

倚天剑第一式——爬虫基础
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
博主简介博主是一个大二学生主攻人工智能领域研究。感谢缘分让我们在CSDN相遇博主致力于在这里分享关于人工智能C++python爬虫等方面的知识分享。如果有需要的小伙伴可以关注博主博主会继续更新的如果有错误之处大家可以指正。
专栏简介本专栏致力于研究python爬虫的实战涉及了所有的爬虫基础知识以及爬虫在人工智能方面的应用。文章增加了JavaScript逆向网站加密和混淆技术AST还原混淆代码WebAssemblyAPP自动化爬取Android逆向等相关技术。同时为了迎合云原生发展同时也增加了基于KubernetesDockerPrometheusGrafana等云原生技术的爬虫管理和运维解决方案。
博主分享给大家分享一句我很喜欢的话“每天多一点努力不为别的值为日后能够多一些选择选择舒心的日子选择自己喜欢的人”


爬虫基础
在写爬虫之前我们需要先了解一些基础知识如HTTP原理网页的基础知识爬虫的基本原理Cookie的基本原理多进程和多线程的基本原理等了解这些有助于帮助我们更好的理解和编写网络爬虫相关的程序。
HTTP基本原理
URI和URL
URI的全称为(Uniform Resourse Identifier),即统一资源标志符URL的全称是(Uniform Resourse Locator),即统一资源定位符。简而言之就是我们在访问一个网站的时候点开网站的链接这个链接就是URL或URI。

根据图中所展示的URI和URL的关系URL是URI的子集这其中还包括了一个URNURN全称 (Uniform Resourse Name根据名字我们就可以知道这只是一个资源命名他不为资源做任何定位处理你可以理解为一本书的编号可以唯一标识这本书但是却不能告诉我们怎么去买到它。在目前的互联网中URN用的很少几乎所有都是URI和URL所以对于一般的网页链接我们都可以称之为URI或URL一般称为URL博主习惯。但是URL也有他的格式:
其中括号所代表的是非必要部分https:baidu.com。这里就简单的解释必要的部分的含义
1.schame协议一般是https除了这个其他常用的协议由httpftp等另外审查么也被称为protocol二者都是代表协议的意思。
2.hostname主机地址可以是域名或IP地址
3.parameters参数用来指定访问某个资源时的附加信息但是现在用的很少所以很多人都将parameters和query混用。
HTTP和HTTPS
爬虫中爬取的网页一般都是基于http或https协议的因此我们的所有示例均是以以http或https协议为基础的网页链接。
HTTP的全称是Hypertext Transfer Protocol中文名为超文本传输协议其作用是把超文本数据从网络传输到本地浏览器能够保证高效而准确的传输超文本文档。HTTP是由万维网协会Word Wide Web Consortium和Internet工作小组IEFTInternet Engineering Task Force合作制定的规范。
HTTPS的全称是Hypertext Transfer Protocol Secure Socket Layer是以安全为目标的HTTP通道简单来讲就是HTTP的安全版即在HTTP下加入SSL层简称HTTPS。
注HTTP和HTTPS协议都属于计算机网络中的应用层协议其下层是基于TCP协议实现的TCP协议属于计算机网络中的传输层协议。本专栏的目的是为了讲解爬虫知识因此这里就不对TCPIP等类容进行深入讲解如果感兴趣的话博主推荐两本书《计算机网络》和《图解HTTP》。
HTTP请求过程
在浏览器地址栏中输入一个URL按下回车便可观察到对应的页面信息。实际上这个过程是浏览器先向网站所在的服务为器发送一个请求网站服务器接收到请求后对其进行处理和解析然后返回对应的相应接着传回浏览器。浏览器再对传回的响应包中的页面源代码进行解析。

为了更直观的说明上述情况这里用Chorme浏览器开发者模式下的NetWork监听组件来做一下演示。
打开chorme浏览器访问百度这时候单击鼠标右键并选择“检查”或者按F12。如图
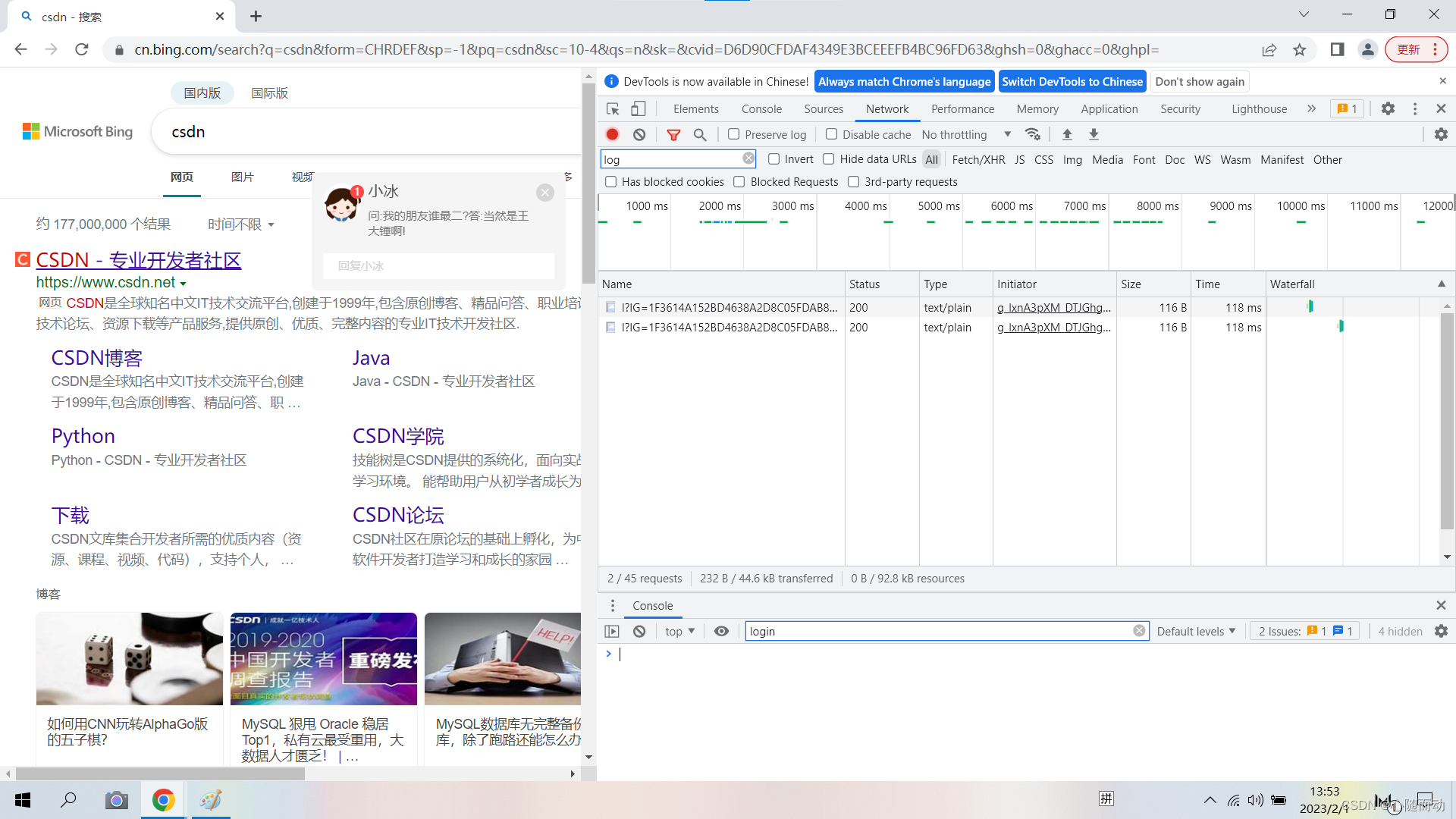
右边的显示就是Network组件我们没刷新一次就会看到Network中多几个条目其中一个条目就代表一次发送请求和接收响应的过程。
现在我们来分析一下各列的意义
1第一列Name请求的名称一般会用URL的最后一部分类容作为名称。
2第二列Status响应的状态码。这里显示200代表响应正常。通过状态码我们就可以判断发送请求之后是否得到了正常的响应。
3第三列Protocol请求的协议类型。h1代表HTTP1.1版本h2表示HTTP2版本。
4第四列Type请求的文档类型这里显示的是text表示是text类型document则代表HTML文档。
5第五列Initiator请球源。用来标记请求是由哪个对象或进程发起的。
6第六列Size从服务器下载的文件或请求的资源大小。如果资源是从缓存中取得的则该列显示from cache。
7第七列Time从发起到获取响应所花费的时间。
8第八列Waterfall网络请求的可视化瀑布流。
上面展示的图示和解释有所差别这是因为博主只是点开了一个搜索网页大家点开了子网页就会出现完整的Network组件监听
单击条目就可以获得具体信息
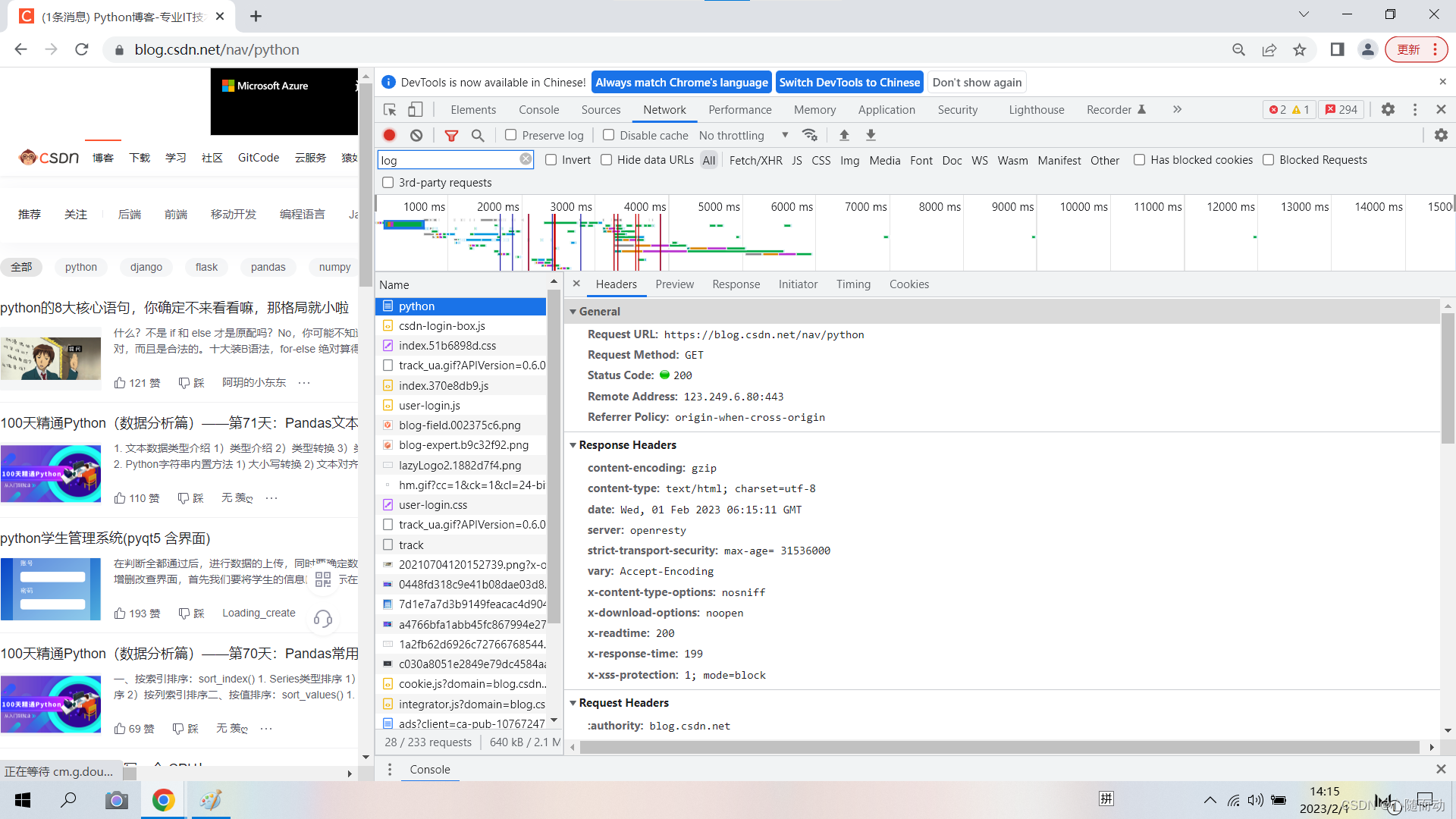
我们后续的文章中在进行爬虫的时候就会根据这其中的信息进行操作。
首先General部分其中Requests URL为请求的URLRequests Method为请求的方法Status Code为响应状态码Remote Address 为远程服务器的地址和端口Refer热热 Policy为Referrer判别策略。
请求
请求英文为Request由客户端发往服务器分为四部分内容请求方法Request Method请求的网址Request URL请求头Request Headers请求体Request Body。
⚪请求方法
在浏览器中输入一个网址URL点击回车这个时候一般是发送GET请求请求的参数会包含到URL中。POST请求一般则是在提交表单的时候例如你在登陆的时候填好密码用户名点击登陆的时候这时候就是POST请求。
二者的区别
①GET请求的参数包含在URL中数据可以在URL中看到POST请求的URL中则不会包含这些数据数据都是以表单形式传输会包含在请求体中。
②GET请求提交的数据最多为1024字节而POST则没有限制。
当然除了这些的请求方式还有其他的请求方式例如HEADPUTDELETE,CONNECT,OPTIONS,TRACE等。
| 方法 | 描述 |
|---|---|
| GET | 请求页面并返回页面内容 |
| POST | 大多数用于提交表格或上传文件数据包含在请求体中 |
| PUT | 用客户端传向服务器的数据取代指定文档中的内容 |
| DELETE | 请求服务器删除指定的页面 |
| CONNECT | 把服务器当作跳板让服务器当作客户端访问其他页面 |
| OPTIONS | 允许客户端查看服务器的性能 |
| TRACE | 回显服务器收到的请求主要用于测试和诊断 |
| HEAD | 和GET请求相似但是返回的响应没有具体的内容用于获取报头 |
请求的网址
①请求头
用来说明服务器要使用的附加信息。
1Accept请求报头域用于指定客户端可以就收哪些类型的信息。
2Accept-Language用于指定客户端可以接受的语言类型。
3Accept-Encoding用于指定客户端可以使用的编码类型
4Host用于指定请求的客户端的IP和端口号其内容为请求URL的原始服务器或网关的位置。
5Cookie也常用复数形式Cookies这是网站为了辨别用户进行会话跟踪而存储在用户本地的数据。
6referer用于标识请求是从哪个页面发来的服务器可以根据这一信息并作出相应的处理如做来源统计防盗链处理等。
7User-Agent简称UA这是一个特殊的字符串头可以使服务器识别客户端使用的操作系统及版本浏览器版本等信息。做爬虫时可以加上此信息可以伪装成浏览器如果不加很容易被识别出来。
8Content-Type也叫互联网媒体类型Internet Media Type或者MIME类型在HTTP协议消息头中它用来表示具体请求中的媒体类型信息。例如text/html代表html格式image/gif代表GIF图片application代表JSON类型。
②请求体
请求体一般承载的内容为POST请求中的表单数据对于GET请求为空。
响应
响应即Response由服务器返回给客户端可以分为三部分响应状态码Response Status Code响应头Response Headers和响应体Response Body。
响应状态码表示服务器响应的状态200表示正常404表示页面没有找到500代表服务器内部发生错误。
①响应头
响应头包含了服务器对请求的应答信息如Content-TypeServerSet-Cookie等。这里就不过多介绍了。
②响应体
响应体是最为重要的响应的所有正文数据都存在响应体中例如请求网页时响应体就是HTML代码。

Web网页基础
我们用浏览器访问不同的页面的时候所呈现的页面都有所不同你有没有想过为什么会这样本节我们就了解一下网页的组成结构和节点等内容。由于博主不是主攻前端所以这里只能简单的介绍。
网页的组成
网页可以分为三大部分——HTMLCSSjavaScript。如果把网页比作一个人那么HTML就相当于骨架CSS为皮肤JavaScript相当于肌肉。这三者结合起来就能杏形成网页。‘
HTML
HTMLHypertext Markup Language中文翻译为超文本标记语言。但是一般称为HTML。
HTML是一种用来描述网页的语言。网页包括图片文字视频按钮等复杂元素。网页通过不同类型的标签来表示不同类型的元素如用img标签表示图片用video表示视频用p标签表示段落这些标签之间的布局常由布局标签div嵌套组合而成。各种标签通过不同的排列和嵌套形成最终的网页框架。

打开浏览器开发者工具点击Elements这里显示就是HTML代码。
CSS
HTML定义了网页的骨架但是只有HTML的页面布局并不完美为了让网页看起来好看就可以用CSS。
CSS全称为Cascading Style Sheets即层叠样式表。“层叠”是指当HTML中引用多个样式文件并且样式发生重叠的时候浏览器能够按照层叠顺序来处理这些样式。“样式”是指网页中文字大小颜色排列间距等格式。CSS是目前唯一的网页页面排版样式标准。
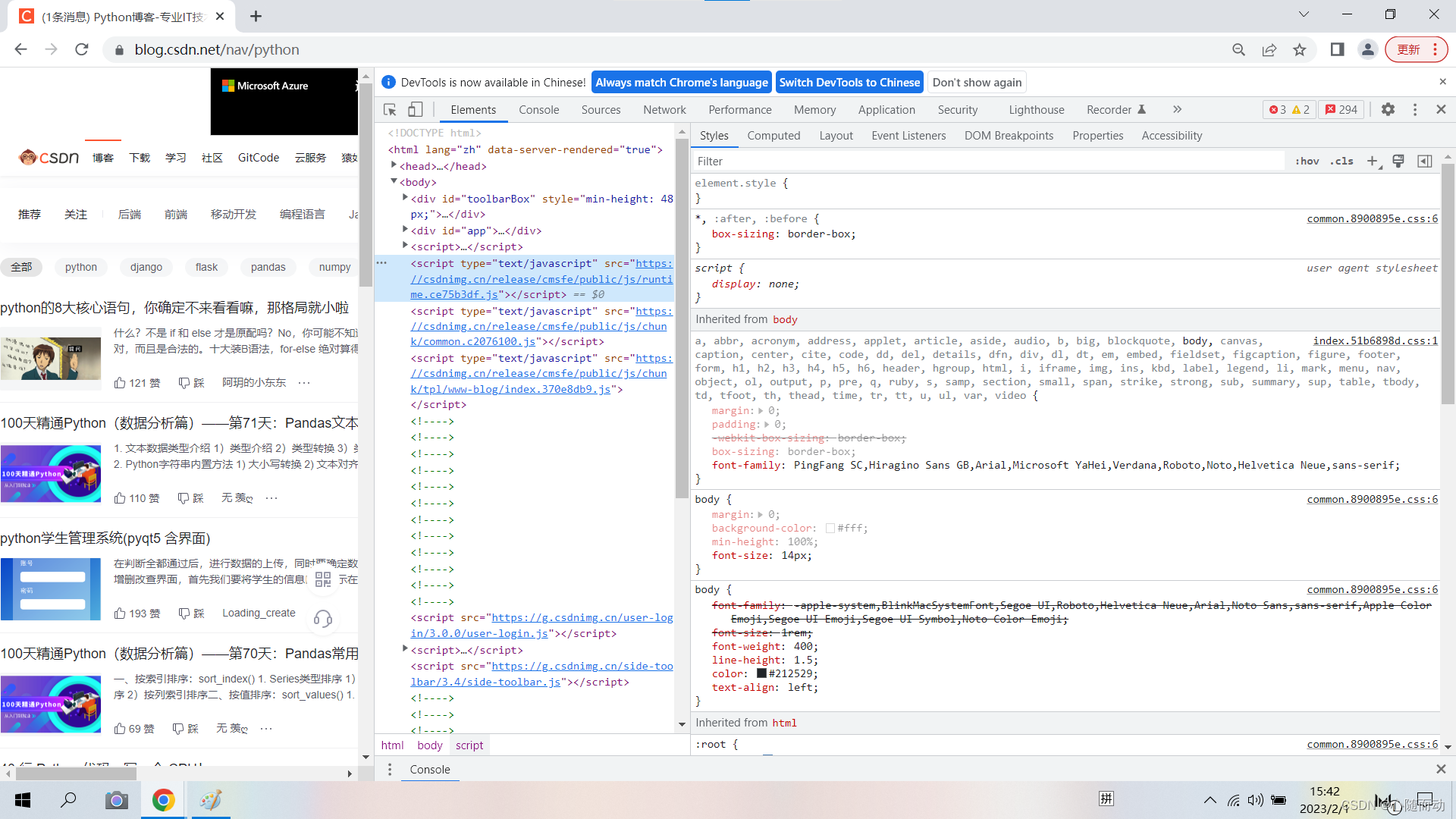
style中的就是CSS样式。
JavaScript
javaScript简称js是一种脚本语言HTML和CSS组合使用提供给用户的只是一种静态信息缺乏交互性。我们在网页中还可以看到交互和动画效果例如进度条提示框轮播图等。这就是JavaScript的功能。
JavaScript一般也是以单独的文件来运行加载后缀为.js在HTML中通过script标签即可引入
<script src='jquery-2.1.0.js></script>
这里的标签格式要记住后面的爬虫会用到。
网页的具体知识这里就不做介绍感兴趣的小伙伴可以去搜索相关知识。
爬虫的基本原理
我们把互联网比作一个大的蜘蛛网那么爬虫就是蜘蛛网上的蜘蛛没爬寻一个节点就相当于访问了一个页面获取了信息。顺着节点连线连续爬行到达下一个节点意味着爬虫可以通过网页之间的链接关系继续获取后续的网页当整个网页涉及的页面被爬取下来数据也就保存下来了。
简单来讲爬虫就是获取网页并提取和保存信息的自动化程序。
1.获取网页
2.提取信息
3.保存数据
4.自动化程序
代理的基本概念
由于爬虫的访问频率很快现在的服务器都会由反爬虫机制一旦你访问频率过快就会被锁IP也会发生报错。于是python推出了IP代理。
基本原理
代理实质就是代理服务器。我们不是用IP代理爬虫的时候我们会向服务器发送请求服务器返回响应。设置服务器代理就相当于在客户端和服务器之间搭一座桥此时我们发送请求的时候先向伪代理器发送请求伪代理器再将请求发送到网页服务器同理返回的响应也要经过伪代理器。而这个过程中Web服务器识别的IP不再是客户端的IP成功实现了IP伪装这就是代理的基本原理。
爬虫代理
如果我们平凡的去访问一个网页那么此网站就会让我们输入验证码或者锁IP爬虫就不能继续正常运行所以我们就需要用代理隐藏真实的IP这就叫做爬虫代理也叫IP代理我习惯叫做IP代理。
代理分类
对代理进行分类时可以根据协议也可以根据代理的匿名程度。
①根据协议区分
1.FTP代理服务器主要用于访问FTP服务器一般有上传下载以及缓存功能。端口一般为212121等。
2.HTTP代理服务主要用于访问网页一般有内容过滤和缓存功能端口一般为8080803128等。
3.SSL/TLS代理主要用于访问加密网站一般有SSL或TLS加密功能最高支持128位加密强度端口一般为443.
4.RTSP代理主要用于Realplayer访问Real流媒体服务器一般有缓存功能端口一般为554.
5.Telnet代理主要用于Telnet远程控制黑客入倾计算机时常用于身份隐藏端口一般为23.
6.POP3/SMTP代理主要用于以POP3/SMTP方式收发邮件一般有缓存功能端口为110/25.
7.SOCKS代理只是单纯的传递数据包不关心具体协议和用法所以速度很快一般有缓存功能能端口一般为1080.SOCKS代理协议又分为SOCKS4和SOCKS5SOCKS4协议只支持TCPSOCLKS5则支持TCP和UDP还支持各种身份验证机制服务器端域名解析等。简单来说SOCKS4能做到的SOCKS5能做到SOCKS5能做到的SOCKS4不能做到。
②.根据匿名程度分
1.高度匿名代理高度匿名代理会将数据包原封不动的转发在服务端看来似乎真的是一个普通的客户端在访问记录的IP则是代理服务器的IP。
2.普通匿名代理普通匿名代理会对数据包进行一些改动服务端可能会发现正在访问自己的是一个代理IP并且有一定的概率去追查客户端真实的IP。这里的代理服务器通常会加入的HTTP头HTTP_VIA和HTTP_X_FORWARDED_FOR.
3.透明代理透明代理不但改动了数据包还告诉了服务器客户端真实的IP这种技术可以提高浏览速度和用内容过滤提高安全性其他的没啥用处。
4.间谍代理间谍代理是组织或个人创建的代理服务器用于记录用户传输的数据然后对记录的数据进行研究监控等。
爬虫中还涉及了多线程和多进程的知识他们我已经在前面的文章中介绍过了这里就不过多解释了后面实际操作中会进行介绍。
总结
本篇文章作为本专栏的第一篇文章目的是了解一下爬虫的相关知识为后面的爬虫学习打好基础。由于博主对前端知识不是很了解文章中涉及的网页知识不够深入如果有错误敬请各位小伙伴指出。
开学了预祝各位同学学习进步生活安康万事如意
