

流批一体计算引擎-6-[Flink]的Python DataStream API程序
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
1 IDEA中运行Flink
从Flink 1.11版本开始, PyFlink 作业支持在 Windows 系统上运行因此您也可以在 Windows 上开发和调试 PyFlink 作业了。
1.1 环境配置
pip3 install apache-flink==1.15.3
CMD>set PATH查看环境变量
CMD>set JAVA_HOME查看环境变量
JAVA_HOME=D:\Java\jdk
1.2 Python API
根据需要的抽象级别的不同有两种不同的API可以在PyFlink中使用
(1)PyFlink Table API允许你使用类似于SQL或者在Python中处理表格数据的方式编写强大的关系查询。
(2)PyFlink DataStream API允许你对Flink的核心组件state和time进行细粒度的控制以便构建更复杂的流处理应用。
从现有的 StreamExecutionEnvironment 创建 StreamTableEnvironment以与 DataStream API 进行互操作。
1.3 配置Flink Kafka连接
(1)在https://mvnrepository.com/里输入flink sql kafka寻找对应版本的连接器。
(2)选择Flink对应的版本1.15.3点击jar。
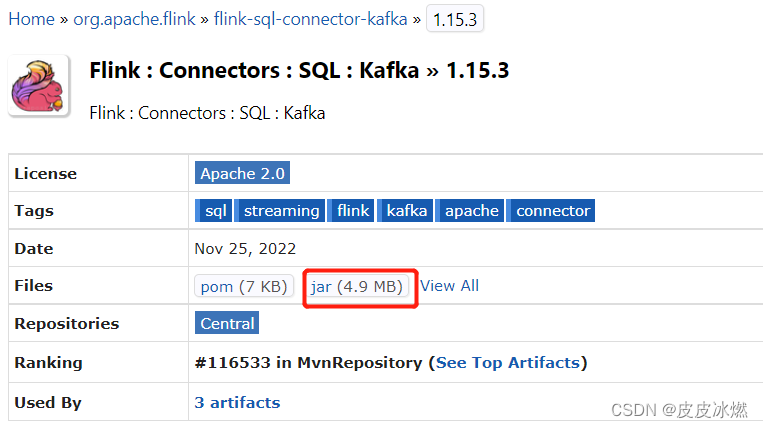

(3)将该jar包放置在python的lib目录下
External Libraries->site-packages->pyflink->lib
2 PyFlink DataStream API
Flink中的数据流程序是对数据流执行转换的常规程序例如过滤、更新状态、定义窗口、聚合。数据流最初是从各种源例如消息队列、套接字流、文件创建的。结果通过接收器返回接收器可以将数据写入文件或标准输出例如命令行终端。
2.1 Python DataStream API程序的基本结构
2.2 第一步:创建StreamExecutionEnvironment
StreamExecutionEnvironment是DataStream API程序的核心概念。以下代码示例显示了如何创建StreamExecutionEnvironment
from pyflink.datastream import StreamExecutionEnvironment
env = StreamExecutionEnvironment.get_execution_environment()
2.3 第二步:创建DataStream
DataStream API从专用的DataStream类获取其名称该类用于表示Flink程序中的数据集合。您可以将它们视为可以包含重复数据的不可变数据集合。这些数据可以是有限的也可以是无界的用于处理它们的API是相同的。
DataStream在使用方面与常规Python集合相似但在某些关键方面有很大不同。它们是不可变的这意味着一旦创建了它们就不能添加或删除元素。您还可以不仅仅简单地检查内部的元素还可以使用DataStream API操作也称为转换处理它们。
您可以通过在Flink程序中添加source来创建初始DataStream。然后您可以从中派生出新的streams并通过使用诸如map、filter等API方法来组合它们。
2.3.1 通过列表类型的对象创建
# -*- coding:utf-8 -*-
from pyflink.common.typeinfo import Types
from pyflink.datastream import StreamExecutionEnvironment
env = StreamExecutionEnvironment.get_execution_environment()
env.set_parallelism(1)
ds = env.from_collection(
collection=[(1, 'aaa|bb'), (2, 'bb|a'), (3, 'aaa|a')],
type_info=Types.ROW([Types.INT(), Types.STRING()]))
ds.print()
env.execute("tutorial_job")

参数type_info是可选的如果未指定则返回的DataStream的输出类型将为Types.PICKLED_BYTE_ARRAY()。
2.3.2 通过DataStream连接器创建
方式一使用DataStream连接器的add_source方法创建数据流如下所示
# -*- coding:utf-8 -*-
from pyflink.common import JsonRowDeserializationSchema
from pyflink.common.typeinfo import Types
from pyflink.datastream import StreamExecutionEnvironment
from pyflink.datastream.connectors import FlinkKafkaConsumer
env = StreamExecutionEnvironment.get_execution_environment()
# 这里使用kafka的sql连接器因为它是一个fat jar可以避免依赖性问题
env.add_jars("flink-sql-connector-kafka-1.15.3.jar")
deserialization_schema = JsonRowDeserializationSchema.builder() \
.type_info(type_info=Types.ROW([Types.INT(), Types.STRING()])).build()
kafka_consumer = FlinkKafkaConsumer(
topics='test_source_topic',
deserialization_schema=deserialization_schema,
properties={'bootstrap.servers': 'localhost:9092', 'group.id': 'test_group'})
ds = env.add_source(kafka_consumer)
ds.print()
env.execute("tutorial_job")
Note It currently only supports FlinkKafkaConsumer to be used as DataStream source connectors with method add_source.
Note The DataStream created using add_source could only be executed in streaming executing mode.
方式二You could also call the from_source method to create a DataStream using unified DataStream source connectors:
# -*- coding:utf-8 -*-
from pyflink.common.typeinfo import Types
from pyflink.common.watermark_strategy import WatermarkStrategy
from pyflink.datastream import StreamExecutionEnvironment
from pyflink.datastream.connectors import NumberSequenceSource
env = StreamExecutionEnvironment.get_execution_environment()
env.set_parallelism(2)
seq_num_source = NumberSequenceSource(1, 10)
ds = env.from_source(
source=seq_num_source,
watermark_strategy=WatermarkStrategy.for_monotonous_timestamps(),
source_name='seq_num_source',
type_info=Types.LONG())
ds.print()
env.execute("tutorial_job")

Note Currently, it only supports NumberSequenceSource and FileSource as unified DataStream source connectors.
Note The DataStream created using from_source could be executed in both batch and streaming executing mode.
2.3.3 通过Table & SQL连接器创建
Table & SQL连接器也能用来创建DataStream。首先使用Table & SQL连接器创建Table然后将Table转化为DataStream。
# -*- coding:utf-8 -*-
from pyflink.common.typeinfo import Types
from pyflink.datastream import StreamExecutionEnvironment
from pyflink.table import StreamTableEnvironment
env = StreamExecutionEnvironment.get_execution_environment()
env.set_parallelism(1)
t_env = StreamTableEnvironment.create(stream_execution_environment=env)
t_env.execute_sql("""
CREATE TABLE my_source (
a INT,
b VARCHAR
) WITH (
'connector' = 'datagen',
'number-of-rows' = '10'
)
""")
ds = t_env.to_append_stream(
t_env.from_path('my_source'),
Types.ROW([Types.INT(), Types.STRING()]))
ds.print()
env.execute("tutorial_job")
Note The StreamExecutionEnvironment env should be specified when creating the StreamTableEnvironment t_env.
Note As all the Java Table & SQL connectors could be used in PyFlink Table API, this means that all of them could also be used in PyFlink DataStream API.
2.4 第三步:DataStream转换
运算符将一个或多个DataStream转换为新的DataStream。程序可以将多种转换组合成复杂的DataStream拓扑。
下面的示例显示了一个简单的示例说明如何使用映射转换将一个DataStream转换为另一个DataStream
ds = ds.map(lambda a: a + 1)
2.5 第四步:DataStream and Table之间转换
# convert a DataStream to a Table
table = t_env.from_data_stream(ds, 'a, b, c')
# convert a Table to a DataStream
ds = t_env.to_append_stream(table, Types.ROW([Types.INT(), Types.STRING()]))
# or
ds = t_env.to_retract_stream(table, Types.ROW([Types.INT(), Types.STRING()]))
2.6 第五步:输出结果
2.6.1 打印结果
您可以调用print方法将DataStream的数据打印到标准输出。
ds.print()
2.6.2 将结果数据收集到客户端
您可以调用execute_and_collect方法将数据流的数据收集到客户端
with ds.execute_and_collect() as results:
for result in results:
print(result)
注意execute_and_collect方法会将数据流的数据收集到客户端的内存中因此限制收集的行数是一个很好的做法。
2.6.3 将结果写入到DataStream sink连接器
方式一您可以调用add_sink方法将数据流的数据发送到数据流接收器连接器
from pyflink.common.typeinfo import Types
from pyflink.datastream.connectors.kafka import FlinkKafkaProducer
from pyflink.datastream.formats.json import JsonRowSerializationSchema
serialization_schema = JsonRowSerializationSchema.builder().with_type_info(
type_info=Types.ROW([Types.INT(), Types.STRING()])).build()
kafka_producer = FlinkKafkaProducer(
topic='test_sink_topic',
serialization_schema=serialization_schema,
producer_config={'bootstrap.servers': 'localhost:9092', 'group.id': 'test_group'})
ds.add_sink(kafka_producer)
注意它目前只支持FlinkKafkaProducer和JdbcSink用作方法add_sink的数据流接收器连接器。
注意add_sink方法只能在流执行模式下使用。
方式二您还可以调用sink_to方法将数据流的数据发送到统一的数据流接收器连接器
from pyflink.datastream.connectors.file_system import FileSink, OutputFileConfig
from pyflink.common.serialization import Encoder
output_path = '/opt/output/'
file_sink = FileSink \
.for_row_format(output_path, Encoder.simple_string_encoder()) \
.with_output_file_config(OutputFileConfig.builder().with_part_prefix('pre').with_part_suffix('suf').build()) \
.build()
ds.sink_to(file_sink)
注意它目前只支持FileSink作为统一的数据流接收器连接器。
注意sink_to方法可用于批处理和流式执行模式。
2.6.4 将结果写入到Table & SQL sink连接器
Table & SQL也可用于写入数据流。您需要首先将数据流转换为表然后将其写入Table & SQL sink连接器。
from pyflink.common import Row
from pyflink.common.typeinfo import Types
from pyflink.datastream import StreamExecutionEnvironment
from pyflink.table import StreamTableEnvironment
env = StreamExecutionEnvironment.get_execution_environment()
t_env = StreamTableEnvironment.create(stream_execution_environment=env)
# option 1the result type of ds is Types.ROW
def split(s):
splits = s[1].split("|")
for sp in splits:
yield Row(s[0], sp)
ds = ds.map(lambda i: (i[0] + 1, i[1])) \
.flat_map(split, Types.ROW([Types.INT(), Types.STRING()])) \
.key_by(lambda i: i[1]) \
.reduce(lambda i, j: Row(i[0] + j[0], i[1]))
# option 1the result type of ds is Types.TUPLE
def split(s):
splits = s[1].split("|")
for sp in splits:
yield s[0], sp
ds = ds.map(lambda i: (i[0] + 1, i[1])) \
.flat_map(split, Types.TUPLE([Types.INT(), Types.STRING()])) \
.key_by(lambda i: i[1]) \
.reduce(lambda i, j: (i[0] + j[0], i[1]))
# emit ds to print sink
t_env.execute_sql("""
CREATE TABLE my_sink (
a INT,
b VARCHAR
) WITH (
'connector' = 'print'
)
""")
table = t_env.from_data_stream(ds)
table_result = table.execute_insert("my_sink")
2.7 第六步:提交作业
Finally, you should call the StreamExecutionEnvironment.execute method to submit the DataStream API job for execution:
env.execute()
If you convert the DataStream to a Table and then write it to a Table API & SQL sink connector, it may happen that you need to submit the job using TableEnvironment.execute method.
t_env.execute()
3 DataStream API 示例代码
从非空集合中读取数据并将结果写入本地文件系统。
from pyflink.common.serialization import Encoder
from pyflink.common.typeinfo import Types
from pyflink.datastream import StreamExecutionEnvironment
from pyflink.datastream.connectors import StreamingFileSink
def tutorial():
env = StreamExecutionEnvironment.get_execution_environment()
env.set_parallelism(1)
ds = env.from_collection(
collection=[(1, 'aaa'), (2, 'bbb')],
type_info=Types.ROW([Types.INT(), Types.STRING()]))
ds.add_sink(StreamingFileSink
.for_row_format('output', Encoder.simple_string_encoder())
.build())
env.execute("tutorial_job")
if __name__ == '__main__':
tutorial()
(1)DataStream API应用程序首先需要声明一个执行环境
StreamExecutionEnvironment这是流式程序执行的上下文。
后续将通过它来设置作业的属性(例如默认并发度、重启策略等)、创建源、并最终触发作业的执行。
env = StreamExecutionEnvironment.get_execution_environment()
env.set_parallelism(1)
(2)声明数据源
一旦创建了 StreamExecutionEnvironment 之后可以使用它来声明数据源。
数据源从外部系统(如Apache Kafka、Rabbit MQ 或 Apache Pulsar)拉取数据到Flink作业里。
为了简单起见本次使用元素集合作为数据源。
这里从相同类型数据集合中创建数据流(一个带有 INT 和 STRING 类型字段的ROW类型)。
ds = env.from_collection(
collection=[(1, 'aaa'), (2, 'bbb')],
type_info=Types.ROW([Types.INT(), Types.STRING()]))
(3)转换操作或写入外部系统
现在可以在这个数据流上执行转换操作或者使用 sink 将数据写入外部系统。
本次使用StreamingFileSink将数据写入output文件目录中。
ds.add_sink(StreamingFileSink
.for_row_format('output', Encoder.simple_string_encoder())
.build())
(4)执行作业
最后一步是执行真实的 PyFlink DataStream API作业。
PyFlink applications是懒加载的并且只有在完全构建之后才会提交给集群上执行。
要执行一个应用程序只需简单地调用env.execute(job_name)。
env.execute("tutorial_job")

4 DataStream转换
三种方式支持用户自定义函数。
4.1 Lambda函数
from pyflink.common.typeinfo import Types
from pyflink.datastream import StreamExecutionEnvironment
env = StreamExecutionEnvironment.get_execution_environment()
env.set_parallelism(1)
data_stream = env.from_collection([1, 2, 3, 4, 5], type_info=Types.INT())
mapped_stream = data_stream.map(lambda x: x + 1, output_type=Types.INT())
mapped_stream.print()
env.execute("tutorial_job")
4.2 python函数
from pyflink.common.typeinfo import Types
from pyflink.datastream import StreamExecutionEnvironment
def my_map_func(value):
return value + 1
def main():
env = StreamExecutionEnvironment.get_execution_environment()
env.set_parallelism(1)
data_stream = env.from_collection([1, 2, 3, 4, 5], type_info=Types.INT())
mapped_stream = data_stream.map(my_map_func, output_type=Types.INT())
mapped_stream.print()
env.execute("tutorial_job")
if __name__ == '__main__':
main()
4.3 接口函数
from pyflink.common.typeinfo import Types
from pyflink.datastream import StreamExecutionEnvironment, MapFunction
class MyMapFunction(MapFunction):
def map(self, value):
return value + 1
def main():
env = StreamExecutionEnvironment.get_execution_environment()
env.set_parallelism(1)
data_stream = env.from_collection([1, 2, 3, 41, 5], type_info=Types.INT())
mapped_stream = data_stream.map(MyMapFunction(), output_type=Types.INT())
mapped_stream.print()
env.execute("tutorial_job")
if __name__ == '__main__':
main()