

学术加油站|机器学习应用在数据库调优领域的前沿工作解读
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
编者按
本文系北京理工大学科研助理牛颂登所著本篇也是「 OceanBase 学术加油站」系列稿件第八篇。
「牛颂登北京理工大学科研助理。 硕士期间在电子科技大学网络空间安全研究院从事聚类和强化学习相关算法研究在应用聚类研究个性化在线学习和强化学习的奖励函数设计方向取得了一定成果目前研究方向为机器学习和数据库相结合的领域。」
本文以 VLDB 2021 的三篇 database tuning 论文为例对机器学习应用在数据库调优领域的前沿工作做了总结和概述。希望阅读完本文你可以对“database tuning”有新的认识有什么疑问也可以在底部留言探讨。
现代数据库管理系统(database management systems下简称 DBMS)公开了许多可配置的控制运行时行为的旋钮。 正确选择 DBMS 的配置对于提高系统性能和降低成本至关重要。但是由于 DBMS 的复杂性调优 DBMS 通常需要有经验的数据库管理员(database administrators简称 DBAs)付出相当大的努力。 最近关于使用机器学习(Machine LearningML)的自动调优方法的研究表明与专业 DBA 相比基于 ML 的自动调优方法获得了更好的性能。
An Inquiry into Machine Learning-based Automatic Configuration Tuning Services on Real-World Database Management Systems[1]
一调优过程
为了更好地理解 DBMS 的配置调优探究在真实的企业级 DBMS 上 ML 调优方法的效果论文通过运行在具有非本地存储的虚拟计算设施上的 Oracle DBMS 实例来比较企业数据库真实工作负载跟踪下的三种 ML 算法GPR、DNN、DDPG的调优效果。
论文的主要工作主要是扩展了 OtterTune 调优服务来支持三种 ML 调优算法并提出了对三种算法的优化在实验的过程中发现了一些自动调优技术领域中被忽略的部署和度量问题。
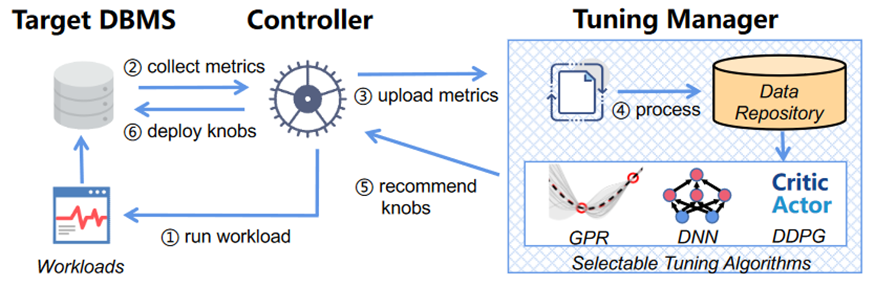
图 1 OtterTune 架构
OtterTune 是一个调优服务它用来为 DBMS 的旋钮配置找到合适的设置由controller 和 tuning manager 组成。 其中 controller 充当目标 DBMS 和 tuning manager 之间的中介它在目标 DBMS 上执行目标工作负载并收集运行时数据包括旋钮配置和系统的度量。Tuning manager 使用 controller 提供的调优会话信息更新其数据存储库并使用这些信息建立 DBMS 如何响应不同旋钮配置的 ML 模型然后用这些模型来指导实验并推荐新的配置给 controller以将配置部署到 DBMS 上。这样的迭代过程一直持续到用户对配置的改进满意为止。
▋ Target Database Application
因为论文探究的是真实企业 DBMS 的 ML 自动调优对系统性能提升的效果作者在 Société Générale SG多国银行的实际业务数据下对 OtterTune 框架进行了评估。论文中使用了 TicketTracker 这一数据和工作负载跟踪的应用程序对 SG 的工作单据进行 2 小时的跟踪收到包含超过 360 万个查询调用。
作者使用 Oracle Recovery Manager 工具从 TicketTracker 数据库的生产服务器上创建了快照复制了磁盘上未压缩的 1.1 TB 大小的数据库并做了分析其中 27%为表数据19% 为表索引54% 为大对象(Large objetcs)。TicketTracker 数据库包含 1226 个表其中只有 453 个有数据的表数据库基于它们包含 1647 个索引。
论文中使用 Oracle 的 real application testingRAT 工具来捕获在 DBMS 实例上执行的查询RAT 支持在测试数据库上使用原始工作负载的精确时间、并发性和事务特征对实例上的查询进行多次重放重放的时间被限制在一个 10 分钟的片段包含 23 万条查询。
TicketTracker 数据库相比于之前一些 ML 调优采用的工作负载 benchmark——TPC-C有数百个表而 TPC-C 只有 9 个表TPC-C 查询的写的比率占到46%而 TicketTracker 里只占了 9%。这也表明实际的企业级 DBMS 与已有研究中的 benchmark 有很大不同。
优化算法的目标函数设置为 Oracle 的 DB Time它用于度量数据库在处理用户请求时所花费的总时间也是 SG 专业 DBA 首选的指标。论文在 SG 私有云的单独 Oracle v12.2 安装上部署了 TicketTracker 数据库和工作负载的五个副本。
二调优算法

图2 GPR/DNN调优管道
论文中的 GPR 实现基于 OtterTune 支持的原始算法采用高斯过程作为先验函数计算测试点与所有训练点之间的距离该算法利用核函数来预测测试点的值和不确定度。由两阶段组成第一个是数据预处理阶段它在 Otter Tune 的数据存储库中准备旋钮配置和系统的度量数据。第二个是旋钮推荐阶段为旋钮选择合适的值。
数据预处理 目的是为了降低度量的维度并选出最重要的一些的 knobs。在这一阶段首先确定 DBMS 度量的子集算法使用因子分析factor analysis的降维技术能够将度量减少到更小的因子集合。将度量降维后继续计算对目标函数影响最大的旋钮的排序列表。论文使用了 Lasso 的特征选择方法其中旋钮数据作为输入 X输出的是结合已经修剪过的度量的目标数据。Lasso 在 X 和 y 之间的回归过程中确定了重要的旋钮顺序。
旋钮推荐 负责在调优会话的每次迭代结束时生成一个新的旋钮配置建议。该算法使用上一阶段的输出数据在给定旋钮排序列表的情况下预测目标 DBMS 工作负载的度量值。然后算法使用目标工作负载和当前最相似工作负载的数据构建一个GPR 模型。将给定的旋钮数组(x)作为输入模型输出目标值(y)和不确定性值(u)的对(y, u)。算法计算 y 和 u 之和的置信上限(UCB)。然后在 UCB 上进行梯度上升以找到能导致良好目标值的旋钮配置。
因为高斯过程模型在较大的数据集和高维特征向量上表现不佳[2]所以论文修改了 OtterTune 最初的基于 GPR 的算法使用深度神经网络(DNN)代替高斯模型。二者遵循相同的 ML 管道都是先进行数据预处理然后进行旋钮推荐。
DNN 依赖于对输入应用线性组合和非线性激活的深度学习算法模型的网络结构有两个隐含层每层有 64 个神经元。所有各层均以整流线性单元(ReLU)作为激活函数完全连接。模型实现了一种称为 dropout 正则化的流行技术以避免模型过拟合并提高其泛化。DNN 还在旋钮推荐步骤期间将高斯噪声添加到神经网络的参数中以控制探索和利用。

图 3 DDPG调优管道
DDPG 方法首先由 CDBTune[3]提出,它是在连续动作空间环境中搜索最优策略的一种深度强化学习算法。DDPG 由三个组件组成(1)actor (2)critic 和(3)replay memory。actor 根据给定的状态选择一个动作(例如对一个 knob 使用什么值)。critic 根据状态对选定的动作即旋钮值进行评估并且提供反馈来指导 actor。actor 的输入是 DBMS 的度量输出推荐的旋钮值。critic 将之前的度量和推荐的旋钮作为输入输出一个 Q 值DDPG 神经网络的 Q 值计算的是对未来所有预期奖励的叠加。replay memory 存储按预测误差降序排列的训练数据。
对于每个旋钮 k, DDPG 构造一个元组其中包含 (1) 先前的度量 m_pre(2) 当前的度量 m以及(3)当前的奖励值 r。在接收到一个新的数据时CDBTune 首先通过比较当前、之前的和初始目标值来计算奖励。训练时从 memory 中获取一个小批量排名靠前的 tuple并通过反向传播更新 actor 和 critic 的权重。最后CDBTune 将当前度量 m 输入 actor 以获得下一旋钮 k_next 的推荐。
论文对 CDBTune 的 DDPG 算法进行了一些优化以提高 DDPG 的收敛速度新方法被叫做 DDPG++。首先DDPG++ 使用即时奖励而不是累积的未来奖励作为 Q 值。第二点DDPG++ 使用了一个更简单的奖励函数不考虑之前的或基础目标值。第三点DDPG++ 在得到一个新的结果时从 replay memory 中获取多个小批量以训练网络更快地收敛。
三实验结果
第一个实验评估了由 DBA 选出旋钮后再由 ML 调优算法在增加调优的旋钮数量时生成的配置的质量。图 4 显示了算法生成的优化配置在三个 vm 上的平均性能改进。每个条的暗和亮部分分别代表每个算法的最小和最大性能。
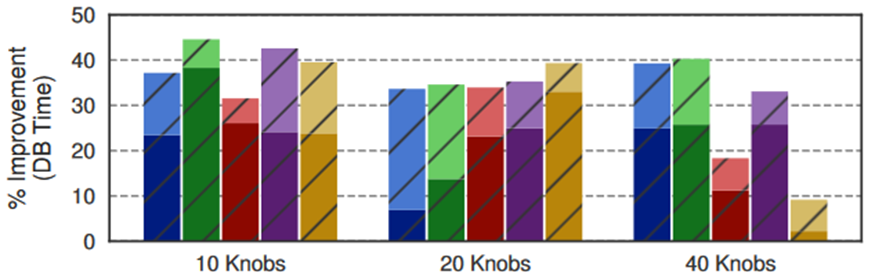
图4 DBA选出的调优旋钮
为了理解为什么配置执行起来效果不同作者手动检查了每个旋钮配置并确定了三个最重要的 Oracle 旋钮当算法没有正确设置它们时会对 DB Time 产生最大的影响。其中前两个参数控制 DBMS 的主缓冲区缓存的大小第三个旋钮启用基于 Oracle 版本的优化器特性。
作者发现GPR 在四个算法中总是快速收敛但是 GPR 很容易陷入局部极小值。DNN 的性能是整体最好的而 DDPG 和 DDPG++需要更多的迭代次数才能达到好的优化性能。
第二个实验是将人工完全排除在调优过程中。首先为了生成旋钮列表排序使用Lasso 算法根据旋钮对目标函数的估计影响程度对其进行排序并将排序列表分为 10knobs 和 20knobs以供 ML 算法进行调优。图 5 显示了 10 和 20 个knobs 配置的平均性能改进。
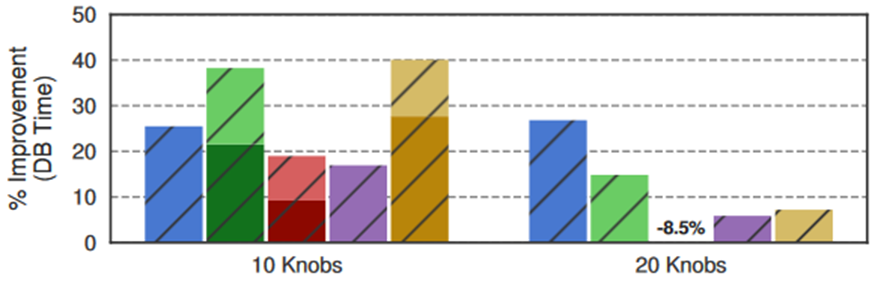
图5 OtterTune选出的调优旋钮
论文中认为20knobs 配置的 DBMS 整体性能较差部分原因是在 2020 年 8 月初作者进行这些实验时私有云存储上存在更多的共享噪声论文中对性能测量的可变性支持了这一解释。
第三个实验作者先在一个工作负载上训练 ML 生成的模型然后使用模型去调优另一个工作负载的 DBMS分析另一工作负载上由 ML 生成的配置的质量。首先使用 OLTP-Bench 执行的 TPC-C 工作负载为每个算法训练模型。然后使用 TPC-C 训练的模型对 TicketTracker 工作负载上的 DBMS 进行迭代调优。图 6 是算法在每个虚拟机上对 SG 默认配置的性能改进。
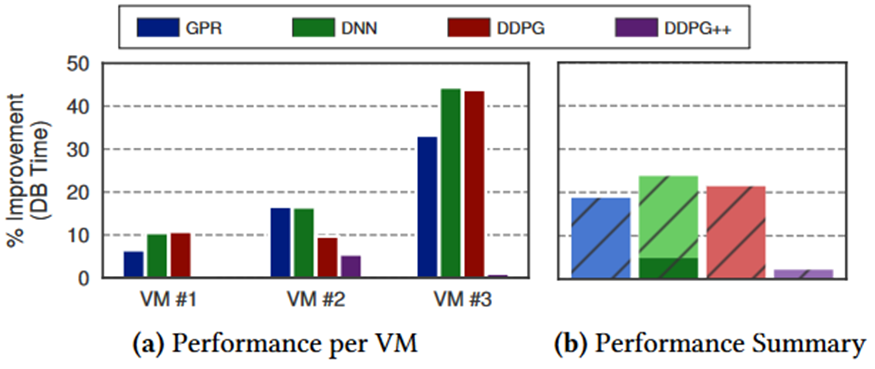
图6 对不同工作负载的适应性
CGPTuner: a Contextual Gaussian Process Bandit Approach for the Automatic Tuning of IT Configurations Under Varying Workload Conditions[4]
一背景知识
这篇论文做的主要工作跟上一篇有些类似都是为了找到 DBMS 中能够提升系统性能的配置不同的是这篇论文首先认为 DBMS 处于整个 IT 栈的最顶端下面的 JVM、操作系统的配置调优也都会影响 DBMS 的性能第二点DBMS 的性能还跟它所处的工作负载有关即这篇论文分析的是实时的、在线的自动调优论文的第三个亮点是它认为目前软件版本更新的比较快而且版本更新会修改其可用的参数那么从以前的知识库中重用信息就让调优的问题变得比较复杂因此它提出的方法是不需要利用以前的知识库的。
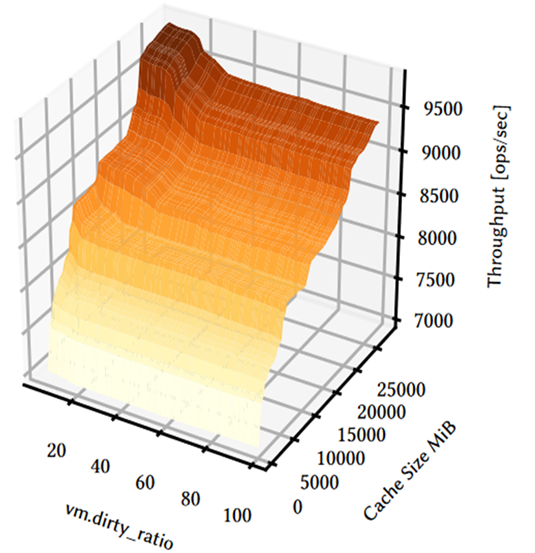
图7 改变MongoDB缓存大小和虚拟机dirty_ratio Linux参数对DBMS性能的影响
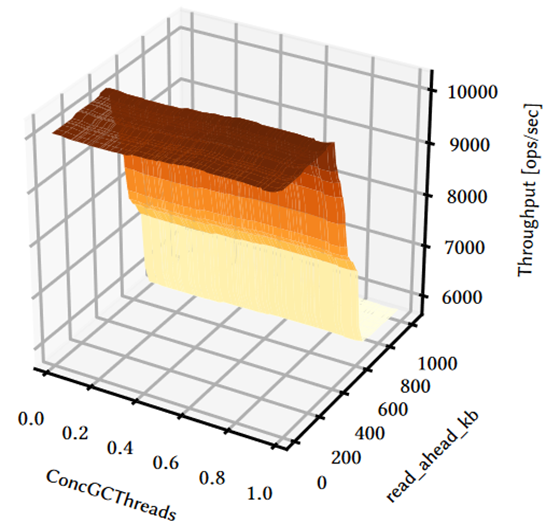
图8 改变JVM并发垃圾收集器的线程和Linux内核的read_ahead_kb参数对Cassandra性能的影响
从图 7 和图 8 中可以看到DBMS、JVM 和 OS 的配置都会影响 DBMS 的性能。
二所提模型
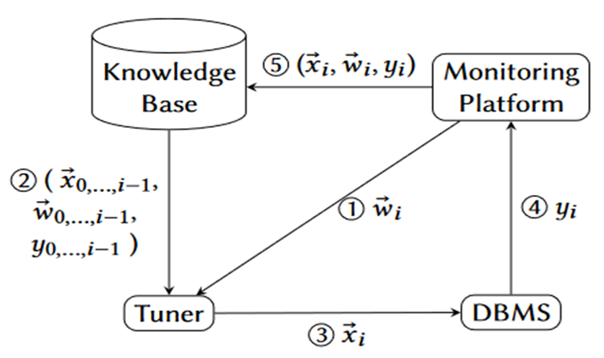
图 9 调优过程和架构
论文所提模型的优化目标就是在给定的工作负载 w 下找到一个配置向量 x将其应用在 IT 栈上面来优化系统的性能指标 y。需要注意的是调优器能够利用先前所有迭代的 x,w 和 y但是不需要其他额外的知识这点是跟比如 OtterTune 这些需要利用其他知识的自动调优不同的地方。
概率模型贝叶斯优化
替代模型 高斯过程
采集函数 GP-Hedge。GP-Hedge 采用了多种获取函数的组合即EI(预期的改进)、PI(改进概率)、LCB(低置信区间等。
之所以叫基于上下文的高斯过程优化是因为作者认为某些工作负载下的优化是相关的比如工作负载 w 下得到的数据可能为另一工作负载 w’ 提供一些有用的信息。基于此作者为高斯过程定义了新的正定核和新的协方差函数作者认为如果两个x,w组成的点是相似的只要它们的x是相似的或者 w 是相似。但是在优化的时候作者只优化了配置空间这一子空间在每次优化的时候是固定了另一维度进行探索和利用。采用基于上下文的高斯过程优化的好处是在迭代过程中所有工作负载的信息是共享的。
论文是用 MongoDB 和 Cassandra DBMS 来评估 CGPTuner用了 YCSB 来模拟了三种不同的工作负载模式。实验时的优化目标是在不增加响应时间的前提下最小化内存消耗来提升部署的效益。作者手动选出了调优的参数 包含 IT 栈不同的组件DBMS、JVM 和 OS的参数。为了验证调优器对于工作负载变化的适应能力论文中设计了两种工作负载模式分别是对三种不同读写比例工作负载在一天中也就是 1 次重复中持续不同的迭代次数。运行的线程数也是变化的以此来模拟一天中不同的工作负载密度。
三实验结果
在实验时作者通过两种方式来比较不同调优器的度量一种是以在线的也就是让调优器直接在生产系统上运行另一种是离线的在测试环境上复制生产系统。
作者用了两个指标来衡量这两种方式下的调优器的质量分别是在线调优的累计奖励 Calculative RewardCR和离线调优的迭代最佳值 Iterative BestIB。如果保持跟默认配置相同的配置CR 将始终是 0如果找到的配置比默认配置还差将会导致负的 CR。也就是说CR 反映了调优器理解问题和适应工作负载变化的能力。IB 值记录了当前迭代下记录的最高的标准性能改进它反映了调优器快速探索并且找到良好配置的能力。
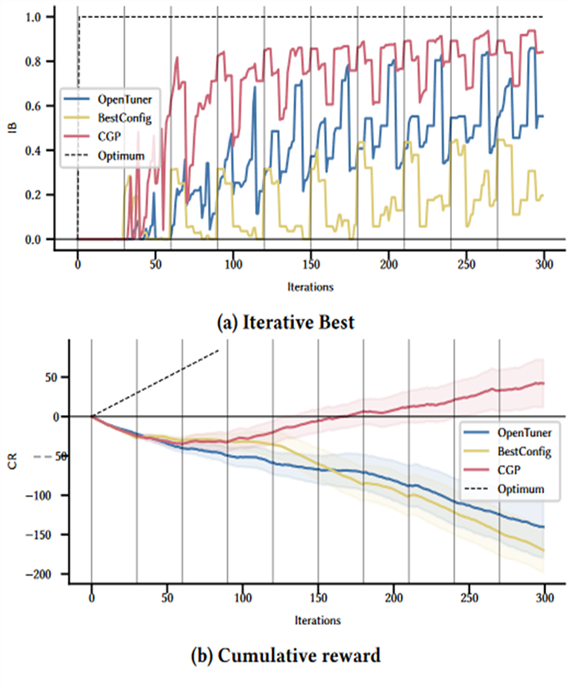
图10 在Cassandra DBMS上运行单峰workload模式
图 10 是加载单峰的工作负载的结果从 IB 值得变化可以看到 CGP 相较于另外两种在线调优算法能更快找到良好的配置并且找到的配置质量高于另外两种算法从 CR 值的变化情况可以看到OpenTuner 和 BestConfig 的累计奖励值在持续地负向增加也就是说这两种算法找的配置始终比默认的设置更差而 CGPTuner 在第 3 天开始 CR 值开始正向增加并且在第六天累计奖励的值开始为正值并不断增加在另一种工作负载模式上的结果类似。
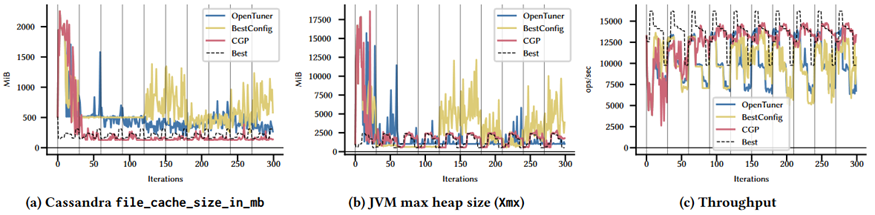
图 11 Cassandra 单峰调优的非标准化内存和吞吐量
除了从优化的角度比较了各种算法外作者还从吞吐量和内存消耗的角度来比较了三种算法。图 11 中的点是 Cassandra DBMS 在单峰工作负载模式上每个调优器获得的中值。可以看到在调优的第二天CGP 已经基本上收敛它为 Cassandra 缓存设置了一个较低的值并根据传入的工作负载改变了 JVM 堆的大小而且这两个参数都非常接近于最佳配置。而 OpenTuner 和 BestConfig 都没有达到收敛始终为这两个内存参数寻找更高的值。至于吞吐量方面CGP 在大多数工作负载上都能获得更好的结果。
综上基于上下文的调优器能实现更高吞吐量的同时分配更少的内存同时能根据到来的工作负载变化 JVM 堆的尺寸。
The Case for NLP-Enhanced Database Tuning: Towards Tuning Tools that “Read the Manual”[5]
一背景知识
本篇论文认为从文本文档中挖掘提示可以为现在的自动调优方法如主动学习、DRL 等加速收敛以及减少训练所需的数据量作为这些方法的补充。数据库调优知识是以自然语言文本的形式提供的。例如数据库管理员在最大限度地提高不熟悉的系统的性能时都会首先查阅数据库系统手册。除了手册之外在网络上的博客、在线论坛或科学论文中还发布了无数的调优提示。相关知识不仅隐藏在文本文档中。甚至配置文件中调优参数的名称以及相关的注释可能也提供了一些直观的语义和值得尝试的值。
二所提模型
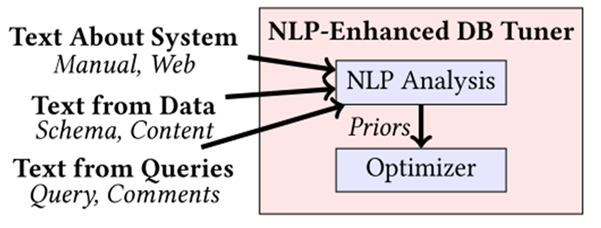
图12 NLP增强的数据库调优器
图 12 显示了 NLP 增强型数据库调优工具的模板系统、数据和查询相关的文本用于形成优化的先验。首先从系统手册、网上博客、论坛、关联的注释以及科学论文里抽取出相关知识作为先验文本。然后论文所提的原型系统可以从输入的先验文本中挖掘数据库系统的调优提示。
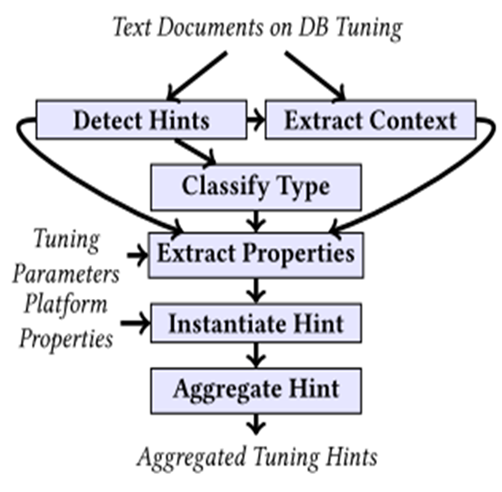
图13 论文所提原型概述
管道的第一阶段首先用基于 Robert-a 语言预处理模型提取出含有建议特定参数的值或者范围的关键语句以及上下文。
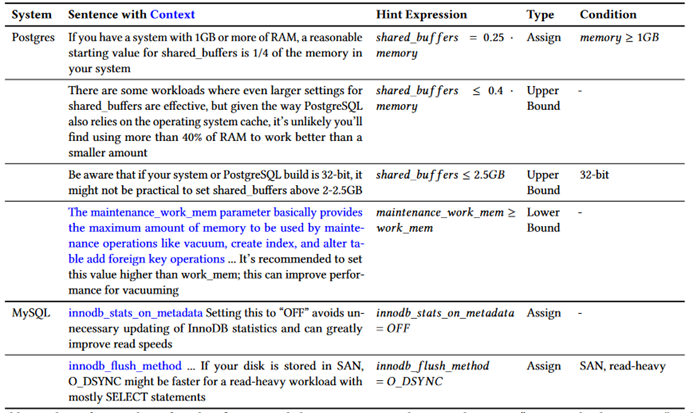
图14 通过谷歌查询“Postgres数据库调优”和MySQL数据库调优
得到的前十个调优提示网页文档的子集
以 Postgres 和 MySQL 的手册为例可以提取出这些关键语句和上下文。例如第一条语句满足条件 RAM 的内存大于 1GB 时可以将其转换为等式 shared_buffers = ¼ memory。
接下来使用 Robert-a 的分类器根据关键语句的类型对其进行分类这里假设的是每个提示都可以被转换成一个涉及所引用参数的等式。语句按类型分为建议参数为特定值的提示、定义下限、上限或推荐值集合的提示。然后根据分类后的关键语句提取参数名称和提示的值。最后对不同文档提取出的提示进行汇总为了减少噪声和剔除相矛盾的属性论文最终用到的提示是过滤后的至少在独立的文档中出现两次的调优提示。
这篇论文相比前两篇配置调优的论文有一些缺点就是所提原型的文本分析不支持不同工作负载下的调优另外仅支持提取特定的参数值以及主内存的百分比对于参数值范围的提取不适用。
三实验结果
为了使任务更具挑战性论文使用提示为一个数据库系统训练两个分类器用来自一个分类器的文档训练分类器并处理为另一个系统检索的所有文档即在以另一个系统为目标的文档上测试用第一个系统的数据训练的分类器。
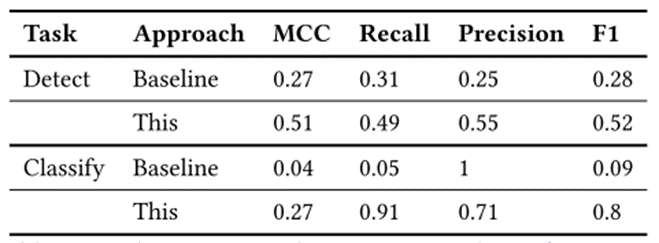
图15 Postgres训练产生提示后处理MySQL提示时的质量度量
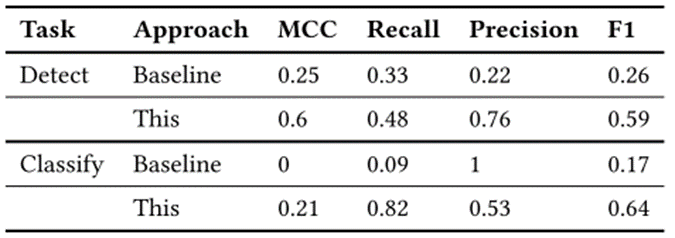
图16 MySQL训练产生提示后处理Postgres提示时的质量度量
综上该论文建议使用文本文档和片段作为数据库调优中的一个额外的信息源提出并评估了一个 NLP 增强型数据库调优器的简单原型来利用这些信息作为补充或证实其他信息源并演示了与默认配置相比自动解析来自Web的信息可以产生显著的加速。
本文通过三篇数据库调优相关论文对其各自工作进行概述希望能在带给读者相关概念的同时启发创新灵感。由于篇幅所限本文并未列出所有数据库调优相关论文而只是以近年论文为起点给出些大致的研究方向感兴趣的读者还需要在此基础上继续探索。
*参考文献
[1] An Inquiry into Machine Learning-based Automatic Configuration Tuning Services on Real-World Database Management Systems. PVLDB, 2021.
[2] Black or White? How to Develop an AutoTuner for Memory-based Analytics. SIGMOD, 2020.
[3] An End-to-End Automatic Cloud Database Tuning System Using Deep Reinforcement Learning. ICMD, 2019.[4] CGPTuner: a Contextual Gaussian Process Bandit Approach for the Automatic Tuning of IT Configurations Under Varying Workload Conditions. PVLDB, 2021.
[5] The Case for NLP-Enhanced Database Tuning: Towards Tuning Tools that “Read the Manual”. PVLDB, 2021.