

Transformer在医学影像中的应用综述-分类
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
文章目录
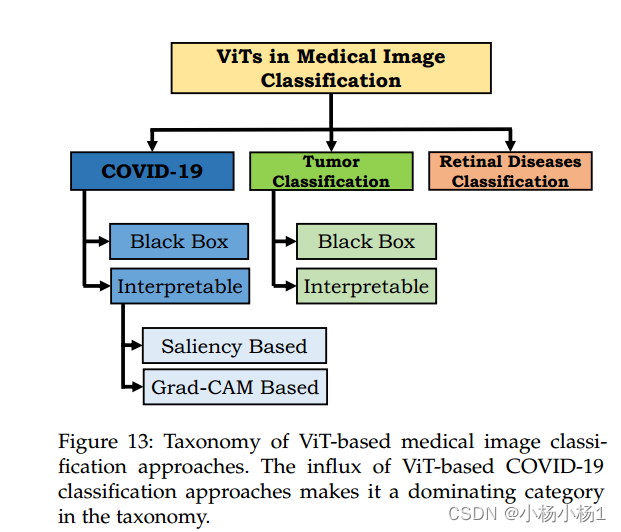
总体结构
COVID-19 Diagnosis
黑盒模型
- Point-of-Care Transformer(POCFormer)利用Linformer将自注意的空间和时间复杂度从二次型降低到线性型。POCFormer有200万个参数约为MobileNetv2的一半因此适合于实时诊断。
- Vision Outlooker (VOLO)新注意机制将精细级特征编码为ViT token 表征从而提高分类性能。
- Swin Transformer和Transformer-in-Transformer将COVID-19图像从肺炎图像和正常图像中分类。
- FESTA利用了联邦和分裂学习的优点利用ViT同时处理多个胸部x射线任务
- 变压器和cnn组成的混合网络
- 基于Swin Transformer的两阶段框架基于UNet的肺分割模型然后使用Swin Transformer主干进行图像分类
可解释的模型
基于显著性的可视化和基于梯度的方法
肿瘤分类
黑盒模型
TransMed第一个利用ViTs进行医学图像分类的工作。它是一种基于CNN和变压器的混合架构能够对多模态MRI医学图像中的腮腺肿瘤进行分类
Gene-Transformer:预测肺癌亚型
多尺度GasHis-Transformer来诊断胃癌
对称交叉熵损失函数诊断急性淋巴细胞白血病的混合模型
可解释模型
基于全切片成像(WSI)的病理诊断中一个标签分配给一组实例(袋)。
如果至少有一个实例是正的则标记为正的;如果袋子中的所有实例都是负的则标记为负的
TransMIL利用两个基于Transformer的模块和一个位置编码层聚合形态信息为了对空间信息进行编码提出了一种金字塔位置编码发生器注意力得分已被可视化以证明可解释性
图形转换网络(GTN)来利用基于图的WSI表示。GTN由图卷积层、变压器层和池化层组成。GTN进一步使用GraphCAM来识别与类标签高度相关的区域。
视网膜疾病分类
MIL-ViT模型该模型首先在大型眼底图像数据集上进行预训练然后在视网膜疾病分类的下游任务上进行微调。
MIL-ViT架构使用基于mil的磁头可以与ViT一起以即插即用的方式使用。
病变感知变压器(LAT)该变压器由基于像素关系的编码器和病变感知变压器解码器组成
卷积层和Transformer层组成的混合架构
小结
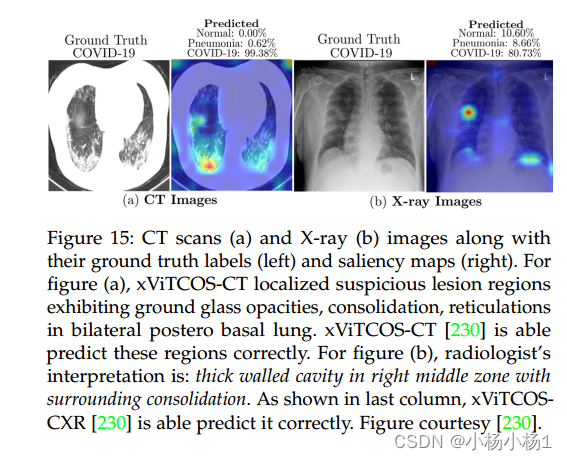
必须更多地关注为COVID-19诊断设计可解释(以获得最终用户信任)和高效(用于即时检测)的ViT模型使其成为未来RTPCR检测的可行替代方案。
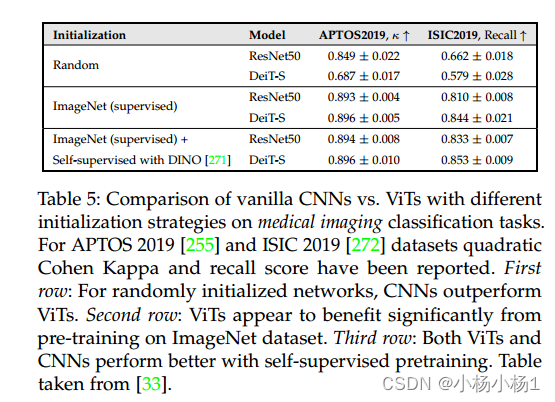
强调一下一个令人兴奋的工作他们首次证明了在ImageNet上预训练的ViTs在医学图像分类任务中的表现与cnn相当如表5所示。这也提出了一个有趣的问题:“在医学成像数据集上预训练的ViT模型在医学图像分类方面是否比在ImageNet上预训练的ViT模型表现得更好?”最近的一项工作试图通过在大规模2D和3D医学图像上预训练ViT来回答这个问题。在医学图像分类问题上他们的模型比在ImageNet上预训练的ViT模型获得了实质性的性能提升这表明该领域值得进一步探索。
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |