

MLACP 2.0:一种更新的抗癌肽预测机器学习工具
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
期刊Computational and Structural Biotechnology
作者
- Le Thi Phan
- Hyun Woo Park
- Thejkiran Pitti
- Thirumurthy Madhavan
- Young-Jun Jeon Balachandran
Manavalan
单位
韩国 成均馆大学生物技术与生物工程学院综合生物技术系 计算生物学和生物信息学实验室
摘要
抗癌肽是一种新型的抗癌药物副作用小比化疗和靶向治疗更有效。从序列信息预测抗癌肽是免疫信息学中最具挑战性的任务之一。在过去的十年里已经提出了基于机器学习的方法来从肽序列中识别ACP活性。这些方法包括我们之前的方法MLACP(开发于2017年)它对抗癌研究产生了重大影响。MLACP工具已被研究界广泛使用但其健壮性仍需显著提高才能继续得到实际应用。在本研究中首次构建了用于ACP研究的大型非冗余训练和独立数据集。使用训练数据集该研究探索了广泛的特征编码并使用七种不同的传统分类器开发了各自的模型。随后根据分类器的性能为每个分类器选择基于编码的模型的子集其预测分数被串联并通过卷积神经网络(CNN)进行训练其对应的预测器被命名为MLACP 2.0。使用一个非常多样化的独立数据集对MLACP 2.0进行的评估显示出出色的性能并且显著优于最近的ACP预测工具。此外与基于CNN的嵌入模型和传统的单一模型相比MLACP 2.0在交叉验证和独立评估中表现出更好的性能。因此我们预计我们提出的MLACP 2.0将通过使发现新的ACP变得更容易从而促进假设驱动实验的设计。
MLACP2.0可在https://balalab-skku.org/mlacp2.上免费获得
1. Introduction
癌症是对人类健康的突出威胁之一在发达国家和发展中国家随着预期寿命的延长癌症往往与更高的死亡率有关。2018年世界卫生组织(WHO)和国际癌症研究机构(IARC)报告称癌症造成1810万新病例和960万死亡[2]。癌症是由异常细胞的不受控制的增殖引起的这些细胞侵入正常的组织和器官并以不受控制的方式繁殖。癌症的复杂性和异质性使其治疗变得困难。因此癌症治疗必须主要集中在限制癌细胞的增殖和抑制其扩散[4]。
在传统的外科手术中不能保证精确切除癌变部位。放射治疗、化疗和靶向治疗是癌症最常见的治疗方法。
尽管如此这些疗法并不是非常精确因为它们无法区分癌细胞和健康细胞结果既破坏了健康细胞又杀死了癌细胞。然而这些疗法价格昂贵对患者有负面副作用[67]。此外由于癌细胞的基因组是动态变化的它们可能对化疗药物产生抗药性[8]。因此迫切需要开发一种新的癌症治疗方法这种治疗方法没有不良反应减少耐药性并特异性地针对癌细胞。
抗菌肽(AMP)是一类不同的生物活性分子可提供对细菌、原生动物、真菌和病毒的保护[9]。显示出潜在抗癌特性的AMPs的一个子集称为抗癌肽(ACPs)它是序列长度不超过50个氨基酸残基的短肽[10]。ACPs具有两亲性因为它存在疏水和阳离子残基与癌细胞的阴离子膜相互作用选择性地靶向和杀死癌细胞[11]。ACPs可以基于膜电荷靶向癌细胞该电荷在膜和ACPs之间形成静电相互作用从而使正常细胞保持不变。
这是在癌症治疗中使用ACP相对于目前可用的方法的主要优势。此外ACP是天然的生物抑制剂而且很容易合成这使它们成为治疗癌症的理想治疗剂。有鉴于此与传统疗法相比基于多肽的疗法已成为一种有前途的癌症治疗剂因为它们毒性小、特异性高、能够穿透膜并且易于化学修饰[1415]。
已经提出了几种用于ACP识别的计算预报器。其中许多方法在最近的文献[1617]中进行了综述包括我们以前的方法MLACP[18]。它是使用不平衡的数据集、四种不同编码的线性集成、支持向量机(SVM)和随机森林(RF)构建的。MLACP在研究界得到广泛应用因此在ACP研究界越来越受欢迎。经过实验验证的ACP的数量呈指数级增长因此现在是时候利用先进的计算技术更新以前的版本从而提高其准确性和稳健性。
MLACP 2.0的开发涉及以下步骤(I)在广泛的文献/数据库搜索的基础上创建了高质量的非冗余训练数据集和独立数据集。(Ii)系统地评估了17种不同的特征编码(包括传统编码和单词嵌入)并使用7种不同的传统分类器(RF、梯度增强(GB)、支持向量机(SVM)、极端梯度增强(XGB)、AdaBoost(AB)、光梯度增强(LGB)和极端随机化树(ERT))建立了相应的模型。(Iii)对于每个分类器基于特定标准从17个基于编码的模型中选择模型子集马修斯相关系数(MCC)大于17个基于编码的模型的平均MCC。随后基于所选模型的子集的来自七个分类器的ACP的预测概率被串联并使用卷积神经网络(CNN)进行训练用于最终预测MLACP 2.0。大量的基准测试验证了MLACP 2.0的有效性在交叉验证和独立评估的基础上与传统的单一编码模型和基于CNN的单热编码和单词嵌入模型相比该模型获得了更准确和稳定的性能。在一项独立测试中MLACP 2.0的表现明显优于现有的预测指标。利用提出的混合集成模型实现了一个用户友好的MLACP(https://balalab-skku.org/mlacp2/))在线预报器。
2. Materials and methods
2.1. Construction of datasets
这项研究的目的是利用现有的方法数据集开发一个预测模型并基于新构建的数据集对所提出的模型进行评估。通过提取现有的37个方法的训练数据集并将其分为ACP和非ACP来构建训练数据集
值得注意的是几种方法使用相同的数据集因此一些序列是多余的。在ACP中应用CD-HIT0.8得到1084个肽序列。同样的截止值被应用于非ACP样本其序列与ACP重叠导致7500个序列。然而我们随机选择了1084个非ACP以避免在建模过程中的阶级偏见并平衡ACP。这是第一次将如此大的非冗余数据集用于ACP预测研究中的训练或模型构建。
独立数据集从以下11个数据库中提取ACPCancerPPD[20]、APD3[21]、PlantPepDB[22]、DBAASPv3.0[23]、SATPdb[24]、ADAM、Dramp 3.0、LAMP[27]、Peptipedia、DbAMP和AMPun产生3725个ACP。其次将0.80的CD-HIT应用于与训练ACP序列重叠的收集的ACP得到769个序列。不同于以往随机多肽被认为是非ACPs的研究我们考虑了其他功能多肽(抗高血压和抗病毒等)、一小部分随机肽、AMP和非ACPs并通过实验确认非促炎诱导多肽为非ACPs得到了1287个非冗余非ACPs。这个独立的数据集可以作为评估未来ACP预测模型的金标准。此外补充信息包括数据集长度分布和成分分析的简要描述。
2.2. Feature encodings
探索同一数据集上的不同特征编码的过程对于理解和识别适当的编码是必不可少的。考虑到这一点本研究使用了广泛的特征包括15个常规编码(二肽组成(DPC)、二肽偏离预期平均值(DDE)、氨基酸组成(AAC)、组成转变和分布(CTDC、CTDT和CTDD)、分组DPC(GDPC)、增强分组AAC(EGAAC)、分组三肽组成(GTPC)、BLOSUM62(BLOS)、增强AAC(EAAC)、K间隔连接三联体(KSC)、KSAAGP准序列顺序(QSO)组成)、。和Z尺度)和双字嵌入是来自seq2vec的单热编码(10HE)和预训练嵌入。在这17个编码中11个编码(AAC、CKSAAGP、CTDC、CTDD、CTDT、DDE、DPC、KSC、QSO、10HE和seq2vec)对ACP预测最重要和显著。值得注意的是九种传统编码对最终预测做出了贡献其编码细节在我们之前的研究中有广泛的描述[31]。
使用相同的过程分别编码20、275、39、195、39、400、400、343、100个D特征向量的AAC、CKSAAGP、CTDC、CTDD、CTDT、DDE、DPC、KSC、QSO。值得注意的是这些特征已被归一化如下Xnorm = x − min ( x ) max ( x ) − min ( x ) =\frac{x-\min (x)}{\max (x)-\min (x)} =max(x)−min(x)x−min(x)以下是对这些单词嵌入的简要描述
2.3. 1OHE
在二进制编码技术中One-Hot编码方法相当流行。我们的数据集中多肽的最大长度是50个氨基酸。如果残基<50个氨基酸则在C末端添加虚拟残基X。因此每个氨基酸由一个21维的特征向量来表示其中标准氨基酸在不同的位置用1来表征在剩余的20个位置用0来表征。另一方面虚拟残基完全由零组成。这导致了1050维的特征向量。
2.4. Seq2vec
我们利用seq2vec的预训练嵌入来实现迁移学习的概念。Heinzinger等人通过使用从UniRef50中提取的数百万个蛋白质序列训练ELMO模型来开发预训练嵌入。在这项研究中我们使用了相同的预训练嵌入为给定的多肽序列提供了1024D特征向量。
2.5. MLACP 2.0 framework
MLACP 2.0框架(图1)是使用上面提到的训练数据集和特征编码开发的它包括构建基线模型和开发元预测器。
基线模型的构建我们使用了在生物信息学和计算生物学中广泛应用的七种不同的分类器(RF、ERT、支持向量机GB、AB、LGB和XGB)。对于每个分类器都有一组超参数它们决定了交叉验证期间模型的性能。
我们使用网格搜索方法和10次交叉验证来优化超参数。为了构建每个基线模型对训练样本进行随机分割重复10次交叉验证5次并将中值参数作为最终的最佳值。这些值随后被用来构建最终的基线模型。每个分类器的超参数搜索范围如下(I)LGB七个超参数是num_Leaves[50到100]间隔20max_bins [200到400]间隔10n_estimators[100到2000]间隔10min_Child_Samples [30到400]间隔10max_深度[5到12]间隔1学习速率2[ 1 0 − 6 到 1 0 − 1 10^-6到10^-1 10−6到10−1]以及打包分数0.8。(Ii)RF和ERT具有相同的超参数但不同的建模步骤其搜索范围为n_estimators[5075…3000]max_Feature [12…20]和Min_Samples_Split [23…10]。(3)支持向量机的两个超参数是 C ∈ [ 2 − 15 , 2 15 ] C\in[ 2^{-15},2^{15}] C∈[2−15,215]步长为2,15,2 3,步长2-1。(iv)AB三个超参数是N_估计量[1020,…,500]最大深度[12……11]学习速率[10.50.250.10.050.01]。(V)GB超参数搜索范围为n_估计器2[1020…500]学习速率[10.50.250.10.050.01]以及最大特征[12…10]。(Vi)四个XGB超参数是N_估计器2[1020…2000]最大深度2[12…11]学习速率[1.0 50.2 50.10.0 50.0 10.0010.00010.20.3]学习速率[0.00010.0010.0020.0 10.0 20.0 51.0]。值得注意的是超参数的名称派生自其相应的包中给出的名称。本工作实现了用于5个分类器(支持向量机、RF、GB、AB和ERT)lightGBM版本3.3.0和XGBoost库来执行分类任务。
最后总共生成119个基线模型并根据以下标准选择一组模型(I)计算每个基线模型的Mathews相关系数的累积分数(CS)、准确度(ACC)和ROC曲线下面积(AUC)。(ii)为每个分类器选择一组基线模型其CS大于平均CS。因此这种过滤产生了67个基准模型。预测的概率值所选择的模型(67D)用于元预测器的开发。
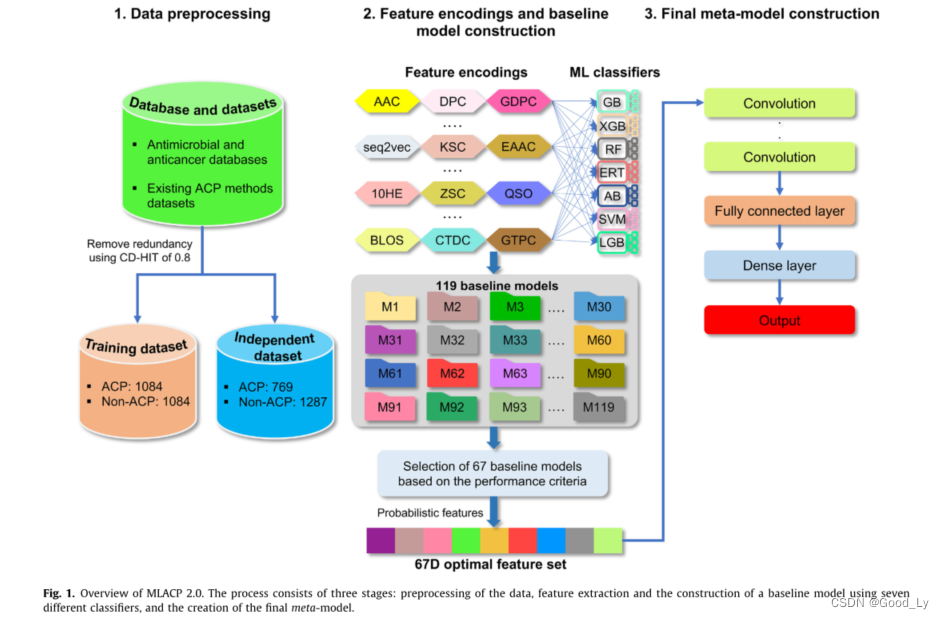
元预测因子的构建基于最近的研究采用了类似的CNN网络架构。然而我们使用10倍交叉验证优化了四个过滤器、epoch和批次大小。具体地说67D特征向量输入到四个一维卷积层的预测概率。与这些层关联的内核大小为4、5、6和7对应的过滤器分别为20、8、32和8。卷积运算后应用了整流线性单元(RELU)的激活函数其描述如下
ReLu
(
x
)
=
max
(
0
,
x
)
=
{
x
if
x
>
0
0
else
\operatorname{ReLu}(x)=\max (0, x)=\left\{\begin{array}{c}x \text { if } x>0 \\ 0 \text { else }\end{array}\right.
ReLu(x)=max(0,x)={x if x>00 else
对于四个一维卷积层中的每一个生成20、8、32和8个特征地图。在每一维卷积层之后应用一维全局最大汇聚层其目的是从转换为单变量特征向量并随后连接的特征映射中寻找最大值。此外独立分量层的丢包率为0.5。然后分别对32个、16个和8个神经元组成的三层致密层应用RELU激活功能。最后应用一个具有S型函数的单个神经元组成的致密层产生一个介于0和1之间的值。如果值大于0.5则该肽属于ACP否则为非ACP。采用ADAM优化算法更新网络权值。值得注意的是CNN是使用Keras深度学习库实现的。
Sigmoid
(
x
)
=
1
1
+
e
−
x
\operatorname{Sigmoid}(x)=\frac{1}{1+e^{-x}}
Sigmoid(x)=1+e−x1
2.6. Model evaluation
此外我们考虑了常用的六个评估指标来评估模型的性能包括MCC、敏感度(Sn)、特异度(Sp)、ACC和AUC。指标的定义如下
{
S
n
=
T
P
T
P
+
F
N
S
p
=
T
N
T
N
+
F
P
A
C
C
=
T
P
+
T
N
T
P
+
T
N
+
F
N
+
F
P
M
C
C
=
T
P
×
T
N
−
F
P
×
F
N
(
T
P
+
F
N
)
(
T
P
+
F
P
)
(
T
N
+
F
P
)
(
T
N
+
F
N
)
\left\{\begin{array}{c}S n=\frac{\mathrm{TP}}{\mathrm{TP}+\mathrm{FN}} \\ S p=\frac{\mathrm{TN}}{\mathrm{TN}+\mathrm{FP}} \\ A C C=\frac{\mathrm{TP}+\mathrm{TN}}{\mathrm{TP}+\mathrm{TN}+\mathrm{FN}+\mathrm{FP}} \\ M C C=\frac{\mathrm{TP} \times \mathrm{TN}-\mathrm{FP} \times \mathrm{FN}}{\sqrt{(\mathrm{TP}+\mathrm{FN})(\mathrm{TP}+\mathrm{FP})(\mathrm{TN}+\mathrm{FP})(\mathrm{TN}+\mathrm{FN})}}\end{array}\right.
⎩
⎨
⎧Sn=TP+FNTPSp=TN+FPTNACC=TP+TN+FN+FPTP+TNMCC=(TP+FN)(TP+FP)(TN+FP)(TN+FN)TP×TN−FP×FN
其中TP、TN、FP、FN分别表示真阳性、真阴性、假阳性和假阴性。此外ROC曲线和AUC值被用来评估总体表现。
3. Results and discussion
3.1. Construction of baseline models
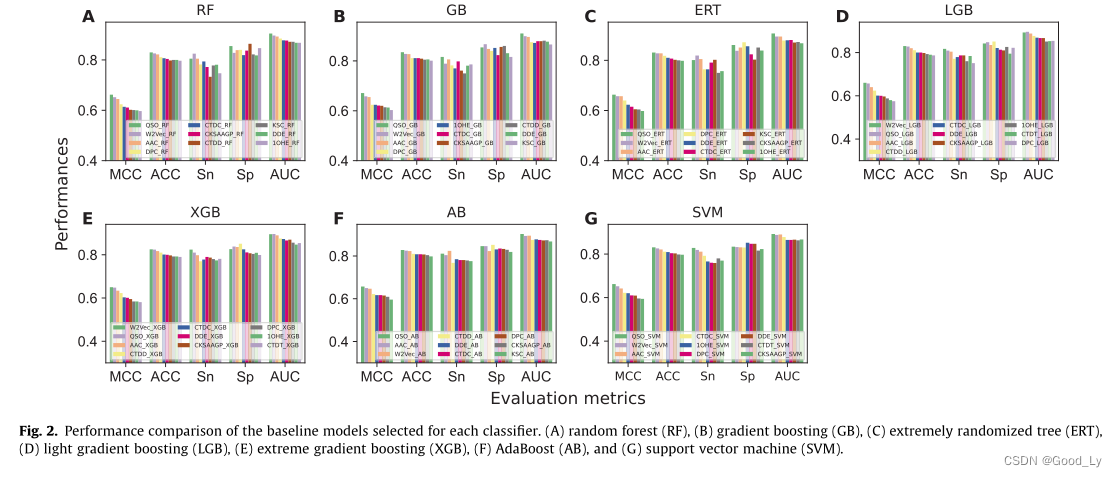
这项研究使用了17种不同的编码(QSO、seq2vec、AAC、DPC、CTDC、CTDD、CTDT、CKSAAGP、KSC、DDE、10HE、EAAC、GTPC、BLOS、ZSC、GPDC和EGAAC)主要涵盖组成、理化特性、进化信息、单词嵌入和位置特定信息。使用7种不同的传统分类器(RF、ERT、GB、AB、支持向量机、LGB和XGB)对每种编码的区分能力进行了评估。
表S1-S7显示了针对每个分类器的这些编码的性能。结果表明RF、ERT、GB、XGB、LGB、AB和支持向量机的ACC范围分别为72.0-83.0%、72.0-83.1%、71.3-83.5%、70.6-82.5%、70.0-83.0%、71.7-82.8%、71.1-83.1%。我们观察到每个分类器产生的17个基线模型之间大约10%的ACC差距。基于四个分类器的QSO编码获得了最好的性能基于两个分类器(XGB和LGB)的seq2vec编码获得了最佳的性能。一般来说大多数ACP预测者在包含高度相似的同源序列的训练数据集中表现出>90.0%的高准确率[4445]。虽然最佳基线模型(QSO-GB)达到了83.5%的最大ACC但它表明由于高度非冗余的训练数据集性能有所下降这可能限制了对模型性能的高估。
3.2. Construction of MLACP 2.0
考虑119个基线模型(17个基线模型 × 7 \begin{array}{r}\times 7\end{array} ×7个分类器)作为最终模型构建是不合适的因为在17个基线模型中每个分类器的性能差距(~10%)。因此我们计算了每个分类器的17个基线模型的平均MCC然后只考虑性能高于平均MCC的模型分别得到了来自RF、GB、LGB和XGB的10个基线模型以及分别来自ERT、SVM和AB的9个基线模型。我们总共获得了67个基准模型其性能如图2所示其ACC值在0.800-0.835的范围内。接下来我们检查了67个基准模型中有多少个独特的编码。在17种编码中只有11种编码(AAC、CKSAAGP、CTDC、CTDD、CTDT、DDE、DPC、KSC、QSO、seq2vec和10HE)构成了选定的基线模型这些模型大多是基于组成和单词嵌入的。其余六种基于编码(EAAC、EGAAC、GTPC、GDPC、ZSC和BLOS)的模型被排除在外因为它们在训练期间的性能相对较低。在选择的基线模型的基础上将ACPS的预测概率连接起来作为新的特征向量然后用CNN训练得到最终的预测模型。值得注意的是我们还测试了用于基线模型构建的其他七个分类器但CNN在稳健性方面具有优势(图S8)。因此我们选择CNN作为元模型构建命名为MLACP 2.0。Mcc、Acc、Sn值、Sp值和AUC值分别为0.694、0.846、0.815、0.876和0.915。
3.3. Comparison of MLACP 2.0 with different approaches to training
dataset
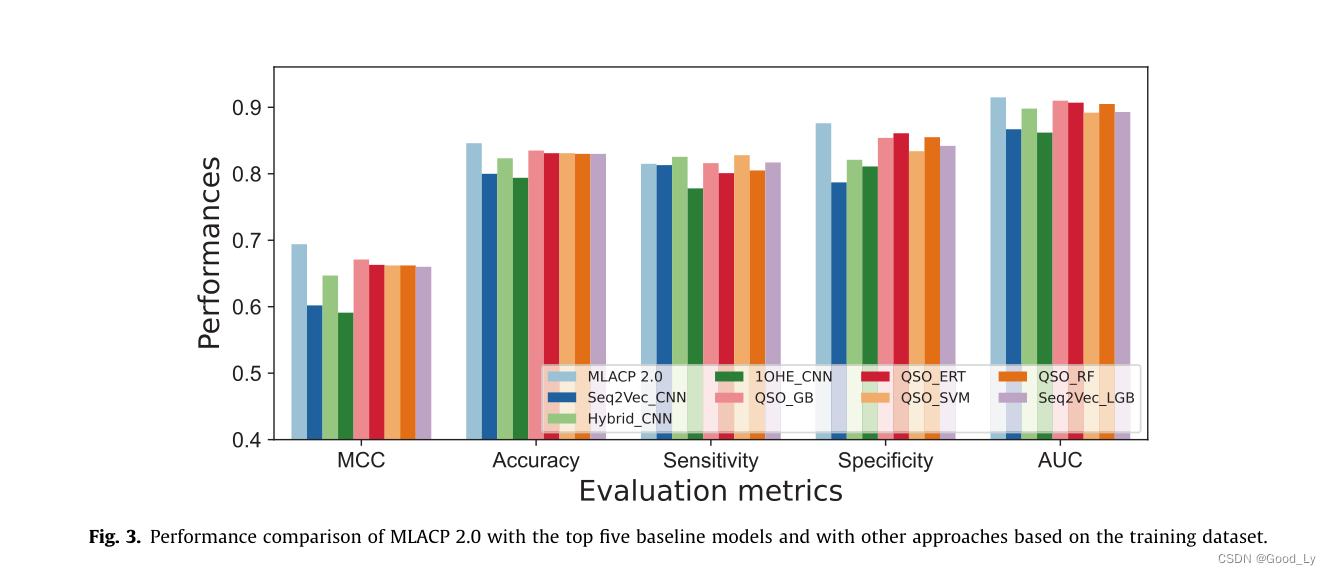
为了说明在MLACP 2.0中使用概率特征的优势我们还开发了基于CNN的单词嵌入模型即seq2vec-CNN和1OHECNN以及基于混合特征的CNN模型(11种编码的线性积分)。图3比较了MLACP 2.0与排名前五的基准模型、基于CNN的单词嵌入和混合功能模型的性能。与最好的五个基线模型相比CNN-HIXED模型的预测效果与最佳的五个基线模型相似并且显著优于CNNword嵌入模型这表明自动单词嵌入特征在ACP预测中不如特征工程有效。MLACP 2.0的表现优于最好的五个基线模型以及基于CNN的模型。更具体地说MLACP 2.0的改进在MCC中为2.3-10.3%在ACC中为1.1-5.2%在AUC中为0.5-4.8%表明系统地评估多个编码的方法与选择用于元模型构建的一组基线模型一起导致了性能的提高。
3.4. Evaluation of MLACP 2.0 and the state-of-the-art methods on an
independent dataset
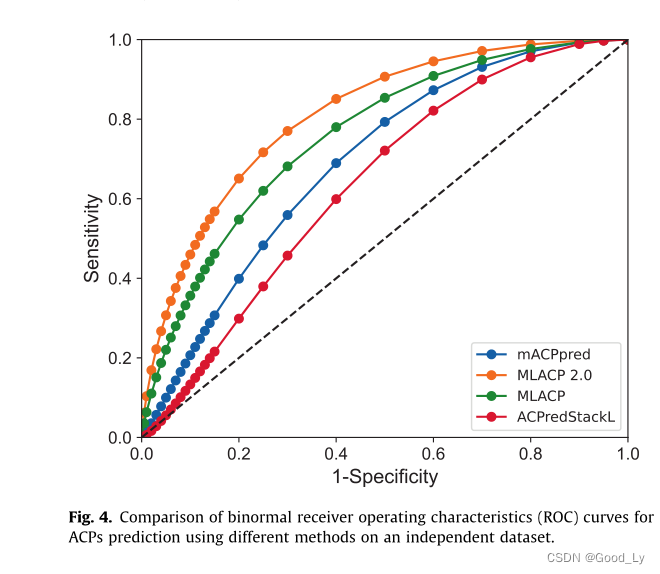
独立的数据集被用来评估MLACP 2.0以及之前的版本和两个最好的ACP预测值(mACPpred和ACPpredStackL)[1646]。值得注意的是据报道其中两种方法在先前的研究中被报道为最好的预测方法并进行了公正的评估。与之前研究中使用的常规独立数据集不同创建了一个具有挑战性的数据集。
独立的数据集具有以下重要特征(I)没有一个ACP与训练数据集的序列同源性>80%以及(Ii)非ACP是考虑到包括其他功能肽在内的几个实际场景而构建的并通过实验表征了负例。根据表1MLACP2.0获得的Mcc、Acc、Sn值、Sp和AUC值分别为0.513、0.765、0.750和0.773和0.817。特别是与现有的预测因子相比MLACP 2.0的MCC提高了16.2-28.0%ACC提高了0.8-13.7%AUC提高了7.3-17.7%。此外与现有的预报器相比MLACP 2.0的预报器性能更均衡(Sn和Sp之间的差异较小)这表明MLACP 2.0在未知数据上表现良好更适合实际应用。
从上述基于阈值的比较中很难获得统计估计。因此我们使用ROC比较了两种不同方法的AUC值并基于双尾检验的结果计算了观察到的差异的P值[47]。根据图4和表1MLACP 2.0在独立数据集上的表现比现有的预测值高出很多。所提出的方法的一个局限性它无法预测氨基酸残基超过50个的多肽。
3.5. Model interpretation
使用最优概率特征向量对MLACP 2.0进行训练。因此它的表现比之前的预测者更好也更具竞争力。概率特征对元模型的贡献和方向性是未知的。在一系列最新研究的基础上我们使用Shapley Additive Exparation(Shap)[48]进行了模型解释分析以说明最显著的特征及其与MLACP 2.0结果的关系。图4显示MLACP 2.0在热图矩阵(f(X))上方以折线图的形式生成预测每个功能的全局重要性以热图右侧的条形图形式显示前20个最重要的功能按其全局重要性的顺序列出。如图5所示我们观察到基于QSO编码的六个基线模型以及基于10HE、CTDD、seq2vec和CKSAAGP编码的三个基线模型分别贡献了两个基线模型其中基于它们各自的模型的四种编码(DDE、CTDC、KSC和AAC)在最终的MLACP 2.0预测中贡献最大。
物理化学性质的重要性已经在以前的研究中得到了强调[4950]。我们的分析还表明CKSAAGP是影响MLACP 2.0性能的特征之一。在基线模型比较中与其他编码相比类星体具有最好的性能(图2)。因此这些模型对MLACP 2.0的贡献最大也就不足为奇了。有趣的是Shap的分析准确地识别了这一现象。
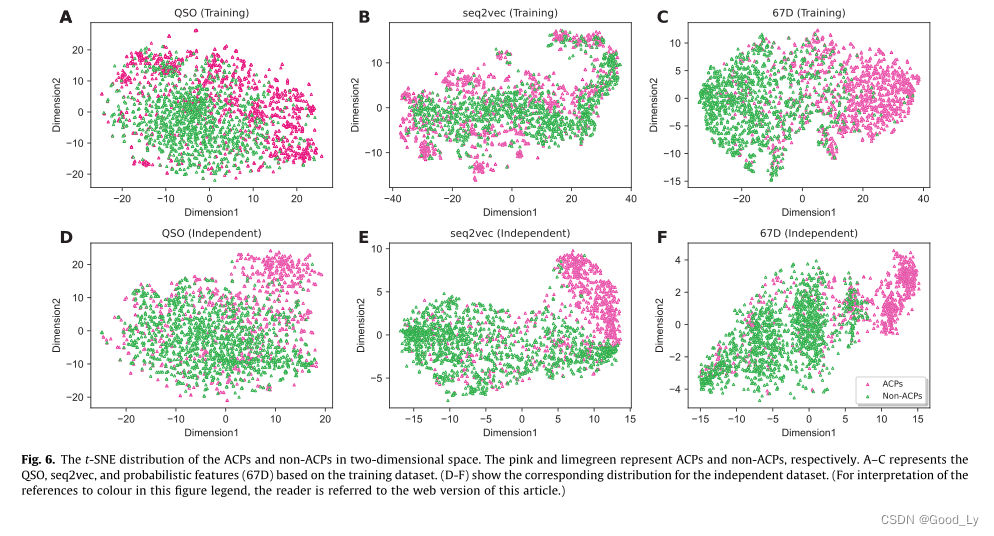
ACPs和非ACPs在二维空间的t-SNE分布。粉红色和石灰色分别代表ACP和非ACP。A-C表示基于训练数据集的类星体、序列2vec和概率特征(67d)。(D-F)显示独立数据集的相应分布。(若要解释本图例中对颜色的引用请参阅本文的网络版。)
4. Conclusion
在这项研究中我们根据多肽序列信息开发了以前ACP预测器的改进版本命名为MLACP 2.0。对于第二代工具的开发我们首先在广泛的数据库和文献搜索的基础上构建了无冗余的训练和独立的数据集。值得注意的是这是第一次使用如此大的非冗余数据集进行建模或训练的研究。其次使用了17种不同的特征编码和7种不同的分类器来开发基线模型池。在下一步中手动识别一组基线模型其预测的ACP值被整合并与CNN一起训练以产生最终的模型。
有几个因素有助于提高MLACP 2.0的性能包括(I)减少的训练数据集与元模型方法相结合(Ii)预测的概率特征在两个数据集上都具有很高的内在区分能力从而提高了性能。有趣的是这种方法可以扩展到预测其他多肽的治疗功能[51-54]。
尽管MLACP 2.0的性能前景看好但它仍有改进的空间。(I)一种与组成和物理化学性质无关的新型基于序列的编码系统有望在未来开发和应用。(2)使用特征选择技术[55-59]可能有助于量化每种编码对区分ACP和非ACP的贡献。(3)还有可能开发集合深度学习模型或混合模型(传统和深度学习模型)[60]以便在未来有更多的数据集可用时改进ACP的性能。