

[Zombodb那些事]Zombodb执行引擎
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
Zombodb执行引擎
0.前言
我们在使用Zombodb时会使用一些SQL查询例如
CREATE EXTENSION zombodb;
DROP EXTENSION zombodb;
CREATE INDEX idxtest_analyze_text ON test_analyze_text USING zombodb ((test_analyze_text.*));
DROP TABLE idxtest_analyze_text;
ALTER INDEX idxbook SET (options='id=<public.book_content.idxcontent>book_id');
SELECT *
FROM book
WHERE book ==> 'author:shakespeare and users.full_name:"John Doe"'这里罗列的SQL不全只是给大家简单看一下Zombodb的基本用法像这些SQL从PostgreSQL(以下简称PG)传递过来到底经历了什么流程上面不同类别的SQL语句到底会怎么去执行ES的Bulk请求的上游是谁谁来管理ES请求==>操作符又是怎么识别的
带着这些疑问我们来开始Zombodb执行引擎。
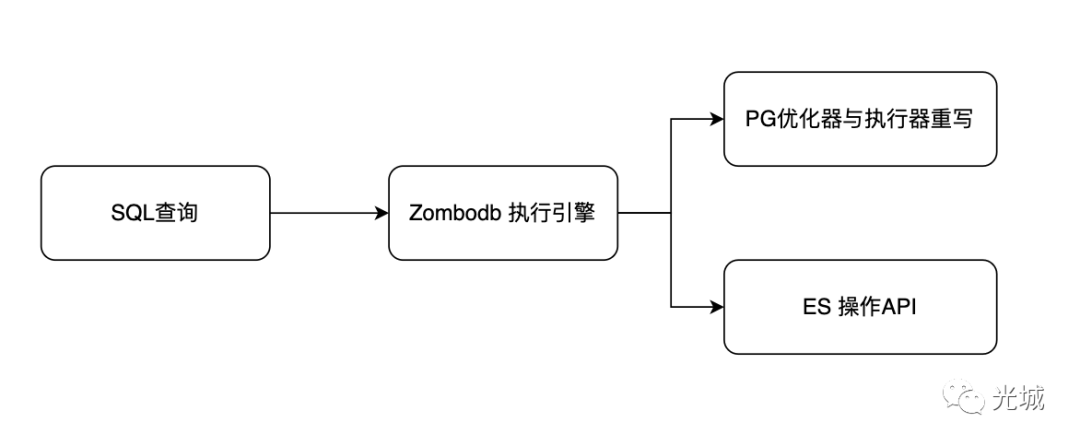
Zombodb执行引擎不像PG那样复杂能搞若干年Zombodb的执行引擎简单用一幅图概括其核心工作。
PG优化器、执行器重写
后面文章会详细展开
ES操作API
没错这里就是来管理上一篇文章写的ES Bulk请求。
看样子是比简单的但是深挖下去这一篇文章搞不定所以我先来个执行引擎轮廓吧。
1.Hooks
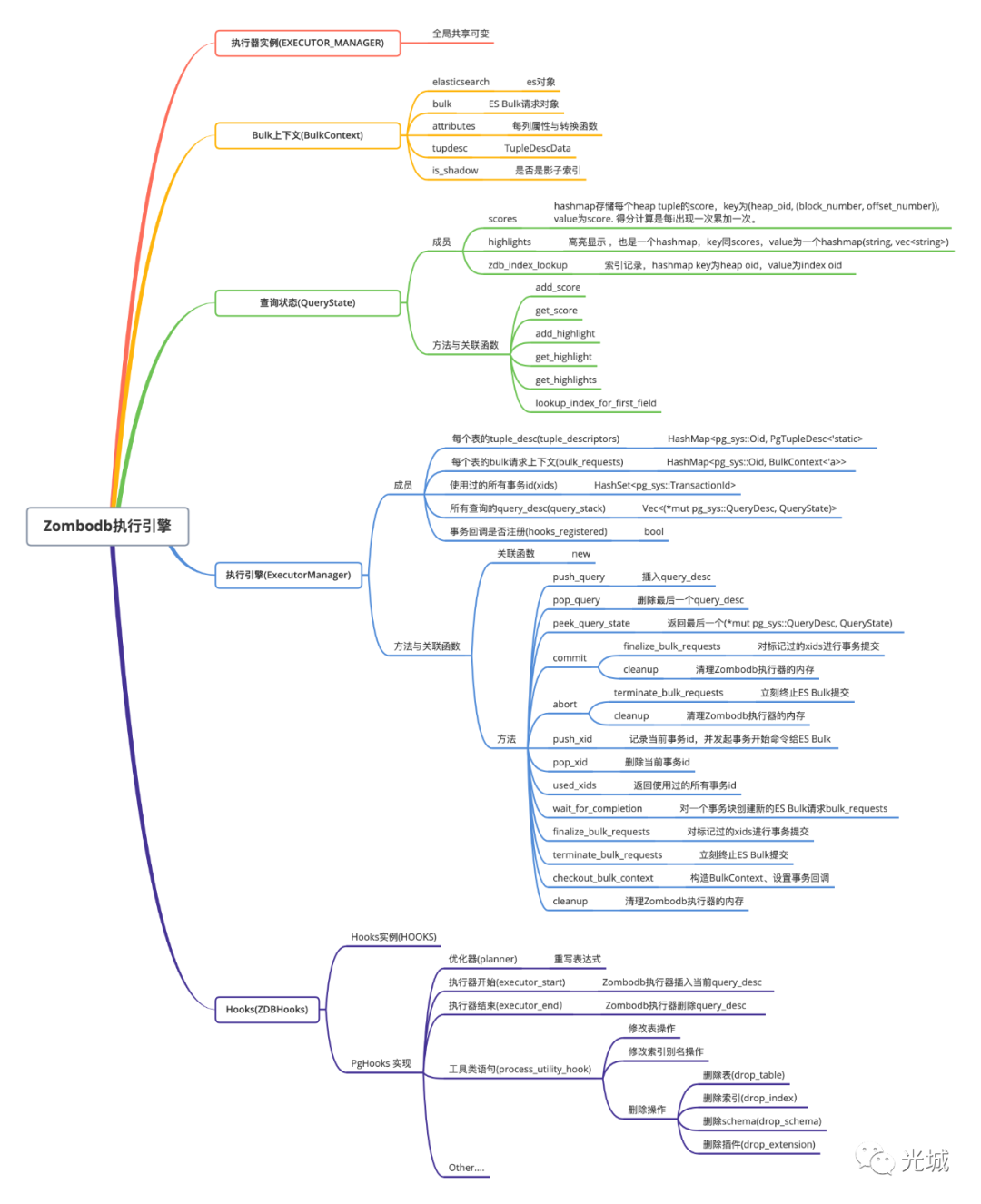
Zombodb执行引擎管理了很多HooksZombodb在全局有一个可变的单例对象所有的操作都是通过EXECUTE_MANAGER来发起调用。
简单说一下Hooks是什么PG代码里面会提供给第三方回调接口这便是Hooks逻辑为
if (hook) {
your_hook();
} else {
default_behavior();
}这里写了一段伪代码如果你定义了hook那么就会走你的逻辑不然就走PG默认行为所以Hooks就是一堆这种hook的组合。Zombodb这边实现了
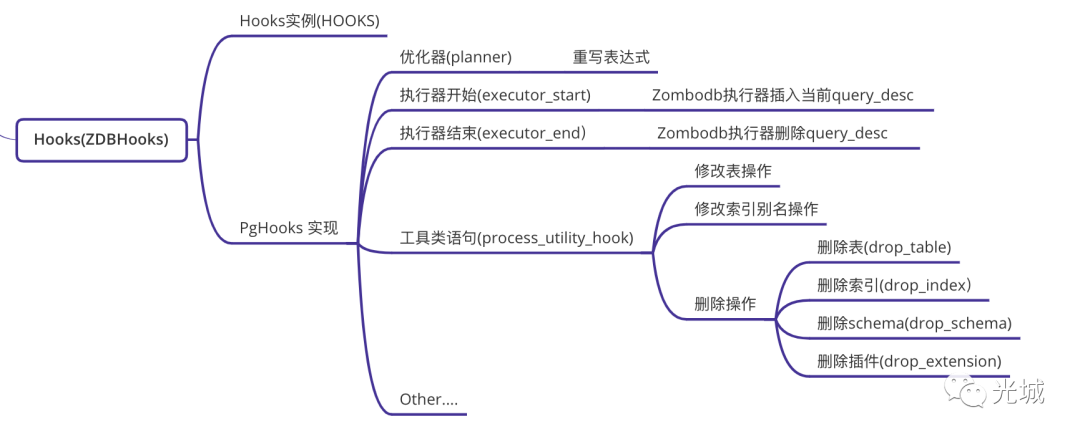
优化器Planner
优化器里面做了不少工作例如ctid重写表达式重写等等这一块后面打算单独讲。
PG执行器开始 executor_start
执行器开始在Zombodb这边实现比较简单就是内部维护了一个query_stack结构往里面插入即可query_stack结构在本文后续讲这里理解为一个Vector即可。
PG执行器结束 executor_end
执行器结束在Zombodb这边实现就更简单了直接从Vector的query_stack中pop出去就完事了。
可以看到PG执行器的Hook逻辑就是类似于现场还原的一个实现。
工具类语句hook process_utility_hook
这里就是实现我们修改表、修改索引别名、删除操作。这里实现比较简单了看一下代码就懂了。
当然还有其他我们内部定制的Hook这些就不赘述。
2.执行引擎
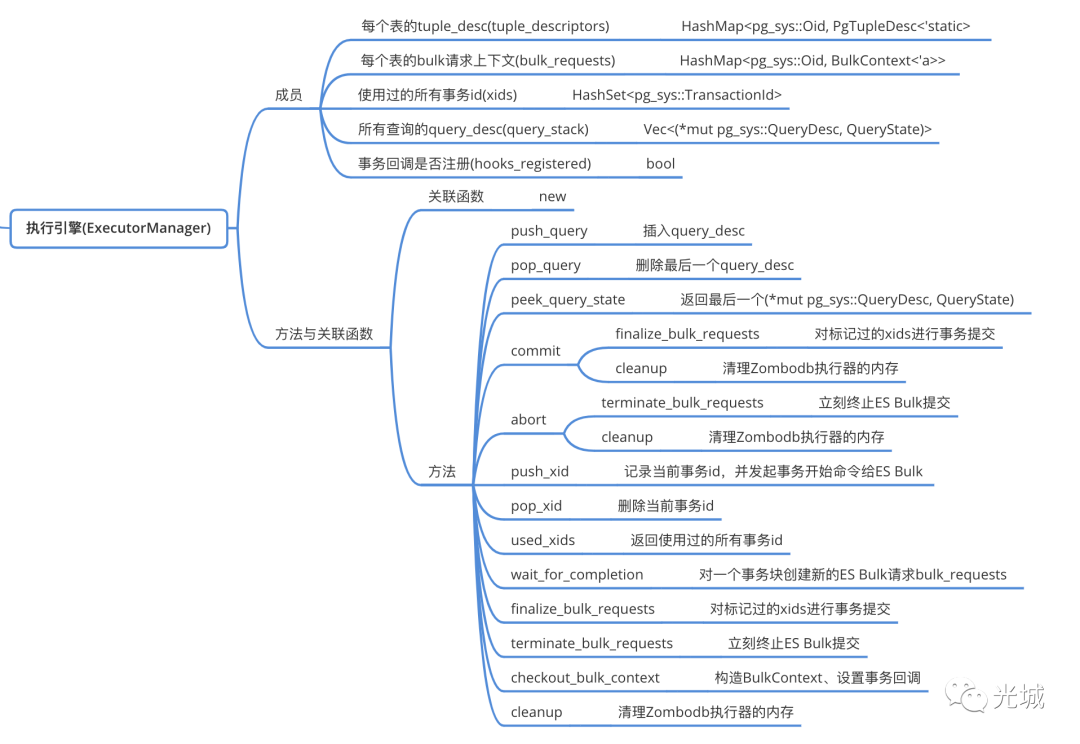
接下来就是Zombodb执行引擎的结构了内部包括
每个表的元组描述符
元组描述符在这里表示你查询的时候的某些列信息。例如这里有一个普通的查询这里id就是tupledesc另一个工具类查询语句结果中的QUERY PLAN就是tupledesc这些内容会在PG里面用TupleDescData存起来。

每个表的bulk请求上下文
bulk请求是什么可以看上一篇文章这里存储的是BulkContex数据结构这个数据结构在Zombodb里面结构如下图所示具体可以看图中注释没有提到的便是is_shadow字段这个表示当前索引是否是影子索引。
所谓影子索引表示的它是否被包了一层然后用户直接看不到需要回溯看UDF才理解。例如下面这个便是影子索引。
---非影子索引
SELECT *
FROM book
WHERE book ==> 'shakespeare';
---影子索引
SELECT *
FROM book
WHERE my_shadow_func(book) ==> 'shakespeare';
CREATE OR REPLACE FUNCTION my_shadow_func(anyelement)
RETURNS anyelement
IMMUTABLE STRICT
LANGUAGE c AS '$libdir/zombodb.so', 'shadow_wrapper';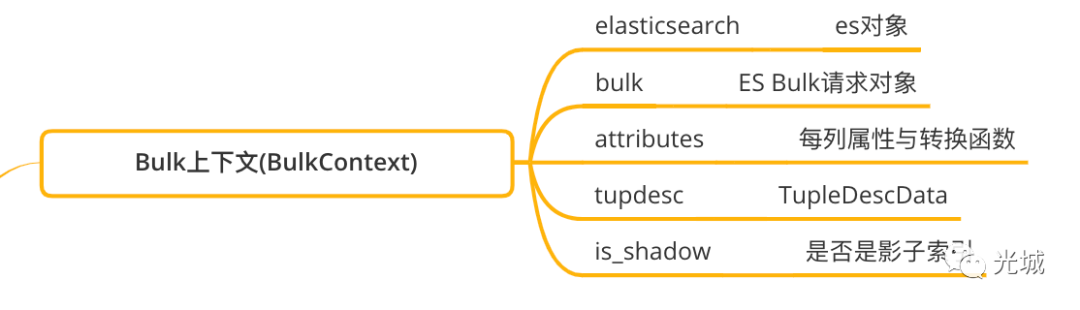
使用过的所有事务id
一个完整的事务可能包括事务发起、事务中、事务提交、事务回滚等其中多个步骤。而Zombodb执行引擎里面使用了一个hashset存储之前已经提交的所有事务id防止重复提交。对外的API如下
事务开始push_xid将当前事务id放入hashset中并发起Bulk事务正在进行的请求。
事务提交commit等待所有hashset中的事务id被提交如果有失败就会panic掉提交后释放执行引擎的所有成员占用的内存。
事务回滚abort给ES Bulk发起立刻终止请求并释放执行引擎的所有成员占用的内存。
所有查询的query_desc
这个就是前面提到的query_stack有一个数组维护里面存储了一个tuple(查询描述符查询状态)。
事务回调是否注册标记
在PG/GP里面会有回调函数用户可以进行注册例如两阶段提交中/后的处理回调都可以自定义逻辑例如在Zombodb里面实现了PreCommit、Abort这里便会调用前面的commit与abort。
设置完毕这些回调函数需要设置注册标记为true因为这些只需要注册一次就行(执行引擎对象是全局单例)。
3.查询状态
Zombodb中提供了两个比较特殊的函数
zdb.scores
zdb.highlights
一个可以用来返回ES的score并放到order by之后用来排序。
另一个是使用ES的文档高亮特性对查询结果进行高亮显示。
为何这里会有一个查询状态呢单独还放到了执行引擎里面像其他的zdb查询缺没有放到执行引擎里面例如
zdb.terms要回答这个问题首先我们需要知道这两个函数的实现入参都有一个ctid而根据Zombodb代码中的注释与调用入口可以发现这两个放到执行引擎里面是为了方便解决HOT问题。
更复杂的解释等后面研究一下这里面的门道吧还有不少东西探究。
本节完~