

【机器学习 吴恩达】2022课程笔记(持续更新)
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
一、机器学习
1.1 机器学习定义
计算机程序从经验E中学习解决某一任务T进行某一性能P通过P测定在T上的表现因经验E而提高
eg:跳棋程序
E: 程序自身下的上万盘棋局
T: 下跳棋
P: 与新对手下跳棋时赢的概率
1.2 监督学习 supervised learning
1.2.1 监督学习定义
给算法一个数据集其中包含了正确答案算法的目的是给出更多的正确答案
如预测房价回归问题、肿瘤良性恶性分类分类问题
1.3 无监督学习 unsupervised learning
1.3.1 无监督学习定义
只给算法一个数据集但是不给数据集的正确答案由算法自行分类。
如聚类
1.谷歌新闻每天收集几十万条新闻并按主题分好类
2.市场通过对用户进行分类确定目标用户
3.鸡尾酒算法:两个麦克风分别离两个人不同距离录制两段录音将两个人的声音分离开来只需一行代码就可实现但实现的过程要花大量的时间
1.3.2 聚类算法
二、单变量线性回归 linear regression
2.1 单变量线性函数
假设函数 hθ(x) = θ0 + θ1x
代价函数 平方误差函数或者平方误差代价函数
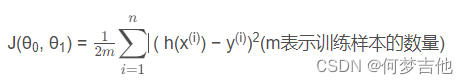
h(x(i))是预测值也写做y帽y(i)是实际值两者取差
分母的2是为了后续求偏导更好计算。
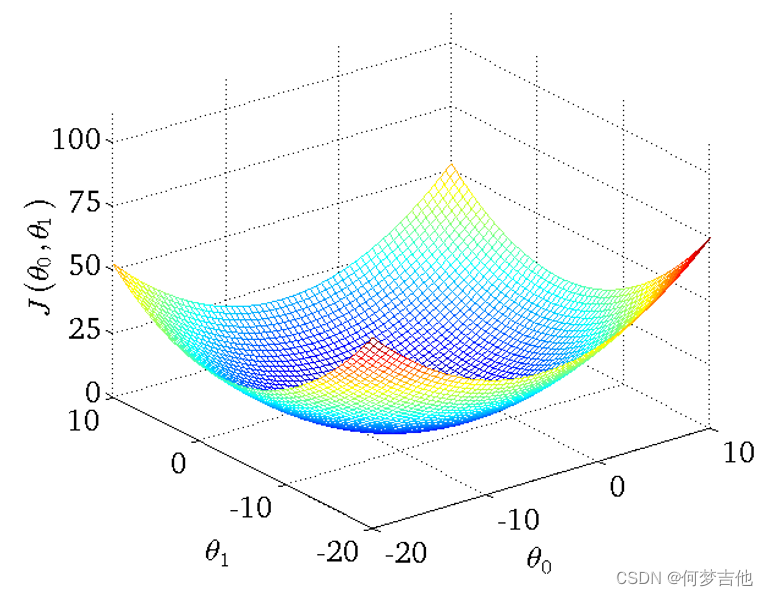
目标: 最小化代价函数即minimize J(θ0, θ1)
- 得到的代价函数的 三维图如下
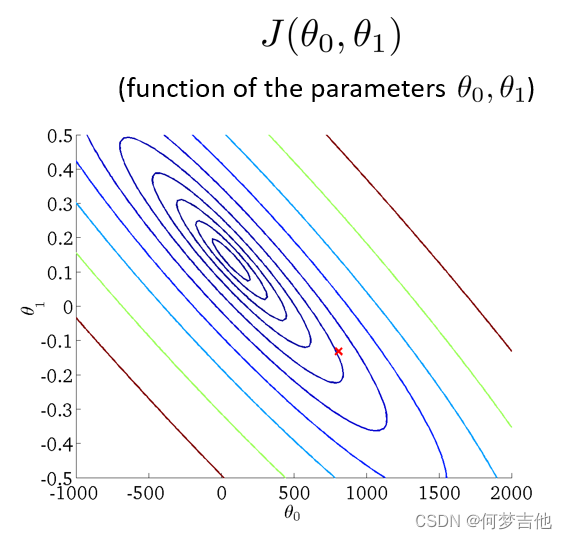
- 将三维图平面化 等高线图 contour plot
等高线的中心对应最小代价函数
2.2 梯度下降算法 Gradient Descent algorithm
算法思路
- 指定θ0 和 θ1的初始值
- 不断改变θ0和θ1的值使J(θ0,θ1)不断减小
- 得到一个最小值或局部最小值时停止
梯度: 函数中某一点(x, y)的梯度代表函数在该点变化最快的方向
选用不同的点开始可能达到另一个局部最小值
梯度下降公式

-
θ0和θ1应同步更新否则如果先更新θ0会使得θ1是根据更新后的θ0去更新的与正确结果不相符
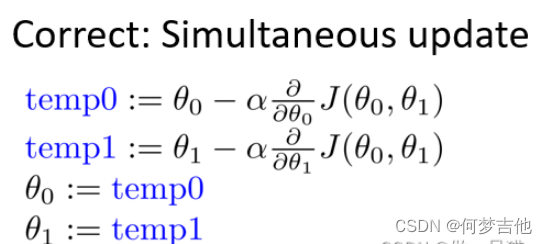
-
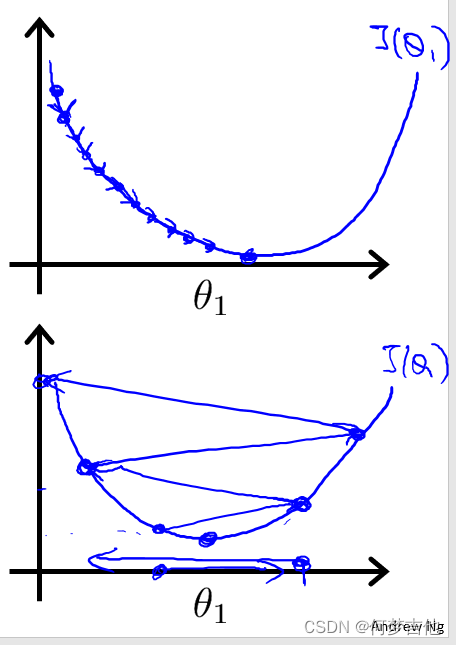
原理:偏导表示的是斜率斜率在最低点左边为负最低点右边为正。 在移动过程中偏导值会不断变小进而移动的步幅也不断变小最后不断收敛直到到达最低点;在最低点处偏导值为0不再移动
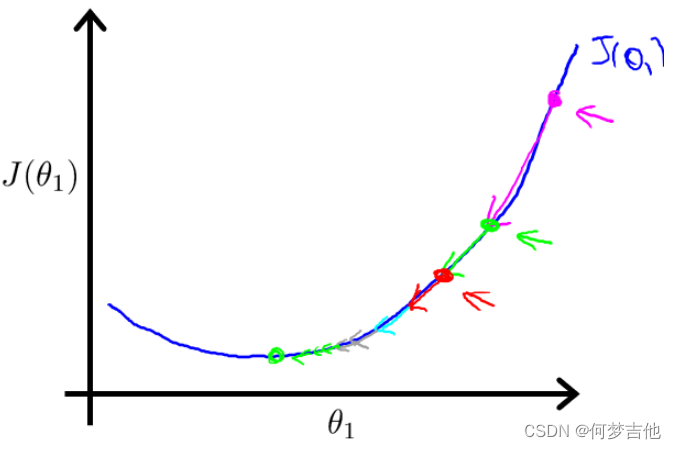
关于α的选择
如果α选择太小会导致每次移动的步幅都很小最终需要很多步才能最终收敛
如果α选择太大会导致每次移动的步幅过大可能会越过最小值无法收敛甚至会发散
2.3 用于线性回归的梯度下降 ——Batch梯度下降
-
公式推导

英文积累
- with respect to 关于
- training example 训练示例
- derivative 导数 derivation 推导
- 1 over m m分之一
- sum of i equals 1 through m i从1到m的总和
- calculus 微积分
- convergence 收敛
- local minimum 局部最小值 global
- convex function 凸函数碗型一个局部最小值
- intuitive name 直观的名称
- subset 子集
- automate 使自动化
- plotting routines 绘图例程