

Java之List详解
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
~ 前言
这是我技术板块的第一篇博客也是最简单的一篇。
为了照顾没有看过源码、或者阅读源码经验很少的同学这一篇文章会相对啰嗦一些会展现一些静态看源码的方式。
后续源码分析的文章会省略大部分基础内容所以如果您关注了我并期待后续的源码讲解那么请认真的查看这一篇的文章。
说明对于List我们这里只讲ArrayList与LinkedList。默认大家对于基本API已经熟悉使用。
后续讲解内容为源码实现这里使用的是JDK8的版本那么。。Link Start

ArrayList
如字面意思ArrayList是一个可变数组 的实现在源码中也有对应的体现。
// public ArrayList(int initialCapacity) 初始化时赋值为这个
private static final Object[] EMPTY_ELEMENTDATA = {};
// public ArrayList() 初始化时赋值为这个
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
// 这个是ArrayList内部存储数据的数组
// 一旦变量被transient修饰变量将不再是对象持久化的一部分
transient Object[] elementData;
然后我们来看一下它的关系图
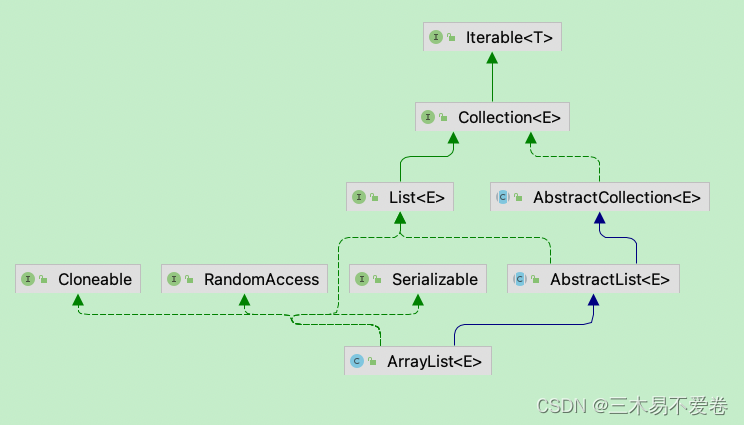
通过关系图我们能清楚的看到它的实现:
- iterable可以使用迭代器
- collection有add、remove等方法
- cloneable可以克隆
- randomAccess可以快速随机访问(下标)
- serializable可以被序列化
~ 关于序列化
有的同学就要问了哈这个可以被序列化啊那为什么存数据的那个数组elementData被transient标识了呢
这是因为在序列化时会调用writeObject方法其中ArrayList实现了这个方法在这个方法里ArrayList自己处理了数据的序列化
for (int i=0; i<size; i++) {
s.writeObject(elementData[i]);
}
其中size表示的是已占用数据数组的长度。那么说回来这段代码有什么意义呢额。。如果这里没有想出来的同学就要扣大分了啊
我们都知道数组的长度是固定的(比如现在总长度为10)那么里面的数组可能不是满的(我现在只占用了6个格子)
如果我全部都进行序列化会浪费内存那么如果我只截取用到的长度就不会浪费内存了(只序列化6个那么就省下了4个格子的内存)。
到这里是不是又感受到我们和大佬的区别了。

接下来我们大概了解一下下面三个变量并对它们有一个印象。
// 修改次数
protected transient int modCount = 0;
// 记录数据长度
private int size;
// 数据默认长度
private static final int DEFAULT_CAPACITY = 10;
然后我们根据常用的API调用进入看源码的环节了
初始化
首先先回想一下我们使用它的方式,并进行简单分析一下
List list = new ArrayList();
第一种无参的构造方法,我们可以想到里面的数组会赋值一个默认数组
elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA // ={}
List list = new ArrayList(12);
第二种是一个数字参数的构造方法我们可以想到数据数组长度为12
elementData = new Object[12];
List list = new ArrayList(list1);
第三种是传入一个Collection参数的构造方法我们可以想到会将list1转为数组赋值给elementData并且将size设置为list1的长度
而在源码中的实现其实与我们分析的差不多但是其中可能多了一些容错的代码例如第三种。
public ArrayList(Collection<? extends E> c) {
Object[] a = c.toArray();
// 赋值size
if ((size = a.length) != 0) {
if (c.getClass() == ArrayList.class) {
elementData = a;
} else {
elementData = Arrays.copyOf(a, size, Object[].class);
}
} else {
// replace with empty array.
elementData = EMPTY_ELEMENTDATA;
}
}
~ 基本方法解析
首先我们每一个方法会先讲解一个案例再对其进行源码分析帮助大家更好的理解其中的逻辑。
size
public static void main(String[] args) {
List list = new ArrayList(12);
list.add(1);
list.add(2);
System.out.println(list.size());
}
输出: 2
public int size() {
return size;
}
返回的size也是让大家在上面记住的,是已经占用格子的个数,这里非常容易混淆
add
public static void main(String[] args) {
List list = new ArrayList();
list.add(1);
System.out.println(list);
}
输出: [1]
public boolean add(E e) {
ensureCapacityInternal(size + 1);
elementData[size++] = e;
return true;
}
我们可以看到调用了ensureCapacityInternal这个方法确定是否需要扩容参数为size+1。
我们可以先猜一下逻辑应该是当前size是否小于这个参数如果小于就需要扩容new一个新数组并将旧数据迁移到新数组中。

简单分析完后让我们进入这个方法仔细看一下
private void ensureCapacityInternal(int minCapacity) {
ensureExplicitCapacity(calculateCapacity(elementData, minCapacity));
}
private static int calculateCapacity(Object[] elementData, int minCapacity) {
// 检测数据是否为空
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
// 从默认值(10)与传入参数中选择最大的数进行返回
return Math.max(DEFAULT_CAPACITY, minCapacity);
}
return minCapacity;
}
private void ensureExplicitCapacity(int minCapacity) {
// 更新数自增
modCount++;
// 如果已经无法添加元素了(数组已满)就进行扩容
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
private void grow(int minCapacity) {
int oldCapacity = elementData.length;
// 默认扩容1.5倍
int newCapacity = oldCapacity + (oldCapacity >> 1);
// 最大值溢出处理
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
// 没有溢出就为int最大值
newCapacity = hugeCapacity(minCapacity);
// 转移数据
elementData = Arrays.copyOf(elementData, newCapacity);
}
以上就是ensureCapacityInternal这个方法的调用链路最后就是进行数组赋值。
最后简单描述一下流程:
- 确定数组最小的大小是10
- 检测数组是否还可以放下元素
** 可以就直接返回
** 需要扩容就调用扩容方法扩容并进行数据转移- 往数组下一个index添加值
remove
public static void main(String[] args) {
List list = new ArrayList();
list.add(1);
list.add(2);
list.remove(0);
System.out.println(list);
}
输出: [2]
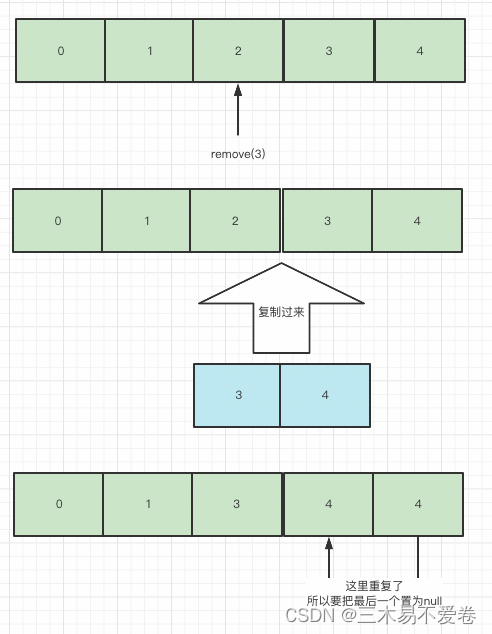
public E remove(int index) {
// 检测index范围是否合法
rangeCheck(index);
modCount++;
// 获取久值即要移除的值
E oldValue = elementData(index);
// 查看index后面是否还有元素
int numMoved = size - index - 1;
// 如果后面还有元素就将后面的元素copy一份并覆盖到index处
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index, numMoved);
// 清除最后一个值使GC能够回收它
elementData[--size] = null;
return oldValue;
}
我们这里就不一步一步分析了具体步骤已经在上面的代码部分标明。可能有些小伙伴看到
System.arraycopy 这一段有一点懵可以直接看下面的图就可以了。
iterator
public static void main(String[] args) {
List list = new ArrayList();
list.add(1);
list.add(2);
Iterator iterator = list.iterator();
while (iterator.hasNext()) {
System.out.println(iterator.next());
// list.add(3);
}
}
输出1 2
如果去掉注释list.add(3);会报错如下:
Exception in thread "main" java.util.ConcurrentModificationException
at java.util.ArrayList$Itr.checkForComodification(ArrayList.java:911)
at java.util.ArrayList$Itr.next(ArrayList.java:861)
at com.example.test.main(test.java:16)
然后我们先看一下它的实现再详细解析。
public Iterator<E> iterator() {
return new Itr();
}
private class Itr implements Iterator<E> {
// 下一个遍历index
int cursor;
// 上一次迭代过程的索引位置
int lastRet = -1;
int expectedModCount = modCount;
Itr() {}
public boolean hasNext() {
return cursor != size;
}
@SuppressWarnings("unchecked")
public E next() {
checkForComodification();
int i = cursor;
// 超出长度
if (i >= size)
throw new NoSuchElementException();
Object[] elementData = ArrayList.this.elementData;
if (i >= elementData.length)
throw new ConcurrentModificationException();
// 游标指向下一个index
cursor = i + 1;
// 返回值
return (E) elementData[lastRet = i];
}
public void remove() {
// 可能连续调用remove
if (lastRet < 0)
throw new IllegalStateException();
checkForComodification();
try {
// 移除并重置游标
ArrayList.this.remove(lastRet);
cursor = lastRet;
lastRet = -1;
expectedModCount = modCount;
} catch (IndexOutOfBoundsException ex) {
throw new ConcurrentModificationException();
}
}
// 确保没有人修改了原来的集合
final void checkForComodification() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
}
}
从上面的源码与注释我们得知以下信息:
- cursor总是指向下一个遍历index就是说总是在当前index+1, lastRet为上一次迭代过程的索引位置即调用next()返回值的index或为-1。
- 每次调用next()方法都会先调用 checkForComodification()检查。
- 当调用remove()后lastRet为-1
那么当我们理清获得的信息后再次查看案例分析它的代码就可以很简单的理清它的思路了。接下来我们用图来理解一下。
假如当我们调用iterator()方法时初始化为以下参数。
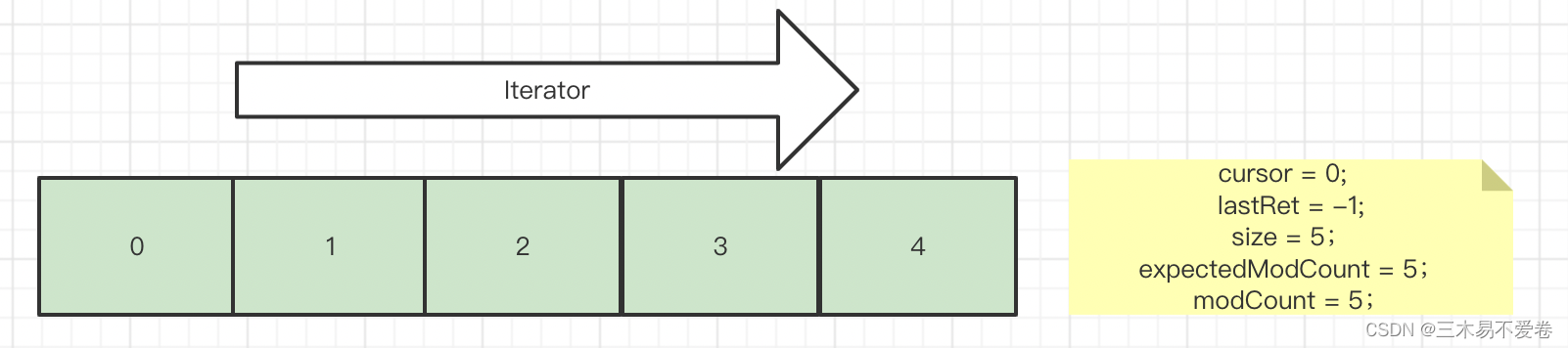
那么调用next()时参数和数组会出现以下变化此时返回的数组指针为第一个。
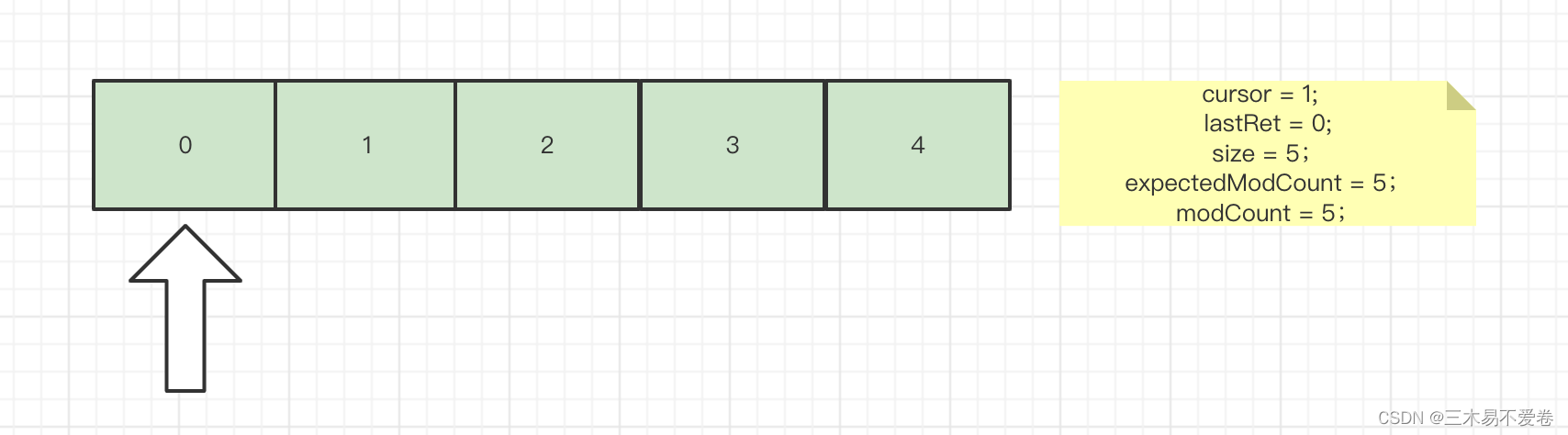
这时当我们调用iterator方法的remove()方法时会真正删除一个元素并重新赋值指向与modcount。
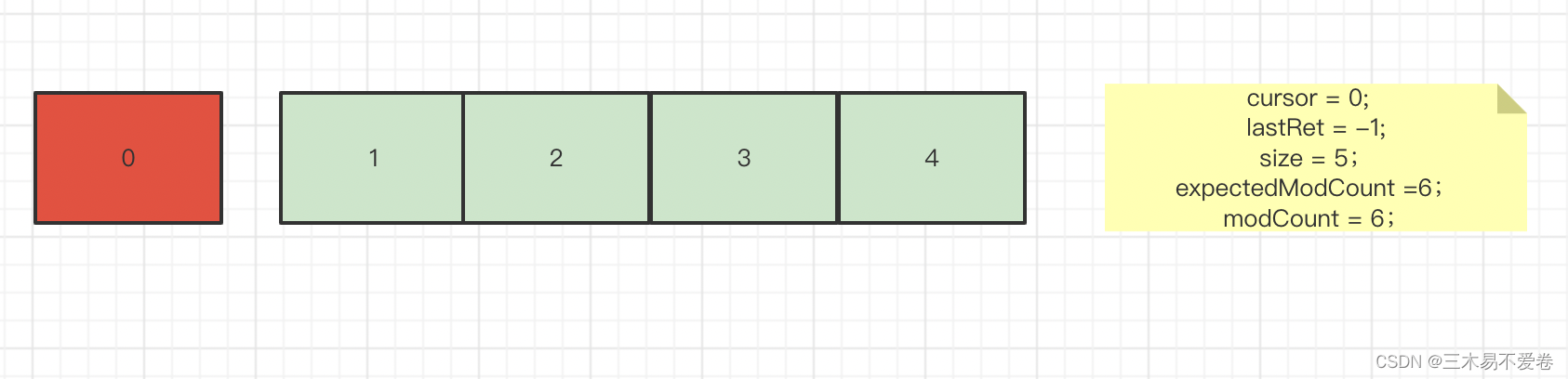
讲到这里可能有些朋友发现了这个调用remove并没有报出错误啊怎么与上面的例子不一样呢
如果细心一点可以发现我们这里调用的是返回iterator对象的remove()方法而例子中是直接对list本身进行的remove()。
不管是list本身的add方法还是remove方法都会修改modcount的值在iterator的方法中都会调用checkForComodification方法来检测
一开始的modcount(expectedModCount)与list本身的modcount是否相同。这样做的目的是防止有人更改了list本身导致迭代数据不一致的问题。
哎这里是不是有点绕应该怎么解释才好理解一点呢
那我在这里举一个简单例子。单线程环境下有一个4个元素的list我使用了迭代器(iterator)指针指向第三个元素。
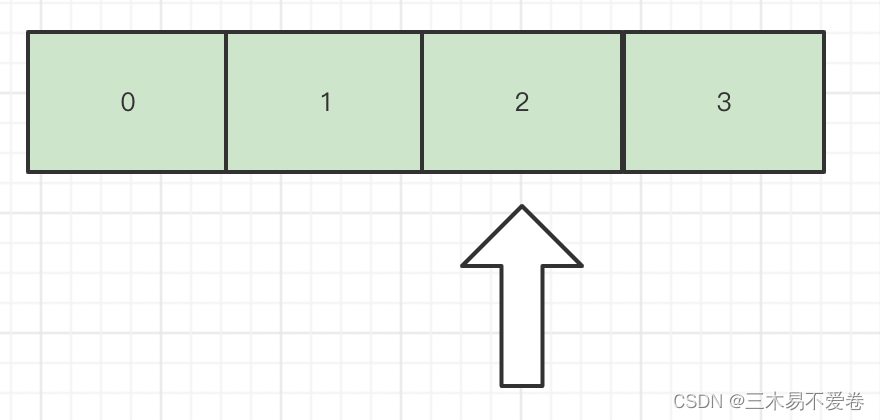
然后我对list本身remove了一个元素。这时指针因为remove()方法往前移动了一个元素我现在的指针实际是指向了最后一个元素。
而这时指针已经遍历完这个元素需要往后走一位时发现少了一个元素。并且数据无法全部遍历完成
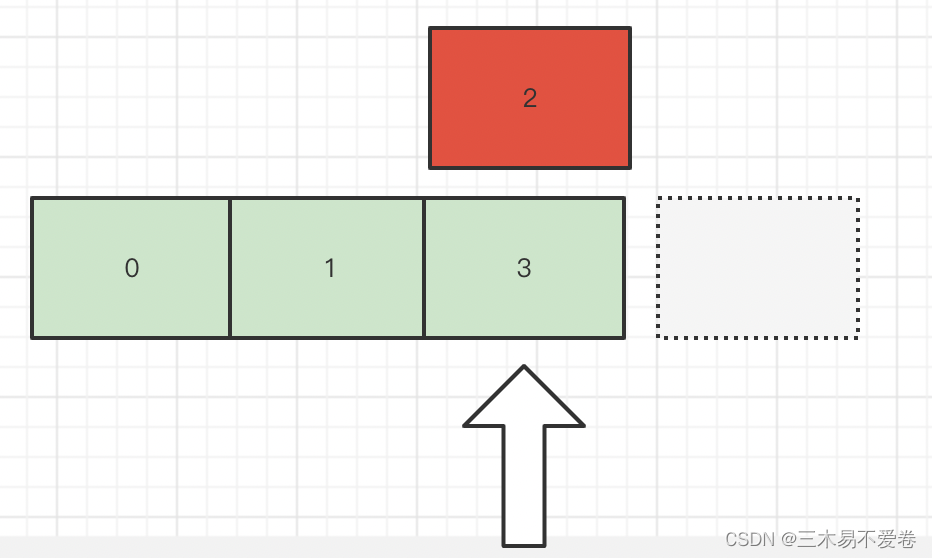
除此之外在多线程下ArrayList是非安全性这时当线程出现不安全时modcount的作用可以使它快速失败(fail-fast)
LinkedList
LinkedList是一个理论只受限于内存大小的链表 实现就是说链表的长度只受限于你机器内存的大小。
它是一个双向链表按照单一原则使用Node包装了指针的信息与数据的内容。
// 指针头表示第一个节点
transient Node<E> first;
// 指针尾表示最后一个节点
transient Node<E> last;
// node节点包装
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
然后我们看一下它的关系图
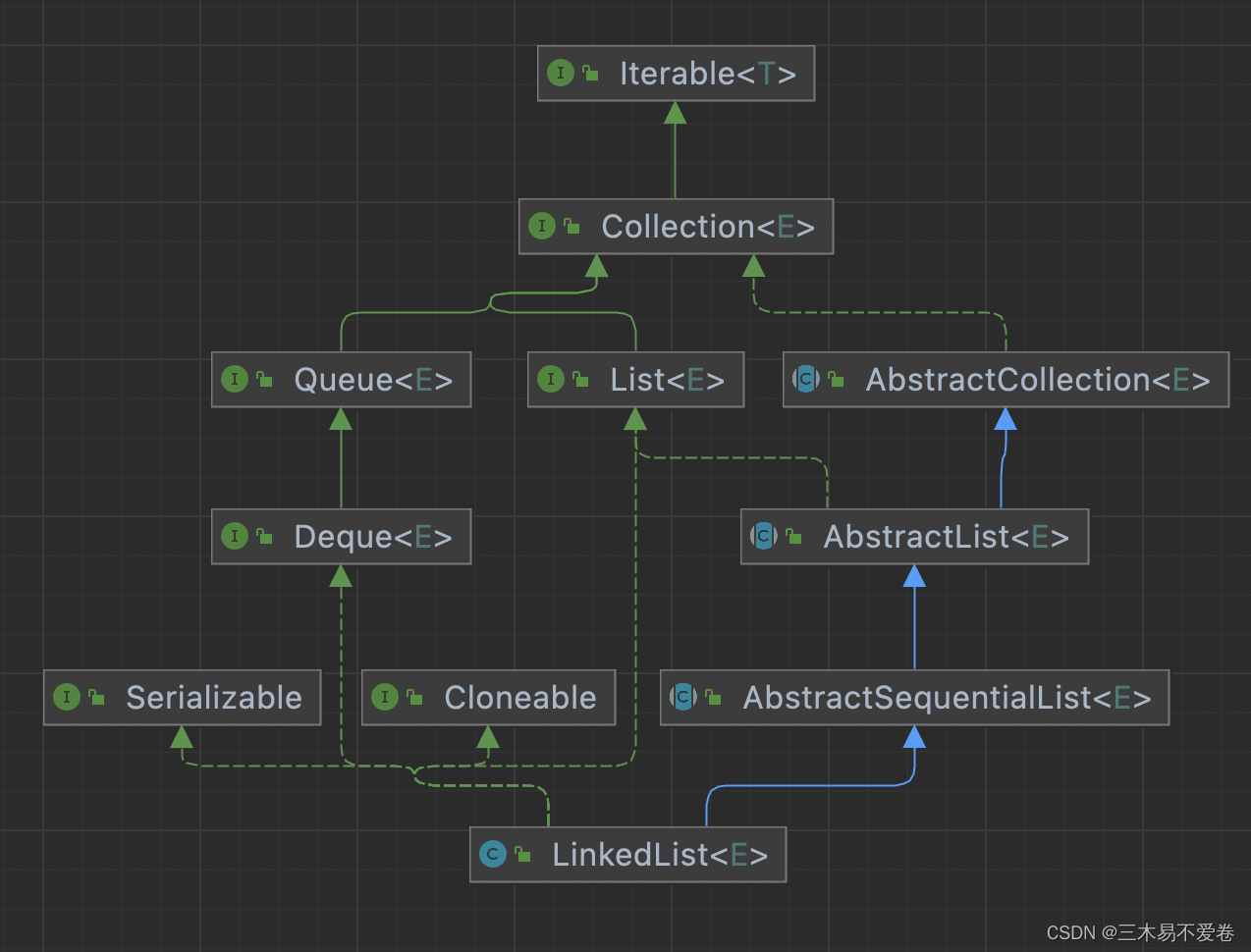
大致与ArrayList相同不过LinkedList实现了Deque说明是一个双端队列。它和ArrayList一样实现了自己序列化数据的方法。
~ 初始化
前面有说到它只受限于内存大小所以不会存在扩容的方法所以也不需要提供设置初始链表大小的方法。
public LinkedList() {
}
public LinkedList(Collection<? extends E> c) {
this();
addAll(c);
}
所以我们这里主要看第二个初始化方法的addAll方法如何将已有元素列表添加到LinkedList中
在开始看之前我们照例先进行猜想如何实现的再进去验证我们的想法是否相同这里我就直接跳过了。
public boolean addAll(Collection<? extends E> c) {
// size为当前链表长度
return addAll(size, c);
}
public boolean addAll(int index, Collection<? extends E> c) {
// 检测size是否合法
checkPositionIndex(index);
// 没有元素就直接返回了
Object[] a = c.toArray();
int numNew = a.length;
if (numNew == 0)
return false;
// 插入位置的前面一个后面一个
Node<E> pred, succ;
if (index == size) {
// index是往最后插入所以index的下一个是null
succ = null;
pred = last;
} else {
succ = node(index);
pred = succ.prev;
}
for (Object o : a) {
@SuppressWarnings("unchecked") E e = (E) o;
Node<E> newNode = new Node<>(pred, e, null);
// 如果index的前一个是空说明链表没有元素那么头节点就是新元素
if (pred == null)
first = newNode;
else
// 往后插
pred.next = newNode;
pred = newNode;
}
if (succ == null) {
last = pred;
} else {
pred.next = succ;
succ.prev = pred;
}
// 更新信息
size += numNew;
modCount++;
return true;
}
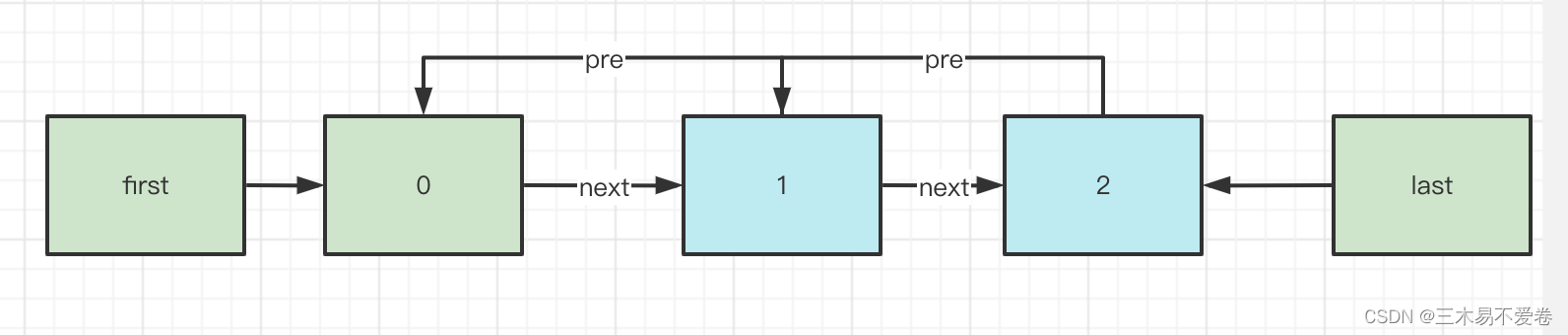
接下来让我们直接通过图来理解吧。
调用上面的代码就是需要将蓝色的数组内容加入到绿色的LinkedList中这里我们假设LinkedList是有元素的。

那么经过addAll方法后改变它的结构
如果原来LinkedList没有元素会变成什么样呢
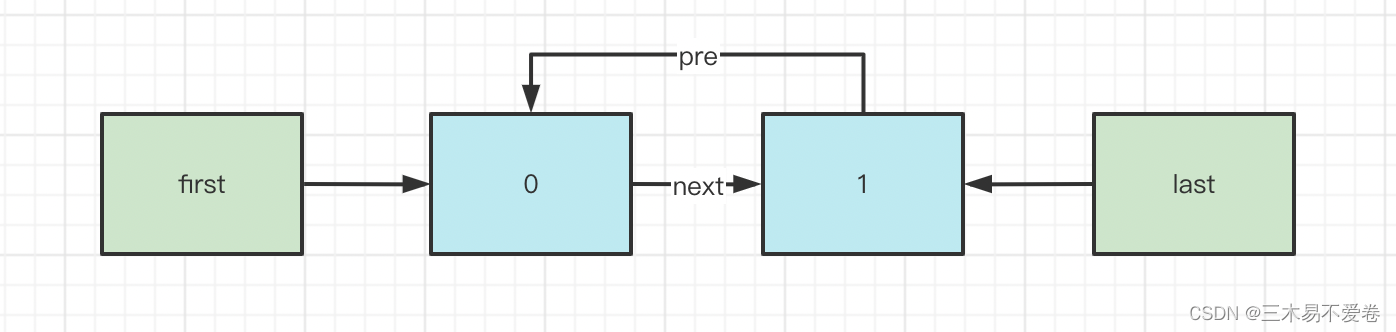
所以总结一下对于这个链表来说改变元素我们只要对数据节点的pre指针与next指针进行维护即可
但是也要注意first与last节点的标识即可。
基本方法解析
前面的ArrayList已经讲解过如何静态看源码的方法了所以这里我们就加快速度。
add
public boolean add(E e) {
linkLast(e);
return true;
}
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
// last为空说明原本链表没有元素那么新增的元素就是第一个也是最后一个
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}
原本没有元素就维护first指针与last指针指向即可如果有元素就往最后一个元素后面插入
这时候需要维护最后一个元素的下一个指针指向新元素新元素的上一个指针指向最后一个指针
这是就已经插入完成了但是这是新元素变成了最后一个了所以last指针要指向新元素。
remove
public boolean remove(Object o) {
// 从头遍历到结尾
if (o == null) {
for (Node<E> x = first; x != null; x = x.next) {
if (x.item == null) {
unlink(x);
return true;
}
}
} else {
for (Node<E> x = first; x != null; x = x.next) {
if (o.equals(x.item)) {
unlink(x);
return true;
}
}
}
return false;
}
E unlink(Node<E> x) {
// 维护指针向
final E element = x.item;
final Node<E> next = x.next;
final Node<E> prev = x.prev;
if (prev == null) {
first = next;
} else {
prev.next = next;
x.prev = null;
}
if (next == null) {
last = prev;
} else {
next.prev = prev;
x.next = null;
}
x.item = null;
size--;
modCount++;
return element;
}
这里是维护指针方式与add相同所以就不重复讲了。
get
public E get(int index) {
checkElementIndex(index);
return node(index).item;
}
Node<E> node(int index) {
// 二分法
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
这里也很简单就是遍历就可以了当然这里也有一个有趣的地方如上面注释标注的地方使用了二分法去减少了一半遍历的时间
因为index是有序的其中原理也很简单。比如有100个元素我要找第60个怎么办
那么我先除一半为5060大于50所以在100的右边一半即(50-100),所以我从尾节点开始遍历即可。
set
public E set(int index, E element) {
checkElementIndex(index);
Node<E> x = node(index);
E oldVal = x.item;
x.item = element;
return oldVal;
}
我们可以看到这个先调用了node方法找到插入节点位置的Node再进行赋值node方法在get方法中已经讲到了这里就不重复了。
~ 总结
讲到这里已经把ArrayList和LinkedList基本api的源码讲解完了虽然很简单但是也有需要可以借鉴的地方。
比如非线程安全的ArrayList使用了modcount来对比前后的值保证快速失败。
自己实现了数据的序列化减少内存的空间浪费。LinkedList中的二分法减少遍历数等等。
ArrayList与LinkedList对比
我们看完了源码那么我们来对比着来看一下着两个类吧。
- ArrayList是由数组实现的并且需要扩容(如果数据很大那么扩容复制数组开销大)最大容量为int的最大值。LinkedList是由链表实现的里面由一个一个Node组成不需要扩容但是需要维护指针最大容量只受物理机器的内存限制。
- ArrayList由于其数组特性是一片连续空间可以快速随机访问(下标访问)。而LinkedList只由指针连接跨越多个地址查找起来需要遍历链表如果严重可能需要遍历全链表的数据。
- ArrayList插入与删除需要将后续的数据复制到前面index但是LinkedList只需要修改指针的指向即可。
- ArrayList与LinkedList对尾插入时性能几乎一致对查询头尾数据或index靠近头尾的数据查询几乎一致。
静态看源码方法总结
- 看源码前请先了解基本API的使用与一些简单的原理。
- 先分析我最关注的点是什么例如我需要了解这个API的功能那么就请直接跳到这个API先看官方注释不要浪费时间在其他点上。
- 分析它的关系图、继承哪些类、实现了哪些类然后直接走主线逻辑那些一堆补充逻辑的尽量跳过它。
- 进去方法前根据方法名与参数多猜它是如何实现的只有多猜多动脑你才能带入开发这个程序的思维当中。
- 看完后总结我的思维与开发者思维实现的区别提取可以借鉴的要素。
- 三次看源码第一次走主线与猜第二次画流程图再走一次主线第三次可以稍微看一些补充逻辑记得只有实在走不通再使用调试的方式否则都以静态的方式去查看源码因为有一些项目是有很多回调的如果都以调试的方式去看源码真的会裂开的
最后
看源码我们不仅要了解API的实现也要提取借鉴点用在我们的业务当中多看多学才不会过后就忘了。

当然还有很多快速看源码的方法这里一次讲不完后面文章中再慢慢补充都讲完后我会专门出一篇来说明如何有效率过脑子的看源码教程。
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |