备上的中断触发接收操作。
4网络设备与媒介层是完成数据包发送和接收的物理实体包括网络适配器和具体的传输媒介网络适配器被设备驱动功能层中的函数在物理上驱动对于linux系统而言网络设备和媒介都可以是虚拟的。
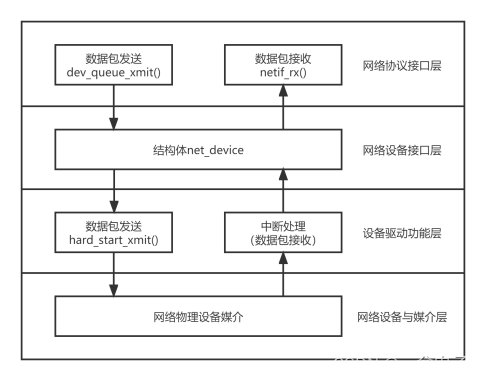
在设计具体的网络驱动程序时我们需要完成的主要工作是编写设备驱动功能层的相关函数以填充net_device数据结构的内容并将net_device注册入内核。
二、网络协议接口层
网络协议接口层最主要的功能是给上层协议提供透明的数据包发送和接收接口。当上层ARP或IP需要发送数据包时它将调用网络接口层的dev_queue_xmit函数发送改数据包。同样地上层对数据包的接收也通过向netif_rx函数传递struct sk_buff数据结构的指针来完成。
1、dev_queue_xmit 函数
此函数用于将网络数据发送出去函数定义在 include/linux/netdevice.h 中函数原型如下
static inline int dev_queue_xmit(struct sk_buff *skb)
函数参数和返回值含义如下
skb要发送的数据这是一个 sk_buff 结构体指针sk_buff 是 Linux 网络驱动中一个非常重要的结构体网络数据就是以 sk_buff 保存的各个协议层在 sk_buff 中添加自己的协议头最终由底层驱动讲 sk_buff 中的数据发送出去。网络数据的接收过程恰好相反网络底层驱动将接收到的原始数据打包成 sk_buff然后发送给上层协议上层会取掉相应的头部然后将最终的数据发送给用户。
返回值0 发送成功负值发送失败。
2、netif_rx 函数
上层接收数据的话使用 netif_rx 函数但是最原始的网络数据一般是通过轮询、中断或 NAPI的方式来接收。netif_rx 函数定义在 net/core/dev.c 中函数原型如下
int netif_rx(struct sk_buff *skb)
函数参数和返回值含义如下
skb保存接收数据的 sk_buff。
返回值NET_RX_SUCCESS 成功NET_RX_DROP 数据包丢弃。
struct sk_buff {
...
unsigned char *head;
unsigned char *data;
unsigned char *tail;
unsigned char *end;
...
}
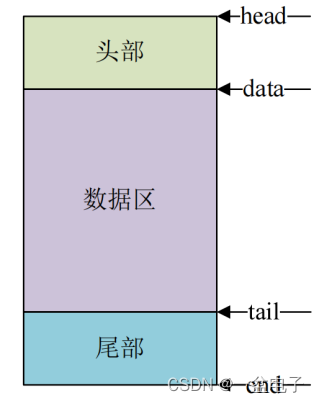
sk_buff结构体中尤其注意的是head和end指向缓冲区的头部和尾部而data和tail指向实际数据的头部和尾部。
针对sk_buff内核提供了一系列的操作与管理函数我们简单看一些常见的 API 函数
3、分配 sk_buff
要使用 sk_buff 必须先分配首先来看一下 alloc_skb 这个函数此函数定义在include/linux/skbuff.h 中函数原型如下
static inline struct sk_buff *alloc_skb(unsigned int size,gfp_t priority)
函数参数和返回值含义如下
size要分配的大小也就是 skb 数据段大小。
priority内存分配优先级为 GFP MASK 宏比如 GFP_KERNEL、GFP_ATOMIC 等。
返回值分配成功的话就返回申请到的 sk_buff 首地址失败的话就返回 NULL。
在网络设备驱动中常常使用 netdev_alloc_skb 来为某个设备申请一个用于接收的 skb_buff此函数也定义在 include/linux/skbuff.h 中函数原型如下
static inline struct sk_buff *netdev_alloc_skb(struct net_device *dev,unsigned int length)
函数参数和返回值含义如下
dev要给哪个设备分配 sk_buff。
length要分配的大小。
返回值分配成功的话就返回申请到的 sk_buff 首地址失败的话就返回 NULL。
注意的是该函数内存分配优先级设置为GFP_ATOMIC。原因是该函数经常在设备驱动的接收中断里被调用。
4、释放 sk_buff
当使用完成以后就要释放掉 sk_buff释放函数可以使用 kfree_skb函数定义在include/linux/skbuff.c 中函数原型如下
void kfree_skb(struct sk_buff *skb)
函数参数和返回值含义如下
skb要释放的 sk_buff。
返回值无。
对于网络设备而言最好使用如下所示释放函数
void dev_kfree_skb (struct sk_buff *skb)
函数只要一个参数 skb就是要释放的 sk_buff。
5、skb_put、skb_push、sbk_pull 和 skb_reserve
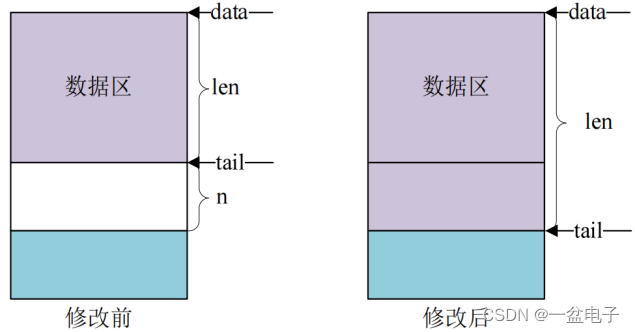
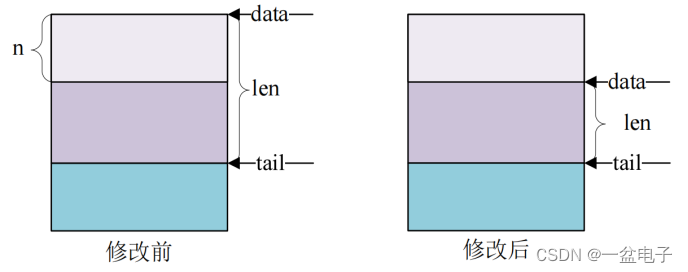
这四个函数用于变更 sk_buff先来看一下 skb_put 函数此函数用于在尾部扩展 skb_buff的数据区也就将 skb_buff 的 tail 后移 n 个字节从而导致 skb_buff 的 len 增加 n 个字节原型如下
unsigned char *skb_put(struct sk_buff *skb, unsigned int len)
函数参数和返回值含义如下
skb要操作的 sk_buff。
len要增加多少个字节。
返回值扩展出来的那一段数据区首地址。
skb_put 操作之前和操作之后的数据区如下图所示
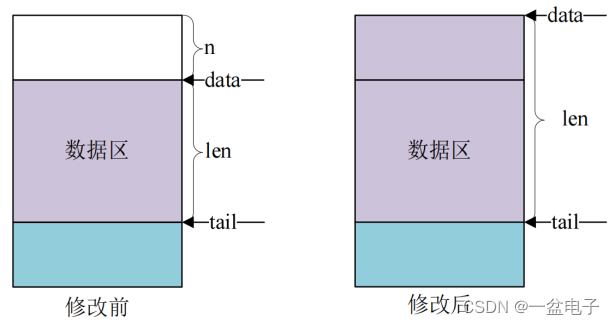
skb_push 函数用于在头部扩展 skb_buff 的数据区函数原型如下所示
unsigned char *skb_push(struct sk_buff *skb, unsigned int len)
函数参数和返回值含义如下
skb要操作的 sk_buff。
len要增加多少个字节。
返回值扩展完成以后新的数据区首地址。
skb_push 操作之前和操作之后的数据区如下图所示
sbk_pull 函数用于从 sk_buff 的数据区起始位置删除数据函数原型如下所示
unsigned char *skb_pull(struct sk_buff *skb, unsigned int len)
函数参数和返回值含义如下
skb要操作的 sk_buff。
len要删除的字节数。
返回值删除以后新的数据区首地址。
skb_pull 操作之前和操作之后的数据区如下图所示
sbk_reserve 函数用于调整缓冲区的头部大小方法很简单讲 skb_buff 的 data 和 tail 同时后移 n 个字节即可函数原型如下所示
static inline void skb_reserve(struct sk_buff *skb, int len)
函数参数和返回值含义如下
skb要操作的 sk_buff。
len要增加的缓冲区头部大小。
返回值无。
三、网络设备接口层
网络设备接口层的主要功能是千变万化的网络设备定义统一、抽象的数据结构net_device 结构体以不变应万变实现多种硬件在软件层次上的统一。
net_device 结构体在内核中指代一个网络设备网络设备驱动程序只需要填充net_device 的具体成员并注册 net_device 即可实现硬件操作函数与内核的挂接。
net_device 是一个庞大的结构体介绍一些关键成员
| 成员 | 说明 |
|---|---|
| name | 网络设备的名字 |
| mem_end | 共享内存结束地址 |
| mem_start | 共享内存起始地址 |
| base_addr | 网络设备 I/O 地址 |
| irq | 网络设备的中断号 |
| netdev_ops | 网络设备的操作集函数类似字符设备中的 file_operations |
| ethtool_ops | 网络管理工具相关函数集用户空间网络管理工具会调用此结构体中的相关函数获取网卡状态或者配置网卡 |
| header_ops | 头部的相关操作函数集比如创建、解析、缓冲等 |
| dma | 网络设备所使用的 DMA 通道 |
| mtu | 网络最大传输单元 |
| last_rx | 最后接收的数据包时间戳记录的是 jiffies |
| dev_addr | 当前分配的 MAC 地址可以通过软件修改 |
| _rx | 接收队列 |
| num_rx_queues | 接收队列数量调用 register_netdev 时会分配指定数量的接收队列 |
| real_num_rx_queues | 当前活动的队列数量 |
| _tx | 发送队列 |
| num_tx_queues | 发送队列数量通过 alloc_netdev_mq 函数分配指定数量的发送队列 |
| real_num_tx_queues | 当前有效的发送队列数量 |
| trans_start | 最后的数据包发送的时间戳记录的是 jiffies |
| phydev | 对应的 PHY 设备 |
1、申请 net_device
编写网络驱动的时候首先要申请 net_device使用 alloc_netdev 函数来申请 net_device这是一个宏宏定义如下
#define alloc_netdev(sizeof_priv, name, name_assign_type, setup) \
alloc_netdev_mqs(sizeof_priv, name, name_assign_type, setup, 1, 1)
可以看出 alloc_netdev 的本质是 alloc_netdev_mqs 函数此函数原型如下:
struct net_device * alloc_netdev_mqs ( int sizeof_priv, const char *name,
void (*setup) (struct net_device *)),
unsigned int txqs, unsigned int rxqs);
函数参数和返回值含义如下
sizeof_priv私有数据块大小。
name设备名字。
setup回调函数初始化设备的设备后调用此函数。
txqs分配的发送队列数量。
rxqs分配的接收队列数量。
返回值如果申请成功的话就返回申请到的 net_device 指针失败的话就返回 NULL。
事实上网络设备有多种大家不要以为就只有以太网一种。Linux 内核内核支持的网络接口有很多比如光纤分布式数据接口(FDDI)、以太网设备(Ethernet)、红外数据接口(InDA)、高性能并行接口(HPPI)、CAN 网络等。内核针对不同的网络设备在 alloc_netdev 的基础上提供了一层封装比如我们本章讲解的以太网针对以太网封装的 net_device 申请函数是 alloc_etherdev这也是一个宏内容如下
#define alloc_etherdev(sizeof_priv) alloc_etherdev_mq(sizeof_priv, 1)
#define alloc_etherdev_mq(sizeof_priv, count) alloc_etherdev_mqs(sizeof_priv, count, count)
可以看出alloc_etherdev 最终依靠的是 alloc_etherdev_mqs 函数此函数就是对alloc_netdev_mqs 的简单封装函数内容如下
struct net_device *alloc_etherdev_mqs(int sizeof_priv, unsigned int txqs, unsigned int rxqs)
{
return alloc_netdev_mqs(sizeof_priv, "eth%d", NET_NAME_UNKNOWN, ether_setup, txqs, rxqs);
}
调用 alloc_netdev_mqs 来申请 net_device注意这里设置网卡的名字为“eth%d”这是格式化字符串大家进入开发板的 linux 系统以后看到的“eth0”、“eth1”这样的网卡名字就是从这里来的。同样的这里设置了以太网的 setup 函数为 ether_setup不同的网络设备其 setup函数不同比如 CAN 网络里面 setup 函数就是 can_setup。
ether_setup 函数会对 net_device 做初步的初始化函数内容如下所示
void ether_setup(struct net_device *dev)
{
dev->header_ops = ð_header_ops;
dev->type = ARPHRD_ETHER;
dev->hard_header_len = ETH_HLEN;
dev->mtu = ETH_DATA_LEN;
dev->addr_len = ETH_ALEN;
dev->tx_queue_len = 1000; /* Ethernet wants good queues */
dev->flags = IFF_BROADCAST|IFF_MULTICAST;
dev->priv_flags |= IFF_TX_SKB_SHARING;
eth_broadcast_addr(dev->broadcast);
}
2、删除 net_device
当我们注销网络驱动的时候需要释放掉前面已经申请到的 net_device释放函数为free_netdev函数原型如下
void free_netdev(struct net_device *dev)
函数参数和返回值含义如下
dev要释放掉的 net_device 指针。
返回值无。
3、注册 net_device
net_device 申请并初始化完成以后就需要向内核注册 net_device要用到函数 register_netdev函数原型如下
int register_netdev(struct net_device *dev)
函数参数和返回值含义如下
dev要注册的 net_device 指针。
返回值0 注册成功负值 注册失败。
4、注销 net_device
既然有注册那么必然有注销注销 net_device 使用函数 unregister_netdev函数原型如下
void unregister_netdev(struct net_device *dev)
函数参数和返回值含义如下
dev要注销的 net_device 指针。
返回值无。
四、网络 NAPI 处理机制
NAPI 是一种高效的网络处理技术。NAPI 的核心思想就是不全部采用中断来读取网络数据而是采用中断来唤醒数据接收服务程序在接收服务程序中采用 POLL 的方法来轮询处理数据。这种方法的好处就是可以提高短数据包的接收效率减少中断处理的时间。目前 NAPI 已经在 Linux 的网络驱动中得到了大量的应用NXP 官方编写的网络驱动都是采用的 NAPI 机制。
1、初始化 NAPI
首先要初始化一个 napi_struct 实例使用 netif_napi_add 函数此函数定义在 net/core/dev.c中函数原型如下
void netif_napi_add(struct net_device *dev, struct napi_struct *napi,int (*poll)(struct napi_struct *, int), int weight)
函数参数和返回值含义如下
dev每个 NAPI 必须关联一个网络设备此参数指定 NAPI 要关联的网络设备。
napi要初始化的 NAPI 实例。
pollNAPI 所使用的轮询函数非常重要一般在此轮询函数中完成网络数据接收的工作。
weightNAPI 默认权重(weight)一般为 NAPI_POLL_WEIGHT。
返回值无。
2、删除 NAPI
如果要删除 NAPI使用 netif_napi_del 函数即可函数原型如下
void netif_napi_del(struct napi_struct *napi)
函数参数和返回值含义如下
napi要删除的 NAPI。
返回值无。
3、使能 NAPI
初始化完 NAPI 以后必须使能才能使用使用函数 napi_enable函数原型如下
inline void napi_enable(struct napi_struct *n)
函数参数和返回值含义如下
n要使能的 NAPI。
返回值无。
4、关闭 NAPI
关闭 NAPI 使用 napi_disable 函数即可函数原型如下
void napi_disable(struct napi_struct *n)
函数参数和返回值含义如下
n要关闭的 NAPI。
返回值无。
5、检查 NAPI 是否可以进行调度
使用 napi_schedule_prep 函数检查 NAPI 是否可以进行调度函数原型如下
inline bool napi_schedule_prep(struct napi_struct *n)
函数参数和返回值含义如下
n要检查的 NAPI。
返回值如果可以调度就返回真如果不可调度就返回假。
6、NAPI 调度
如果可以调度的话就进行调度使用__napi_schedule 函数完成 NAPI 调度函数原型如下
void __napi_schedule(struct napi_struct *n)
函数参数和返回值含义如下
n要调度的 NAPI。
返回值无。
我们也可以使用 napi_schedule 函数来一次完成 napi_schedule_prep 和__napi_schedule 这两个函数的工作napi_schedule 函数内容如下所示
static inline void napi_schedule(struct napi_struct *n)
{
if (napi_schedule_prep(n))
__napi_schedule(n);
}
从示例代码可以看出napi_schedule 函数就是对napi_schedule_prep和__napi_schedule 的简单封装一次完成判断和调度。
7、NAPI 处理完成
NAPI 处理完成以后需要调用 napi_complete 函数来标记 NAPI 处理完成函数原型如下
inline void napi_complete(struct napi_struct *n)
函数参数和返回值含义如下
n处理完成的 NAPI。
返回值无。
五、设备驱动功能层
net_device结构体的成员属性和net_device_ops结构体中的函数指针需要被设备驱动功能层赋予具体的数值和函数。对于具体的设备xxx应该编写相应的设备驱动功能层函数这些函数如xxx_open()、xxx_stop()等。
net_device_ops 结构体定义在 include/linux/netdevice.h 文件中net_device_ops 结构体里面都是一些以“ndo_”开头的函数这些函数就需要网络驱动编写人员去实现不需要全部都实现根据实际驱动情况实现其中一部分即可。结构体内容如下所示(结构体比较大这里有缩减)
struct net_device_ops {
int (*ndo_init)(struct net_device *dev);
void (*ndo_uninit)(struct net_device *dev);
int (*ndo_open)(struct net_device *dev);
int (*ndo_stop)(struct net_device *dev);
netdev_tx_t (*ndo_start_xmit) (struct sk_buff *skb, struct net_device *dev);
u16 (*ndo_select_queue)(struct net_device *dev, struct sk_buff *skb,void *accel_priv,select_queue_fallback_t fallback);
void (*ndo_change_rx_flags)(struct net_device *dev,int flags);
void (*ndo_set_rx_mode)(struct net_device *dev);
int (*ndo_set_mac_address)(struct net_device *dev,void *addr);
int (*ndo_validate_addr)(struct net_device *dev);
int (*ndo_do_ioctl)(struct net_device *dev,struct ifreq *ifr, int cmd);
int (*ndo_set_config)(struct net_device *dev,struct ifmap *map);
int (*ndo_change_mtu)(struct net_device *dev,int new_mtu);
int (*ndo_neigh_setup)(struct net_device *dev,
struct neigh_parms *);
void (*ndo_tx_timeout) (struct net_device *dev);
......
#ifdef CONFIG_NET_POLL_CONTROLLER
void (*ndo_poll_controller)(struct net_device *dev);
int (*ndo_netpoll_setup)(struct net_device *dev,
struct netpoll_info *info);
void (*ndo_netpoll_cleanup)(struct net_device *dev);
#endif
......
int (*ndo_set_features)(struct net_device *dev,netdev_features_t features);
......
};
fec_probe 函数设置了网卡驱动的 net_dev_ops 操作集为 fec_netdev_opsfec_netdev_ops 内容如下
static const struct net_device_ops fec_netdev_ops = {
.ndo_open = fec_enet_open,
.ndo_stop = fec_enet_close,
.ndo_start_xmit = fec_enet_start_xmit,
.ndo_select_queue = fec_enet_select_queue,
.ndo_set_rx_mode = set_multicast_list,
.ndo_change_mtu = eth_change_mtu,
ndo_validate_addr = eth_validate_addr,
ndo_tx_timeout = fec_timeout,
.ndo_set_mac_address = fec_set_mac_address,
.ndo_do_ioctl = fec_enet_ioctl,
#ifdef CONFIG_NET_POLL_CONTROLLER
.ndo_poll_controller = fec_poll_controller,
#endif
.ndo_set_features = fec_set_features,
};
1、fec_enet_open 函数简析
打开一个网卡的时候 fec_enet_open 函数就会执行函数源码如下所示(限于篇幅原因有省略)
static int fec_enet_open(struct net_device *ndev)
{
struct fec_enet_private *fep = netdev_priv(ndev);
const struct platform_device_id *id_entry = platform_get_device_id(fep->pdev);
int ret;
pinctrl_pm_select_default_state(&fep->pdev->dev);
ret = fec_enet_clk_enable(ndev, true);
if (ret)
return ret;
/* I should reset the ring buffers here, but I don't yet know
* a simple way to do that.
*/
ret = fec_enet_alloc_buffers(ndev);
if (ret)
goto err_enet_alloc;
/* Init MAC prior to mii bus probe */
fec_restart(ndev);
/* Probe and connect to PHY when open the interface */
ret = fec_enet_mii_probe(ndev);
if (ret)
goto err_enet_mii_probe;
napi_enable(&fep->napi);
phy_start(fep->phy_dev);
netif_tx_start_all_queues(ndev);
......
return 0;
err_enet_mii_probe:
fec_enet_free_buffers(ndev);
err_enet_alloc:
fep->miibus_up_failed = true;
if (!fep->mii_bus_share)
pinctrl_pm_select_sleep_state(&fep->pdev->dev);
return ret;
}
第 9 行调用 fec_enet_clk_enable 函数使能 enet 时钟。
第 17 行调用 fec_enet_alloc_buffers 函数申请环形缓冲区 buffer此函数里面会调用fec_enet_alloc_rxq_buffers 和 fec_enet_alloc_txq_buffers 这两个函数分别实现发送队列和接收队列缓冲区的申请。
第 22 行重启网络一般连接状态改变、传输超时或者配置网络的时候都会调用 fec_restart函数。
第 25 行打开网卡的时候调用 fec_enet_mii_probe 函数来探测并连接对应的 PHY 设备。
第 29 行调用 napi_enable 函数使能 NAPI 调度。
第 30 行调用 phy_start 函数开启 PHY 设备。
第 31 行调用 netif_tx_start_all_queues 函数来激活发送队列。
2、fec_enet_close 函数简析
关闭网卡的时候 fec_enet_close 函数就会执行函数内容如下
static int fec_enet_close(struct net_device *ndev)
{
struct fec_enet_private *fep = netdev_priv(ndev);
phy_stop(fep->phy_dev);
if (netif_device_present(ndev))
{
napi_disable(&fep->napi);
netif_tx_disable(ndev);
fec_stop(ndev);
}
phy_disconnect(fep->phy_dev);
fep->phy_dev = NULL;
fec_enet_clk_enable(ndev, false);
pm_qos_remove_request(&fep->pm_qos_req);
pinctrl_pm_select_sleep_state(&fep->pdev->dev);
pm_runtime_put_sync_suspend(ndev->dev.parent);
fec_enet_free_buffers(ndev);
return 0;
}
第 5 行调用 phy_stop 函数停止 PHY 设备。
第 8 行调用 napi_disable 函数关闭 NAPI 调度。
第 9 行调用 netif_tx_disable 函数关闭 NAPI 的发送队列。
第 10 行调用 fec_stop 函数关闭 I.MX6ULL 的 ENET 外设。
第 13 行调用 phy_disconnect 函数断开与 PHY 设备的连接。
第 16 行调用 fec_enet_clk_enable 函数关闭 ENET 外设时钟。
第 20 行调用 fec_enet_free_buffers 函数释放发送和接收的环形缓冲区内存。
3、fec_enet_start_xmit 函数简析
I.MX6ULL 的网络数据发送是通过 fec_enet_start_xmit 函数来完成的这个函数将上层传递过来的 sk_buff 中的数据通过硬件发送出去函数源码如下
static netdev_tx_t fec_enet_start_xmit(struct sk_buff *skb,struct net_device *ndev)
{
struct fec_enet_private *fep = netdev_priv(ndev);
int entries_free;
unsigned short queue;
struct fec_enet_priv_tx_q *txq;
struct netdev_queue *nq;
int ret;
queue = skb_get_queue_mapping(skb);
txq = fep->tx_queue[queue];
nq = netdev_get_tx_queue(ndev, queue);
if (skb_is_gso(skb))
ret = fec_enet_txq_submit_tso(txq, skb, ndev);
else
ret = fec_enet_txq_submit_skb(txq, skb, ndev);
if (ret)
return ret;
entries_free = fec_enet_get_free_txdesc_num(fep, txq);
if (entries_free <= txq->tx_stop_threshold)
netif_tx_stop_queue(nq);
return NETDEV_TX_OK;
}
此函数的参数第一个参数 skb 就是上层应用传递下来的要发送的网络数据第二个参数ndev 就是要发送数据的设备。
第 14 行判断 skb 是否为 GSO(Generic Segmentation Offload)如果是 GSO 的话就通过fec_enet_txq_submit_tso 函数发送如果不是的话就通过 fec_enet_txq_submit_skb 发送。这里简单讲一下 TSO 和 GSO:
TSO全称是 TCP Segmentation Offload利用网卡对大数据包进行自动分段处理降低 CPU负载。
GSO全称是 Generic Segmentation Offload在发送数据之前先检查一下网卡是否支持 TSO如果支持的话就让网卡分段不过不支持的话就由协议栈进行分段处理分段处理完成以后再交给网卡去发送。
第 21 行通过 fec_enet_get_free_txdesc_num 函数获取剩余的发送描述符数量。
第 23 行如果剩余的发送描述符的数量小于设置的阈值(tx_stop_threshold)的话就调用函数netif_tx_stop_queu 来暂停发送通过暂停发送来通知应用层停止向网络发送 skb发送中断中会重新开启的。
4、fec_enet_interrupt 中断服务函数简析
前面说了 I.MX6ULL 的网络数据接收采用 NAPI 框架所以肯定要用到中断。fec_probe 函数会初始化网络中断中断服务函数为 fec_enet_interrupt函数内容如下
static irqreturn_t fec_enet_interrupt(int irq, void *dev_id)
{
struct net_device *ndev = dev_id;
struct fec_enet_private *fep = netdev_priv(ndev);
uint int_events;
irqreturn_t ret = IRQ_NONE;
int_events = readl(fep->hwp + FEC_IEVENT);
writel(int_events, fep->hwp + FEC_IEVENT);
fec_enet_collect_events(fep, int_events);
if ((fep->work_tx || fep->work_rx) && fep->link)
{
ret = IRQ_HANDLED;
if (napi_schedule_prep(&fep->napi))
{
/* Disable the NAPI interrupts */
writel(FEC_ENET_MII, fep->hwp + FEC_IMASK);
__napi_schedule(&fep->napi);
}
}
if (int_events & FEC_ENET_MII)
{
ret = IRQ_HANDLED;
complete(&fep->mdio_done);
}
if (fep->ptp_clock)
fec_ptp_check_pps_event(fep);
return ret;
}
可以看出中断服务函数非常短而且也没有见到有关数据接收的处理过程那是因为I.MX6ULL 的网络驱动使用了 NAPI具体的网络数据收发是在 NAPI 的 poll 函数中完成的中断里面只需要进行 napi 调度即可这个就是中断的上半部和下半部处理机制。
第 8 行读取 NENT 的中断状态寄存器 EIR获取中断状态
第 9 行将第 8 行获取到的中断状态值又写入 EIR 寄存器用于清除中断状态寄存器。
第 10 行调用 fec_enet_collect_events 函数统计中断信息也就是统计都发生了哪些中断。fep 中成员变量 work_tx 和 work_rx 的 bit0、bit1 和 bit2 用来做不同的标记work_rx 的 bit2 表示接收到数据帧work_tx 的 bit2 表示发送完数据帧。
第 15 行调用 napi_schedule_prep 函数检查 NAPI 是否可以进行调度。
第 17 行如果使能了相关中断就要先关闭这些中断向 EIMR 寄存器的 bit23 写 1 即可关闭相关中断。
第 18 行调用__napi_schedule函数来启动 NAPI 调度这个时候 napi 的 poll 函数就会执行在本网络驱动中就是 fec_enet_rx_napi 函数。
__napi_schedule函数被轮询方式驱动的中断程序调用将设备的poll方法添加到网络层的poll处理队列中排队并且准备接收数据包最终触发一个NET_RX_SOFTIRQ软中断从而通知网络层接收数据包。
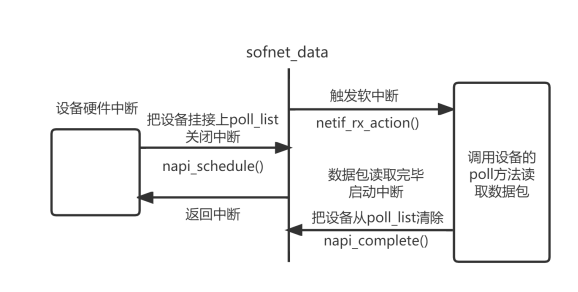
fec_enet_init 函数初始化网络的时候会调用 netif_napi_add 来设置 NAPI 的 poll 函数为 fec_enet_rx_napi函数内容如下
static int fec_enet_rx_napi(struct napi_struct *napi, int budget)
{
struct net_device *ndev = napi->dev;
struct fec_enet_private *fep = netdev_priv(ndev);
int pkts;
pkts = fec_enet_rx(ndev, budget);
fec_enet_tx(ndev);
if (pkts < budget) {
napi_complete(napi);
writel(FEC_DEFAULT_IMASK, fep->hwp + FEC_IMASK);
}
return pkts;
}
第 7 行调用 fec_enet_rx 函数进行真正的数据接收。
第 9 行调用 fec_enet_tx 函数进行数据发送。
第 12 行调用 napi_complete 函数来宣布一次轮询结束
第 13 行设置 ENET 的 EIMR 寄存器重新使能中断。
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |