

机器学习知识总结——18.实现一个简单的K-Means聚类
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
文章目录
在上一章节里简要的介绍了无监督学习中聚类的知识点看的太多理论概念难免会有点莫名其妙现在就让我们来实现一个简单的 K-Means 算法从而从原理上彻底弄明白聚类是怎么工作的。
引用库
我们还是像其他示例一样尽量用最少的第三方库来阐述清楚问题所以这里我们也只引用Numpy和绘图工具matplotlib
import numpy as np
import matplotlib as plt
生成样本数据
我们需要生成一些样本于是继续用到 np.random.normal 用来生成正态分布数据。
# 生成样本数据
np.random.seed(0)
cluster1 = np.random.normal(3, 1, (100, 2))
cluster2 = np.random.normal(7, 1, (100, 2))
cluster3 = np.random.normal(11, 1, (100, 2))
X = np.concatenate((cluster1, cluster2, cluster3), axis=0)
训练K-Means
基本上我们需要实现的函数主要有三个一个是样本到质心的距离计算函数可以使用简单的欧式距离进行判断
# 计算每个样本到质心的距离
def distance(X, centers):
dist = np.sqrt(np.sum((X[:, np.newaxis] - centers) ** 2, axis=-1))
return dist
然后要随时更新质心
# 重新计算质心
def update_centers(X, labels, k):
centers = np.array([X[labels == i].mean(axis=0) for i in range(k)])
return centers
然后就是主要的 k-means 主函数了
# k-means 主函数
def kmeans(X, k, max_iter=100):
centers = initial_centers
for i in range(max_iter):
dist = distance(X, centers)
labels = np.argmin(dist, axis=-1)
centers = update_centers(X, labels, k)
return labels, centers
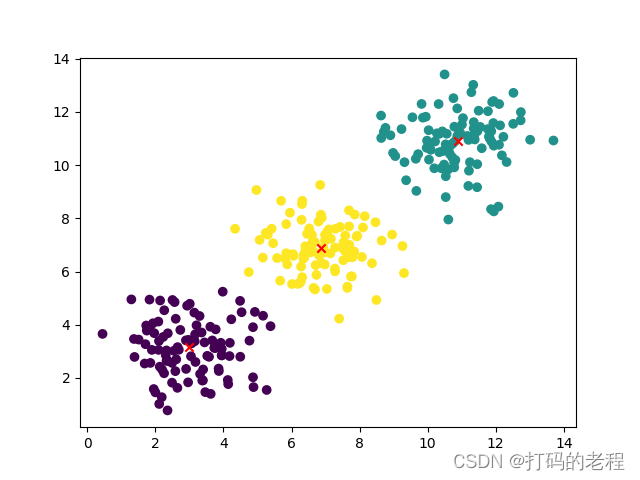
然后我们告诉程序请帮我们把训练数据生成3类
# 实验
labels, centers = kmeans(X, 3)
得到的结果如下
实验
为了验证我们的模型是否有能力对新的数据进行分类我们使用随机数生成一个测试数据集并实现了一个简单的预测函数
# 现在我们来开始做预测
def predict(X, centers):
dist = np.sqrt(np.sum((X[:, np.newaxis] - centers) ** 2, axis=-1))
return np.argmin(dist, axis=-1)
然后看看我们的结果是怎样
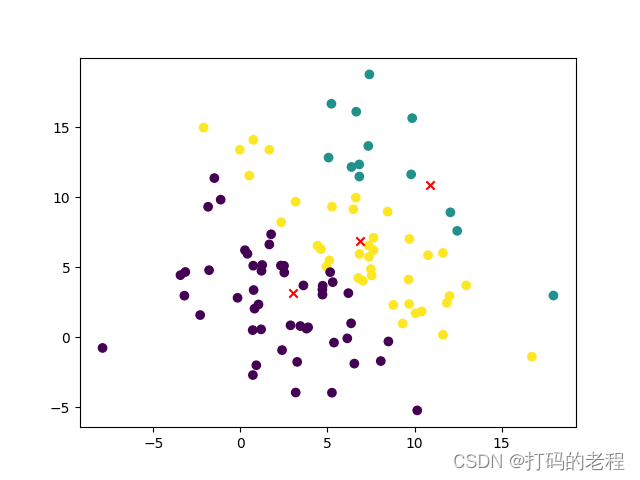
看来成功了一个简单的聚类实现大致上就是上面这些代码所示范的过程希望对你有所帮助。