Hadoop3集群搭建
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
Hadoop3集群搭建
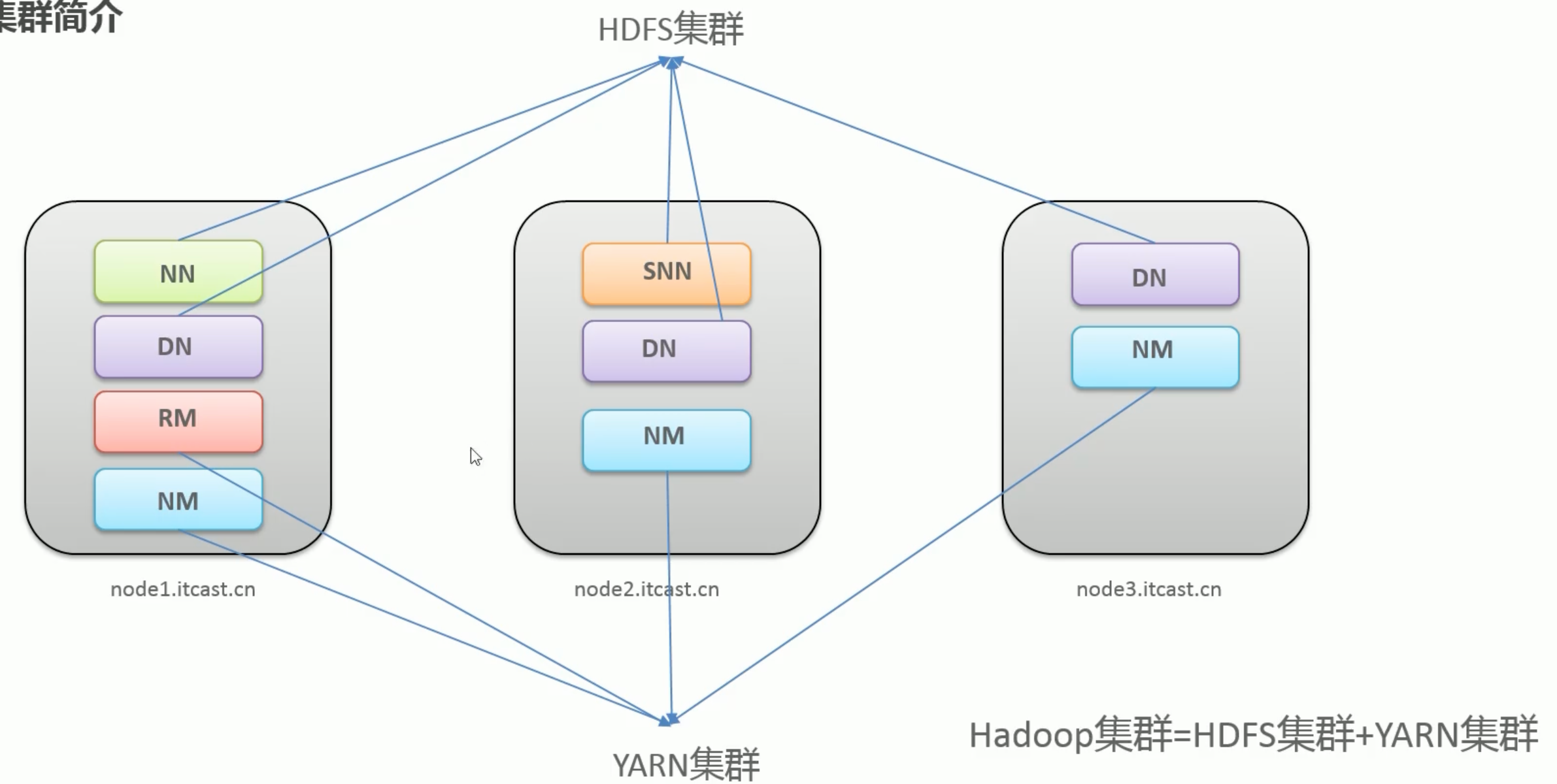
Hadoop集群简介
HDFS集群
作用分布式存储
主角色NameNode
从角色DataNode
主角色辅助角色SecondaryNameNode相当于主角色NameNode的秘书
YARN集群
作用资源管理、调度
主角色ResourceManager
从角色NodeManager




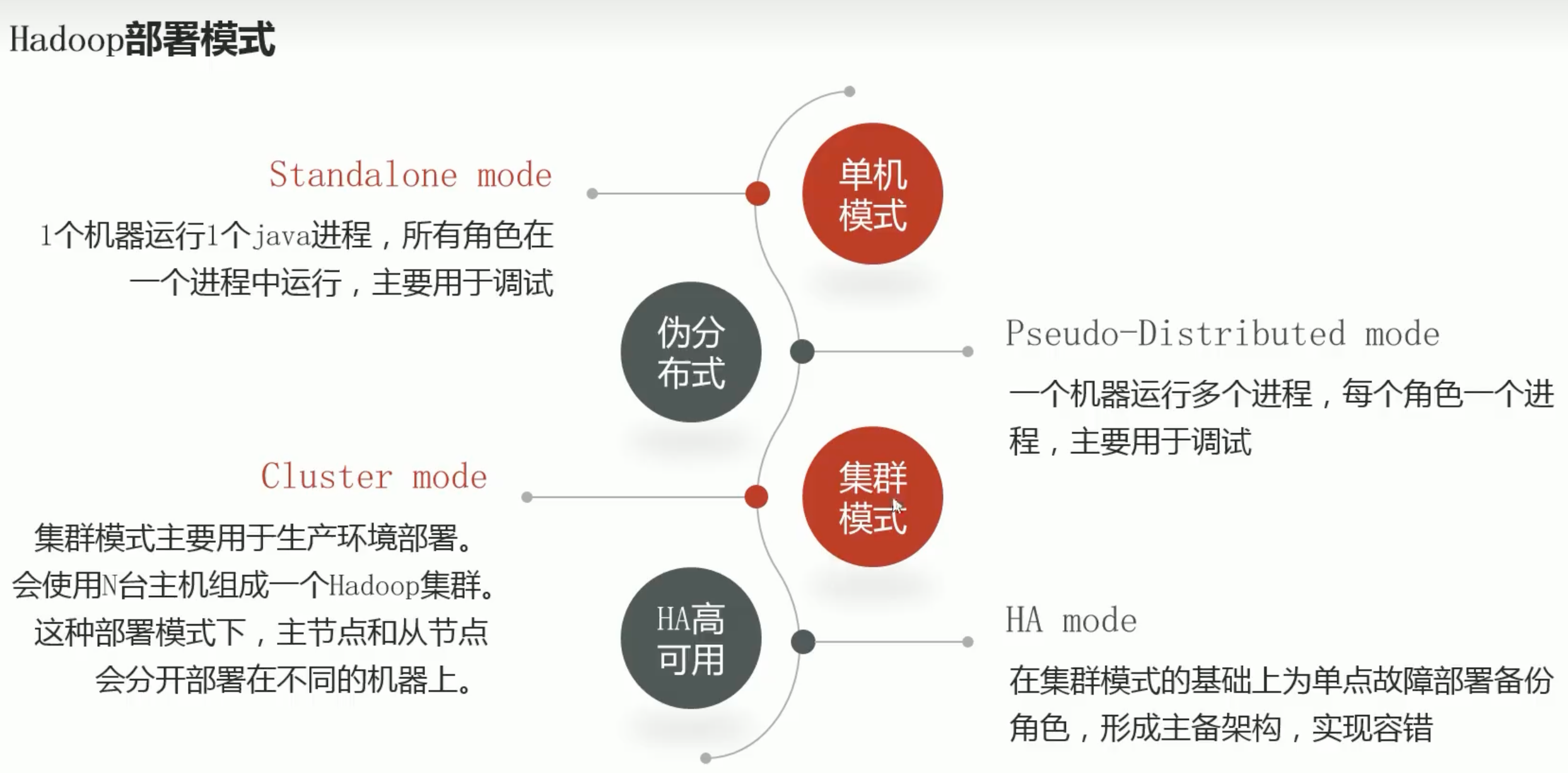
Hadoop部署模式
Hadoop集群源码编译安装
https://www.cnblogs.com/snguo/p/16717947.html
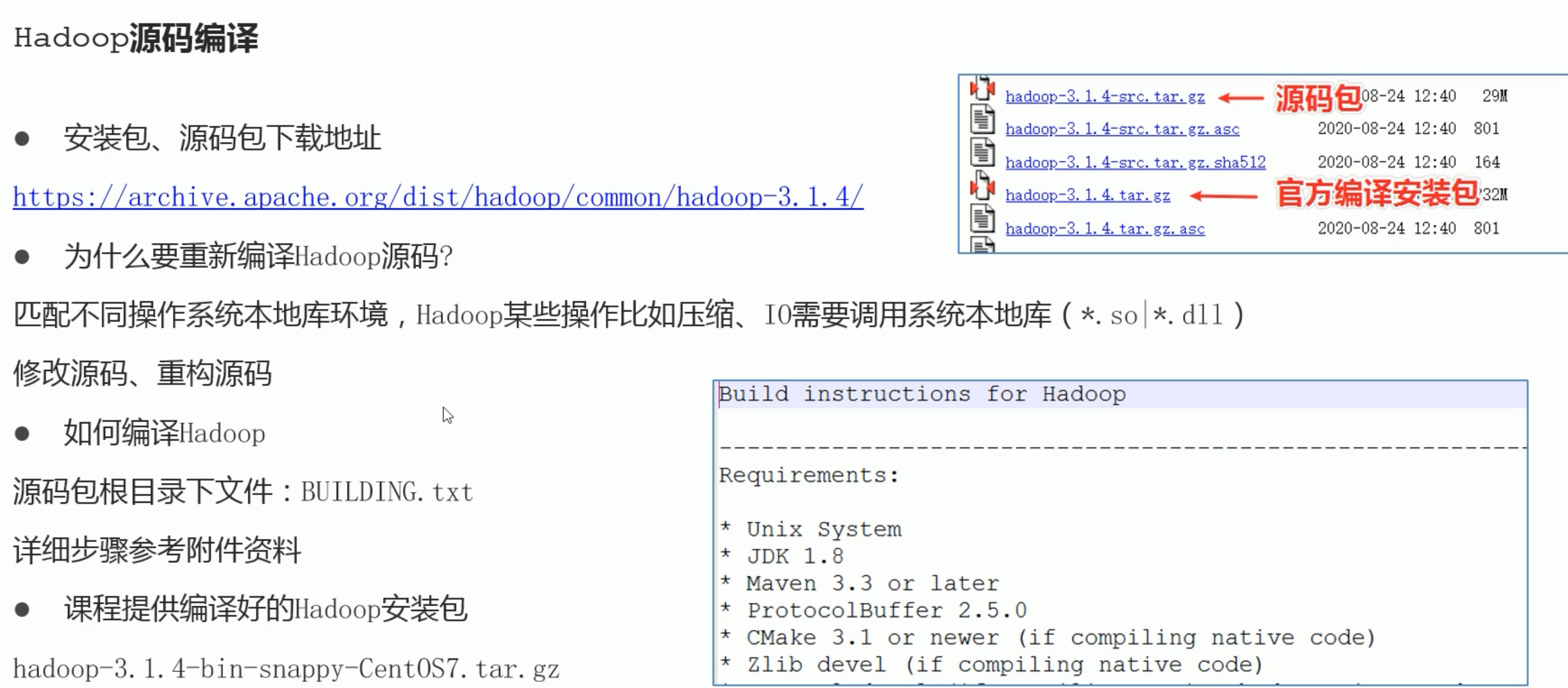
0.Hadoop源码编译(建议)
Hadoop源码包和二进制文件下载地址
https://hadoop.apache.org/releases.html
1.集群角色规划

| 服务器 | 运行角色 |
|---|---|
| master | namenode(HDFS主角色) datanode(HDFS从角色) resourcemanager(YARN主角色) nodemanager(YARN从角色) |
| node1 | secondarynamenode(HDFS辅助角色) datanode(HDFS从角色) nodemanager(YARN从角色) |
| node2 | datanode(HDFS从角色) nodemanager(YARN从角色) |
2.服务器基础环境准备
- 修改3台机器的主机名
# 其他节点修改成node1~2
hostnamectl set-hostname master
- 同步3台机器的
/etc/hosts文件 永久关闭3台机器的SELinux和防火墙
# 临时关闭SELinux
setenforce 0
# 修改SELinux的状态为disabled
## sed "s/原字符串/替换字符串/" filename
sed -i 's/^SELINUX=.*/SELINUX=disabled/' /etc/selinux/config
# 禁止开机启动并现在关闭
systemctl disable --now firewalld
- ssh免密3台机器(包括
本机到本机) - 保证集群内机器的时间同步
- 集群内机器都要 安装
oracle-JDK1.8(要卸载openjdk)
安装JDK1.8(安装OracleJDK8)
安装OracleJDK8
https://blog.csdn.net/omaidb/article/details/128634443
在master安装好JDK后将JDK程序和修改后的/etc/profile.d/jdk.sh同步到集群其他机器
# 将jdk程序同步到其他机器
scp -r /usr/java/ node1:/usr/
## 或使用xsync脚本同步到集群内机器
xsync /usr/java/
# 将修改后的/etc/profile同步到其他机器
scp /etc/profile.d/jdk.sh node1:/etc/profile.d
## 或使用xsync脚本同步到集群内机器
xsync /etc/profile.d/jdk.sh
3.创建Hadoop安装目录,上传Hadoop安装包
创建Hadoop安装目录
集群内所有机器都要执行
# 集群内机器创建统一工作目录
# mkdir -p /data/hadoop/{data,tmp,namenode,src}
mkdir -p /export/{server,data,src}
## 软件安装路径
mkdir -p /export/server/
## 数据存储路径
mkdir -p /export/data/
## 安装包存放路径
mkdir -p /export/src/
解压安装包
# 上传安装包到/export/src/
scp hadoop-3.3.4.tar.gz master:/export/src/
# 解压hadoop安装包到/export/server/
## -C 解压到指定路径
tar xvf hadoop-3.3.4.tar.gz -C /export/server/
4.Hadoop安装包目录结构
- bin存放对hadoop相关服务hdfs、yarn、MapReduce进行操作的脚本
- etchadoop的配置文件目录存放hadoop的配置文件
- lib存放hadoop的本地库对数据进行压缩解压缩功能
- sbin存放启动或停止hadoop相关服务的脚本
- share存放hadoop的依赖jar包、文档、官方案例。

5.编辑Hadoop配置文件
配置文件在cd $HADOOP_HOME/etc/hadoop目录
# cd到hadoop目录
cd $HADOOP_HOME/etc/hadoop
cd /export/server/hadoop-3.3.4/etc/hadoop
默认配置文件以-default结尾
- core-default.xml核心配置文件
- hdfs-default.xmlhdfs配置文件
- yarn-default.xmlyarn配置文件
- mapred-default.xmlMapReduce配置文件
自定义配置文件以-site结尾
- core-sit.xml核心配置文件
- hdfs-site.xmlhdfs配置文件
- yarn-site.xmlyarn配置文件
- mapred-site.xmlMapReduce配置文件
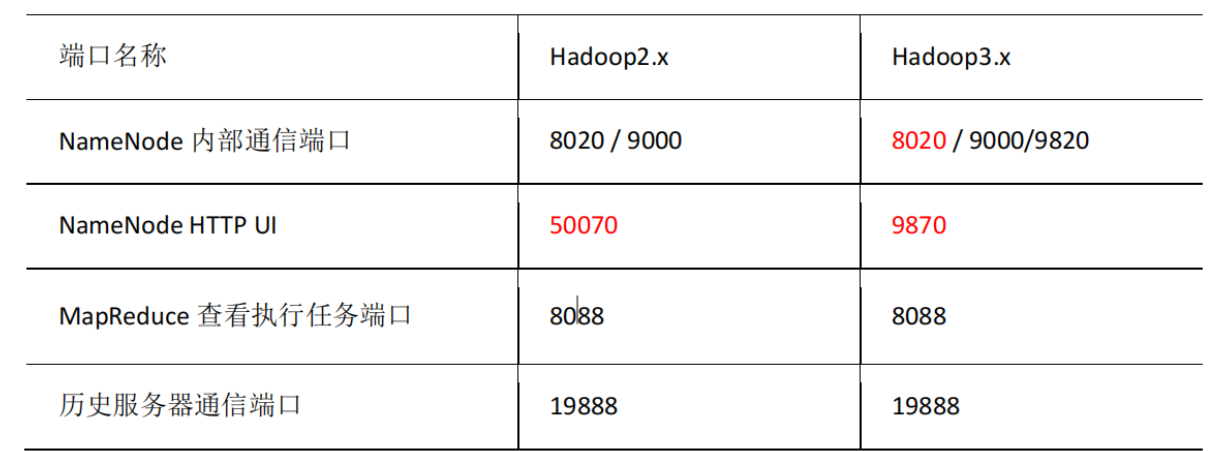
Hadoop常用端口说明
配置hadoop-env.sh

# 备份hadoop-env.sh
cp /export/server/hadoop-3.3.4/etc/hadoop/hadoop-env.sh{,.bak}
# 进入hadoop配置目录(必需)
cd cd $HADOOP_HOME/etc/hadoop
cd /export/server/hadoop-3.3.4/etc/hadoop/
# 去除配置的注释和空行
grep -Ev "^#|^$" hadoop-env.sh > /tmp/hadoop-env.sh && cat /tmp/hadoop-env.sh >hadoop-env.sh
# 编辑hadoop-env.sh
vim /export/server/hadoop-3.3.4/etc/hadoop/hadoop-env.sh
配置内容
# 指定JAVA_HOME路径
export JAVA_HOME=/usr/java/jdk1.8.0_202
# 若SSH端口不是默认的22需指定端口
# export HADOOP_SSH_OPTS="-p 1234"
# 设置用户以执行对应角色的shell命令
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
配置core-site.xml
https://blog.csdn.net/wjt199866/article/details/106473174
# 备份
cp /export/server/hadoop-3.3.4/etc/hadoop/core-site.xml{,.bak}
# 编辑core-site.xml
vim /export/server/hadoop-3.3.4/etc/hadoop/core-site.xml
配置内容如下
<configuration>
<!--指定namenode的地址-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:8020</value>
</property>
<!--用来指定使用hadoop时产生文件的存放目录,format时会自动生成目录-->
<property>
<name>hadoop.tmp.dir</name>
<!-- 这里指定到hadoop的数据存储目录下 -->
<value>/export/data/hadoop</value>
</property>
<!-- 在WEB UI中访问HDFS时使用的用户名 -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
<!--用来设置检查点备份日志的最长时间-->
<property>
<name>fs.checkpoint.period</name>
<value>3600</value>
</property>
</configuration>
配置hdfs-site.xml
# 备份hdfs-site.xml
cp /export/server/hadoop-3.3.4/etc/hadoop/hdfs-site.xml{,.bak}
# 编辑hdfs-site.xml
vim /export/server/hadoop-3.3.4/etc/hadoop/hdfs-site.xml
配置内容如下
<configuration>
<!-- 设定SNN(主角色的辅助角色)运行主机和端口 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<!-- 查看规划以确定SNN运行在哪台机器 -->
<value>node1:9868</value>
</property>
</configuration>
配置mapred-site.xml
# 备份mapred-site.xml
cp /export/server/hadoop-3.3.4/etc/hadoop/mapred-site.xml{,.bak}
# 编辑mapred-site.xml
vim /export/server/hadoop-3.3.4/etc/hadoop/mapred-site.xml
配置内容如下
<configuration>
<!--指定MR(Map/Reduce)运行方式-->
<property>
<name>mapreduce.framework.name</name>
<!-- yarn集群模式,local本地模式 -->
<value>yarn</value>
</property>
<!-- MR App Master环境变量 -->
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<!-- MR MapTask环境变量 -->
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<!-- MR ReduceTask环境变量 -->
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<!-- MR程序历史服务地址(按需配置) -->
<!-- <property>
<name>mapreduce.jobhistory.address</name>
<value>node2:10020</value>
</property> -->
<!-- MR程序历史服务器web端地址(按需配置) -->
<!-- <property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>node2:19888</value>
</property> -->
</configuration>
配置yarn-site.xml
# 备份yarn-site.xml
cp /export/server/hadoop-3.3.4/etc/hadoop/yarn-site.xml{,.bak}
# 编辑yarn-site.xml
vim /export/server/hadoop-3.3.4/etc/hadoop/yarn-site.xml
配置内容如下
<configuration>
<!--指定Yarn集群主角色(ResourceManager)的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<!--指定NomenodeManager上运行的附属服务获取数据的方式是mapreduce_shuffle-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 每容器请求的最小内存资源(以MB为单位),根据机器配置调整 -->
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>512</value>
</property>
<!-- 每容器请求的最大内存资源(以MB为单位),根据机器配置调整 -->
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>2048</value>
</property>
<!-- 容器虚拟内存与物理内存之间的比率(倍) -->
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>4</value>
</property>
<!--开启日志聚集功能-->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置yarn日志聚集服务器地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://node2:19888/jobhistory/logs</value>
</property>
<!-- 设置日志保留时间为7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
</configuration>
配置workers文件
配置从角色的主机名或IP
# 备份yarn-site.xml
cp /export/server/hadoop-3.3.4/etc/hadoop/workers{,.bak}
# 编辑yarn-site.xml
vim /export/server/hadoop-3.3.4/etc/hadoop/workers
配置内容: 添加Hadoop集群机器主机名或IP到该文件中
master
node1
node2
配置Hadoop安全参数
https://support.huaweicloud.com/usermanual-mrs/admin_guide_000277.html
6.分发Hadoop安装包
将master上的/export/server/目录同步到集群内其他机器;
使用xsync脚本优化同步
https://blog.csdn.net/omaidb/article/details/121746997
# 登陆master
ssh master
# 复制安装包到node1 node2 node3
scp -r /export/server/hadoop-3.3.4 node1:/export/server/
# 使用xsync将Hadoop程序同步到node1 node2 node3
xsync /export/server/hadoop-3.3.4
7.配置Hadoop环境变量
在master上配置Hadoop环境变量
vim /etc/profile.d/hadoop.sh
# 指定HADOOP_HOME路径
export HADOOP_HOME=/export/server/hadoop-3.3.4
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
重新加载环境变量
# 使新增的HADOOP变量生效
source /etc/profile
# 查看hadoop命令是否找到
which hadoop
# 查看hadoop版本
hadoop version


将修改后的/etc/profile.d/hadoop.sh同步到其他机器
# 将修改后的/etc/profile同步到其他机器
scp /etc/profile.d/hadoop.sh node1:/etc/profile.d
# 使用xsync将Hadoop变量同步到node1 node2 node3
xsync /etc/profile.d/hadoop.sh
8.NameNode初始化(格式化)
- 首次启动HDFS时必需对其进行格式化操作
- format本质上是初始化工作进行HDFS清理和准备工作

# 首次启动HDFS时必需对其进行格式化操作
hdfs namenode -format
下图提示初始化成功了。
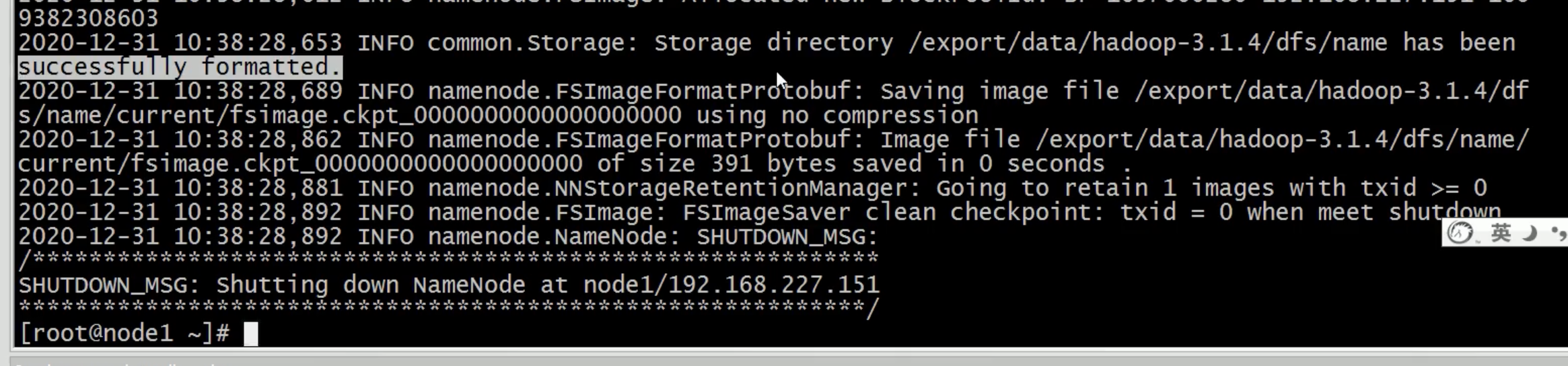
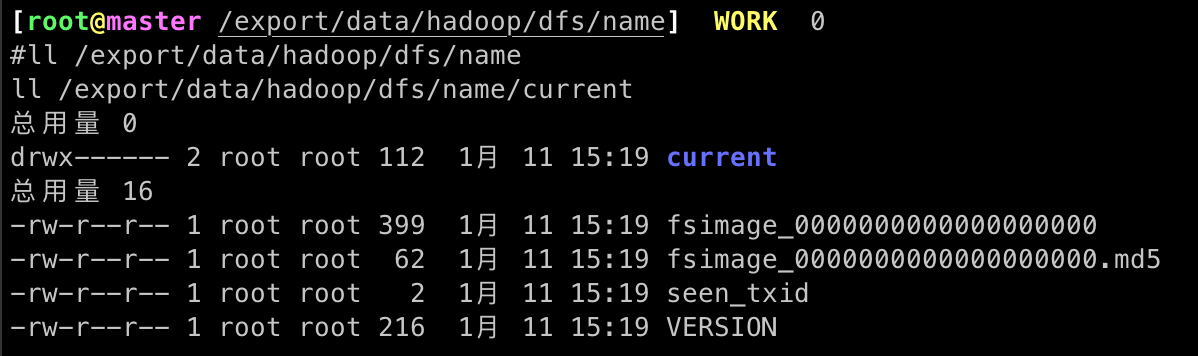
# 查看数据存储路径
ll /export/data/hadoop/dfs/name
ll /export/data/hadoop/dfs/name/current
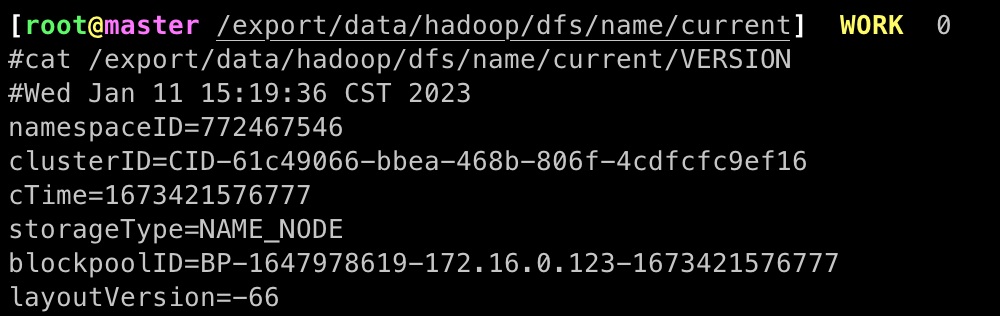
查看hadoop版本信息
# 查看hadoop版本信息
cat /export/data/hadoop/dfs/name/current/VERSION
9.在指定节点上启动指定角色
https://book.itheima.net/course/1269935677353533441/1269937996044476418/1269939192469692419
需要根据集群角色规划清单来选择在指定节点上启动指定角色。
| 服务器 | 运行角色 |
|---|---|
| master | namenode(HDFS主角色) datanode(HDFS从角色) resourcemanager(YARN主角色) nodemanager(YARN从角色) |
| node1 | secondarynamenode(HDFS辅助角色) datanode(HDFS从角色) nodemanager(YARN从角色) |
| node2 | datanode(HDFS从角色) nodemanager(YARN从角色) |
在master机器上执行
# HDFS启动namenode(HDFS主角色)
hdfs --daemon start namenode
# HDFS启动datanode(HDFS从角色)
hdfs --daemon start datanode
# YARN启动resourcemanager(YARN主角色)
yarn --daemon start resourcemanager
# YARN启动nodemanager(YARN从角色)
yarn --daemon start nodemanager
在node1机器上执行
# HDFS启动secondarynamenode(HDFS辅助角色)
hdfs --daemon start secondarynamenode
# HDFS启动datanode(HDFS从角色)
hdfs --daemon start datanode
# YARN启动nodemanager(YARN从角色)
yarn --daemon start nodemanager

在node2机器上执行
# HDFS启动datanode(HDFS从角色)
hdfs --daemon start datanode
# YARN启动nodemanager(YARN从角色)
yarn --daemon start nodemanager

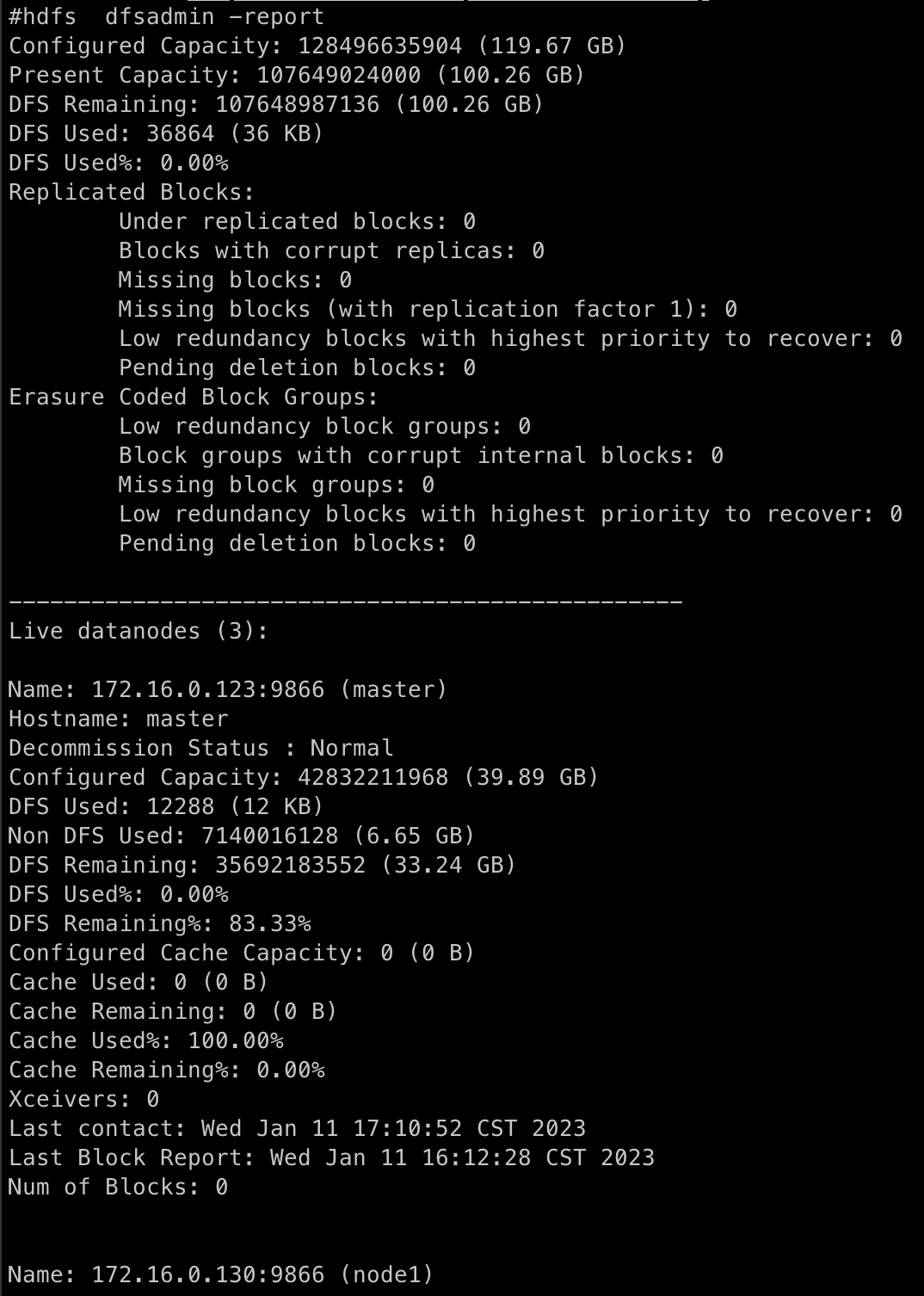
10.查看HDFS状态
# 查看HDFS状态
hdfs dfsadmin -report
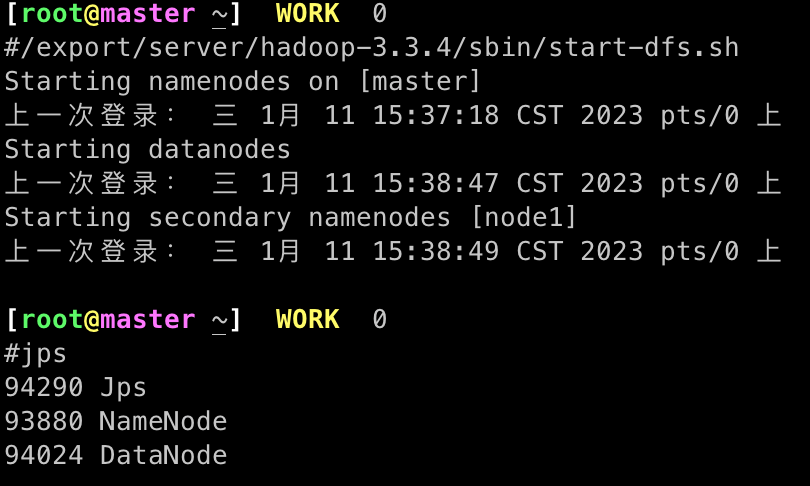
Hadoop启动和关闭基本用法
# 一键启动所有角色(一般适用于单机模式)
/export/server/hadoop-3.3.4/sbin/start-all.sh
# 一键关闭所有角色(一般适用于单机模式)
/export/server/hadoop-3.3.4/sbin/stop-all.sh
# 整体启动或停止hdfs(一般适用于单机模式)
## 启动hdfs
/export/server/hadoop-3.3.4/sbin/start-dfs.sh
## 关闭hdfs
/export/server/hadoop-3.3.4/sbin/stop-dfs.sh
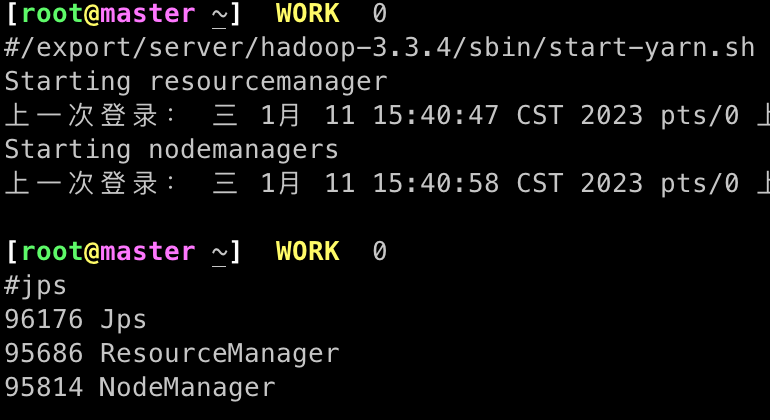
# 整体启动或停止yarn(一般适用于单机模式)
## 启动yarn
/export/server/hadoop-3.3.4/sbin/start-yarn.sh
## 停止yarn
/export/server/hadoop-3.3.4/sbin/stop-yarn.sh

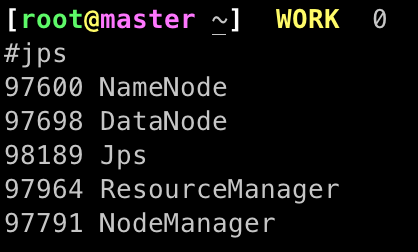
查看角色是否启动
# 使用jps查看启动的java进程
jps
HDFS集群手动启动与关闭指定角色基本用法
# hdfs集群启动角色
hdfs --daemon start namenode|datanode|secondarynamenode
# hdfs关闭角色
hdfs --daemon stop namenode|datanode|secondarynamenode
启动datanode时会自动创建logs目录
YARN集群手动启动与关闭指定角色基本用法
# YARN启动NodeManger、ResourceManger角色
yarn --daemon start resourcemanager|nodemanager
# 关闭NodeManger、ResourceManger角色
yarn --daemon stop resourcemanager|nodemanager
启动或停止历史服务器(按需启动)
# 启动历史服务器(HistoryServer角色)
mapred --daemon start historyserver
# 关闭历史服务器(HistoryServer角色)
mapred --daemon stop historyserver
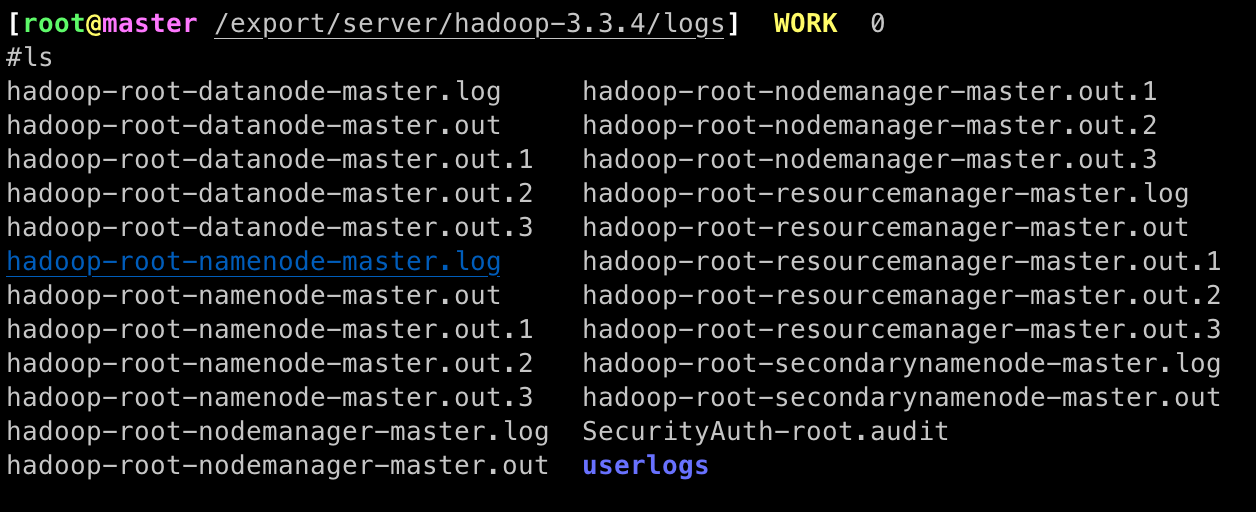
查看日志
# 日志所在目录
/export/server/hadoop-3.3.4/logs
Haddop Web UI页面-HDFS集群
webui界面地址 http://namenode_host:9870
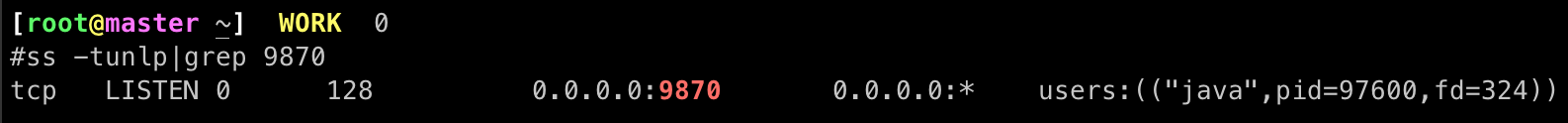
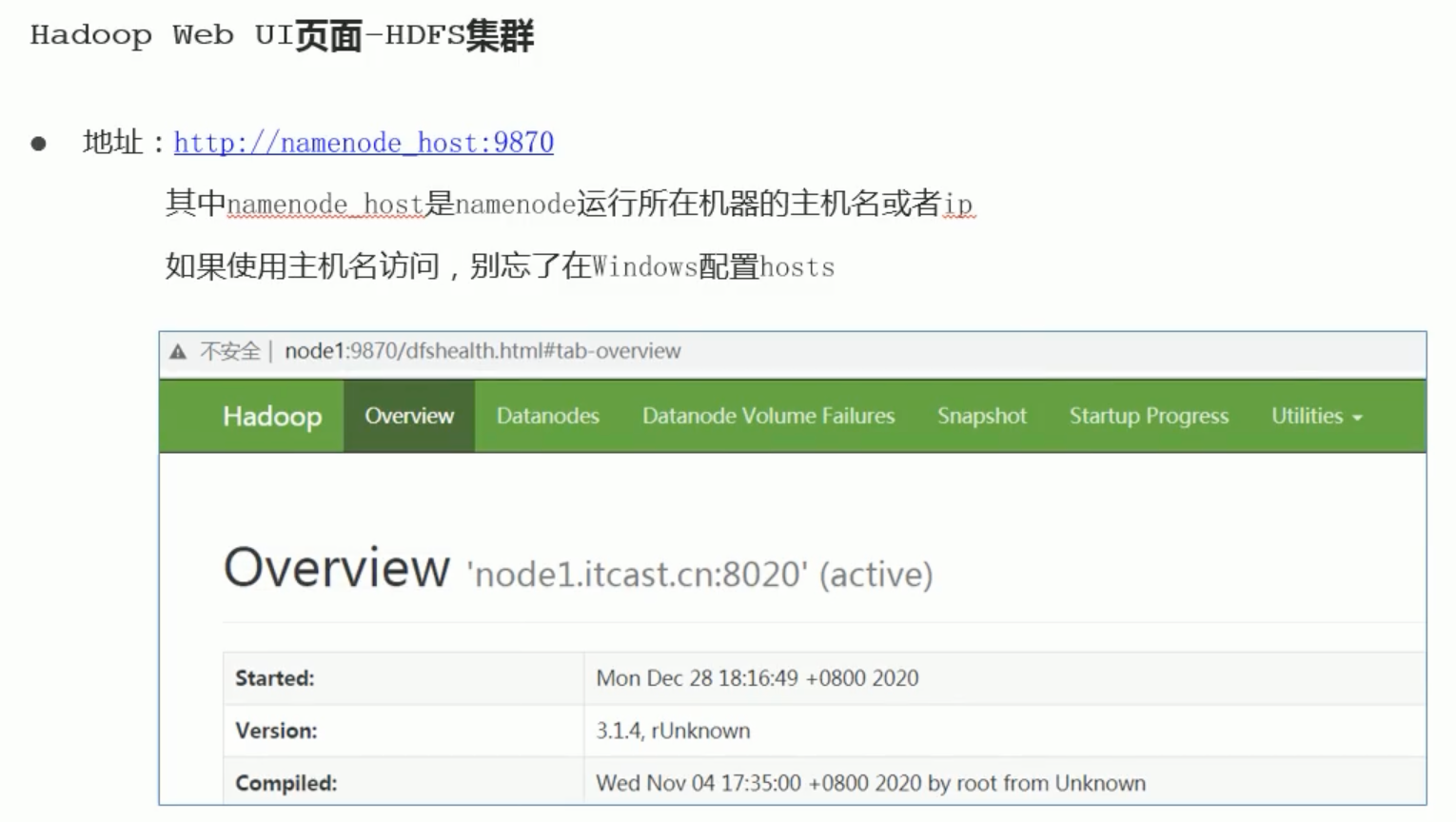
web-ui查看日志
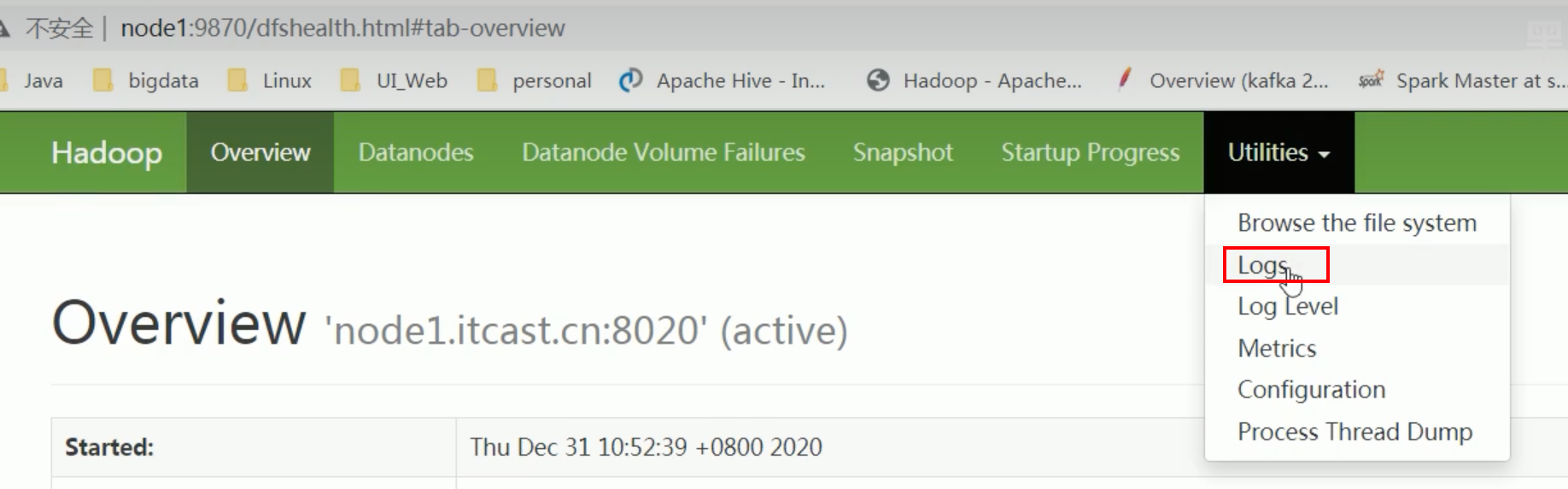
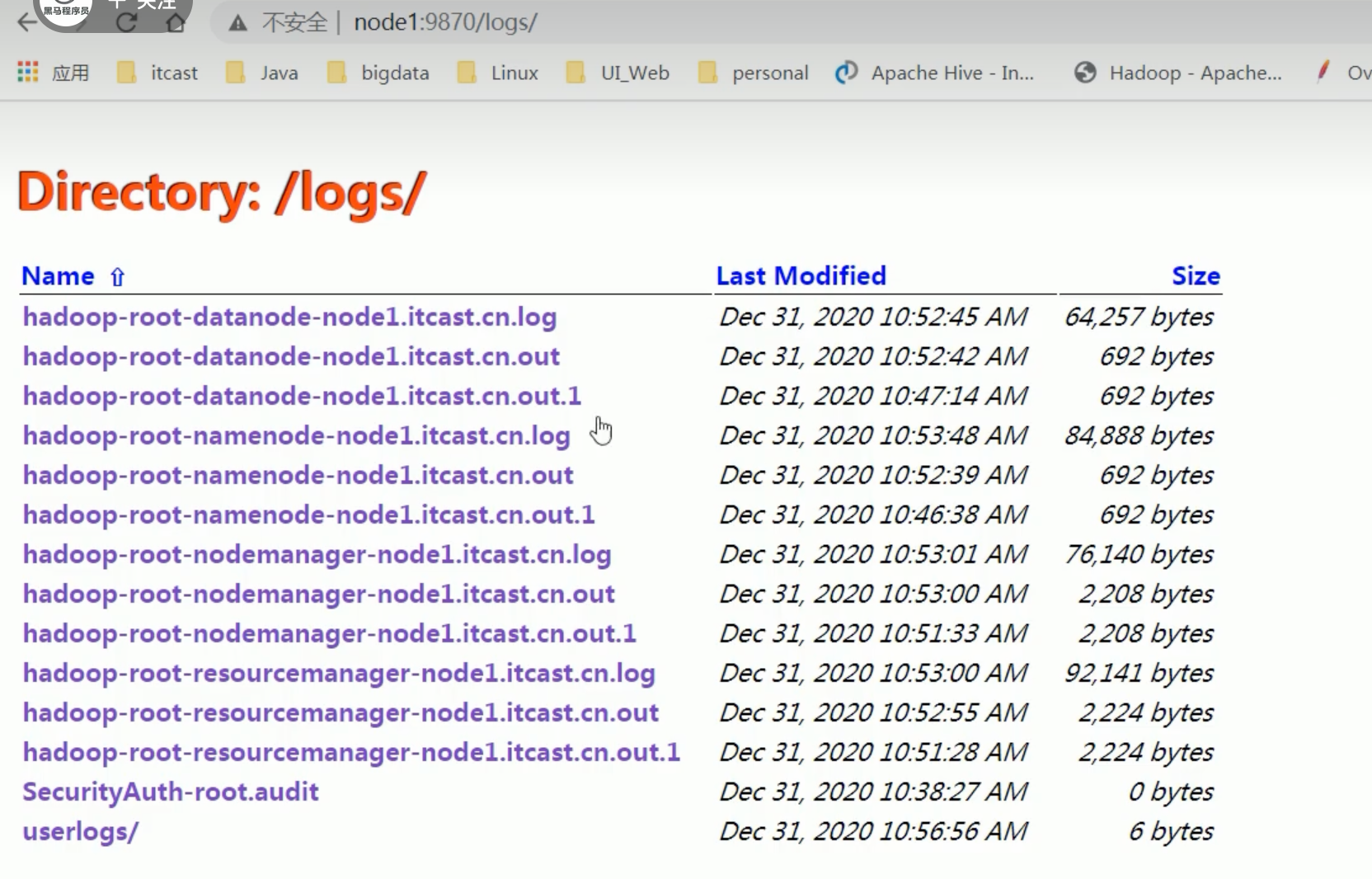
浏览文件系统
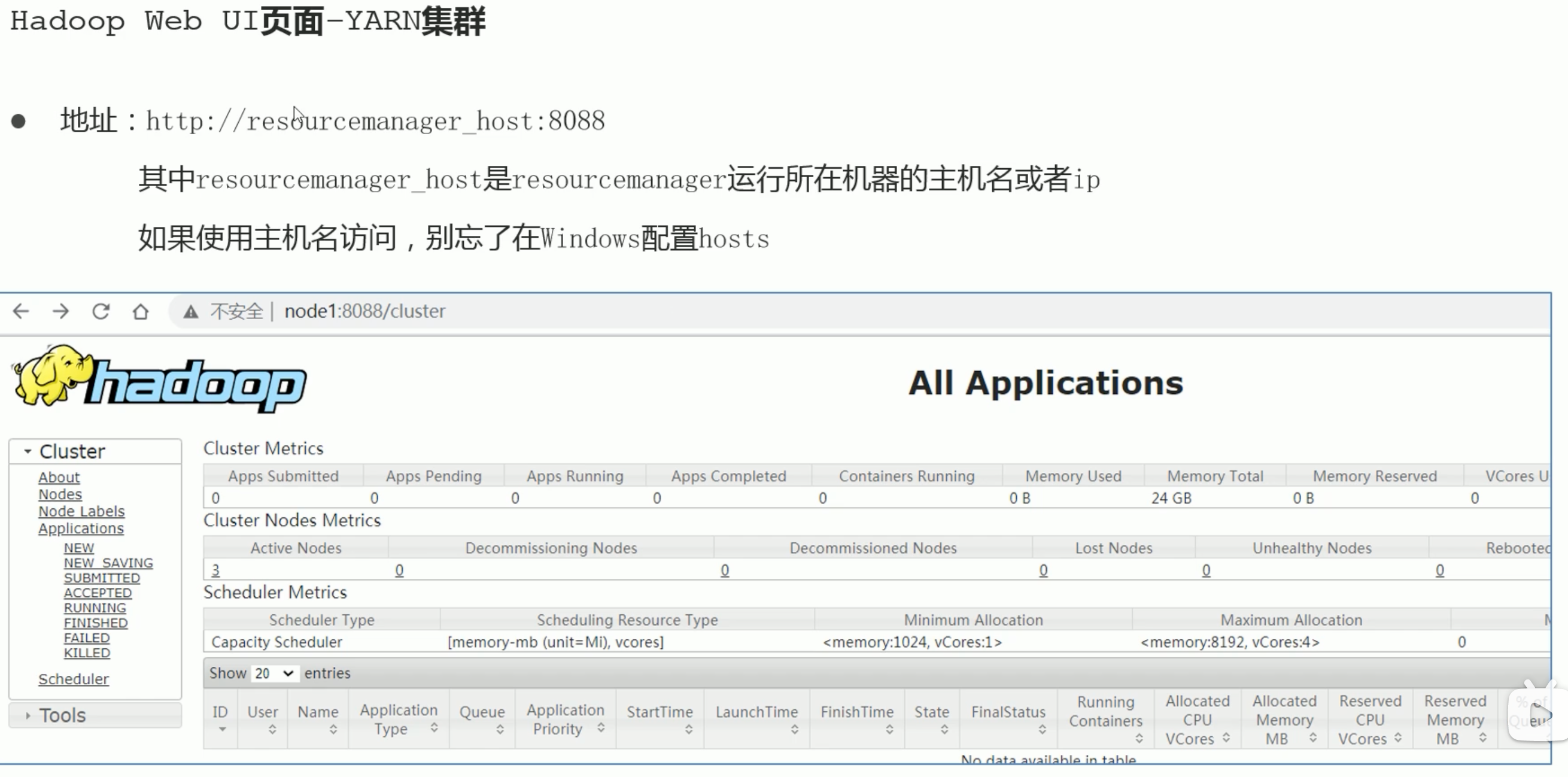
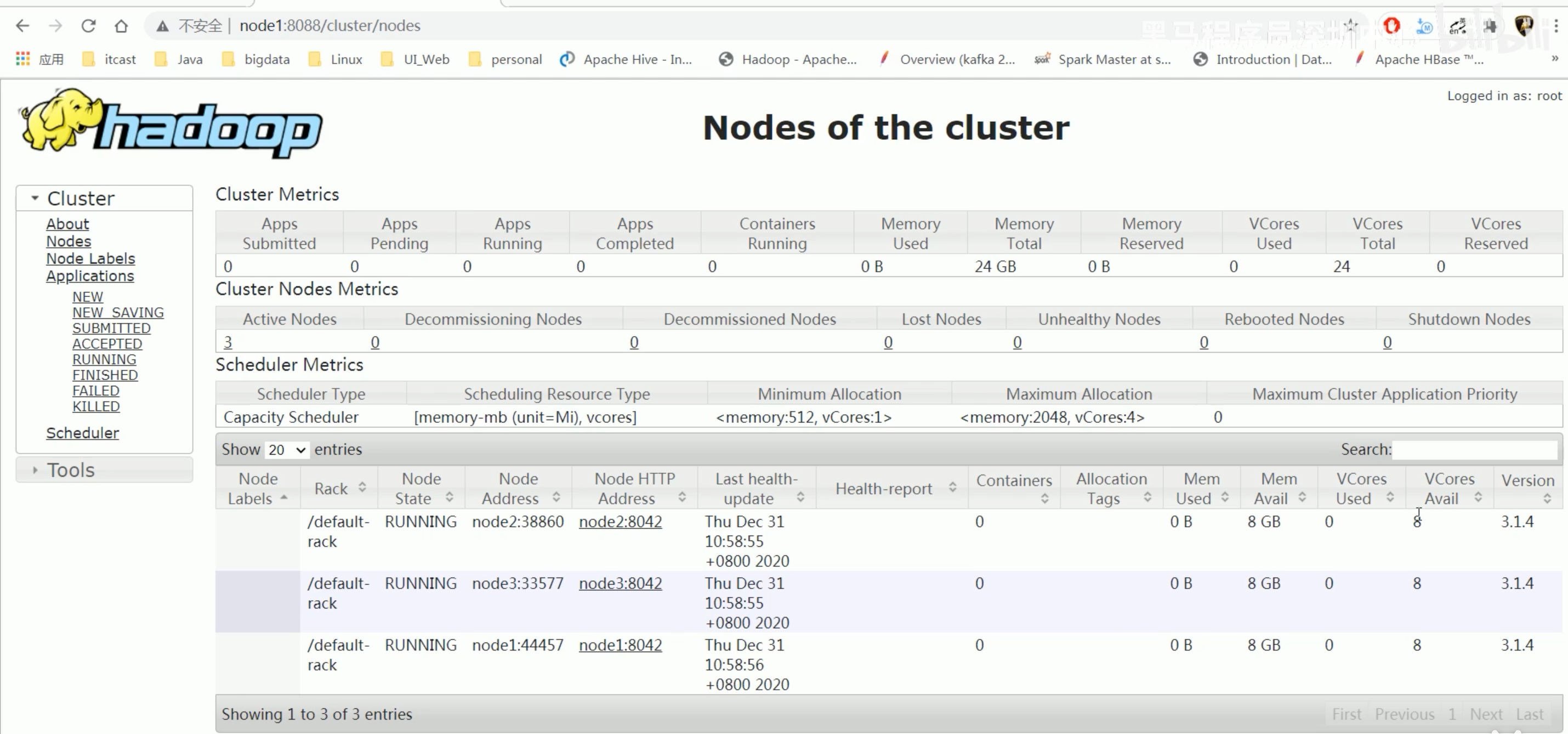
Haddop Web UI页面-YARN集群
webui界面地址 http://resourcemanager_host:8088