MoCoViT: Mobile Convolutional Vision Transformer
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
paper链接: https://arxiv.org/abs/2205.12635v1
MoCoViT: Mobile Convolutional Vision Transformer
(一)、引言
本文中提出了Mobile卷积视觉Transformer(MoCoViT)它通过将Transformer引入移动卷积网络来利用这两种架构的优势来提高性能和效率。与最近的视觉Transformer工作不同MoCoViT中的Mobile Transformer块是为移动设备精心设计的非常轻量通过两个主要修改来实现:Mobile自注意(MoSA)模块和Mobile前馈网络(MoFFN)。MoSA通过Branch Sharing方案简化了注意力图的计算而MoFFN作为Transformer中的移动版MLP进一步大幅减少了计算量。综合实验证明本文提出的MoCoViT家族在各种视觉任务上优于最先进的便携式CNN和Transformer神经结构。
与以往的工作不同本文提出了一种非常高效的Mobile Transformer块(MTB)。该模块是针对移动视觉任务精心设计的由Mobile自注意(MoSA)和Mobile前馈网络(MoFFN)两个关键组件组成。在MoSA中在查询、键和值的计算中线性层被轻量级的Ghost模块取代。
此外采用分支共享(Branch Sharing)方案在计算过程中重用权值。因此MoSA比普通的自关注更有效。对于多层感知(Multi Layer Perception, MLP)其复杂性在Transformer块中是不可忽视的。MoFFN的产生就是为了解决这个问题。将MLP中的上投影和下投影线性层也替换为高效的Ghost模块形成MoFFN。在MTB的基础上提出了移动卷积视觉转换器(MoCoViT)这是一种新的移动应用架构其中CNN块和MTB块串联在一起。
为了实现复杂度和性能之间的最佳平衡CNN块被放置在早期阶段而MTB块只在最后阶段使用。
简而言之本工作贡献可以概括如下:
1、为移动设备提出了一种非常轻量的ransformer块。在块内部Mobile自注意力和Mobile前馈网络经过精心设计旨在实现复杂性和性能之间的最佳平衡。
2、提出了MoCoViT一种高效的架构结合了CNN和Transformer的优势并在各种视觉任务上实现了SOTA性能。
(二)、实现细节
(一)、Mobile Self-Attention (MoSA)
首先在细粒度操作方面将vanilla self-attention中的线性层替换为更高效的Ghost模块这是轻量级网络中常用的结构可以被视为卷积操作的一种高效变体以低成本的方式生成相对相似的特征对。下图显示了Ghost模块的结构。Ghost模块采用普通卷积先生成一些固有的特征映射然后利用廉价的线性运算对特征进行增广增加通道。在实践中廉价的线性运算通常被实现为深度卷积以更好地权衡性能和速度。
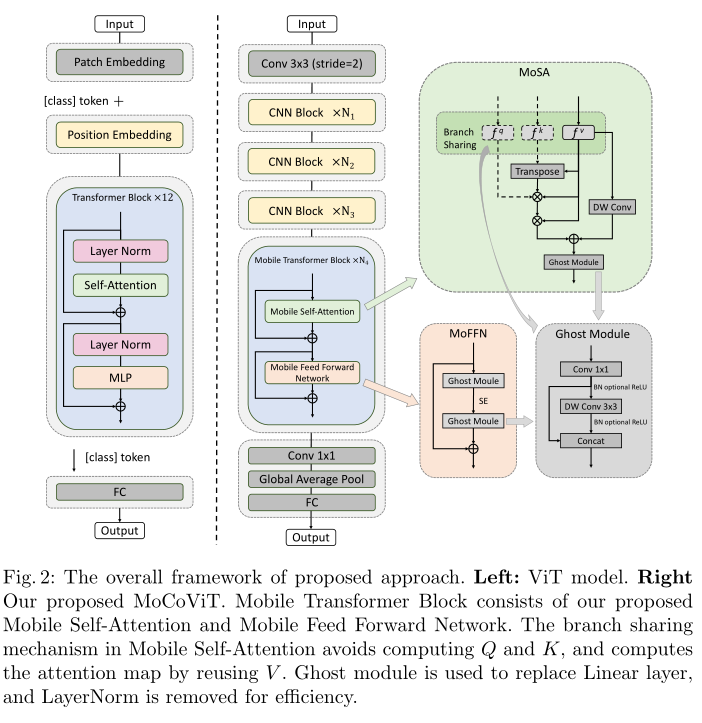
其次从宏观角度提出了分支共享机制实现Q、K、V计算中的权重重用。如上图所示
f
q
f^q
fq、
f
k
f^k
fk、
f
v
f^v
fv分别是q、k、v在相同输入特征下的投影。在分支共享机制中直接将特征V重用为Q和K。这种方法主要是基于作者的一个见解:Q和K只参与了注意力图的计算而自注意机制的最终结果是V中每个令牌的线性组合。与Q和K相比V需要保留更多的语义信息以保证最终加权和结果的表示能力。因此自注意机制的结果与V强相关而与Q和K弱相关。
因此对于小容量的移动网络可以简化Q和K的计算以达到更好的性能开销平衡。
分支共享机制可以表示为:
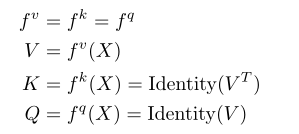
其中
f
v
f^v
fv,
f
k
f^k
fk和
f
q
f^q
fq分别是计算q k v的投影。为了进一步提高性能还引入了深度卷积层作为细化器以进一步增强该Transformer块。MoSA的计算可以写成:
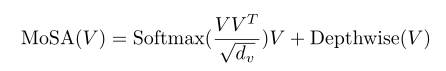
提出的移动自我注意的计算复杂度为:
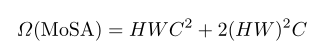
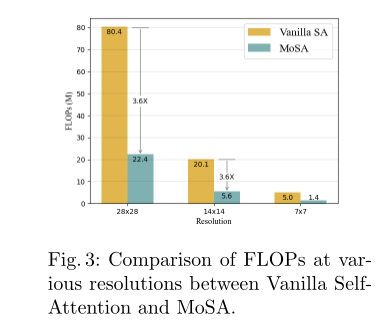
其中N = H × W为空间维度C为通道维度。为了定量地证明开销的减少比较了不同分辨率下vanilla自注意和MoSA的FLOPs和参数。相比对于vanilla自注意MoSA的FLOPs小于3.6×参数小于2.4×如图所示
(二)、Mobile Feed Forward Network (MoFFN)
在普通的ViT中MLP层由向上投影的全连接(FC)层和向下投影的FC层组成并且在MLP部分之前应用LayerNorm。为了在移动设备上部署用一个更高效的Ghost模块替换了vanilla MLP中的FC层。在MoFFN中使用批量归一化可以在部署时进行合并。此外没有使用在移动端部署不友好的GeLU激活函数而是采用了在轻量级模型中广泛使用的ReLU激活函数。在上投影Ghost模块之后还应用了挤压和激发(SE)模块。
除了计算效率外MoFFN比MLP有更大的感受野。在原有的ViT架构中MLP侧重于通过线性层提取单个令牌的通道维度信息而空间维度上的信息交互主要在自注意部分进行。也就是说vanilla ViT中的MLP没有空间意识因此需要在自注意之后使用。MoFFN解决了MLP中的这一缺陷。首先在Ghost Module中通过点向卷积提取每个令牌的通道维度特征然后使用核大小为3×3的深度卷积提取空间维度特征。最后我们将点卷积和深度卷积的输出连接起来。
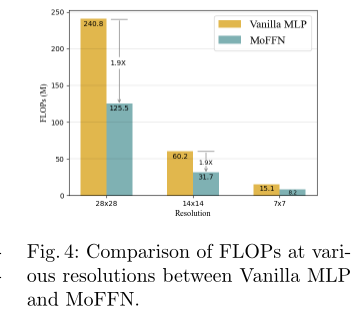
定量分析了MoFFN在不同分辨率下所带来的计算开销降低。结果如下所示。可以看到MoFFN的FLOPs比vanilla MLP约少1.9倍。
(三)、Mobile Transformer Block (MTB)
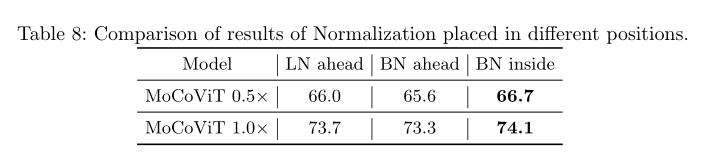
利用MoSA和MoFFN的优点本文介绍了专为轻量级深度模型设计的移动Transformer块。Transformer块由多头自我注意(MHSA)和MLP层交替层组成。在每个块之前和之后分别应用LayerNorm (LN)和residual connections。在MTB中保留每个块之后的剩余连接但用我们提出的MoSA和MoFFN替换vanilla self-attention和vanilla MLP。此外去掉了注意力和MLP部分之前低效的LayerNorm代之以Ghost模块内部的批处理归一化(batch normalization, BN)。BN是一种移动友好的规范化操作因为它可以在部署时与卷积层合并。
(四)、Building efficient networks with Mobile Transformer Block
MoCoViT采用特征金字塔结构特征图的分辨率随着网络深度的增加而降低通道数增加。将整个架构分为4个阶段只在最深的阶段使用MTB。这主要基于两个方面的考虑:首先自注意的计算复杂度与空间分辨率呈二次函数关系。在浅层阶段特征具有较高的空间分辨率这导致了较大的计算开销和内存消耗。其次在轻量级网络的早期阶段由于网络的表示能力有限构建全局表示是一项相对困难的任务。Transformer块的优点是提取全局信息而CNN善于提取局部信息。因此在网络的浅层中使用CNN块有助于提高特征提取的效率。
MoCoViT的结构细节见下表。在早期阶段使用Ghost瓶颈它广泛应用于移动设备(例如智能手机和自动驾驶汽车)。所有的Ghost瓶颈都使用stride=1除了每个阶段的最后一个使用stride=2。建议的MTB在最后阶段使用。最后利用全局平均池化和卷积层将特征映射转换为1280维的特征向量进行分类。
(三)、实验
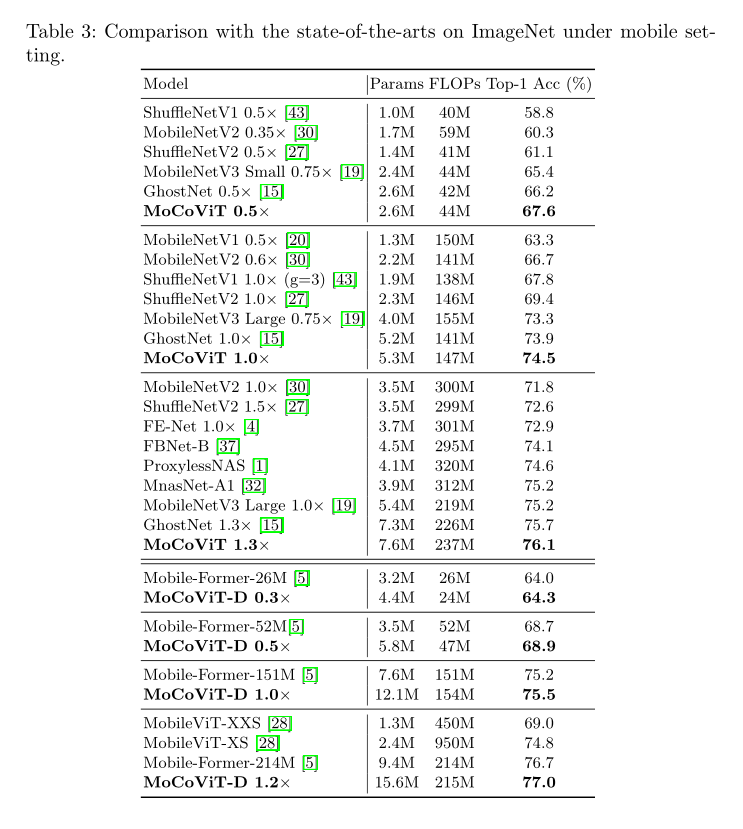
(一)、分类
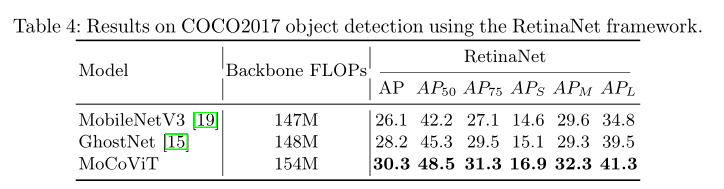
(二)、检测
(三)、分割

(四)、消融实验
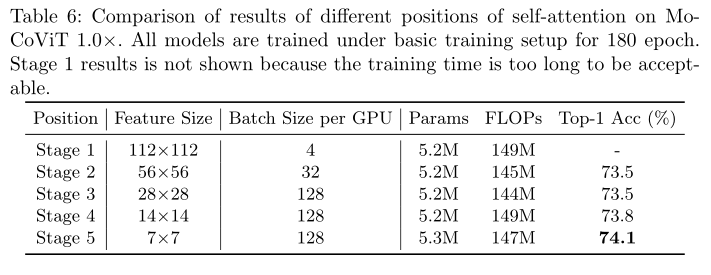
比较了不同阶段使用移动Transformer块的精度结果如下表所示。值得一提的是当在浅层使用移动自注意时模型的内存占用显著增加因此训练批大小减小。
MoCoViT包含两个重要的设计:MoSA和MoFFN。为了证明它们的重要性在基本训练设置下作为基线训练GhostNet 0.5× 180个epoch。然后比较不同类型的自注意机制来评估绩效收益。
结果如下表所示