

[机器学习、Spark]Spark机器学习库MLlib的概述与数据类型_mllib
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
👨🎓👨🎓博主发量不足
📑📑本期更新内容Spark机器学习库MLlib的概述与数据类型
📑📑下篇文章预告Spark MLlib基本统计
💨💨简介分享的是一个当代疫情在校封校的大学生学习笔记
目录
MLlib是Spark提供的可扩展的机器学习库其特点是采用较为先进的迭代式、内存存储的分析计算使得数据的计算处理速度大大高于普通的数据处理引擎。
Spark机器学习库MLlib的概述
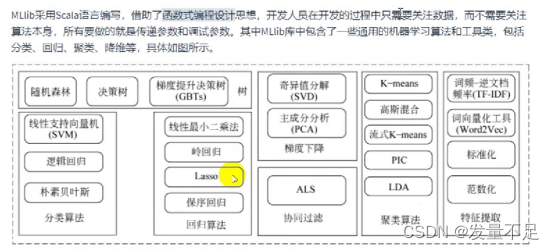
一.MLib的简介
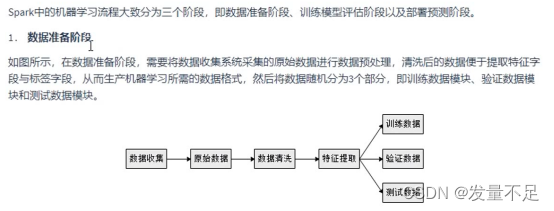
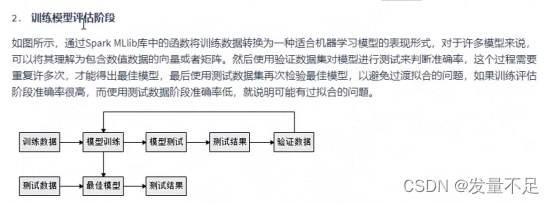
二.Spark机器学习工作流程

数据类型
MLlib的主要数据类型包括本地向量、标注点、本地矩阵。
本地向量和本地矩阵是提供公共接口的简单数据模型Breeze和Jblas提供了底层的线性代数运算。
在监督学习中用标注点类型表示训练样本。
一.本地向量
本地向量分为密集向量(Dense)和稀疏向量(Sparse),密集向量是由Double类型的数组支持而稀疏向量是由两个并列的数组支持。
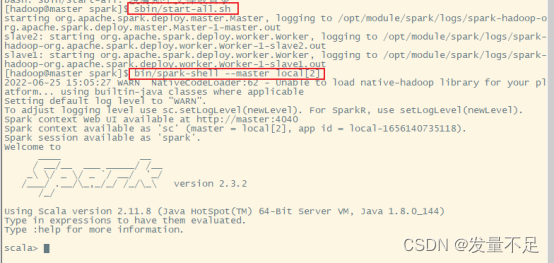
启动Spark集群服务(hadoop用户下spark路径)sbin/start-all.sh
启动Spark-Shellbin/spark-shell --master local[2]
导包
import org.apache.spark.mllib.linalg.{Vector,Vectors}
创建一个密集本地向量
val dv:Vector=Vectors.dense(1.0,0.0,3.0)
创建一个稀疏本地向量
val sv1:Vector=Vectors.sparse(3,Array(0,2),Array(1.0,3.0))
通过指定非零项目创建稀疏本地向量
val sv22:Vector = Vectors.sparse(3,Seq((0,1.0),(2,3.0)))
二.标注点
标签点Labeled Point是一个本地向量也分稀疏或者稠密并且是一个带有标签的本地向量。
在 MLlib 中标签点常用于监督学习类算法。标签Label是用 Double 类型存放的因此标签点可以用于回归或者分类算法中。如果是二维分类标签则必须是 0 或 1 之间的一种。而如果是多个维度的分类标签应当是从 0 开始的数字代表各个分类的索引。
导包
import org.apache.spark.mllib.linalg.Vectors
import org.apache.spark.mllib.regression.LabeledPoint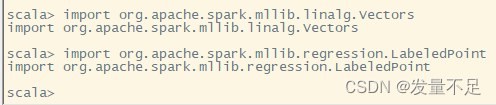
创建带有正标签和密集向量的标注点pos和带有负标签和稀疏向量的标注点neg
val pos = LabeledPoint(1.0,Vectors.dense(1.0,0.0,3.0))
val neg = LabeledPoint(0.0,Vectors.sparse(3,Array(0,2),Array(1.0,3.0)))
三.本地矩阵
导包
import org.apache.spark.mllib.linalg.{Matrix,Matrices}
创建一个3行2列的密集矩阵
val dm:Matrix = Matrices.dense(3,2,Array(1.0,3.0,5.0,2.0,4.0,6.0))
创建一个3行2列的稀疏矩阵
val sm:Matrix = Matrices.sparse(3,2,Array(0,1,3),Array(0,2,1),Array(9,6,8))