

吴恩达机器学习课程笔记:多元梯度下降法
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
1.吴恩达机器学习课程笔记多元梯度下降法
仅作为个人学习笔记若各位大佬发现错误请指正
1.1 多元特征变量
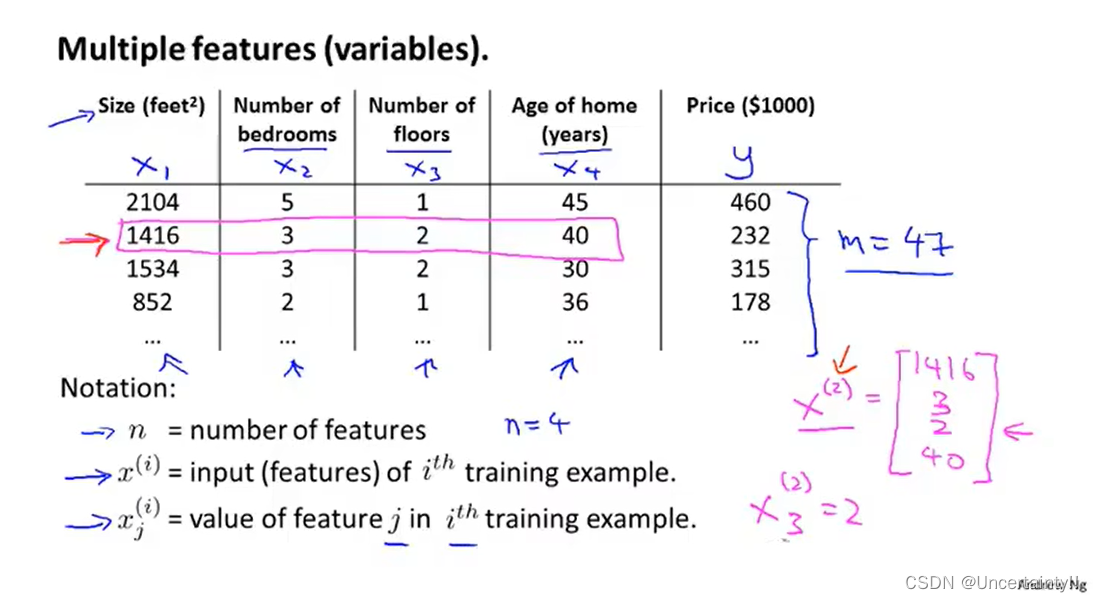
每一列代表一个特征例如房屋大小、卧室数量、楼层数、房屋年龄
n
n
n代表特征数量
每一行代表一个样本例如第二个样本
x
(
2
)
=
[
1416
,
3
,
2
,
40
]
T
x^{(2)}=[1416,3,2,40]^T
x(2)=[1416,3,2,40]T第
i
i
i个训练样本
x
(
i
)
x^{(i)}
x(i)
m
m
m代表样本容量
x
j
(
i
)
x^{(i)}_j
xj(i)代表第
i
i
i个样本中的第
j
j
j个特征
1.2 多元特征的假设函数
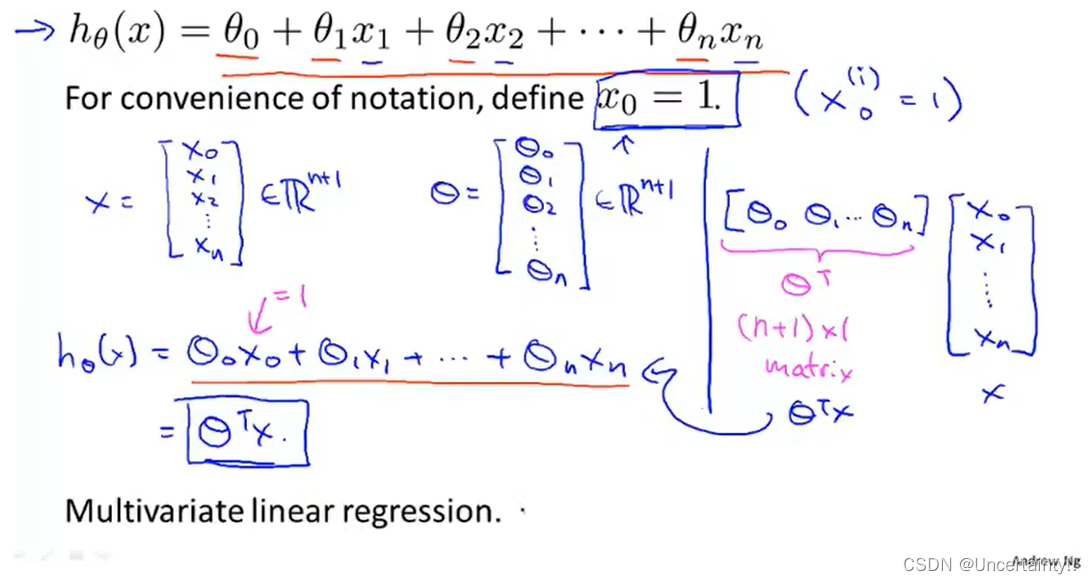
为了方便形式简洁我们把假设函数写为向量内积形式这样也方便我们直接使用线性代数的函数库
1.3 多元梯度下降法

左侧当特征个数为1时的梯度下降法右侧当特征个数大于等于1时的梯度下降法
1.4 特征缩放归一化
因特征的不同特征的值的范围也不同这会导致梯度下降会非常缓慢我们对特征进行处理将所有特征都归一化处理将特征的值都处理到同一个较小范围内这样在进行梯度下降就会比处理前会快速很多

左侧是未对特征进行处理的情况这种情况等高线整体上会比较细长梯度下降时较缓慢
右侧是对特征进行缩放的情况这种情况等高线整体上会比较圆润梯度下降时较快速
缩放的范围可以大致定为
[
−
1
,
1
]
[-1,1]
[−1,1]也可以根据具体情况自行决定

1.5 特征缩放均值归一化
另一种特征缩放的方法均值归一化这种方法类似于将随机变量标准化的过程
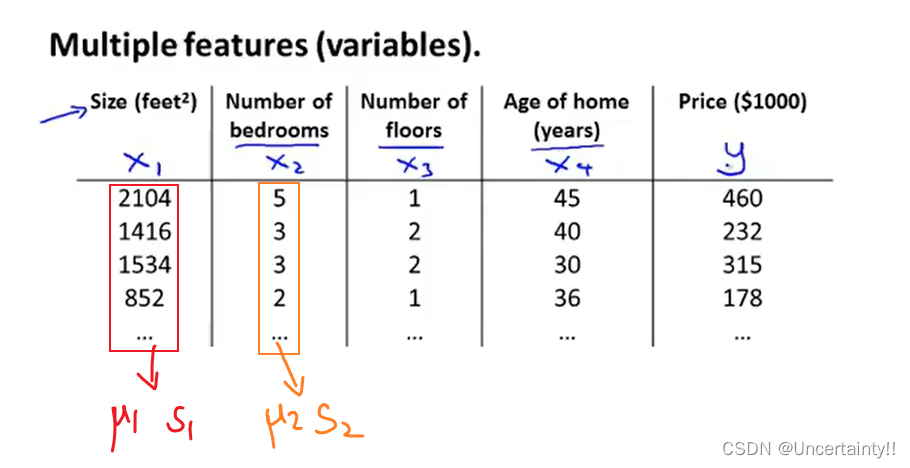
可以先行计算出每个特征的均值
μ
i
\mu_i
μi和特征的值的范围
S
i
S_i
Si最大值-最小值
x
i
=
x
i
−
μ
i
S
i
x_i=\frac{x_i-\mu_i}{S_i}
xi=Sixi−μi
根据上式对每一个特征中的每一个值进行均值归一化处理

1.6 学习率大小对多元梯度下降的影响
笔记来源多元梯度下降法II.–.学习率
通过迭代步数–代价函数值函数图像我们可以判断梯度下降是否最终收敛了理想情况是随着迭代步数的增大代价函数值随之下降在自动收敛检测中我们大致认为当代价函数值小于等于
1
0
−
3
10^{-3}
10−3时梯度下降就达到了收敛。一般选择一个合适的阈值还是很困难的为了检查梯度下降算法是否收敛通常情况下我们可以直接看下面这种图像而不去进行自动收敛检测。

学习率太小则收敛速度较慢
学习率太大则可能不是每次迭代代价都会下降也可能不会收敛
学习率我们可以选取
0.0001
0.001
0.01
0.1
0.00010.0010.010.1
0.00010.0010.010.1 每次扩大10倍来观察效果
也可取
0.0003
0.003
0.03
0.3
0.00030.0030.030.3
0.00030.0030.030.3
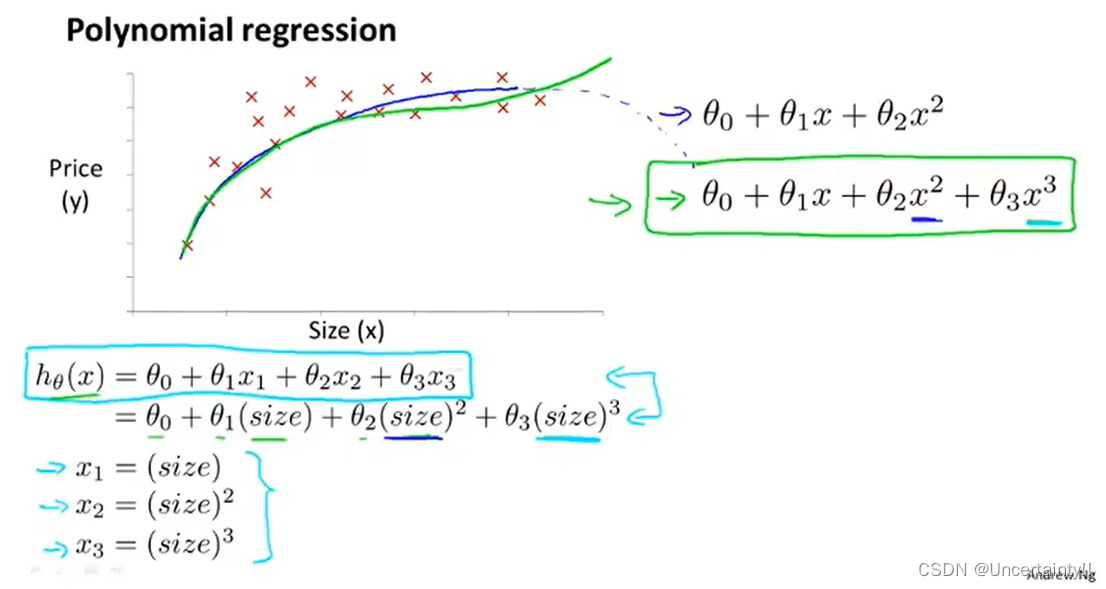
1.7 多项式回归
笔记来源特征和多项式回归
有时可以通过原有特征来定义新特征的方法来获得较好或教简单的模型也可以只选其中一些特征所以说其实并不是所有特征都要采用我们可以只采用其中一些特征之后我们会学习到一些算法它们会自动选择使用什么特征
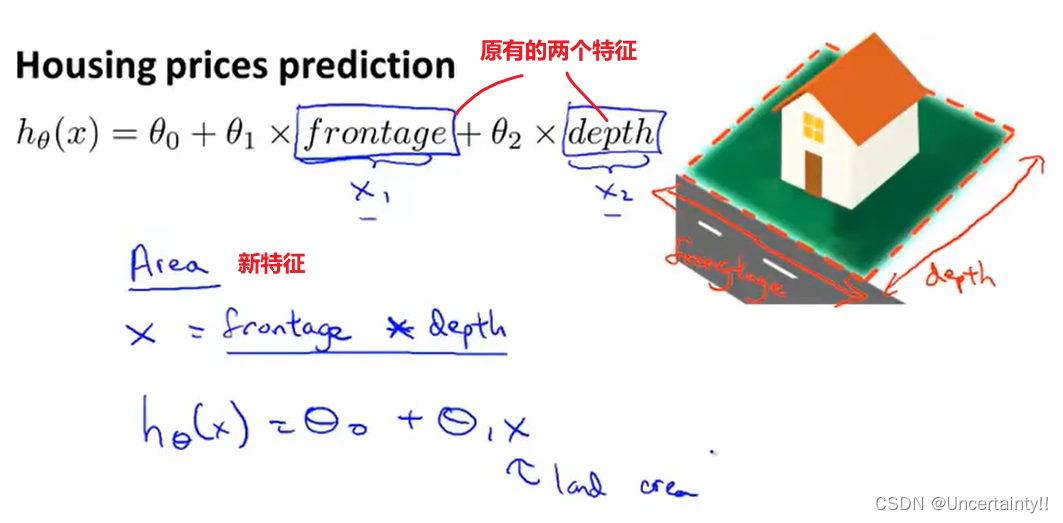
我们最终目的是通过这些已有特征来预测房价我们可以根据生活中关于房价的经验来选择较为合适的模型比如起初我们选择了二次函数作为模型但我们知道二次函数是凹或凸的房子越大房价理应越高不会呈现出类似二次函数的形状这里我们就应该做出调整选用三次函数作为模型当然也可以选用其他合适模型诸如此类。之后我们会学习到一些算法它们会根据已有数据选择较为合适的模型。
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |