

在全新ubuntu上用gpu训练paddleocr模型遇到的坑与解决办法-CSDN博客
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
目录
- 一. 我的ubuntu版本
- 二.首先拉取paddleocr源代码
- 三.下载模型
- 四.训练前的准备
- 1.在源代码文件夹里创造一个自己放东西的文件
- 2.准备数据
- 3.改写yml配置文件
- 4.安装anaconda
- 五.开始训练
- 六.报错
- 4报错UnicodeDecodeError: ‘utf-8’ codec can’t decode byte 0xbc in position 2: invalid start byt
- 5Out of memory error on GPU 0. Cannot allocate xxxxMB memory on GPU 0, xxxxGB memory has been allocated and available memory is only 0.000000B.
一. 我的ubuntu版本
二.首先拉取paddleocr源代码
下载地址https://gitee.com/paddlepaddle/PaddleOCR
三.下载模型
-
我要训练一个中文模型看到该预训练模型泛化性能最优于是下载这个模型
https://gitee.com/link?target=https%3A%2F%2Fpaddleocr.bj.bcebos.com%2FPP-OCRv3%2Fchinese%2Fch_PP-OCRv3_rec_train.tar -
其他模型地址https://gitee.com/paddlepaddle/PaddleOCR/blob/release/2.6/doc/doc_ch/models_list.md
四.训练前的准备
1.在源代码文件夹里创造一个自己放东西的文件
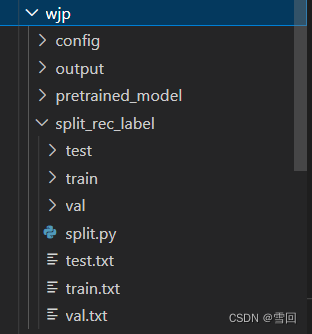
-
config文件夹用来装yml配置文件
pretrained_model用来装上一步下载的预训练模型
split_rec_label用来放数据集
output用来放训练出的模型 -
创建文件夹非强制只是这样更方便管理自己文件yml源文件地址就在
PaddleOCR-release-2.6/configs/rec/PP-OCRv3这个路径下
2.准备数据
2.1数据标注
参考博客https://blog.csdn.net/qq_49627063/article/details/119134847
2.2数据划分
在训练之前所有图片都在一个文件夹中所有label信息都在同一个txt文件中因此需要编写脚本将其按照8:1:1的比例进行分割。
import os
import re
import shutil
import random
import argparse
def split_label(all_label, train_label, val_label, test_label):
f = open(all_label, 'r')
f_train = open(train_label, 'w')
f_val = open(val_label, 'w')
f_test = open(test_label, 'w')
raw_list = f.readlines()
num_train = int(len(raw_list) * 0.8)
num_val = int(len(raw_list) * 0.1)
num_test = int(len(raw_list) * 0.1)
random.shuffle(raw_list)
for i in range(num_train):
f_train.writelines(raw_list[i])
for i in range(num_train, num_train + num_val):
f_val.writelines(raw_list[i])
for i in range(num_train + num_val, num_train + num_val + num_test):
f_test.writelines(raw_list[i])
f.close()
f_train.close()
f_val.close()
f_test.close()
def split_img(all_imgs, train_label, train_imgs, val_label, val_imgs, test_label, test_imgs):
f_train = open(train_label, 'r')
f_val = open(val_label, 'r')
f_test = open(test_label, 'r')
train_list = f_train.readlines()
val_list = f_val.readlines()
test_list = f_test.readlines()
for i in range(len(train_list)):
img_path = os.path.join(all_imgs, re.split("[/\t]", train_list[i])[1])
shutil.move(img_path, train_imgs)
for i in range(len(val_list)):
img_path = os.path.join(all_imgs, re.split("[/\t]", val_list[i])[1])
shutil.move(img_path, val_imgs)
for i in range(len(test_list)):
img_path = os.path.join(all_imgs, re.split("[/\t]", test_list[i])[1])
shutil.move(img_path, test_imgs)
def get_args():
parser = argparse.ArgumentParser()
parser.add_argument("--all_label", default="../paddleocr/PaddleOCR/train_data/cls/cls_gt_train.txt")
parser.add_argument("--all_imgs_dir", default="../paddleocr/PaddleOCR/train_data/cls/images/")
parser.add_argument("--train_label", default="../paddleocr/PaddleOCR/train_data/cls/train.txt")
parser.add_argument("--train_imgs_dir", default="../paddleocr/PaddleOCR/train_data/cls/train/")
parser.add_argument("--val_label", default="../paddleocr/PaddleOCR/train_data/cls/val.txt")
parser.add_argument("--val_imgs_dir", default="../paddleocr/PaddleOCR/train_data/cls/val/")
parser.add_argument("--test_label", default="../paddleocr/PaddleOCR/train_data/cls/test.txt")
parser.add_argument("--test_imgs_dir", default="../paddleocr/PaddleOCR/train_data/cls/test/")
return parser.parse_args()
def main(args):
if not os.path.isdir(args.train_imgs_dir):
os.makedirs(args.train_imgs_dir)
if not os.path.isdir(args.val_imgs_dir):
os.makedirs(args.val_imgs_dir)
if not os.path.isdir(args.test_imgs_dir):
os.makedirs(args.test_imgs_dir)
split_label(args.all_label, args.train_label, args.val_label, args.test_label)
split_img(args.all_imgs_dir, args.train_label, args.train_imgs_dir, args.val_label, args.val_imgs_dir, args.test_label, args.test_imgs_dir)
if __name__ == "__main__":
main(get_args())
3.改写yml配置文件
- 源地址https://gitee.com/paddlepaddle/PaddleOCR/blob/release/2.6/configs/rec/PP-OCRv3/ch_PP-OCRv3_rec_distillation.yml
Global:
debug: false
use_gpu: true
epoch_num: 800
log_smooth_window: 20
print_batch_step: 10
save_model_dir: wjp/output/rec_ppocr_v3_distillation
save_epoch_step: 3
eval_batch_step: [0, 2000]
cal_metric_during_train: true
pretrained_model:
checkpoints:
save_inference_dir:
use_visualdl: false
infer_img: doc/imgs_words/ch/word_1.jpg
character_dict_path: ppocr/utils/ppocr_keys_v1.txt
max_text_length: &max_text_length 25
infer_mode: false
use_space_char: true
distributed: true
save_res_path: wjp/output/rec/predicts_ppocrv3_distillation.txt
Optimizer:
name: Adam
beta1: 0.9
beta2: 0.999
lr:
name: Piecewise
decay_epochs : [700]
values : [0.0005, 0.00005]
warmup_epoch: 5
regularizer:
name: L2
factor: 3.0e-05
Architecture:
model_type: &model_type "rec"
name: DistillationModel
algorithm: Distillation
Models:
Teacher:
pretrained:
freeze_params: false
return_all_feats: true
model_type: *model_type
algorithm: SVTR
Transform:
Backbone:
name: MobileNetV1Enhance
scale: 0.5
last_conv_stride: [1, 2]
last_pool_type: avg
Head:
name: MultiHead
head_list:
- CTCHead:
Neck:
name: svtr
dims: 64
depth: 2
hidden_dims: 120
use_guide: True
Head:
fc_decay: 0.00001
- SARHead:
enc_dim: 512
max_text_length: *max_text_length
Student:
pretrained:
freeze_params: false
return_all_feats: true
model_type: *model_type
algorithm: SVTR
Transform:
Backbone:
name: MobileNetV1Enhance
scale: 0.5
last_conv_stride: [1, 2]
last_pool_type: avg
Head:
name: MultiHead
head_list:
- CTCHead:
Neck:
name: svtr
dims: 64
depth: 2
hidden_dims: 120
use_guide: True
Head:
fc_decay: 0.00001
- SARHead:
enc_dim: 512
max_text_length: *max_text_length
Loss:
name: CombinedLoss
loss_config_list:
- DistillationDMLLoss:
weight: 1.0
act: "softmax"
use_log: true
model_name_pairs:
- ["Student", "Teacher"]
key: head_out
multi_head: True
dis_head: ctc
name: dml_ctc
- DistillationDMLLoss:
weight: 0.5
act: "softmax"
use_log: true
model_name_pairs:
- ["Student", "Teacher"]
key: head_out
multi_head: True
dis_head: sar
name: dml_sar
- DistillationDistanceLoss:
weight: 1.0
mode: "l2"
model_name_pairs:
- ["Student", "Teacher"]
key: backbone_out
- DistillationCTCLoss:
weight: 1.0
model_name_list: ["Student", "Teacher"]
key: head_out
multi_head: True
- DistillationSARLoss:
weight: 1.0
model_name_list: ["Student", "Teacher"]
key: head_out
multi_head: True
PostProcess:
name: DistillationCTCLabelDecode
model_name: ["Student", "Teacher"]
key: head_out
multi_head: True
Metric:
name: DistillationMetric
base_metric_name: RecMetric
main_indicator: acc
key: "Student"
ignore_space: False
Train:
dataset:
name: SimpleDataSet
data_dir: wjp/split_rec_label/train
ext_op_transform_idx: 1
label_file_list:
- wjp/split_rec_label/train.txt
transforms:
- DecodeImage:
img_mode: BGR
channel_first: false
- RecConAug:
prob: 0.5
ext_data_num: 2
image_shape: [48, 320, 3]
max_text_length: *max_text_length
- RecAug:
- MultiLabelEncode:
- RecResizeImg:
image_shape: [3, 48, 320]
- KeepKeys:
keep_keys:
- image
- label_ctc
- label_sar
- length
- valid_ratio
loader:
shuffle: true
batch_size_per_card: 32
drop_last: true
num_workers: 4
Eval:
dataset:
name: SimpleDataSet
data_dir: wjp/split_rec_label/val
label_file_list:
- wjp/split_rec_label/val.txt
transforms:
- DecodeImage:
img_mode: BGR
channel_first: false
- MultiLabelEncode:
- RecResizeImg:
image_shape: [3, 48, 320]
- KeepKeys:
keep_keys:
- image
- label_ctc
- label_sar
- length
- valid_ratio
loader:
shuffle: false
drop_last: false
batch_size_per_card: 128
num_workers: 4
4.安装anaconda
参考博客https://blog.csdn.net/wyf2017/article/details/118676765
- 创建python虚拟环境
conda create -n ppocr
- 切换虚拟环境
source activate ppocr
五.开始训练
python tools/train.py -c wjp/ch_PP-OCRv3_rec_distillation.yml -o Global.pretrained_model=wjp/ch_PP-OCRv3_rec_train/best_accuracy
//-c参数放配置文件地址-o参数放预训练模型地址
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple
六.报错
1 libGL.so.1
ImportError: libGL.so.1: cannot open shared object file: No such file or directory
- 解决办法
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple opencv-python-headless
2Polygon
ModuleNotFoundError: No module named 'Polygon'
- 解决办法
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple Polygon3
(3) lanms
ModuleNotFoundError: No module named 'lanms'
源码下载地址https://github.com/AndranikSargsyan/lanms-nova/tree/master
参考我这个教程编译http://t.csdnimg.cn/BqOW6
- 将__init __.py文件替换
import numpy as np
def merge_quadrangle_n9(polys, thres=0.3, precision=10000):
if len(polys) == 0:
return np.array([], dtype='float32')
p = polys.copy()
p[:, :8] *= precision
ret = np.array(merge_quadrangle_n9(p, thres), dtype='float32')
ret[:, :8] /= precision
return ret
- 找到linux种anaconda的包放在什么地方
pip show numpy
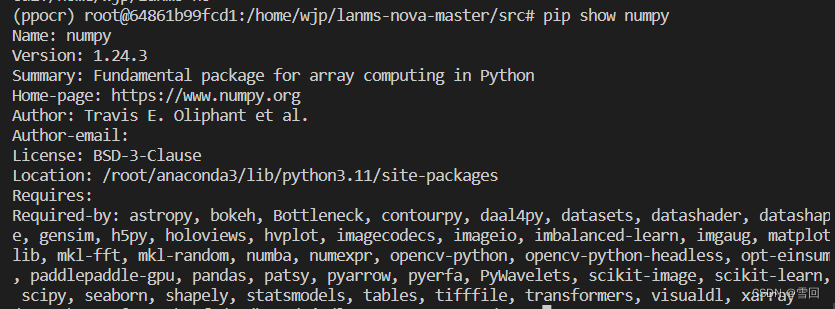
就知道该环境下的包安装地址
- 将编译好库的整个lanms文件夹移动到该地址去即可调用
4报错UnicodeDecodeError: ‘utf-8’ codec can’t decode byte 0xbc in position 2: invalid start byt
f = open('txt01.txt',encoding='utf-8')
将 encoding=’utf-8’ 改为GB2312、gbk、ISO-8859-1随便尝试一个均可以
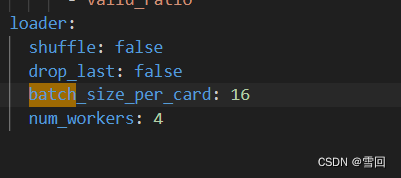
5Out of memory error on GPU 0. Cannot allocate xxxxMB memory on GPU 0, xxxxGB memory has been allocated and available memory is only 0.000000B.
将训练的配置yml文件中的batch_size_per_card参数不断改小除以2直到不再报这个错即可。
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |