

小记(hadoop)
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
这里写自定义目录标题
大数据四个特征:
数据量大 Volume
价值低 Value
种类繁多 Variety
增长速度快 Velocity
hadoop三大组件
mapreduce
hdfs
yarn
HDFS文件系统的读写原理
读
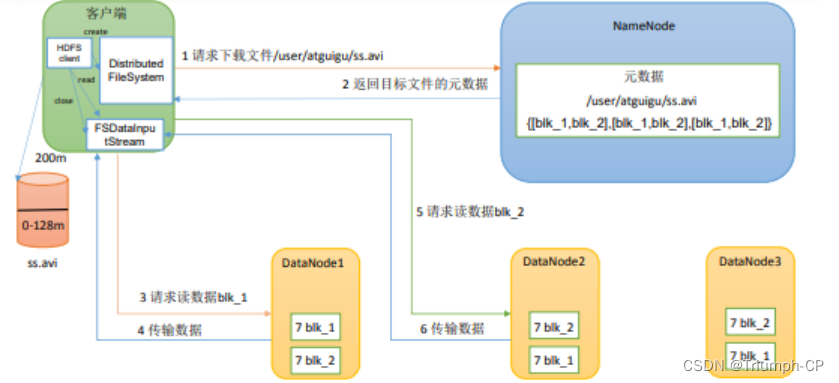
1、客户端通过 DistributedFileSystem 向 NameNode 请求下载文件NameNode 通过查询元数据找到文件块所在的 DataNode 地址。
2、挑选一台 DataNode就近原则然后随机服务器请求读取数据。
3、DataNode 开始传输数据给客户端从磁盘里面读取数据输入流以 Packet 为单位
来做校验。
4、客户端以 Packet 为单位接收先在本地缓存然后写入目标文件
写
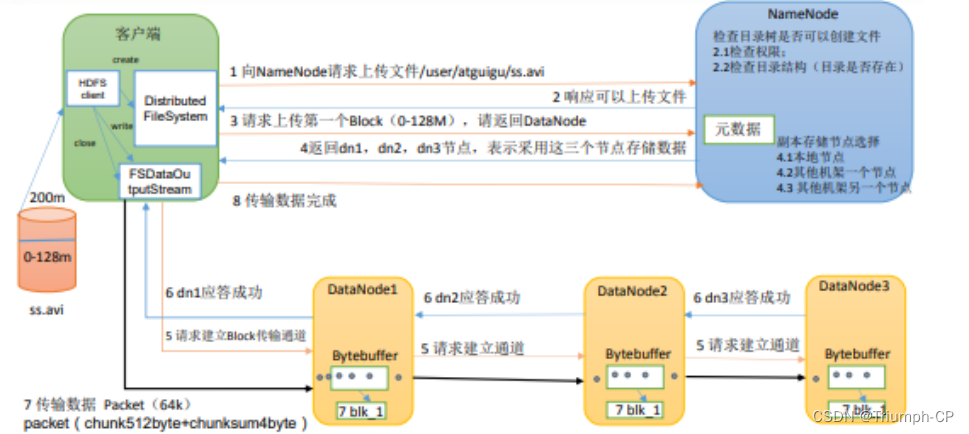
1、客户端向namenode请求上传文件
2、namenode响应可以上传文件
3、客户端请求上传第一个block询问namenode请求返回datanode
4、namenode向客户端返回datanode值存在哪
5、客户端向datanode请求建立传输通道
6、datanode应答
7、客户端向datanode传输数据
8、客户端向namenode发送传输成功请求传输第二个block重复3-7
mapreduce工作原理
MapReduce模型主要包含Mapper类和Reducer类两个抽象类。Mapper类主要负责对数据的分析处理最终转化为key-value数据对;Reducer类主要获取key-value数据对然后处理统计得到结果。MapReduce实现了存储的均衡但没有实现计算的均衡。
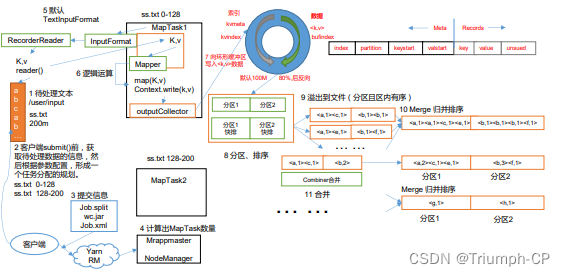
逻辑角度分析作业运行顺序:输入分片(input split)、map阶段、combiner阶段、shuffle阶段、reduce阶段
1、在客户端提交前将待处理的文本split
2、然后提交给yarn计算出MapTask数量
3、通过io流将数据传入MapTask中通过Mapper进行逻辑计算再将数据通过io流传出
4、数据传出来进入环形缓冲区写入<k,v>数据进行分区、排序
5、从内存缓冲区不断溢出本地磁盘文件可能会溢出多个文件
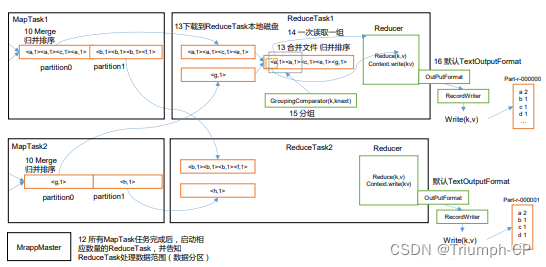
6、多个溢出文件会被合并成大的溢出文件在溢出过程及合并的过程中都要调用 Partitioner 进行分区和针对 key 进行排序
7、ReduceTask 根据自己的分区号去各个 MapTask 机器上取相应的结果分区数据
8、ReduceTask 会抓取到同一个分区的来自不同 MapTask 的结果文件ReduceTask 会将这些文件再进行合并归并排序
9、合并成大文件后Shuffle 的过程也就结束了后面进入 ReduceTask 的逻辑运算过程从文件中取出一个一个的键值对 Group调用用户自定义的 reduce()方法