

机器学习知识总结 —— 20.使用朴素贝叶斯进行数据分类
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
文章目录
作为一种监督学习分类方法在上一章中我们已经介绍过它的数理原理。现在我们开始来实现一个简单的朴素贝叶斯分类的算法这样我们能更好的理解它是怎么运作的。
准备基础数据
首先还是有请我们的好朋友 numpy让它给我们生成一些数据 。
# 生成三类数据每类数据有100个样本
np.random.seed(42)
class1 = np.random.randn(100, 2) * 0.5 + np.array([1, 1])
class2 = np.random.randn(100, 2) * 0.5 + np.array([-1, -1])
class3 = np.random.randn(100, 2) * 0.5 + np.array([1, -1])
# 将数据集分为训练集和测试集
X_train = np.concatenate([class1[:70], class2[:70], class3[:70]])
y_train = np.concatenate([np.zeros(70), np.ones(70), 2 * np.ones(70)])
X_test = np.concatenate([class1[70:], class2[70:], class3[70:]])
y_test = np.concatenate([np.zeros(30), np.ones(30), 2 * np.ones(30)])
这样我们的数据可以分为测试集和训练集两部分这里我们给了全部的样本分别以标签123进行分类。
计算先验概率
在朴素贝叶斯分类器中我们需要计算每个类别的先验概率。先验概率指的是在考虑任何特征的情况下一个样本属于某个类别的概率。
先验概率的计算公式为 P ( Y = c k ) P(Y=c_k) P(Y=ck)其中 Y Y Y表示类别变量 c k c_k ck表示第 k k k个类别。因为我们假设每个类别的样本数相等所以可以用每个类别的样本数除以总样本数来估计先验概率。
具体到代码计算先验概率的逻辑如下
- 首先创建一个大小为3的全零向量prior_probs用于存储每个类别的先验概率
- 针对每个类别使用Numpy的sum函数计算出训练集y_train中等于该类别的样本数量并将其除以y_train的长度得到该类别的先验概率
- 将该类别的先验概率存储在prior_probs向量的相应位置上。
最终prior_probs向量中存储了每个类别的先验概率。
于是我们可以得到下面这样的代码
prior_probs = np.zeros(3)
for i in range(3):
prior_probs[i] = np.sum(y_train == i) / y_train.shape[0]
计算条件概率
条件概率指的是在已知一个样本属于某个类别的情况下该样本的某个特征取某个值的概率。
具体到高斯朴素贝叶斯分类器中我们假设每个特征在每个类别中的条件概率都是高斯分布。因此我们需要计算每个类别中每个特征的均值和标准差从而得到该特征在该类别下的高斯分布。这样在预测时我们就可以使用每个特征在每个类别下的高斯分布来计算该样本在该类别下的概率。
具体到代码计算每个特征在每个类别中的条件概率的逻辑如下
- 首先创建两个大小为(3,特征数)的全零矩阵mean_vectors和std_vectors用于存储每个类别中每个特征的均值和标准差
- 针对每个类别使用Numpy的mean函数计算出训练集X_train中该类别下每个特征的均值同时使用Numpy的std函数计算出该类别下每个特征的标准差
- 将该类别下每个特征的均值和标准差存储在mean_vectors和std_vectors矩阵的相应位置上。
最终mean_vectors和std_vectors矩阵中存储了每个类别中每个特征的均值和标准差用于计算条件概率。在预测时我们将测试集中的每个样本输入到高斯分布中计算出该样本在每个类别下的概率并选择概率最大的类别作为预测结果。
# 计算每个特征在每个类别中的条件概率
mean_vectors = np.zeros((3, X_train.shape[1]))
std_vectors = np.zeros((3, X_train.shape[1]))
for i in range(3):
mean_vectors[i] = np.mean(X_train[y_train == i], axis=0)
std_vectors[i] = np.std(X_train[y_train == i], axis=0)
预测分布
对于测试集中的每个样本我们需要计算它在每个类别下的概率从而得到该样本最可能属于哪个类别。在高斯朴素贝叶斯分类器中我们假设每个特征在每个类别中的条件概率都是高斯分布因此可以使用高斯分布的概率密度函数来计算每个特征值在每个类别中的条件概率。具体地我们可以利用每个特征在每个类别下的均值和标准差将该特征值输入到高斯分布的概率密度函数中从而得到该特征值在该类别下的概率。最后我们将每个特征的条件概率相乘再乘以该类别的先验概率得到该样本在该类别下的概率。在计算完每个类别下该样本的概率后我们选择概率最大的类别作为该样本的预测标签。
- 首先创建一个大小为y_test长度的全零向量y_pred用于存储每个测试集样本的预测标签
- 针对每个测试集样本使用Numpy的prod函数计算出该样本在每个类别下每个特征的条件概率再将每个特征的条件概率相乘乘以该类别的先验概率得到该样本在每个类别下的概率
- 将该样本的预测标签设为概率最大的类别。
最终y_pred向量中存储了每个测试集样本的预测标签可以与真实标签进行比较以计算准确率。
# 预测测试集的标签
y_pred = np.zeros(y_test.shape[0])
for i, x in enumerate(X_test):
# 计算x在每个类别下的概率
probs = np.zeros(3)
for j in range(3):
probs[j] = np.prod(1 / (np.sqrt(2 * np.pi) * std_vectors[j]) * np.exp(-(x - mean_vectors[j]) ** 2 / (2 * std_vectors[j] ** 2))) * prior_probs[j]
y_pred[i] = np.argmax(probs)
验证结果
主要部分结束我们看看输出的结果如何
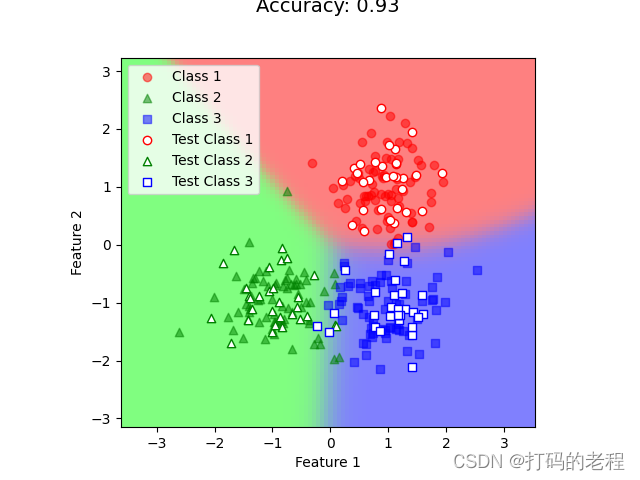
最终的准确度是93%总体还是不错的。当然在现实中我们要处理的特征肯定不止两维这里只是一个简单的示例。