

吴恩达机器学习课程笔记:正规方程法
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
1.吴恩达机器学习课程笔记正规方程法
笔记来源
1.吴恩达机器学习课程笔记正规方程法
2.神经网络 - 多元线性回归 - 正规方程法
仅作为个人学习笔记若各位大佬发现错误请指正
正规方程法区别于梯度下降法的迭代求解属于直接求解方程得到参数的最优解
正规方程法可直接使用特征的值无需对特征的值进行缩放而梯度下降法需要对特征的值进行缩放
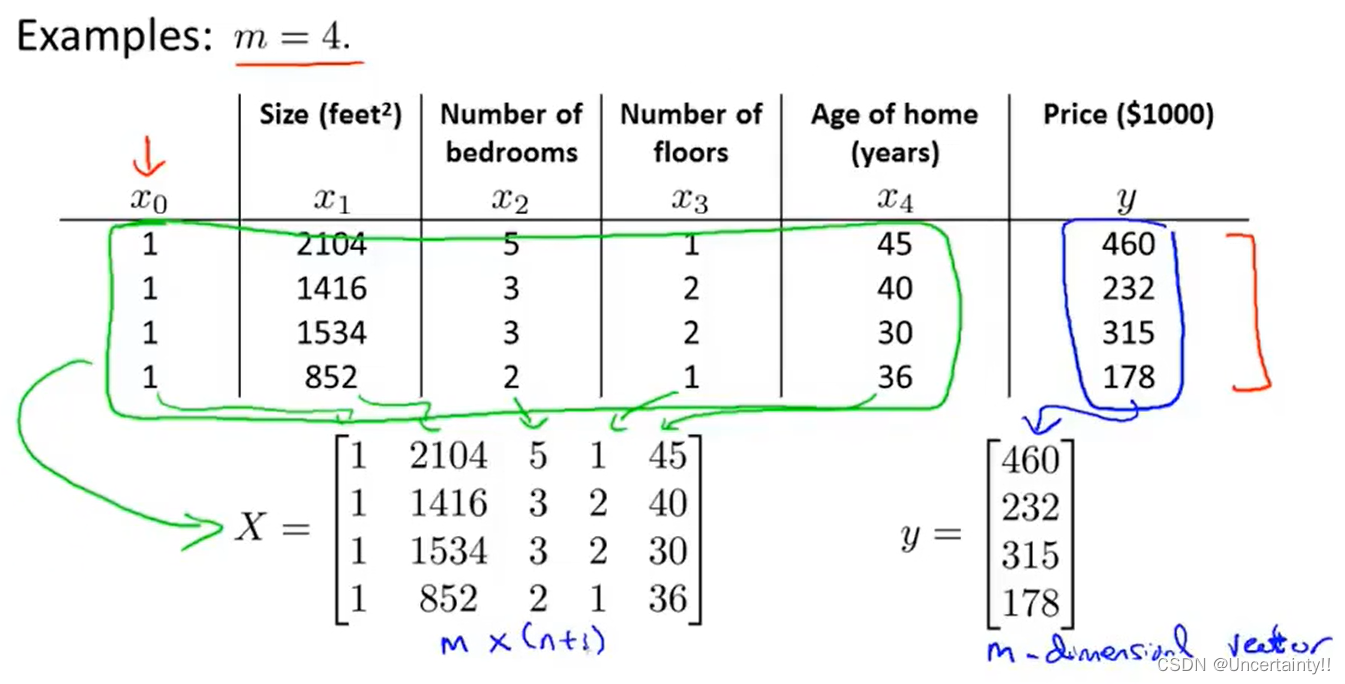
假设函数
h
θ
(
x
)
=
θ
0
x
0
⃗
+
θ
1
x
1
⃗
+
θ
2
x
2
⃗
+
⋯
+
θ
n
x
n
⃗
h
θ
(
x
)
=
X
⋅
θ
⃗
θ
⃗
=
(
θ
0
θ
1
⋮
θ
n
)
X
=
(
x
0
⃗
,
x
1
⃗
,
x
2
⃗
,
⋯
,
x
n
⃗
)
h_{\theta}(x)=\theta_0\vec{x_0}+\theta_1\vec{x_1}+\theta_2\vec{x_2}+\cdots+\theta_n\vec{x_n}\\ ~\\ h_{\theta}(x)=\bold{X\cdot \vec{\theta}}\\ ~\\ \vec{\theta}=\begin{pmatrix}\theta_0\\\theta_1\\ \vdots\\ \theta_n \end{pmatrix}\ X=\begin{pmatrix}\vec{x_0},\vec{x_1},\vec{x_2},\cdots,\vec{x_n}\end{pmatrix}\\
hθ(x)=θ0x0+θ1x1+θ2x2+⋯+θnxn hθ(x)=X⋅θ θ=
θ0θ1⋮θn
X=(x0,x1,x2,⋯,xn)
h
θ
(
x
)
=
X
⋅
θ
⃗
=
y
⃗
h_{\theta}(x)=\bold{X\cdot \vec{\theta}}=\vec{y}
hθ(x)=X⋅θ=y
我们需要求解出矩阵
θ
⃗
\vec{\theta}
θ所以我们需要
X
X
X为可逆矩阵也就是需要其为方阵但由于样本数量与特征数量不一定是相等的故
X
X
X不一定是方阵但我们可以构造出方阵即
X
T
X
X^TX
XTX如果此方阵可逆这样我们就可以求解出矩阵
θ
⃗
\vec{\theta}
θ
下面我们左右同乘矩阵
X
T
X^T
XT
本人笔记最小二乘估计Least Squares Approximations、拟合Fitting
X
T
X
⋅
θ
⃗
=
X
T
y
⃗
X^TX\cdot \vec{\theta}=X^T\vec{y}
XTX⋅θ=XTy
求出
(
X
T
X
)
−
1
(X^TX)^{-1}
(XTX)−1
θ
⃗
=
(
X
T
X
)
−
1
X
T
y
⃗
\vec{\theta}=(X^TX)^{-1}X^T\vec{y}
θ=(XTX)−1XTy
什么原因会造成矩阵
X
T
X
X^TX
XTX变为不可逆矩阵
笔记来源正规方程在矩阵不可逆情况下的解决方法
1.多余特征例如一个特征房屋大小以平方英尺为单位、另一个特征也是房屋大小以平方米为单位两个特征表达同一个东西造成特征的冗余应删除其中一个特征
2.特征数量大于样本数量删除一些特征或进行正则化

梯度下降法与正规方程法的比较
当特征过大时建议采用梯度下降法

| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |