

机器学习(16)---聚类(KMeans)
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
聚类
一、聚类概述
1.1 无监督学习与聚类算法
1. 有监督学习是说模型在训练的时候既需要特征矩阵X也需要真实标签y。无监督学习是说在训练的时候只需要特征矩阵X不需要标签。
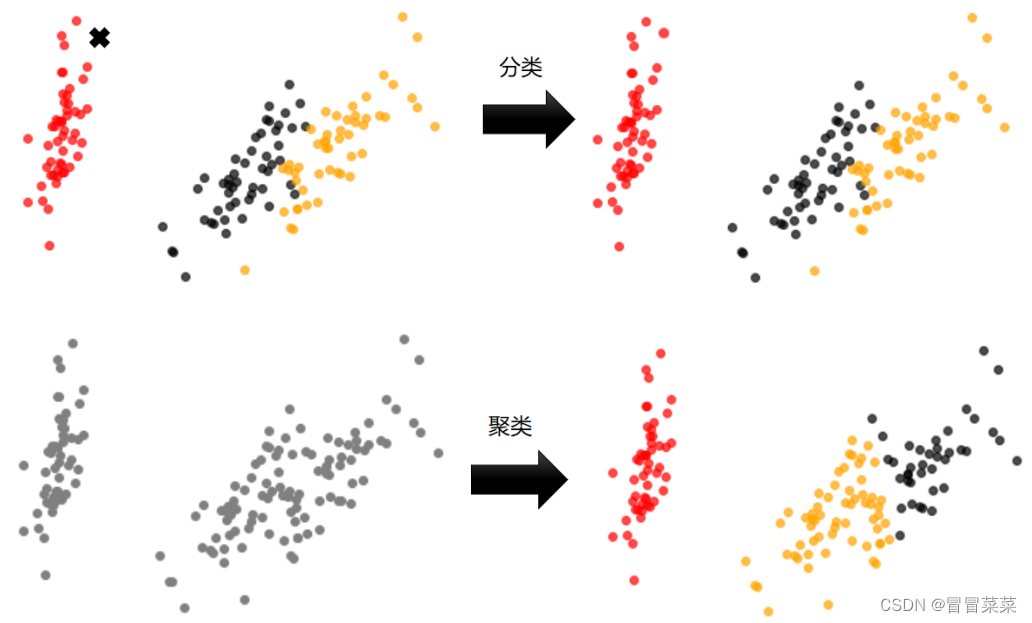
2. 聚类算法又叫做“无监督分类”其目的是将数据划分成有意义或有用的组或簇。聚类和分类的直观上比较可参考下图
3. 聚类和分类对比表格
| 聚类 | 分类 | |
|---|---|---|
| 核心 | 将数据分成多个组探索每个组的数据是否有联系 | 从已经分组的数据中去学习把新数据放到已经分好的组中去 |
| 学习类型 | 无监督无需标签进行训练 | 有监督需要标签进行训练 |
| 典型算法 | K-MeansDBSCAN层次聚类光谱聚类 | 决策树贝叶斯逻辑回归 |
| 算法输出 | 聚类结果是不确定的不一定总是能够反映数据的真实分类同样的聚类根据不同的业务需求可能是一个好结果也可能是一个坏结果 | 分类结果是确定的分类的优劣是客观的不是根据业务或算法需求决定 |
1.2 sklearn中的聚类算法
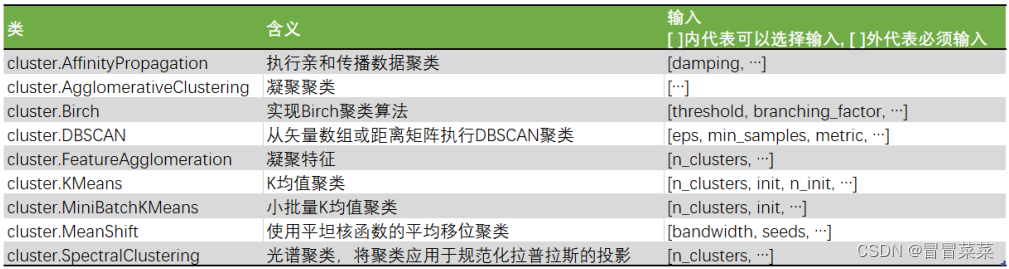
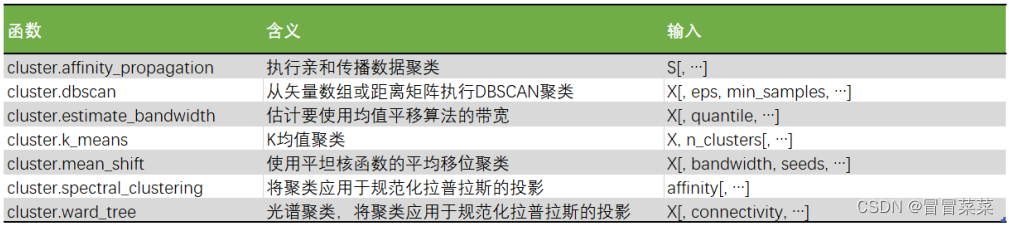
聚类算法在sklearn中有两种表现形式一种是类和我们目前为止学过的分类算法以及数据预处理方法们都一样需要实例化训练并使用接口和属性来调用结果。另一种是函数function只需要输入特征矩阵和超参数即可返回聚类的结果和各种指标。
二、 KMeans
2.1 基本原理
1. 簇KMeans算法将一组N个样本的特征矩阵X划分为K个无交集的簇直观上来看是簇是一组一组聚集在一起的数据在一个簇中的数据就认为是同一类。簇就是聚类的结果表现。
2. 质心簇中所有数据的均值 通常被称为这个簇的“质心”centroids。在一个二维平面中一簇数据点的质心的横坐标就是这一簇数据点的横坐标的均值质心的纵坐标就是这一簇数据点的纵坐标的均值。同理可推广至高维空间。
3. 在KMeans算法中簇的个数K是一个超参数需要我们人为输入来确定。KMeans的核心任务就是根据我们设定好的K找出K个最优的质心并将离这些质心最近的数据分别分配到这些质心代表的簇中去。具体过程可以总结如下
| 顺序 | 过程 |
|---|---|
| 1 | 随机抽取K个样本作为最初的质心 |
| 2 | 开始循环 |
| 2.1 | 将每个样本点分配到离他们最近的质心生成K个簇 |
| 2.2 | 对于每个簇计算所有被分到该簇的样本点的平均值作为新的质心 |
| 3 | 当质心的位置不再发生变化迭代停止聚类完成 |
注那什么情况下质心的位置会不再变化呢当我们找到一个质心在每次迭代中被分配到这个质心上的样本都是一致的即每次新生成的簇都是一致的所有的样本点都不会再从一个簇转移到另一个簇质心就不会变化了。
4. 这个过程在可以由下图来显示我们规定将数据分为4簇K=4其中白色X代表质心的位置

2.2 簇内误差平方和
1. 我们认为被分在同一个簇中的数据是有相似性的而不同簇中的数据是不同的。我们追求“簇内差异小簇外差异大”。而这个“差异“由样本点到其所在簇的质心的距离来衡量。
2. 对于一个簇来说所有样本点到质心的距离之和越小我们就认为这个簇中的样本越相似簇内差异就越小。而距离的衡量方法有多种令 表示簇中的一个样本点 表示该簇中的质心n表示每个样本点中的特征数目i表示组成点 的每个特征则该样本点到质心的距离可以由以下距离来度量

3. 如果我们采用欧几里得距离则一个簇中所有样本点到质心的距离的平方和为

注其中m为一个簇中样本的个数j是每个样本的编号。这个公式被称为簇内平方和cluster Sum of Square又叫做Inertia。而将一个数据集中的所有簇的簇内平方和相加就得到了整体平方和Total Cluster Sum ofSquare又叫做total inertia。Total Inertia越小代表着每个簇内样本越相似聚类的效果就越好。因此KMeans追求的是求解能够让Inertia最小化的质心。
三、sklearn中的KMeans
3.1 所用模块
1. 模块class sklearn.cluster.KMeans(n_clusters=8, init=’k-means++’, n_init=10, max_iter=300, tol=0.0001, precompute_distances=’auto’, verbose=0, random_state=None, copy_x=True, n_jobs=None, algorithm=’auto’)。
2. n_clusters是KMeans中的k表示着我们告诉模型我们要分几类。这是KMeans当中唯一一个必填的参数默认为8类但通常我们的聚类结果会是一个小于8的结果。通常在开始聚类之前我们并不知道n_clusters究竟是多少因此我们要对它进行探索。
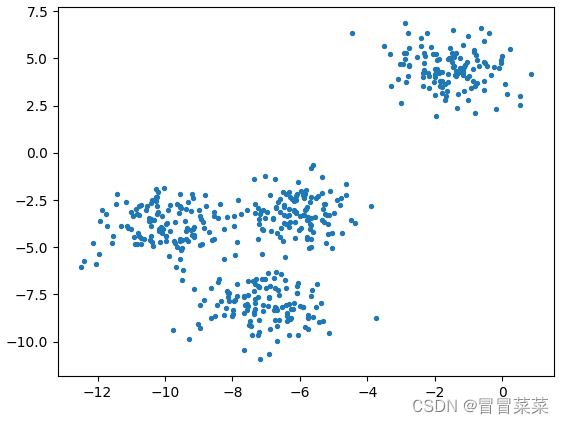
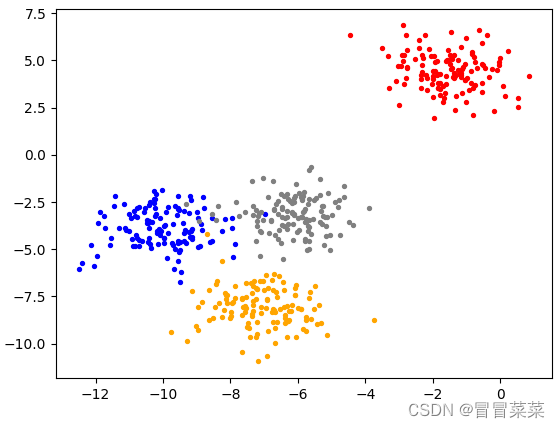
3. 进行一次简单的聚类
from sklearn.datasets import make_blobs
import matplotlib.pyplot as plt
#自己创建数据集
X, y = make_blobs(n_samples=500,n_features=2,centers=4,random_state=1)
fig, ax1 = plt.subplots(1)
ax1.scatter(X[:, 0], X[:, 1]
,marker='o' #点的形状
,s=8 #点的大小
)
plt.show()
color = ["red","blue","orange","gray"]
fig, ax1 = plt.subplots(1)
for i in range(4):
ax1.scatter(X[y==i, 0], X[y==i, 1]
,marker='o' #点的形状
,s=8 #点的大小
,c=color[i]
)
plt.show()
3.2 聚类算法的模型评估指标
1. 聚类模型的结果不是某种标签输出并且聚类的结果是不确定的其优劣由业务需求或者算法需求来决定并且没有永远的正确答案。
2. Inertia是用距离来衡量簇内差异的指标但是使用Inertia来作为聚类的衡量指标的缺点和极限太大。
- 它不是有界的。
- 它的计算太容易受到特征数目的影响。
- 它会受到超参数K的影响在我们之前的常识中其实我们已经发现随着K越大Inertia注定会越来越小但这并不代表模型的效果越来越好了。
- Inertia对数据的分布有假设它假设数据满足凸分布即数据在二维平面图像上看起来是一个凸函数的样子并且它假设数据是各向同性的isotropic会让聚类算法在一些细长簇环形簇或者不规则形状的流形时表现不佳。
3.3 轮廓系数
1. 对没有真实标签的数据进行探索也就是对不知道真正答案的数据进行聚类。这样的聚类是完全依赖于评价簇内的稠密程度簇内差异小和簇间的离散程度簇外差异大来评估聚类的效果。
2. 轮廓系数定义1样本与其自身所在的簇中的其他样本的相似度a等于样本与同一簇中所有其他点之间的平均距离 。 2样本与其他簇中的样本的相似度b等于样本与下一个最近的簇中的所有点之间的平均距离。 注根据聚类的要求”簇内差异小簇外差异大“我们希望b永远大于a并且大得越多越好。
3.1单个样本的轮廓系数计算为
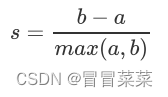
2这个公式可以被解析为

3很容易理解轮廓系数范围是(-1,1)其中值越接近1表示样本与自己所在的簇中的样本很相似并且与其他簇中的样本不相似当样本点与簇外的样本更相似的时候轮廓系数就为负。当轮廓系数为0时则代表两个簇中的样本相似度一致两个簇本应该是一个簇。可以总结为轮廓系数越接近于1越好负数则表示聚类效果非常差。
4. 在sklearn中我们使用模块metrics中的类silhouette_score来计算轮廓系数它返回的是一个数据集中所有样本的轮廓系数的均值。但我们还有同在metrics模块中的silhouette_sample它的参数与轮廓系数一致但返回的是数据集中每个样本自己的轮廓系数。
from sklearn.datasets import make_blobs
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score
from sklearn.metrics import silhouette_samples
X, y = make_blobs(n_samples=500,n_features=2,centers=4,random_state=1) #返回特征矩阵和标签
n_clusters = 4
cluster = KMeans(n_clusters=n_clusters, random_state=0).fit(X)
y_pred = cluster.labels_
print(silhouette_score(X,y_pred))
print(silhouette_samples(X,y_pred))
3.4 CHI(卡林斯基-哈拉巴斯指数)
1. 对于有k个簇的聚类而言Calinski-Harabaz指数s(k)写作如下公式
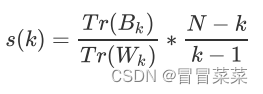
其中N为数据集中的样本量k为簇的个数即类别的个数Bk是组间离散矩阵即不同簇之间的协方差矩阵Wk是簇内离散矩阵即一个簇内数据的协方差矩阵而tr表示矩阵的迹。在线性代数中一个n×n矩阵A的主对角线从左上方至右下方的对角线上各个元素的总和被称为矩阵A的迹或迹数一般记作tr(A)。数据之间的离散程度越高协方差矩阵的迹就会越大。组内离散程度低协方差的迹就会越小Tr(Wk)也就越小同时组间离散程度大协方差的的迹也会越大Tr(Bk)就越大这正是我们希望的因此Calinski-harabaz指数越高越好。
2. 虽然calinski-Harabaz指数没有界在凸型的数据上的聚类也会表现虚高。但是比起轮廓系数它有一个巨大的优点就是计算非常快速。代码块
from sklearn.metrics import calinski_harabaz_score
calinski_harabaz_score(X, y_pred)
四、KMeans做矢量量化
4.1 概述
1. KMeans聚类的矢量量化本质是一种降维运用但它与我们之前学过的任何一种降维算法的思路都不相同。特征选择的降维是直接选取对模型贡献最大的特征PCA的降维是聚合信息而矢量量化的降维是在同等样本量上压缩信息的大小即不改变特征的数目也不改变样本的数目只改变在这些特征下的样本上的信息量。
2. 对于图像来说一张图片上的信息可以被聚类如下表示
这是一组40个样本的数据分别含有40组不同的信息(x1,x2)。我们将代表所有样本点聚成4类找出四个质心我们认为这些点和他们所属的质心非常相似因此他们所承载的信息就约等于他们所在的簇的质心所承载的信息。于是我们可以使用每个样本所在的簇的质心来覆盖原有的样本有点类似四舍五入的感觉类似于用1来代替0.9和0.8。这样40个样本带有的40种取值就被我们压缩了4组取值虽然样本量还是40个但是这40个样本所带的取值其实只有4个就是分出来的四个簇的质心。
4.2 案例
1. 查看原图
import matplotlib.pyplot as plt
from sklearn.datasets import load_sample_image
import pandas as pd
china = load_sample_image("china.jpg")
newimage = china.reshape((427 * 640,3))
print(pd.DataFrame(newimage).drop_duplicates().shape) #(96615, 3)
plt.figure(figsize=(15,15))
plt.imshow(china)
plt.show()

2. 矢量量化
n_clusters = 64
china = np.array(china, dtype=np.float64) / china.max()
w, h, d = original_shape = tuple(china.shape)
assert d == 3
image_array = np.reshape(china, (w * h, d))
#先用1000个数据找出质心
image_array_sample = shuffle(image_array, random_state=0)[:1000]
kmeans = KMeans(n_clusters=n_clusters, random_state=0).fit(image_array_sample)
#找出质心后按照已经存在的质心对所有数据进行聚类
labels = kmeans.predict(image_array)
image_kmeans = image_array.copy()
for i in range(w*h):
image_kmeans[i] = kmeans.cluster_centers_[labels[i]]
image_kmeans
pd.DataFrame(image_kmeans).drop_duplicates().shape
image_kmeans = image_kmeans.reshape(w,h,d)
image_kmeans.shape
centroid_random = shuffle(image_array, random_state=0)[:n_clusters]
labels_random = pairwise_distances_argmin(centroid_random,image_array,axis=0)
labels_random.shape
len(set(labels_random))
image_random = image_array.copy()
for i in range(w*h):
image_random[i] = centroid_random[labels_random[i]]
image_random = image_random.reshape(w,h,d)
image_random.shape
plt.figure(figsize=(10,10))
plt.axis('off')
plt.title('Original image (96,615 colors)')
plt.imshow(china)
plt.figure(figsize=(10,10))
plt.axis('off')
plt.title('Quantized image (64 colors, K-Means)')
plt.imshow(image_kmeans)
plt.figure(figsize=(10,10))
plt.axis('off')
plt.title('Quantized image (64 colors, Random)')
plt.imshow(image_random)
plt.show()
注使用聚类算法压缩图片后可以看出图片颜色不会有太大的误差。



| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |