

Python正则表达式
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |


正则表达式
正则表达式
1、正则表达式概述
正则表达式又称正规表示式、正规表示法、正规表达式、规则表达式、常规表示法英语Regular Expression在代码中常简写为regex、regexp或RE是计算机科学的一个概念。正则表达式使用单个字符串来描述、匹配一系列匹配某个句法规则的字符串。在很多文本编辑器里正则表达式通常被用来检索、替换那些匹配某个模式的文本。
2、re模块
一个正则表达式或RE指定了一集与之匹配的字符串模块内的函数可以让你检查某个字符串是否跟给定的正则表达式匹配
模块定义了几个函数常量和一个例外。有些函数是编译后的正则表达式方法的简化版本少了一些特性。绝大部分重要的应用总是会先将正则表达式编译之后在进行操作。
compile方法
re.compile(pattern[,flags])
# 作用把正则表达式语法转化成正则表达式对象
pattern正则表达式语法
flags定义匹配模式包括{
re.I忽略大小写
re.L表示特殊字符集 \w,\W,\b,\B,\s,\S 依赖于当前环境
re.M多行模式
re.S' . '并且包括换行符在内的任意字符注意' . '匹配任意字符但不包 括换行符
re.U表示特殊字符集 \w,\d,\D,\S 依赖于 Unicode 字符属性数据库
}
search方法
re.search(pattern, string[, flags=0])
# 作用扫描整个字符串并返回第一个成功的匹配。如果匹配失败则返回None。
pattern : 正则表达式对象
string : 要被查找替换的原始字符串。
flags定义匹配模式包括{
re.I忽略大小写
re.L表示特殊字符集 \w,\W,\b,\B,\s,\S 依赖于当前环境
re.M多行模式
re.S' . '并且包括换行符在内的任意字符注意' . '匹配任意字符但不包括换行符
re.U表示特殊字符集 \w,\d,\D,\S 依赖于 Unicode 字符属性数据库
}
match方法
re.match(pattern, string[, flags=0])
# 作用从起始位置开始匹配匹配成功返回一个对象未匹配成功返回None
pattern : 正则表达式对象
string : 需要匹配的字符串
flags定义匹配模式包括{
re.I忽略大小写
re.L表示特殊字符集 \w,\W,\b,\B,\s,\S 依赖于当前环境
re.M多行模式
re.S' . '并且包括换行符在内的任意字符注意' . '匹配任意字符但不包括换行符
re.U表示特殊字符集 \w,\d,\D,\S 依赖于 Unicode 字符属性数据库
}
这里我们分别简单了解一下这些模块
1、compile方法是将正则表达式转换成对象
2、search和match方法是根据compile对象转换生成好的规则进行匹配。
可以使用search来进行匹配第一个最先匹配到的正常的电话号码而match用来匹配第一个注意是第一个字符的这里的第一个是在被搜索的这串字符的第一位索引上的。
1、re.Match object 对象
2、span=()搜索结果在文本索引位置
3、match匹配结果
这里我们现在就需要急切了解到两个问题
# 第一、得到的匹配对象re.Match object该如何处理以及re模块是否存在一些其他的方法
# 第二、正则表达式的写法
3、Match对象
我们来看一下Match对象Match对象是一次匹配的结果包含匹配的很多信息。
Match匹配对象的属性
| 属性与方法 | 描述 |
|---|---|
| pos | 搜索的开始位置 |
| endpos | 搜索的结束位置 |
| string | 搜索的字符串 |
| re | 当前使用的正则表达式对象 |
| lastindex | 最后匹配的组索引 |
| lastgroup | 最后匹配的组名 |
| group(index) | 某个组匹配的结果 |
| groups() | 所有分组的匹配结果每个分组组成的结果以列表返回 |
| groupdict() | 返回组名作为key每个分组的匹配结果作为value的字典 |
| start([group]) | 获取组的开始位置 |
| end([group]) | 获取组的结束位置 |
| span([group]) | 获取组的开始和结束位置 |
| expand(template) | 使用组的匹配结果来替换template中的内容并把替换后的字符串返回 |
这里我们来看一些例子
如何判断一个字符串是手机号呢
import re # re模块
s = """
abcdef
13388593428
aa1a3hi233rhi3
87156340
affa124564531346546
afa19454132135
"""
# compile 编译
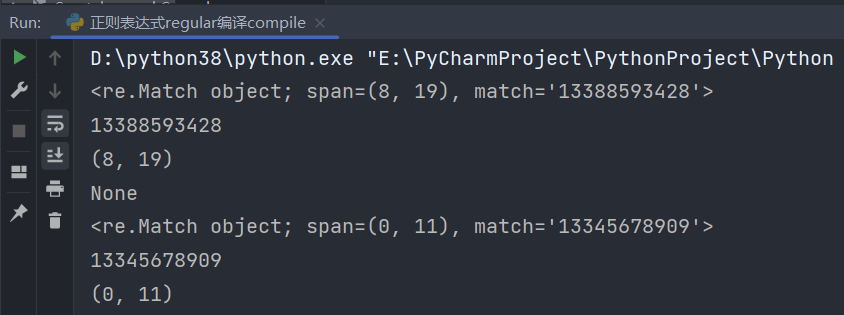
pattern = re.compile(r'1[3-9]\d{9}') # 编译正则表达式后得到一个编译对象
# search 搜索
result = pattern.search(s) # search 只会返回第一个匹配的结果
print(result) # <re.Match object; span=(8, 19), match='13388593428'>
print(result.group(0)) # 返回第一个匹配结果 13388593428
print(result.span(0)) # 返回第一个匹配结果的下标 (8, 19)
t = '13345678909cc'
# match从第一个字符开始匹配如果没有匹配到返回值为None
print(pattern.match(s)) # None
result2 = pattern.match(t)
print(result2) # <re.Match object; span=(0, 11), match='13345678909'>
print(result2.group(0)) # 13345678909
print(result2.span(0)) # (0, 11)
4、正则表达式
构造正则表达式的方法和创建数学表达式的方法一样。也就是用多种元字符与运算符可以将小的表达式结合在一起来创建更大的表达式。正则表达式的组件可以是单个的字符、字符集合、字符范围、字符间的选择或者所有这些组件的任意组合。
正则表达式是由普通字符例如字符 a 到 z以及特殊字符称为"元字符"组成的文字模式。模式描述在搜索文本时要匹配的一个或多个字符串。正则表达式作为一个模板将某个字符模式与所搜索的字符串进行匹配。
元字符 参见 python 模块 re 文档
| 字符 | 功能 |
|---|---|
| . | 匹配任意字符不包括换行符 |
| ^ | 匹配开始位置多行模式下匹配每一行的开始(也有取反的意思区分应用场景) |
| $ | 匹配结束位置多行模式下匹配每一行的结束 |
| * | 匹配前一个元字符0到多次 |
| + | 匹配前一个元字符1到多次 |
| ? | 匹配前一个元字符0到1次 |
| {m,n} | 匹配前一个元字符m到n |
| \ \ | 转义字符跟在其后的字符将失去作为特殊元字符的含义 例如\.只能匹配.不能再匹配任意字符 |
| [ ] | 字符集一个字符的集合可匹配其中任意一个字符 |
| | | 逻辑表达式 或 比如 a |
| (…) | 分组默认为捕获即被分组的内容可以被单独取出 默认每个分组有个索引从 1 开始按照"("的顺序决定索引值 |
| (?iLmsux) | 分组中可以设置模式iLmsux之中的每个字符代表一个模式 |
| (?:…) | 分组的不捕获模式计算索引时会跳过这个分组 |
| (?P…) | 分组的命名模式取此分组中的内容时可以使用索引也可以使用name |
| (?P=name) | 分组的引用模式可在同一个正则表达式用引用前面命名过的正则 |
| (?#…) | 注释不影响正则表达式其它部分 |
| (?=…) | 顺序肯定环视表示所在位置右侧能够匹配括号内正则 |
| (?!..) | 顺序否定环视表示所在位置右侧不能匹配括号内正则 |
| (?<=…) | 逆序肯定环视表示所在位置左侧能够匹配括号内正则 |
| (?<!..) | 逆序否定环视表示所在位置左侧不能匹配括号内正则 |
| (?(id/name)yes|no) | 若前面指定id或name的分区匹配成功则执行yes处的正则否则执行no处的正则 |
| \number | 匹配和前面索引为number的分组捕获到的内容一样的字符串 |
| \A | 匹配字符串开始位置忽略多行模式 |
| \Z | 匹配字符串结束位置忽略多行模式 |
| \b | 匹配位于单词开始或结束位置的空字符串 |
| \B | 匹配不位于单词开始或结束位置的空字符串 |
| \d | 匹配一个数字 相当于 [0-9] |
| \D | 匹配非数字,相当于 [^0-9] |
| \s | 匹配任意空白字符 相当于 [ \t\n\r\f\v] |
| \S | 匹配非空白字符相当于 [^ \t\n\r\f\v] |
| \w | 匹配数字、字母、下划线中任意一个字符 相当于 [a-zA-Z0-9_] |
| \W | 匹配非数字、字母、下划线中的任意字符相当于[^\w] |
5、表示字符
| 字符 | 功能 |
|---|---|
| . | 匹配任意单个字符不包括换行符 |
| [ ] | 匹配字符集区间中的集合可匹配其中任意一个字符 |
| \d | 匹配数字即0-9,可以表示为[0-9] |
| \D | 匹配非数字即不是数字相当于 [^0-9] |
| \s | 匹配空白字符即 空格tab键相当于 [ \t\n\r\f\v] |
| \S | 匹配非空白字符相当于 [^ \t\n\r\f\v] |
| \w | 匹配单词字符即a-z、A-Z、0-9、_ |
| \W | 匹配非单词字符即非数字、字母、下划线中的任意字符相当于[^\w] |
import re
# match 从第一个字符开始匹配
one = '886'
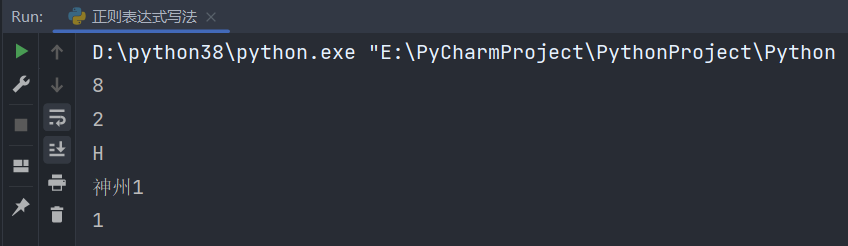
# 1.匹配任意单个字符
print(re.match('.', one).group()) # 8
# []字符集一个字符的集合可匹配其中任意一个字符
two = '234'
print(re.match('[0-9]', two).group()) # 2
three = 'HellO'
print(re.match('[Hh]', three).group()) # 同时匹配 H和 h
# H
free = '神州10号'
print(re.match(r'神州\d', free).group()) # \d 匹配数字
# 神州1
# search 返回第一个匹配的结果
print(re.search(r'\d', free).group()) # 1
6、转义字符
'\' 在正则表达式中使用反斜杠进行转义与其他的方法类似相同。
转义特殊字符允许你匹配 '*', '?', 或者此类其他字符或者表示一个特殊序列。
我们知道在Python中也存在反斜杠的转义字符其中我们还有更简便的方法就是原生字符。
如果没有使用原始字符串 r'raw' 来表达样式要牢记Python也使用反斜杠作为转义序列只有转义序列没有被Python的分析器识别反斜杠和字符才能出现在字符串中。如果Python可以识别这个序列那么反斜杠就应该重复两次。这会导致理解上非常的麻烦所以高度推荐使用原始字符串就算是最简单的表达式也要使用原始字符串。
代码
from re import match
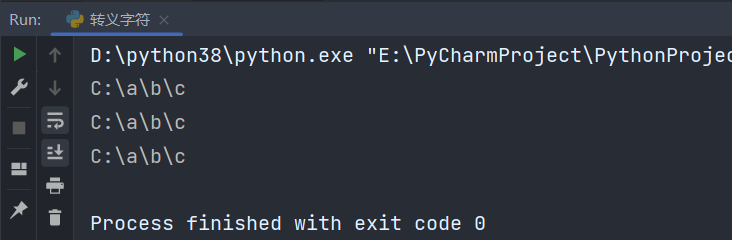
path = 'C:\\a\\b\\c' # 文件路径
print(path) # C:\a\b\c
print(match('C:\\\\a\\\\b\\\\c', path).group()) # C:\a\b\c
print(match(r'C:\\a\\b\\c', path).group()) # C:\a\b\c
我们可以看到 '\' 反斜杠转义字符在实际python字符串中是没有被转义的但是打印出来的结果中被进行了转义由我们的python解释器进行转义字符我们了解到正则表达式中的转义字符也与python中的转义字符类似的规则。
7、表示数量
匹配多个字符的相关格式
| 字符 | 功能 |
|---|---|
| * | 匹配前一个字符出现0次或者无限次即可有可无 |
| + | 匹配前一个字符出现1次或者无限次即至少有1次 |
| ? | 匹配前一个字符出现1次或者0次即要么有1次要么没有 |
| {m} | 匹配前一个字符出现m次 |
| {m,} | 匹配前一个字符至少出现m次 |
| {m,n} | 匹配前一个字符出现从m到n次 |
* 匹配前一个字符出现0次或者无限次及可有可无
# 需求1匹配一个字符串第一个字符字母大写后面的字母必须是小写或者没有
# * 匹配前一个字符出现0次或者无限次及可有可无
print(match('[A-Z][a-z]*', 'H').group()) # match 从第一个字符开始匹配 没有返回值为None
print(match('[A-Z][a-z]*', 'Hello').group()) # Hello
print(match('[A-Z][a-z]*', 'HelloWorld').group()) # Hello
+ 匹配前一个字符出现1次或者无限次即至少有1次
# + 匹配前一个字符出现1次或者无限次即至少有1次
print(match('[A-Z]+[a-z]*', 'Mm').group()) # Mm
print(match('[A-Z]+[a-z]*', 'MHHmf').group()) # MHHmf
\w 匹配数字、字母、下划线中任意一个字符 相当于 [a-zA-Z0-9_]
# 需求2:匹配一个变量名,必须以字母开头
# \w 匹配数字、字母、下划线中任意一个字符 相当于 [a-z A-Z 0-9 _]
print(match('[a-zA-Z][\\w]*', 'AADame1').group())
print(match(r'[a-zA-Z]+[\w]*', 'SFGame1__23').group())
? 匹配前一个字符出现1次或者0次即要么有1次要么没有
# 需求3:匹配从0-99之间的任意一个数字
# ? 匹配前一个字符出现1次或者0次即要么有1次要么没有
print(match('[0-5]?[1-9]', '6').group()) # 6
print(match('[0-5]?[1-9]', '46').group()) # 46
{m,n}匹配前一个字符出现从m到n次
# 需求4:匹配密码8-20位可以是 字母 数字 下划线
# {m,n}匹配前一个字符出现从m到n次
print(match('[\\w]{8,20}', '1234567dfkgf_').group()) # 1234567dfkgf_
# {m}匹配前一个字符出现m次
print(match('[\\w]{6}', '1234686789').group()) # 123468
# {m,}匹配前一个字符至少出现m次
print(match('[\\w]{6}', '1234686789').group()) # 123468
练习匹配163的邮箱地址 用户包含6~18个字符可以是字母数字下划线但是必须以字母开头
from re import match
# 练习5匹配163的邮箱地址 用户包含6~18个字符可以是字母数字下划线但是必须以字母开头
emails = """awhahlf@163.com
affafafafaaaaaaaaaaaaaaaa@163.com
afa_@163.com
225afafaf@163.com
aaaa____@qq.com
aaaa____@163.com"""
print(match('[A-Za-z][\\w]{5,17}@163\.com', emails).group()) # awhahlf@163.com
8、表示边界
限定开始与结尾的匹配
| 字符 | 功能 |
|---|---|
| ^ | 匹配开始位置多行模式下匹配每一行的开始(也有取反的意思区分应用场景) |
| $ | 匹配字符串结尾 |
| \b | 匹配一个单词的边界 |
| \B | 匹配非单词边界 |
'^' 用法
用法一: 限定开头
匹配字符串的开头 并且在 MULTILINE 模式也匹配换行后的首个符号
re.MULTILINE 设置以后样式字符 '^' 匹配字符串的开始和每一行的开始换行符后面紧跟的符号样式字符 '$' 匹配字符串尾和每一行的结尾换行符前面那个符号。默认情况下’^’ 匹配字符串头'$' 匹配字符串尾。
具体实现例子
# 导包
>>> import re
# 定义字符串害死邮箱的例子
>>> tel = '''
225afafaf@163.com
awhahlf@163.com
affafafafaaaaaaaaaaaaaaaa@163.com
afa_@163.com
225afafaf@163.com
aaaa____@qq.com
aaaa____@163.com
'''
# 生成正则表达式一个是带 ^ ,一个不带
>>> pattern1 = r"[a-zA-Z][\w_]{5,17}@163.com"
>>> pattern2 = r"^[a-zA-Z][\w_]{5,17}@163.com"
# 生成三个正则对象第一个是 正常写入的正则表达式第二个是带 ^ 限定的表达式第三个是带 ^ 限定的表达式且支持换行匹配
>>> single_line1 = re.compile(pattern1)
>>> single_line2 = re.compile(pattern2)
>>> multiline = re.compile(pattern2, re.MULTILINE)
# 使用三个已经生成好的匹配字符
>>> ret1 = re.search(single_line1, tel)
>>> ret2 = re.search(single_line2, tel)
>>> ret3 = re.search(multiline, tel)
# 第一种不带 ^ 匹配发现立即匹配到第二行的邮箱
>>> print(ret1.group())
afafaf@163.com
# 第二种带 ^ 匹配发现没有匹配到我们看到匹配限定不换行第一行匹配
>>> print(ret2)
None
# 第二种带 ^ 匹配发现没有匹配到我们看到匹配限定支持换行使用了re.MULTILINE换行匹配查到了afa_@163.com
# re.MULTILINE支持换行后接字符不能再接空格字符等
>>> print(ret3.group())
aaaa____@163.com
上面的例子我们看到了 ^ 与re.MULTILINE用法但是我们仔细来看 ^ 应用模式。
# 导包
>>> import re
# 新生成一个例子
>>> tel1 = 'awhahlf@163.comaffafafafaaaaaaaaaaaaaaaa@163.comafa_@163.com'
>>> tel2 = ' awhahlf@163.comaffafafafaaaaaaaaaaaaaaaa@163.comafa_@163.com'
# 第一行不存在空格我们使用相同的表达式匹配到了第一行第一个字符
>>> ret = re.search("^[a-zA-Z][\w_]{5,17}@163\.com", tel1)
>>> print(ret.group())
'awhahlf@163.com'
# 但是当我们第一行存在空格我们使用相同的表达式匹配不到对应的内容返回来一个空
>>> ret = re.search("^[a-zA-Z][\w_]{5,17}@163\.com", tel2)
>>> print(ret)
None
被限定字符也会受到空格换行等符号的影响所以在边界相关的内容中空格与换行等等这些会间接影响到结果的判断。
用法二取反
在某些特定的条件下^ 有存在取反的作用例如当我们使用[^0-9],这就是取反一个非数字的例子。
# 导包
>>> import re
# 需要筛选的字符
>>> tel = '123789'
# 使用字符,直接取反可以很直接的看到
>>> ret = re.search("[^0-9]", tel)
>>> print(ret)
None
# 但是将 ^ 从中括号中拿出来就是取出对应的开头匹配的值
>>> ret = re.search("^[0-9]", tel)
>>> print(ret.group())
1
很明显在对应的环境中 ^ 所显示的内容是取反的含义不过需要注意是在[ ]中括号字符集限定中。
'$' 用法
匹配字符串尾或者换行符的前一个字符当然换行符是在 MULTILINE 模式匹配换行符的前一个字符。
例如foo 可以匹配 'foo' 和 'foobar' , 但正则 foo$ 只匹配 'foo'。更有趣的是 在 'foo1\nfoo2\n' 搜索 foo.$ 通常匹配 'foo2' 但在 MULTILINE 模式 可以匹配到 'foo1' 在 'foo\n' 搜索 $ 会找到两个空串一个在换行前一个在字符串最后。
# 导包
import re
# 我们将匹配后缀信息此时我们没有进行限定结尾
>>> ret = re.match("[a-zA-Z][\w_]{5,17}@163\.com", "xiaoWang@163.com")
>>> ret.group()
'xiaoWang@163.com'
# 继续匹配后缀为163.comheihei这个如果是后缀增加那我们在筛选的时候就会存在一些问题因为实际上域名就已经不对了。
>>> ret = re.match("[a-zA-Z][\w_]{5,17}@163\.com", "xiaoWang@163.comheihei")
>>> ret.group()
'xiaoWang@163.com'
# 通过$来确定末尾
>>> ret = re.match("[a-zA-Z][\w_]{5,17}@163\.com$", "xiaoWang@163.comheihei")
>>> ret.group()
Traceback (most recent call last):
File "<pyshell#14>", line 1, in <module>
ret.group()
AttributeError: 'NoneType' object has no attribute 'group'
'\b' 用法
'\b' 匹配空字符串但只在单词开始或结尾的位置。一个单词被定义为一个单词字符的序列。注意通常 \b 定义为 \w 和 \W 字符之间或者 \w 和字符串开始/结尾的边界 意思就是 r'\bfoo\b' 匹配 'foo', 'foo.', '(foo)', 'bar foo baz' 但不匹配 'foobar' 或者 'foo3'。
这里就产生了一个概念单词与字符单词是一组词组而字符是包含单字符与多字符。
# 导入模块
import re
# 匹配 bver开头结尾的单词当然这里面在字符前面还包含了 '.*'号
>>> re.match(r".*\bver\b", "ho ver abc").group()
'ho ver'
# bver开头结尾的单词但是这里单词为 verabc 不符合筛选错误
>>> re.match(r".*\bver\b", "ho verabc").group()
Traceback (most recent call last):
File "<pyshell#20>", line 1, in <module>
re.match(r".*\bver\b", "ho verabc").group()
AttributeError: 'NoneType' object has no attribute 'group'
# bver开头结尾的单词但是这里单词为 hover 不符合筛选错误
>>> re.match(r".*\bver\b", "hover abc").group()
Traceback (most recent call last):
File "<pyshell#21>", line 1, in <module>
re.match(r".*\bver\b", "hover abc").group()
AttributeError: 'NoneType' object has no attribute 'group'
'\B' 用法
匹配空字符串但不能在词的开头或者结尾。意思就是 r'py\B' 匹配 'python', 'py3', 'py2', 但不匹配 'py', 'py.', 或者 'py!'. \B 是 \b 的取非所以Unicode样式的词语是由Unicode字母数字或下划线构成的虽然可以用 ASCII 标志来改变。如果使用了 LOCALE 标志则词的边界由当前语言区域设置
ASCII让 `\w`, `\W`, `\b`, `\B`, `\d`, `\D`, `\s` 和 `\S` 只匹配ASCII而不是Unicode。这只对Unicode样式有效会被byte样式忽略
LOCALE由当前语言区域决定 `\w`, `\W`, `\b`, `\B` 和大小写敏感匹配。这个标记只能对byte样式有效。这个标记不推荐使用因为语言区域机制很不可靠它一次只能处理一个 "习惯”而且只对8位字节有效。Unicode匹配在Python 3 里默认启用并可以处理不同语言
\B是区分于\b与之相对进行取反操作的
# 导包
>>> import re
# 相同的内容使用\B进行取反操作 匹配 ver 非包含开头结尾的单词当然这里面在字符前面还包含了 '.*'号
# 如果未加'.*'号也会报错注意思路取值是筛选单词与边界相关。
>>> re.match(r".*\Bver\B", "hoverabc").group()
'hover'
>>> re.match(r".*\Bver\B", "ho verabc").group()
Traceback (most recent call last):
File "<pyshell#25>", line 1, in <module>
re.match(r".*\Bver\B", "ho verabc").group()
AttributeError: 'NoneType' object has no attribute 'group'
# 相同的内容使用\B进行取反操作 匹配 bver 开头结尾的单词
>>> re.match(r".*\Bver\B", "hover abc").group()
Traceback (most recent call last):
File "<pyshell#26>", line 1, in <module>
re.match(r".*\Bver\B", "hover abc").group()
AttributeError: 'NoneType' object has no attribute 'group'
# 相同的内容使用\B进行取反操作 匹配 bver 开头结尾的单词
>>> re.match(r".*\Bver\B", "ho ver abc").group()
Traceback (most recent call last):
File "<pyshell#27>", line 1, in <module>
re.match(r".*\Bver\B", "ho ver abc").group()
AttributeError: 'NoneType' object has no attribute 'group'
\b与\B之间的区别是相互的互相的对立面一个单词让我们对这个单词进行头尾做对应的限定时。
\b更多的是针对整个被正则\b限定包含的单词在搜索的环境中是否存在对应的精准值再上方看到是使用了空格将独立的单词进行隔离包裹出完整的内容作为最后的取值结果标准。
\B相反是以非空格形式将我们的被正则\B限定包含的单词在搜索的环境中是否存在对应的再上方看到是使用了非空格将独立的单词进行隔离包裹出完整的内容作为最后的取值结果标准。
from re import search, match, MULTILINE
# 练习匹配163的邮箱地址 用户包含6~18个字符可以是字母数字下划线但是必须以字母开头
emails = '''flymeawei@163.com
affafafafaaaaaaaaaaaaaaaa@163.com
afa_@163.com 225afafaf@163.com
aaaa____@qq.com
aaaa____@163.comsd
awea____@163.com
'''
# 1.^ 匹配开始位置多行模式下匹配每一行的开始
# (也有取反的意思区分应用场景)
print(search('^[A-Za-z][\\w]{5,17}@163\.com', emails, MULTILINE).group()) # MULTILINE 对多行字符串
# flymeawei@163.com
# ^ 取反 加在[]里面 [^0-9]非数字
print(match('[^0-9]*', 'fid77af43').group()) # fid
print(match('^[0-9]*', '56fid77af43').group()) # 56
# $ 2.匹配字符串结尾
print(search('^[A-Za-z][\\w]{5,17}@163\.com$', emails, MULTILINE).group()) # awea____@163.com
# \b 3.匹配一个单词的边界
print(search('\\bkunming\\b', 'I love kunming too').group()) # kunming
# \B 4.不以单词边界匹配
print(search(r'\bkunming\B', 'hah kunminghah').group()) # kunming
9、表示分组
分组组合操作
| 字符 | 功能 |
|---|---|
| | | 匹配左右任意一个表达式 |
| (ab) | 将括号中字符作为一个分组 |
| \number | 匹配和前面索引为number的分组捕获到的内容一样的字符串 |
(?P<name>) | 分组起别名 |
| (?P=name) | 引用别名为name分组匹配到的字符串 |
’ | ’ 用法
A|B A 和 B 可以是任意正则表达式创建一个正则表达式匹配 A 和 B. 任意个正则表达式可以用 '|' 连接。(它也可以在组合内使用)。扫描目标字符串时 '|' 分隔开的正则样式从左到右进行匹配。当一个样式完全匹配时这个分支就被接受。意思就是一旦 A 匹配成功 B 就不再进行匹配即便它能产生一个更好的匹配。或者说'|' 操作符绝不贪婪。 如果要匹配 '|' 字符使用 \| 或者把它包含在字符集里比如 [|]
可以看一个例子匹配出0-100之间的数字
import re
# 1.匹配0-100的数字
# | 或 匹配左右任意一个表达式
print(re.match('[1-9]?\d$|100', '100').group()) # 100
print(re.match('[1-9]?\d$|100', '1').group()) # 1
print(re.match('[1-9]?\d$|100', '10').group()) # 10
'()' 用法
组合匹配括号内的任意正则表达式并标识出组合的开始和结尾。匹配完成后组合的内容可以被获取并可以在之后用 \number 转义序列进行再次匹配之后进行详细说明。要匹配字符 '(' 或者 ')', 用 \( 或 \), 或者把它们包含在字符集合里: [(], [)].
直接来看代码
# 导包
>>> import re
# 这里常规测试邮箱无边界限定匹配正常
>>> ret = re.match("\w{4,20}@163\.com", "test@163.com")
>>> ret.group()
'test@163.com'
# 在括弧中加入了分支进行判断根据结果判断也匹配到结果
>>> ret = re.match("\w{4,20}@(163|126|qq)\.com", "test@126.com")
>>> ret.group()
'test@126.com'
# 如法炮制在匹配对应的分支判断下在小括号中的分支留下对应的其中一组结果。
>>> ret = re.match("\w{4,20}@(163|126|qq)\.com", "test@qq.com")
>>> ret.group()
'test@qq.com'
# 只有当不在对应的值内匹配即存在无法识别的问题
>>> ret = re.match("\w{4,20}@(163|126|qq)\.com", "test@gmail.com")
>>> ret.group()
Traceback (most recent call last):
File "<pyshell#8>", line 1, in <module>
ret.group()
AttributeError: 'NoneType' object has no attribute 'group'
'\number' 用法
上面说到在分组中可以只用 \number 进行转义操作。
了解 \ 可以调节转义字符但是当后面加上数字则存在特殊序列由 '\' 和一个字符组成的特殊序列。
匹配数字代表的组合。每个括号是一个组合组合从1开始编号。比如 (.+) \1 匹配 'the the' 或者 '55 55', 但不会匹配 'thethe' (注意组合后面的空格)。这个特殊序列只能用于匹配前面99个组合。如果 number 的第一个数位是0 或者 number 是三个八进制数它将不会被看作是一个组合而是八进制的数字值。在 '[' 和 ']' 字符集合内任何数字转义都被看作是字符。
例如我这里有个内容需要匹配出<html>hh</html>这种标签我想熟悉的话已经写出来了看代码。
# 需求3 匹配<标签>xxx<标签> + 一次或多次
print(re.match(r'^<[a-zA-Z]+>\w*</[a-zA-Z]+>', '<P>hello</P>').group())
print(re.match(r'^<[a-zA-Z]+>\w*</[a-zA-Z]+>', '<p>hello</div>').group())
print(re.match(r'^<[a-zA-Z]+>\w*</[a-zA-Z]+>', '<div>hello</div>').group())
# \number 匹配和前面索引为number的分组捕获到的内容一样的字符串
print(re.match(r'^<([a-zA-Z]+)>.*</\1>', '<p>hello</p>').group())
# 第二种 匹配一个网页嵌套标签
# (?P<name>) 分组起别名
line = '<div><p>hellO</p></div>'
print(re.match(r'<(?P<n1>[a-zA-Z]*)>.*<(?P<n2>\w*)>.*</(?P=n2)></(?P=n1)>', line).group())
# line2 = '<div><p>hellO</h></div>'
# print(re.match(r'<(?P<n1>\w*)><(?P<n2>\w*)>.*</(?P=n2)></(?P=n1)>', line2).group())
'(?P<name>) (?P=name)' 用法
?P<要起的别名>(?P=起好的别名)
(?P<name>)命名组合类似正则组合但是匹配到的子串组在外部是通过定义的 name 来获取的。组合名必须是有效的Python标识符并且每个组合名只能用一个正则表达式定义只能定义一次。一个符号组合同样是一个数字组合就像这个组合没有被命名一样。
命名组合可以在三种上下文中引用。如果样式是 (?P<quote>['"]).*?(?P=quote) 也就是说匹配单引号或者双引号括起来的字符串)
| 引用组合 “quote” 的上下文 | 引用方法 |
|---|---|
| 在正则式自身内 | (?P=quote) (如示)\1 |
| 处理匹配对象 m | m.group('quote')``m.end('quote') (等) |
传递到 re.sub() 里的 repl 参数中 | \g<quote>``\g<1>``\1 |
(?P=name) 反向引用一个命名组合它匹配前面那个叫 name 的命名组中匹配到的串同样的字串。
# 导包
>>> import re
s = '<html><h1>我是一号字体</h1></html>'
# pattern = r'<(.+)><(.+)>.+</\2></\1>'
#如果分组比较多的话数起来比较麻烦可以使用起别名的方法?P<要起的名字> 以及使用别名(?P=之前起的别名)
pattern = r'<(?P<key1>.+)><(?P<key2>.+)>.+</(?P=key2)></(?P=key1)>'
v = re.match(pattern,s)
print(v)
# 进行通过别名的方法解决问题
>>> ret = re.match(r"<(?P<name1>\w*)><(?P<name2>\w*)>.*</(?P=name2)></(?P=name1)>", "<html><h1>www.mashibin.com</h1></html>")
>>> ret.group()
'<html><h1>www.mashibin.com</h1></html>'
# 这里起了别名但是针对匹配的对应的字符串并没有对应的内容无法完成匹配所以错误
>>> ret = re.match(r"<(?P<name1>\w*)><(?P<name2>\w*)>.*</(?P=name2)></(?P=name1)>", "<html><h1>www.mashibin.com</h2></html>")
>>> ret.group()
Traceback (most recent call last):
File "<pyshell#4>", line 1, in <module>
ret.group()
AttributeError: 'NoneType' object has no attribute 'group'
注意(?P<name>)和(?P=name)中的字母p大写
10、RE模块高级使用
import re
# 1. findall 查找所有
emails = '''awhahlf@163.com
affafafafaaaaaaaaaaaaaaaa@163.com
afa_@163.com 225afafaf@163.com
aaaa____@qq.com
aaaa__1__@126.com
awea____@163.com
'''
# findall 查找所有
lst = re.findall(r'(^[a-zA-Z][\w]{5,17}@(163|126)\.com$)', emails, re.MULTILINE)
print(lst[0], lst[1])
# 需求匹配一个数字把匹配结果的数字加一返回
def add(result): # result 表示一个匹配对象
str_num = result.group()
num = int(str_num) + 1
return str(num)
# sub
print(re.sub(r'\d+', add, 'python=187'))
# split
line = 'hello, world;kunming. '
print(re.split(r'\W+', line))
# 按照:h和空格字符串进项分割
print(re.split(r':| ', 'info:xiaoZhang 33 shandong'))
11、贪婪与非贪婪业务默认也是贪婪的去匹配查询
-
什么是贪婪模式
Python里数量词默认是贪婪的 总是尝试匹配尽可能多的字符
*+{m,n}。 -
什么是非贪婪
与贪婪相反总是尝试匹配尽可能少的字符可以使用"*","?","+","{m,n}"后面加上使贪婪变成非贪婪。
# 贪婪模式.+中的'.'会尽量多的匹配
>>> import re
# 我们需要的结果中相比符合规范在限定类型数据是我们会将特定需要的一些字符做一些匹配
# 例如下面的更好的是将电话与描述之间进行分割筛选我们存在使用进行了两组分组但实际匹配没变知识理清规则
>>> ret = re.match(r'(.+)(\d+-\d+-\d+)','This is my tel:133-1234-1234')
>>> print(f'{ret.group(1)}, {ret.group(2)}')
This is my tel:13, 3-1234-1234
# 这里我们通过进行将贪婪转换成非贪婪模式
>>> ret = re.match(r'(.+?)(\d+-\d+-\d+)','This is my tel:133-1234-1234')
>>> print(f'{ret.group(1)}, {ret.group(2)}')
This is my tel:, 133-1234-1234
正则表达式模式中使用到通配字那它在从左到右的顺序求值时会尽量“抓取”满足匹配最长字符串在我们上面的例子里面“.+”会从字符串的启始处抓取满足模式的最长字符其中包括我们想得到的第一个整型字段的中的大部分“\d+”只需一位字符就可以匹配所以它匹配了数字“4”而“.+”则匹配了从字符串起始到这个第一位数字4之前的所有字符。
解决方式非贪婪操作符“”这个操作符可以用在"*","+","?"的后面要求正则匹配的越少越好。
练习
# 1、验证账号是否合法(字母开头允许5-16字节允许字母数字下划线)。
^[a-zA-Z][a-zA-Z0-9_]{4,15}$
# 2、验证密码是否合法(以字母开头长度在6~18之间只能包含字母、数字和下划线)
^[a-zA-Z][a-zA-Z0-9_]{5,17}$
# 3、匹配是否全是汉字
^[\u4E00-\u9FA5]+$
# 4、验证日期格式2020-09-10
\d{4}-\d{2}-\d{2}
# 5、验证身份证号码。
^[1-9]\d{7}((0\d)|(1[0-2]))(([0|1|2]\d)|3[0-1])\d{3}$|^[1-9]\d{5}[1-9]\d{3}((0\d)|(1[0-2]))(([0|1|2]\d)|3[0-1])\d{3}([0-9]|X)$
"""
1、验证账号是否合法(字母开头允许5-16字节允许字母数字下划线)。
2、验证密码是否合法(以字母开头长度在6~18之间只能包含字母、数字和下划线)
3、匹配是否全是汉字
4、验证日期格式2020-09-10
5、验证身份证号码。
"""
import re
# 1.验证账号是否合法(字母开头允许5-16字节允许字母数字下划线)。
print(re.match(r'^[a-zA-z]\w{4,15}$', 'a3443wre5678rfgh').group()) # a3443wre5678rfgh
# 2、验证密码是否合法(以字母开头长度在6~18之间只能包含字母、数字和下划线)
print(re.match(r'^[a-zA-Z]\w{5,17}$', 'd697g798bv9d44444e').group()) # d697g798bv9d44444e
# 3.匹配是否全是汉字
print(re.match('^[\u4e00-\u9fa5]{0,}$', '哈哈').group()) # 哈哈
# 4.验证日期格式2020-09-10)
print(re.match(r'^\d{4}-\d{2}-\d{2}$', '2020-09-10').group()) # 2020-09-10
# 5.验证身份证号码。
print(re.match(r'^[1-9]\d{7}((0\d)|(1[0-2]))(([0|1|2]\d)|3[0-1])\d{3}$|^[1-9]\d{5}[1-9]\d{3}((0\d)|(1[0-2]))(([0|1|2]\d)|3[0-1])\d{3}([0-9]|X)$',
'533326200006013333').group()) # 533326200006013333