

对抗性自动编码器系列--自动编码器AutoEncoder的原理及实现-手写数字的重建
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
文章目录
- 前言
- 自动编码器介绍
- 自动编码器重建手写数字
- 关于损失函数
- 重建结果
- 这部分实验代码
前言
先来看看实验:
我们使用 MNIST 手写数字,测试通过自动编码器和对抗性自动编码器学习重建恢复效果。
- 原始图像:
- 自动编码器重建效果
- 对抗性自动编码器重建效果
虽然这里看到,自动编码器和对抗性自动编码器重建出来的能力差不多,但是他们之间的差别在哪里,之后通过更多的实验告诉大家。
大多数人类和动物学习都是无监督学习。如果把人工智能比作一个蛋糕,那么无监督学习就是蛋糕,监督学习就是蛋糕上的糖衣(锦上添花),强化学习就是蛋糕上的樱桃🍒(锦上添花)。
我们知道如何制作糖衣和樱桃,但我们不知道如何制作蛋糕。
同样,我们需要先解决无监督学习问题,然后才能考虑实现真正的人工智能。
我们知道可以使用卷积神经网络 (CNN) 或在某些情况下密集全连接层 (MLP — 有人喜欢称之为多层感知器) 来执行图像识别。
但是,单独的 CNN(或 MLP)不能用于执行诸如从图像中分离内容和风格(content and style)、生成真实的图像(生成模型)、使用非常小的标记集对图像进行分类或执行数据压缩等任务。
这些任务中的每一个都可能需要特别的架构和训练算法。但是,如果我们能够仅使用一种架构来实现上述所有任务,那不是很酷吗?对抗性自动编码器(一种以半监督方式训练的)可以仅使用一种架构来执行所有这些任务甚至更多。
我们学习自动编码器有什么用?
重建图像本身自然是没有任何意义的,但是能把图像重建出来,说明模型学到了输入图像集的分布和特征。
- 提取图像特征,特征我们可以拿来做影像组学。
- 异常检测,图像的分布可以拿来做异常检测。
- 图像去噪,其中可以使用有噪声的图像生成清晰的无噪声图像。
- 语义散列可以使用降维来加快信息检索速度。
- 最近,以对抗方式训练的自动编码器可以用作生成模型(我们稍后会深入探讨)。
具体地, 我们将从以下几部分来介绍:
- 自动编码器重建 MNIST 手写数字
- 对抗性自动编码器重建 MNIST 手写数字
- 半监督自动编码器重建 MNIST 手写数字
- 使用自动编码器对 MNIST 进行分类
本系列会仔细的讲解自动编码器(AutoEncoder, AE),对抗性自动编码器(Adversarial AutoEncoder, AAE)的的原理和实战。学会了基础,可以尝试看看有没有新颖的研究课题可以做。
自动编码器介绍
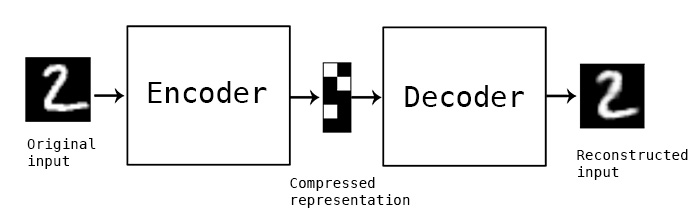
自动编码器(以下简称AE)不一定大家都有了解,但是,提到 Unet,大家都熟悉吧。把 Unet中间的跳跃连接拿掉,它就是一个自动编码器。
只不过Unet是拿来做分割,输出的是分割结果。自动编码器是拿来做重建,希望输出=输入。因此,二者用的loss上会有区别。
来看一下相对正式的定义:
Autoencoder 是一种神经网络,经过训练可以产生与输入非常相似的输出(因此它基本上尝试将其输入复制到其输出),并且由于它不需要任何标签,因此可以对其进行无监督训练。
它包含两个部分: Encoder, Decoder
- Encoder(编码器):它接受输入 x(可以是图像、词嵌入、视频或音频数据)并产生输出 h(其中 h 通常比
x 具有更低的维度)。
例如,编码器输入为: 100 x 100 的图像 x ,输出 100 x 1(可以是任何大小)的输出 h。在这种情况下,编码器只是压缩图像,使其占据较低维度的空间,在这样做时,我们现在可以看到,与直接存储图像 x 相比,可以使用 1/100 的内存来存储 h(大小为 100 x 1) (虽然这会导致一些数据丢失)。
这里的 h 通常说的是 latent space(潜在空间,模型图上一般用 z 表示)。(这个概念很重要,会经常提到)
一个更形象的解释:
让我们想想像 WinRAR 这样的压缩软件,它可用于压缩文件以获得占用较少空间的zip(或 rar,…)文件。编码器就是干这个事,不断地压缩输入。
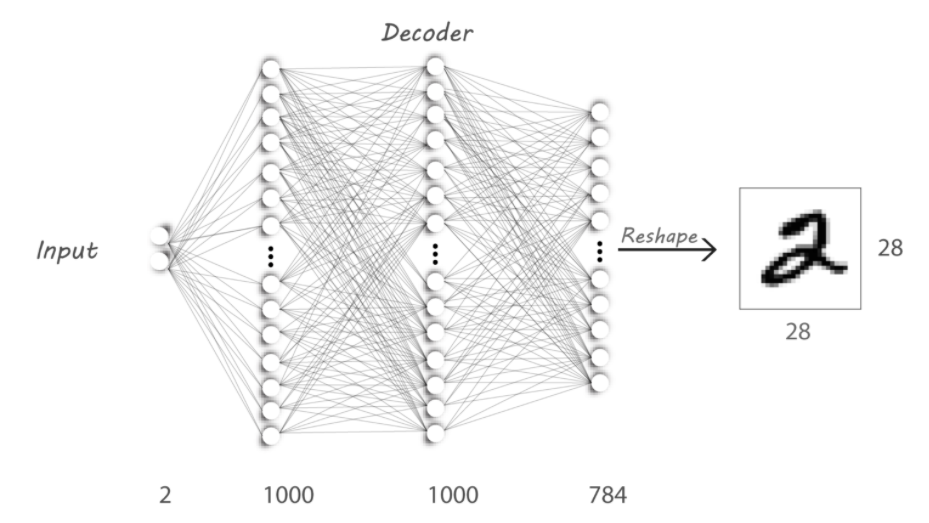
- Decoder(解码器):它将 Encoder h 的输出作为输入,并尝试恢复 Encoder 的输入。
例如: h 现在的大小为 100 x 1,解码器尝试使用 h 恢复原始的 100 x 100 图像。我们将训练 Decoder 从 h 中获取尽可能多的信息以重构 x。
因此,Decoder 的操作类似于在 WinRAR 上执行解压缩。
一句话总结:Encoder做降维,Decoder用来恢复。
接下来,我们使用 AE 来重建手写数字。
自动编码器重建手写数字
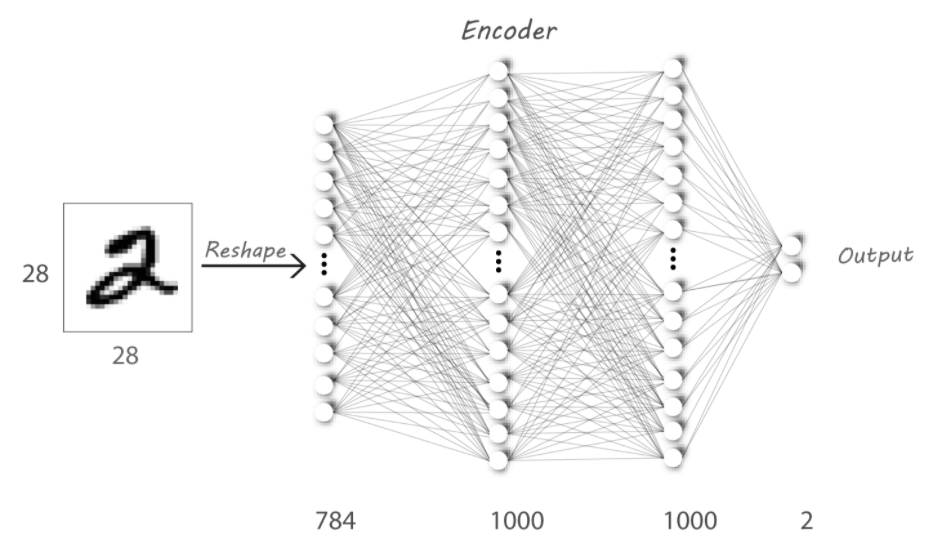
我们设计一个具有3个全连接层的 Encoder 和 Decoder。Encoder的输入是手写数字,图像尺寸为28*28,把它 reshape 成 784 个神经元的输入层。这里我们将latent space(z) 设置为2.
相当于我们把一个28*28大小的图像,压缩到2个像素点,Decoder通过这个两个点恢复出输入图像的信息。咋一看,实在有些不敢相信,2个点就能表征一个图像,我们试试看~~~~
关于损失函数
使用的损失函数是均方误差 (MSE),它计算输入 (x_input) 和输出图像 (decoder_output) 中像素之间的距离。我们称之为重建损失,因为我们的主要目标是在输出端重建输入。
重建结果
原始图像

恢复结果

看起来,还是能把数字重建的差不多,虽然模糊了些。有3个重建错误。
我们把 Encoder 的输出给 Decoder,基本能恢复出数字的样子来。
但,我们随机产生两个数字,传给 Decoder 会怎么样呢?试试看
我们把(0,0)数字作为 Decoder 的输入,会输出什么呢?

感觉像数字,又不像数字!
为什么我们不能从在随机数中采样,恢复出图像呢?
这是因为我们得到的 latent space 并没有覆盖整个二维空间,如果我们随机输入的 z 不是在 latent space 中采样的,那自然也恢复不出来。那我们怎么知道 latent space 到底是一个什么分布呢,如何从 latent space 中采样呢?
这可以通过在生成 latent space 时将 Encoder 的输出限制为具有某种随机分布(例如平均值为 0.0 且标准差为 2.0 的正态分布), 这样我们在这个正态分布中采样2个点,就可以很好地恢复图像。这正是对抗性自动编码器的能力,我们将在第 2 部分研究它的实现。
这部分实验代码
- 文中内容参考
- 原作者 Tensorflow 代码
- Tina 姐的代码 GitHub上提供了详细的代码说明。
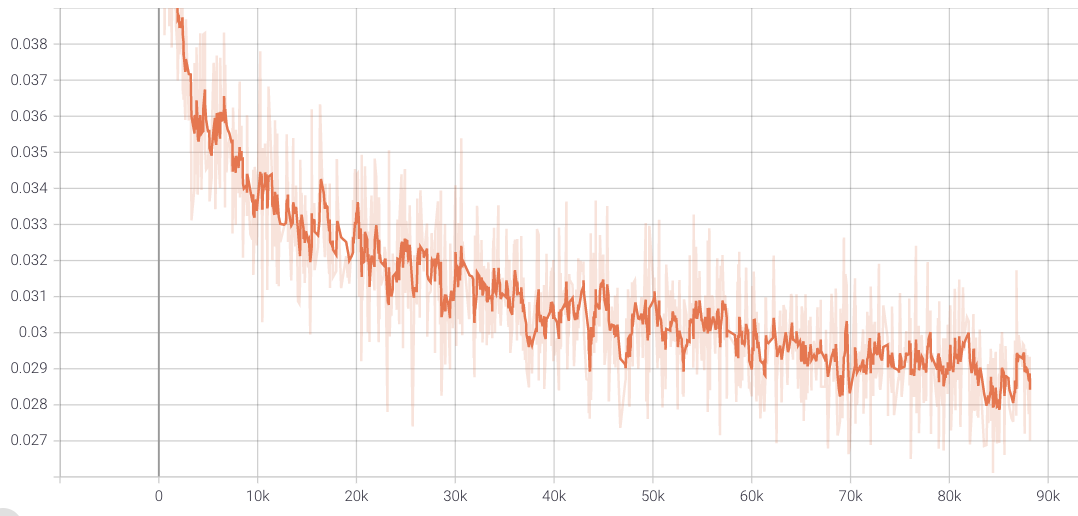
- 我的 pytorch 代码训练结果
loss
输入图像

重建结果

文章持续更新,可以关注微信公众号【医学图像人工智能实战营】获取最新动态,一个关注于医学图像处理领域前沿科技的公众号。坚持已实践为主,手把手带你做项目,打比赛,写论文。凡原创文章皆提供理论讲解,实验代码,实验数据。只有实践才能成长的更快,关注我们,一起学习进步~
我是Tina, 我们下篇博客见~
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |