

基于ChatGPT的视频智能摘要实战
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
随着在 YouTube 上提交的大量新视频很容易感到挑战并努力跟上我想看的一切。 我可以与我每天将视频添加到“稍后观看”列表中的经历联系起来只是为了让列表变得越来越长实际上并没有稍后再看。 现在像 ChatGPT 或 LLaMA 这样的大型语言模型为这个长期问题提供了一个潜在的解决方案。
推荐用NSDT设计器 快速搭建可编程3D场景。
通过将数小时的视频内容转换为几行准确的摘要文本视频摘要器可以快速为我们提供视频的要点这样我们就不必花费大量时间来完整观看它。 在我创建这个网络应用程序之后我最常使用的场景是参考它的摘要来决定某个视频是否值得观看尤其是那些辅导、脱口秀或演示视频。
你可以通过多种方式使用强大的语言模型来完成此视频摘要。
- 一种选择是使用或设计 ChatGPT 插件它可以将令人难以置信的 AI 连接到实时 YouTube 网站。 但是只有少数商业开发人员可以访问 ChatGPT 插件因此这对包括我在内的所有人来说可能不是最可行的途径。
- 另一种选择是下载视频的抄本字幕并将其附加到提示中然后要求语言模型通过发送提示来总结抄本文本。 然而这种方法有一个很大的缺点——你不能总结一个包含超过 4096 个标记的视频这对于一个普通的谈话节目来说通常是 7 分钟左右。
- 一个更有前途的选择是使用上下文学习技术对转录本进行向量化并使用向量向语言模型提示“摘要”查询。 这种方法可以生成准确的答案指示转录文本的摘要并且不限制视频长度。
如果你有兴趣开发自己的上下文学习应用程序我之前关于构建聊天机器人以学习和聊天文档的文章提供了一个很好的起点。 通过一些细微的修改我们可以应用相同的方法来创建我们自己的视频摘要器。 在本文中我将逐步指导你完成开发过程以便你了解并复制自己的视频摘要器。
1、功能框图
在这个Video Summarizer应用程序中我们以llama-index为基础开发了一个Streamlit web应用程序为用户提供视频URL的输入以及屏幕截图、文字记录和摘要内容的显示。 使用 llamaIndex 工具包我们不必担心 OpenAI 中的 API 调用因为对嵌入使用的复杂性或提示大小限制的担忧很容易被其内部数据结构和 LLM 任务管理所覆盖。
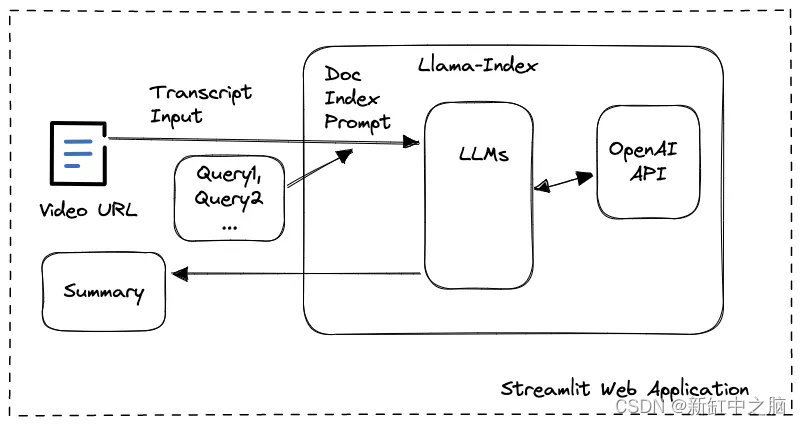
你有没有想过为什么我在让 LLM 生成摘要时设计了几个查询而不是一个用于转录文本处理的查询 答案在于情境学习过程。 当文档被送入 LLM 时它会根据其大小分成块或节点。 然后将这些块转换为嵌入并存储为向量。
当提示用户查询时模型将搜索向量存储以找到最相关的块并根据这些特定块生成答案。 例如如果你在大型文档如 20 分钟的视频转录本上查询“文章摘要”模型可能只会生成最后 5 分钟的摘要因为最后一块与上下文最相关 的“总结”。
为了说明这个概念请看下面的图表
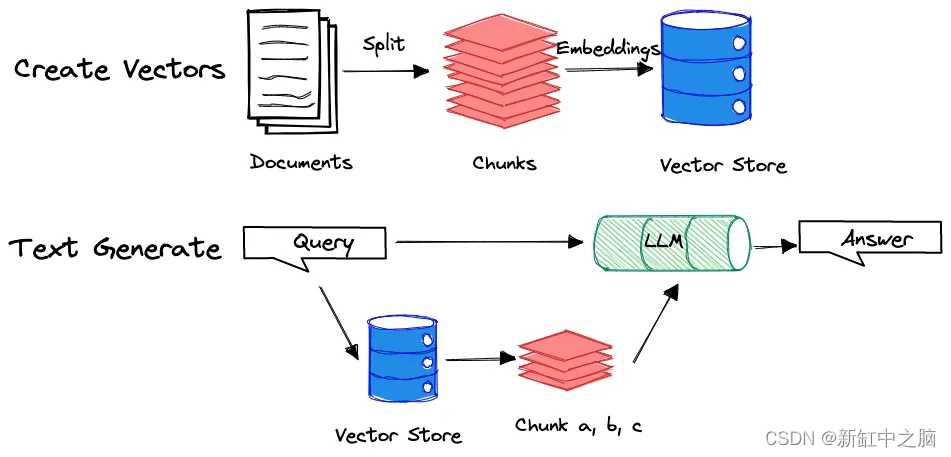
通过设计多个查询我们可以促使 LLM 生成更全面的摘要涵盖整个文档。 我将在本文后面更深入地组织多个查询。
从第2章到第5章我将重点介绍本项目中使用到的所有模块的基础知识和典型用法介绍。 如果你愿意在没有这些技术背景的情况下立即开始编写整个 Video Summarizer 应用程序建议你转到第 6 章。
2、Youtube 视频转录文本
总结 YouTube 视频的第一步是下载转录文本。 有一个名为 youtube-transcript-api 的开源 Python 库可以完美满足我们的要求。
使用如下命令安装模块后
!pip install youtube-transcript-api
可以使用以下代码轻松下载 JSON 格式的转录文本
from youtube_transcript_api import YouTubeTranscriptApi
from youtube_transcript_api.formatters import JSONFormatter
srt = YouTubeTranscriptApi.get_transcript("{video_id}", languages=['en'])
formatter = JSONFormatter()
json_formatted = formatter.format_transcript(srt)
print(json_formatted)
在 .get_transcript() 方法中唯一应该强制提供的参数是 11 位视频 ID你可以在 v= 之后的每个 YouTube 视频的 URL 中找到它例如
https://www.youtube.com/watch? v=hJP5GqnTrNo
当视频提供英语以外的其他语言时可以将它们添加到参数语言中该参数语言作为包含不同语言的列表。
该库还提供“Formatter”方法来生成具有定义格式的转录数据。 在这种情况下我们只需要 JSON 格式即可进行进一步的步骤。
通过运行上面的代码你会看到像这样的一个像样的转录文本
[
{"text": "So anyone who's been paying attention\nfor the last few months", "start": 4.543, "duration": 3.878},
{"text": "has been seeing headlines like this,", "start": 8.463, "duration": 2.086},
{"text": "especially in education.", "start": 10.59, "duration": 2.086},
{"text": "The thesis has been:", "start": 12.717, "duration": 1.919},
...
]
3、OpenAI API 密钥
LlamaIndex 的设计目的是兼容各种 LLM默认使用 OpenAI 的 GPT 模型进行嵌入和生成操作。 因此当我们决定实施基于 OpenAI GPT 模型的视频摘要器时我们应该向程序提供我们的 OpenAI API 密钥。
插入我们的密钥唯一需要做的就是通过环境变量提供它
import os
os.environ["OPENAI_API_KEY"] = '{your_api_key}'
4、LlamaIndex
LlamaIndex 是一个 Python 库充当用户私有数据和大型语言模型 (LLM) 之间的接口。 它有几个对开发人员有用的功能包括连接到各种数据源、处理提示限制、创建语言数据索引、将提示插入数据、将文本拆分为更小的块以及提供查询索引的接口的能力 . 借助 LlamaIndex开发人员无需实施数据转换即可将现有数据用于 LLM管理 LLM 与数据的交互方式并提高 LLM 的性能。
可以在此处查看完整的LlamaIndex文档。
以下是使用 LlamaIndex 的一般步骤
安装包
!pip install llama-index
Step1 — 加载文档文件
from llama_index import SimpleDirectoryReader
SimpleDirectoryReader = download_loader("SimpleDirectoryReader")
loader = SimpleDirectoryReader('./data', recursive=True, exclude_hidden=True)
documents = loader.load_data()
SimpleDirectoryReader 是 LlamaIndex 工具集中的文件加载器之一。 它支持在用户提供的文件夹下加载多个文件在本例中它是子文件夹“./data/”。 这个神奇的加载器功能可以支持解析各种文件类型如.pdf、.jpg、.png、.docx等让您不必自己将文件转换为文本。 在我们的应用程序中我们只加载一个文本文件 (.json) 来包含视频转录数据。
Step2 — 构建索引
from llama_index import LLMPredictor, GPTSimpleVectorIndex, PromptHelper, ServiceContext
from langchain import ChatOpenAI
# define LLM
llm_predictor = LLMPredictor(llm=ChatOpenAI(temperature=0, model_name="gpt-3.5-turbo", max_tokens=500))
service_context = ServiceContext.from_defaults(llm_predictor=llm_predictor)
index = GPTSimpleVectorIndex.from_documents(
documents, service_context=service_context
)
在调用此方法时LlamaIndex 应与你定义的 LLM 交互以构建索引在本演示的情况下LlamaIndex 使用 gpt-3.5 聊天模型通过 OpenAI API 调用嵌入方法。
Step3 — 查询索引
通过建立索引查询非常简单无需上下文数据直接输入即可。
response = index.query("Summerize the video transcript")
print(response)
5、Web开发
与我文章中之前的项目一样我们将继续使用方便的 Streamlit 工具集来构建 Video Summarizer 应用程序。

Streamlit 是一个开源的 Python 库有助于创建交互式 Web 应用程序。 它的主要目的是供数据科学家和机器学习工程师用来与他人分享他们的工作。 借助 Streamlit开发人员可以使用最少的代码创建应用程序并且可以使用单个命令轻松地将它们部署到 Web。
它提供了多种可用于创建交互式应用程序的小部件。 这些小部件包括按钮、文本框、滑块和图表。 可以从其官方文档中找到所有小部件的用法。
Web 应用程序的典型 Streamlit 代码可以像下面这样简单
!pip install streamlit
import streamlit as st
st.write("""
# My First App
Hello *world!*
""")
然后只需键入以下命令即可在线运行该网站
!python -m streamlit run demo.py
如果运行成功会打印出用户可以访问的URL
You can now view your Streamlit app in your browser.
Network URL: http://xxx.xxx.xxx.xxx:8501
External URL: http://xxx.xxx.xxx.xxx:8501
6、完整的 Video Summarizer 应用程序
要实现总结 YouTube 视频的整个工作流程用户体验非常简单。
第 1 步 — 用户输入 YouTube 视频的 URL。
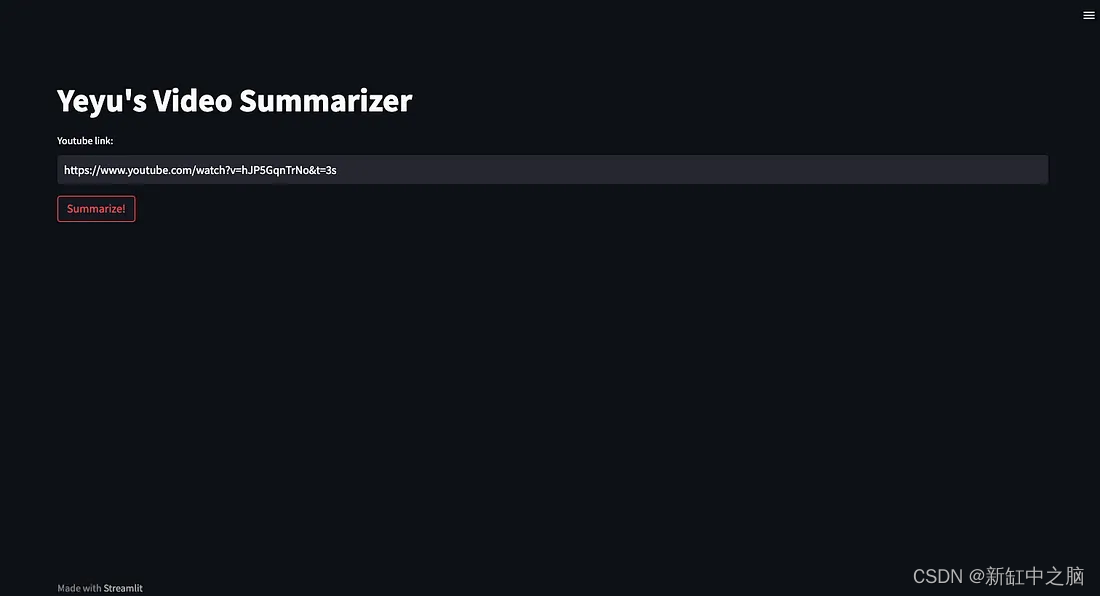
在这一步中我们通过 Streamlit st.text_input() 方法创建一个 text_input 小部件以接收用户输入的视频 URL。
第 2 步 — 应用程序下载视频的屏幕截图和文字记录文件并将它们显示在侧边栏中。
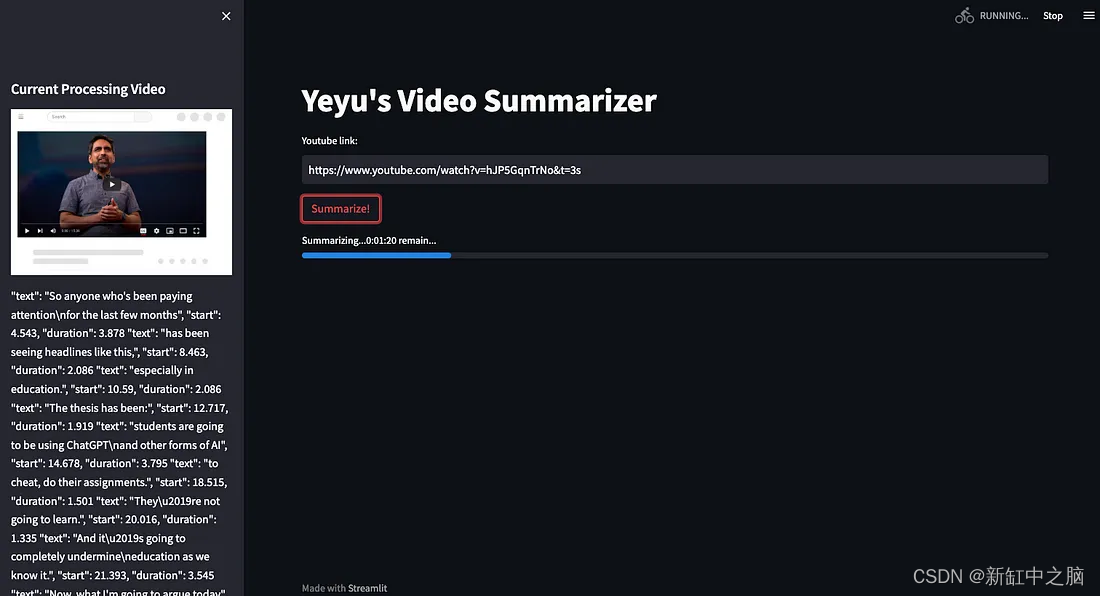
在这一步中在成功从 URL 解析视频 ID 后我们使用 html2image 库创建一个侧边栏区域来显示屏幕截图另存为 ./youtube.png并显示转录文本另存为 ./data/transcript。 json 通过使用 LlamaIndex 的 SimpleDirectoryReader() 方法。 我们还从 Streamlit 小部件中实现了一个进度条以指示剩余时间因为当视频需要很长时间时摘要过程会花费更多时间。
第 3 步 — 应用程序生成整个视频的摘要每 5 分钟的视频有一个详细描述
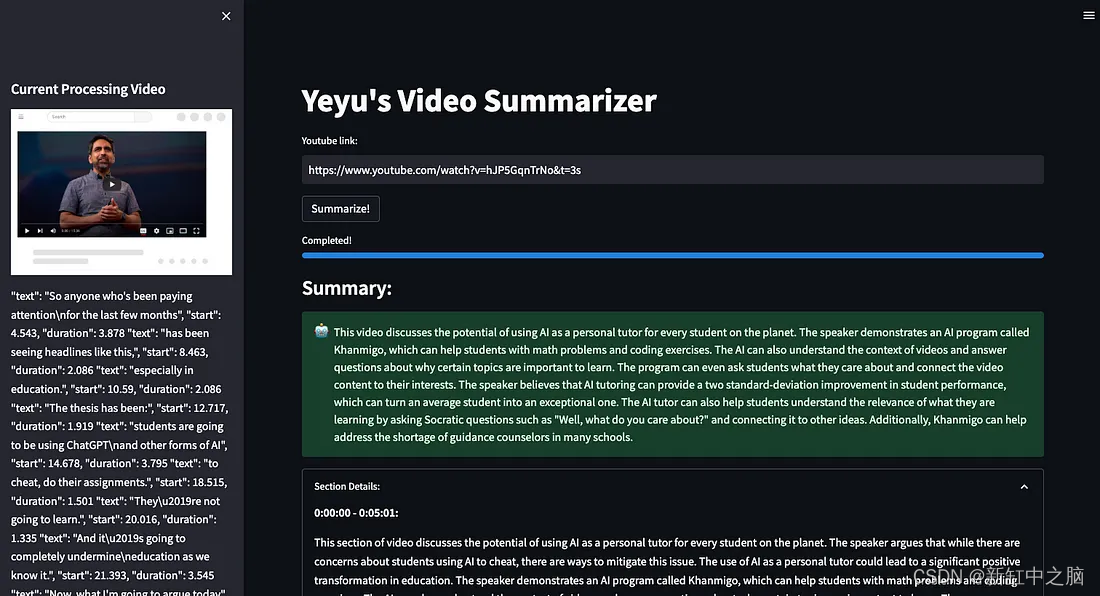
在此步骤中如前所述我们不希望语言模型通过仅搜索摘要作业的相关块来遗漏整个视频中的重要信息。 为避免这种情况我们创建了一个循环每 5 分钟查询一次摘要视频部分。 这确保带有向量的提示的标记不超过 4096 个标记的最大限制防止拆分成块。 需要注意的是5 分钟间隔只是一个粗略的估计。 我们创建一个 st.expander() 小部件来包含 5 分钟部分的摘要并创建一个 st.success() 小部件来通过查询显示最终摘要以总结部分摘要。
我用来总结 5 分钟窗口的提示是
Summarize this article from ”{start_text}\” to ”{end_text}, limited in 100 words, start with ”This section of video”
start_text 和 end_text 是文本字段中引用转录 JSON 中起始字段的内容
请找到完整的演示代码供你参考
!python -m pip install openai streamlit llama-index langchain youtube-transcript-api html2image
import os
os.environ["OPENAI_API_KEY"] = '{your_api_key}'
import streamlit as st
from llama_index import download_loader
from llama_index import GPTSimpleVectorIndex
from llama_index import LLMPredictor, GPTSimpleVectorIndex, PromptHelper, ServiceContext
from langchain import OpenAI
from langchain.chat_models import ChatOpenAI
from youtube_transcript_api import YouTubeTranscriptApi
from youtube_transcript_api.formatters import JSONFormatter
import json
import datetime
from html2image import Html2Image
doc_path = './data/'
transcript_file = './data/transcript.json'
index_file = 'index.json'
youtube_img = 'youtube.png'
youtube_link = ''
if 'video_id' not in st.session_state:
st.session_state.video_id = ''
def send_click():
st.session_state.video_id = youtube_link.split("v=")[1][:11]
index = None
st.title("Yeyu's Video Summarizer")
sidebar_placeholder = st.sidebar.container()
youtube_link = st.text_input("Youtube link:")
st.button("Summarize!", on_click=send_click)
if st.session_state.video_id != '':
progress_bar = st.progress(5, text=f"Summarizing...")
srt = YouTubeTranscriptApi.get_transcript(st.session_state.video_id, languages=['en'])
formatter = JSONFormatter()
json_formatted = formatter.format_transcript(srt)
with open(transcript_file, 'w') as f:
f.write(json_formatted)
hti = Html2Image()
hti.screenshot(url=f"https://www.youtube.com/watch?v={st.session_state.video_id}", save_as=youtube_img)
SimpleDirectoryReader = download_loader("SimpleDirectoryReader")
loader = SimpleDirectoryReader(doc_path, recursive=True, exclude_hidden=True)
documents = loader.load_data()
sidebar_placeholder.header('Current Processing Video')
sidebar_placeholder.image(youtube_img)
sidebar_placeholder.write(documents[0].get_text()[:10000]+'...')
# define LLM
llm_predictor = LLMPredictor(llm=ChatOpenAI(temperature=0, model_name="gpt-3.5-turbo", max_tokens=500))
service_context = ServiceContext.from_defaults(llm_predictor=llm_predictor)
index = GPTSimpleVectorIndex.from_documents(
documents, service_context=service_context
)
index.save_to_disk(index_file)
section_texts = ''
section_start_s = 0
with open(transcript_file, 'r') as f:
transcript = json.load(f)
start_text = transcript[0]["text"]
progress_steps = int(transcript[-1]["start"]/300+2)
progress_period = int(100/progress_steps)
progress_timeleft = str(datetime.timedelta(seconds=20*progress_steps))
percent_complete = 5
progress_bar.progress(percent_complete, text=f"Summarizing...{progress_timeleft} left")
section_response = ''
for d in transcript:
if d["start"] <= (section_start_s + 300) and transcript.index(d) != len(transcript) - 1:
section_texts += ' ' + d["text"]
else:
end_text = d["text"]
prompt = f"summarize this article from \"{start_text}\" to \"{end_text}\", limited in 100 words, start with \"This section of video\""
#print(prompt)
response = index.query(prompt)
start_time = str(datetime.timedelta(seconds=section_start_s))
end_time = str(datetime.timedelta(seconds=int(d['start']))
section_start_s += 300
start_text = d["text"]
section_texts = ''
section_response += f"**{start_time} - {end_time}:**\n\r{response}\n\r"
percent_complete += progress_period
progress_steps -= 1
progress_timeleft = str(datetime.timedelta(seconds=20*progress_steps))
progress_bar.progress(percent_complete, text=f"Summarizing...{progress_timeleft} left")
prompt = "Summarize this article of a video, start with \"This Video\", the article is: " + section_response
#print(prompt)
response = index.query(prompt)
progress_bar.progress(100, text="Completed!")
st.subheader("Summary:")
st.success(response, icon= "")
with st.expander("Section Details: "):
st.write(section_response)
st.session_state.video_id = ''
st.stop()
将代码保存到 Python 文件“demo.py”创建一个 ./data/ 文件夹然后运行命令
!python -m streamlit run demo.py
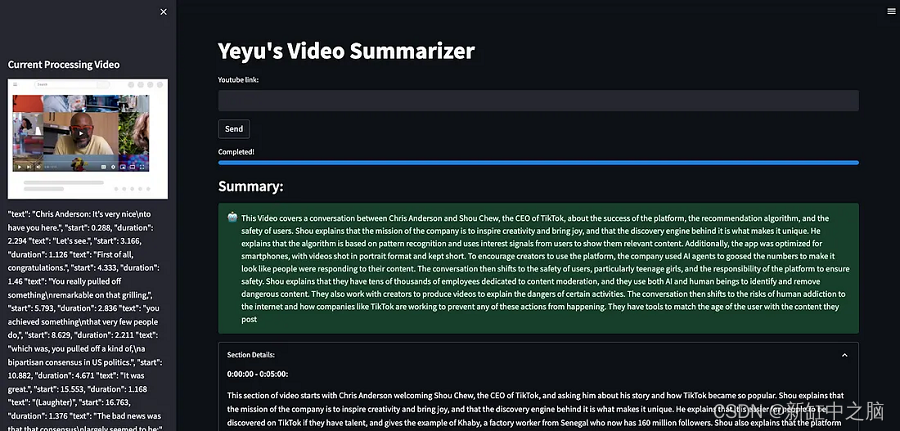
Video Summarizer 现已准备就绪能够简单而有效地执行其任务。
注意——请从一段短视频开始测试因为长视频会花费你大量的 OpenAI API 使用费。 在继续之前还请检查视频是否启用文本转录。
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |