

计算机视觉OpenCv学习系列:第十部分、实时人脸检测
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
第十部分、实时人脸检测
第一节、实时人脸检测
1.OpenCV人脸检测支持演化
OpenCV4 DNN模块
DNN- 深度神经网络
- 来自另外一个开源项目tiny dnn
- OpenCV3.3正式发布
- 最新版本OpenCV4.5.5
- 支持后台硬件加速机制 CPU/GPU等
- 支持多种任务(分类、检测、分割、风格迁移、场景文字检测等)
- 只支持推理不支持训练推理支持模型的部署但是不支持训练。
- 支持主流的深度学习框架生成模型
- 推荐使用pytorch/tensorflow
人脸检测的发展过程
-
OpenCV3.3之前基于HAAR/LBP级联检测
-
OpenCV3.3开始支持深度学习人脸检测支持人脸检测
-
模型caffe/tensorflowOpenCV4.5.4 支持人脸检测+landmark
-
模型下载地址
- https://gitee.com/opencv_ai/opencv_tutorial_data
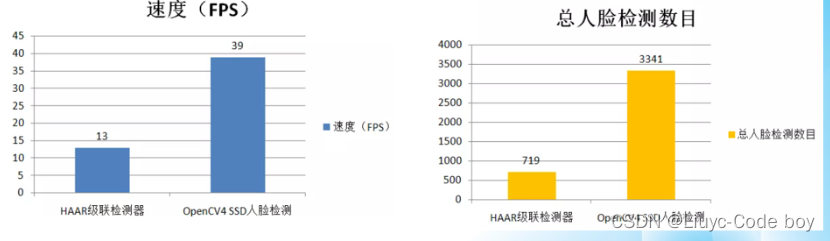
OpenCV人脸检测支持演化
- OpenCV人脸检测传统算法与深度学习模型对比
- 针对同一段视频文件速度与检测总数统计比较
2.OpenCV DNN检测函数
# 读取模型
1. readNetFromTensorflow
# 转换为blob对象(实际上就是一个tensor)
2. blobFromImage
# 设置输入
3. setInput
# 推理预测
4. forward
- 模型输入:1x3x300x300将图片放入自动变成1x3x300x300的大小
- 模型输出:1xNx7N代表检测出多少个人脸下所示就是1x1x7
- 7个数字分别是
- 最后四个人脸检测框左上角和右下角坐标x1, x2, y1, y2
- 第三个预测置信度
- 第一个batch-size的index索引 目前是0每批读入一个图片
- 第二个classid分类的类别因为当前是人脸识别只有一类所以classid=0
- 所以当前只用解析后五个参数即可
- 推理时间与帧率
3.代码练习与测试
1.readNetfromTensorflow 加载模型
2.blobFromImage转换输入格式数据
3.setInput设置输入数据
4.forward推理
5.对输出的数据 Nx7 完成解析
6.绘制矩形框跟得分
加载模型一次即可推理可以执行多次
# 人脸识别需要的文件
model_bin ="../data/opencv_face_detector_uint8.pb"
config_text = "../data/opencv_face_detector.pbtxt"
# 识别一张图片中的人脸
def frame_face_demo():
# 记录开始时间
a = time.time()
print(a)
# 获取摄像头
font = cv.FONT_HERSHEY_SIMPLEX
font_scale = 0.5
thickness = 1
# 部署tensorflow模型
net = cv.dnn.readNetFromTensorflow(model_bin, config=config_text)
# 记录调用时长
print(time.time() - a)
print(time.strftime('%Y-%m-%d %H:%M:%S'))
e1 = cv.getTickCount()
# 摄像头是和人对立的将图像垂直翻转
frame = cv.imread(r"F:\python\opencv-4.x\samples\data\lena.jpg")
h, w, c = frame.shape
print("h:", h, "w: ", w, "c: ", c)
# 模型输入:1x3x300x300
# 1.0表示不对图像进行缩放设定图像尺寸为(300, 300)减去一个设定的均值(104.0, 177.0, 123.0)是否交换BGR通道和是否剪切都选False
blobimage = cv.dnn.blobFromImage(frame, 1.0, (300, 300), (104.0, 177.0, 123.0), False, False)
net.setInput(blobimage)
# forward之后模型输出:1xNx7
cvout = net.forward()
print(cvout.shape)
t, _ = net.getPerfProfile()
label = "Inference time: %.2f ms" % (t * 1000.0 / cv.getTickFrequency())
# 绘制检测矩形
# 只考虑后五个参数
for detection in cvout[0, 0, :]:
# 获取置信度
score = float(detection[2])
objindex = int(detection[1])
# 置信度>0.5说明是人脸
if score > 0.5:
# 获取实际坐标
left = detection[3] * w
top = detection[4] * h
right = detection[5] * w
bottom = detection[6] * h
# 绘制矩形框
cv.rectangle(frame, (int(left), int(top)), (int(right), int(bottom)), (255, 0, 0), thickness=2)
# 绘制类别跟得分
label_txt = "score:%.2f" % score
# 获取文本的位置和基线
(fw, uph), dh = cv.getTextSize(label_txt, font, font_scale, thickness)
cv.rectangle(frame, (int(left), int(top) - uph - dh), (int(left) + fw, int(top)), (255, 255, 255), -1, 8)
cv.putText(frame, label_txt, (int(left), int(top) - dh), font, font_scale, (255, 0, 255), thickness)
e2 = cv.getTickCount()
fps = cv.getTickFrequency() / (e2 - e1)
cv.putText(frame, label + (" FPS: %.2f" % fps), (10, 50), cv.FONT_HERSHEY_SIMPLEX, 1.0, (0, 0, 255), 2)
cv.imshow("face-dectection-demo", frame)
# 释放资源
cv.waitKey(0)
cv.destroyAllWindows()
# 视频文件执行之后会有警告但是不影响使用
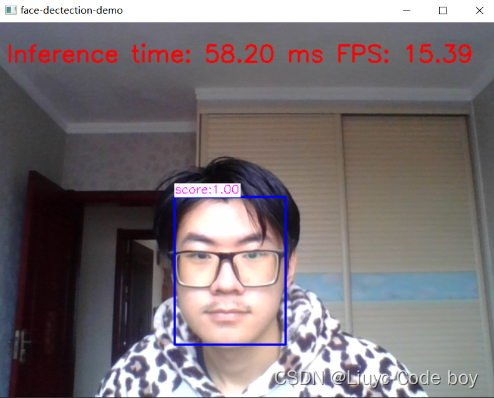
结果示例

# 人脸识别需要的文件
model_bin ="../data/opencv_face_detector_uint8.pb"
config_text = "../data/opencv_face_detector.pbtxt"
# 实时人脸识别摄像头
def video_face_demo():
# 记录开始时间
a = time.time()
print(a)
# 获取摄像头
cap = cv.VideoCapture(0)
font = cv.FONT_HERSHEY_SIMPLEX
font_scale = 0.5
thickness = 1
# 部署tensorflow模型
net = cv.dnn.readNetFromTensorflow(model_bin, config=config_text)
# 记录调用时长
print(time.time() - a)
print(time.strftime('%Y-%m-%d %H:%M:%S'))
while True:
e1 = cv.getTickCount()
# 获取每一帧的帧率
fps = cap.get(cv.CAP_PROP_FPS)
print(fps)
# 摄像头读取,ret为是否成功打开摄像头,true,false。 frame为视频的每一帧图像
ret, frame = cap.read()
# 摄像头是和人对立的将图像垂直翻转
frame = cv.flip(frame, 1)
if ret is not True:
break
h, w, c = frame.shape
print("h:", h, "w: ", w, "c: ", c)
# 模型输入:1x3x300x300
# 1.0表示不对图像进行缩放设定图像尺寸为(300, 300)减去一个设定的均值(104.0, 177.0, 123.0)是否交换BGR通道和是否剪切都选False
blobimage = cv.dnn.blobFromImage(frame, 1.0, (300, 300), (104.0, 177.0, 123.0), False, False)
net.setInput(blobimage)
# forward之后模型输出:1xNx7
cvout = net.forward()
print(cvout.shape)
t, _ = net.getPerfProfile()
label = "Inference time: %.2f ms" % (t * 1000.0 / cv.getTickFrequency())
# 绘制检测矩形
# 只考虑后五个参数
for detection in cvout[0, 0, :]:
# 获取置信度
score = float(detection[2])
objindex = int(detection[1])
# 置信度>0.5说明是人脸
if score > 0.5:
# 获取实际坐标
left = detection[3] * w
top = detection[4] * h
right = detection[5] * w
bottom = detection[6] * h
# 绘制矩形框
cv.rectangle(frame, (int(left), int(top)), (int(right), int(bottom)), (255, 0, 0), thickness=2)
# 绘制类别跟得分
label_txt = "score:%.2f" % score
# 获取文本的位置和基线
(fw, uph), dh = cv.getTextSize(label_txt, font, font_scale, thickness)
cv.rectangle(frame, (int(left), int(top) - uph - dh), (int(left) + fw, int(top)), (255, 255, 255), -1, 8)
cv.putText(frame, label_txt, (int(left), int(top) - dh), font, font_scale, (255, 0, 255), thickness)
e2 = cv.getTickCount()
fps = cv.getTickFrequency() / (e2 - e1)
cv.putText(frame, label + (" FPS: %.2f" % fps), (10, 50), cv.FONT_HERSHEY_SIMPLEX, 1.0, (0, 0, 255), 2)
cv.imshow("face-dectection-demo", frame)
# 10ms显示一张图片
c = cv.waitKey(10)
if c == 27:
break
# 释放资源
cap.release()
cv.waitKey(0)
cv.destroyAllWindows()
# 视频文件执行之后会有警告但是不影响使用
结果示例
学习参考
本系列所有OpenCv相关的代码示例和内容均来自博主学习的网站opencv_course