

机器学习之网络优化(侧重学习率调整)
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
人工智能的问题在于他实在让人捉摸不透。——文森特
非凸优化问题
数学中如二维曲线 y = x 2 y=x^2 y=x2当 x = 0 x=0 x=0时 y y y存在极小值 y m i n = 0 y_{min}=0 ymin=0。而求解该最小值利用导数 y ′ = 2 x y^{'}=2x y′=2x,令 y = 0 y=0 y=0,有 x = 0 x=0 x=0即可。
对于高维空间变量求解难度有所增加如非凸优化问题中高维变量如三维变量
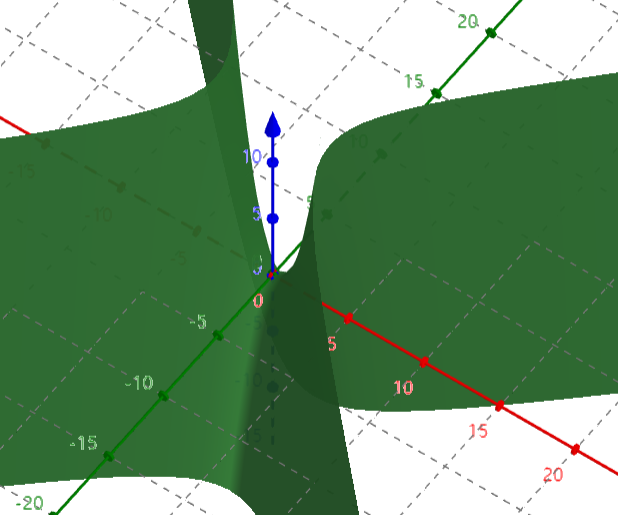
如上图中三个变量假设红色为
x
x
x轴绿色为
y
y
y轴蓝色为
z
z
z轴。此时已经处于
x
x
x方向的最低点但是
y
y
y方向不是最低点而我们优化的目的在于寻找局部最小值每一维度熵都需要处于最低点那么上图很明显不满足要求。但是每一维度都处于最低点也是以概率
p
p
p发生的极低事件假设100个变量那么全部处于最低点概率为
p
100
p^{100}
p100。
针对该问题的可解决方式有周期性调整学习率——循环学习率和带热重启的随机梯度下降。
-
循环学习率
将学习率在一个区间内周期性先增大、再缩小。
设每一个周期迭代次数为 2 Δ T 2\Delta T 2ΔT即增大时间占前 Δ T \Delta T ΔT缩小时间占前 Δ T \Delta T ΔT.对于第 t t t次迭代循环周期次数 m = ⌊ 1 + t 2 Δ T ⌋ m=⌊1+\frac{t}{2\Delta T}⌋ m=⌊1+2ΔTt⌋,学习率为 α t = α m i n m + ( α m a x m − α m i n m ) ( 1 − m a x ( 0 , 1 − b ) ) \alpha_t = \alpha_{min}^m + (\alpha_{max}^m-\alpha_{min}^m)(1-max(0,1-b)) αt=αminm+(αmaxm−αminm)(1−max(0,1−b)),其中 α m i n m \alpha_{min}^m αminm和 α m a x m \alpha_{max}^m αmaxm为第 m m m个周期的学习率下界限与上界限 b = ∣ t Δ T − 2 m + 1 ∣ b=|\frac{t}{\Delta T} - 2m+1| b=∣ΔTt−2m+1∣。
α t = α m i n m + ( α m a x m − α m i n m ) ( 1 − m a x ( 0 , 1 − b ) ) \alpha_t = \alpha_{min}^m + (\alpha_{max}^m-\alpha_{min}^m)(1-max(0,1-b)) αt=αminm+(αmaxm−αminm)(1−max(0,1−b))该公式从不精确的角度来讲当 t Δ T \frac{t}{\Delta T} ΔTt为偶数时学习率取下界当 t Δ T \frac{t}{\Delta T} ΔTt为奇数时学习率取上界。 -
带热重启的随机梯度下降
该方法的原理为将学习率每隔一定周期后重新设值再进行学习率衰减。
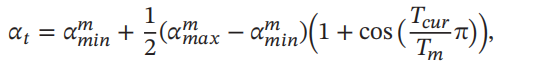
其中 T c u r T_{cur} Tcur为上一次重启之后的epoch数量 T m = T m − 1 × 放大因子 T_m= T_{m−1} × 放大因子 Tm=Tm−1×放大因子
此外还有AdaGrad算法、RMSprop算法、AdaDelta算法等用于调整学习率。
优化算法
小批量梯度下降
为了减轻对计算资源的压力一般不采取同时将所有训练集进行训练而是分批次进行。
若神经网络函数为
f
(
x
;
θ
)
f(x;\theta)
f(x;θ),
θ
\theta
θ为网络参数小批量的意思为每次选取训练集中的部分数据进行训练如训练集用
s
s
s表示那么选取
n
n
n个样本表示为
s
n
=
{
x
t
,
y
t
}
t
=
1
n
s_n=\{x^t,y^t\}_{t=1}^n
sn={xt,yt}t=1n则每次迭代时损失函数关于参数
θ
\theta
θ的偏导数为
ϑ
(
L
θ
)
=
1
n
∑
(
x
,
y
)
∈
s
n
ϑ
L
(
y
,
f
(
x
;
θ
)
)
ϑ
θ
\begin{aligned} \vartheta (L_{\theta})=\frac{1}{n}\sum_{(x,y) \in s_n}\frac{\vartheta L(y,f(x;\theta))}{\vartheta \theta} \end{aligned}
ϑ(Lθ)=n1(x,y)∈sn∑ϑθϑL(y,f(x;θ))
更新参数
θ
\theta
θ为(
t
t
t为迭代次数,
α
为学习率参数
\alpha为学习率参数
α为学习率参数)
θ
t
=
θ
t
−
1
−
α
ϑ
(
L
θ
)
\begin{aligned} \theta_t = \theta_{t-1} - \alpha \vartheta (L_{\theta}) \end{aligned}
θt=θt−1−αϑ(Lθ)
PS:批量大小对网络参数优化影响较大批量大小越大随机梯度的方差越小引入的噪声也越小训练也越稳定因此可以设置较大的学习率.而批量大小较小时需要设置较小的学习率否则模型会不收敛。——邱锡鹏《神经网络与深度学习》
"随机梯度的方差越小"这句话可以浅理解为每次训练的样本数量越多越接近每轮训练整个训练集的真实梯度所以偏离的方差值更小。
学习率通常要随着批量大小的增大而相应地增大。线性缩放规则批量增加n倍学习率相应增加n倍。
确定的批次大小决定了每次的
e
p
o
c
h
epoch
epoch值
1
e
p
o
c
h
=
t
o
t
a
l
_
d
a
t
a
b
a
t
c
h
_
s
i
z
e
I
t
e
r
a
t
i
o
n
1 \space epoch=\frac{total\_data}{batch\_size}Iteration
1 epoch=batch_sizetotal_dataIteration
Keskar N S, Mudigere D, Nocedal J, et al., 2016. On large-batch training for deep learning: Generalization gap and sharp minima[J]. arXiv preprint arXiv:1609.04836.
该论文指出批量越大越有可能收敛到尖锐最小值批量越小越有可能收敛到
平坦最小值.
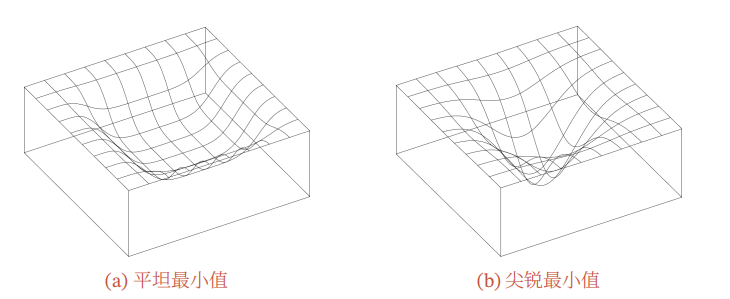
(该图来自——邱锡鹏《神经网络与深度学习》)
学习率调优
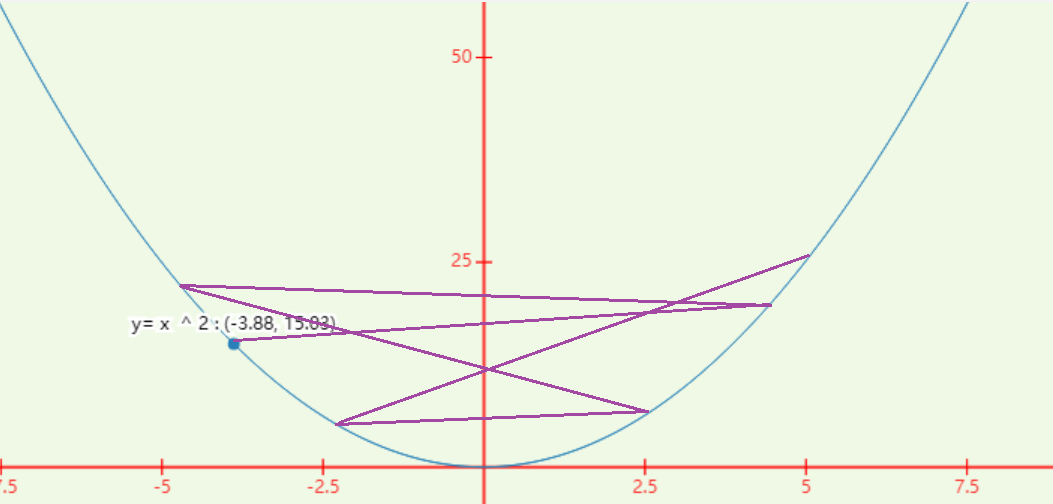
学习率在训练过程中并非一成不变在训练后期接近收敛时需要将学习率调小以防止振荡发生如
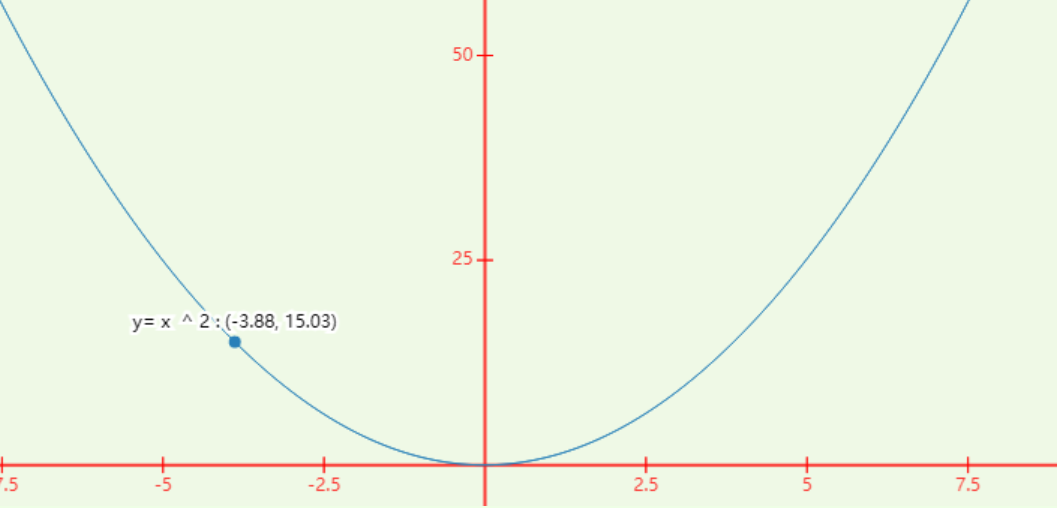
若处于上图中的
(
−
3.88
,
15.03
)
(-3.88,15.03)
(−3.88,15.03)学习率过大可能导致下图情形紫色为更新过程可以看见难以回到最低点左右振荡严重
常见的调优的方法较多有分段常数衰减、逆时衰减、指数衰减、自然指数衰减、余弦衰减等。
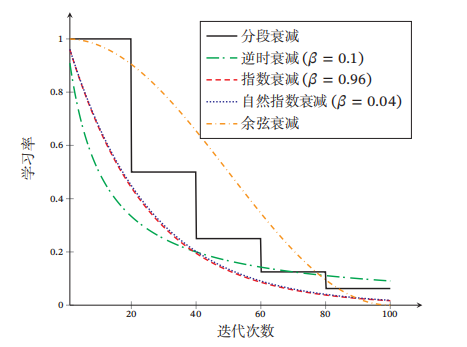
(不同学习率衰减方法的比较——该图来自邱锡鹏《神经网络与深度学习》)
训练初期不稳定的问题
网络模型在最初训练时参数的初值由随机值设定那么容易出现训练开始阶段不稳定那么为了解决该问题常用的方法——学习率预热。
学习率预热的原理为
在训练阶段将最初的几个epoch的学习率使用较小值待训练较为稳定时再使用最初设定的学习率数学表达式为
α
t
′
=
m
n
α
0
,
n
≥
m
≥
1
\alpha_t^{'}=\frac{m}{n}\alpha_0,\space n \ge m \ge 1
αt′=nmα0, n≥m≥1,其中
n
n
n为最初的几个epoch数量
m
m
m为当前epoch次数。