

Hadoop作业实时智能监控项目实践
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
1. 背景
对于Hadoop集群监控,有基于Linux的硬件告警,比如磁盘,内存,网络带宽告警;有基于组件的告警,例如OOM报警、RPC告警。这些告警能反应个体机器的运行状况,不能反映整个集群的运行状况;同时,这些告警都是在已知的故障指标,但是对于未知的指标,可能已经发生并且对系统产生较大影响,由于没有告警不能及时介入,造成严重的故障。
为了解决上述问题,本文介绍一种基于MapTask进度和ReduceTask进度进行更细粒度的进度检查,引入了HoltWinters时序预测算法按照不同频度对这些进度进行预测,实时对比作业进度和预测进度,计算异常进度。异常进度一般表示由于某些异常导致作业产生延迟,对于一些重点MR数据ETL任务,如果延迟会对下游作业产生破坏性影响,因此需要将异常进度告警,让数据开发或者组件运维进行排查。
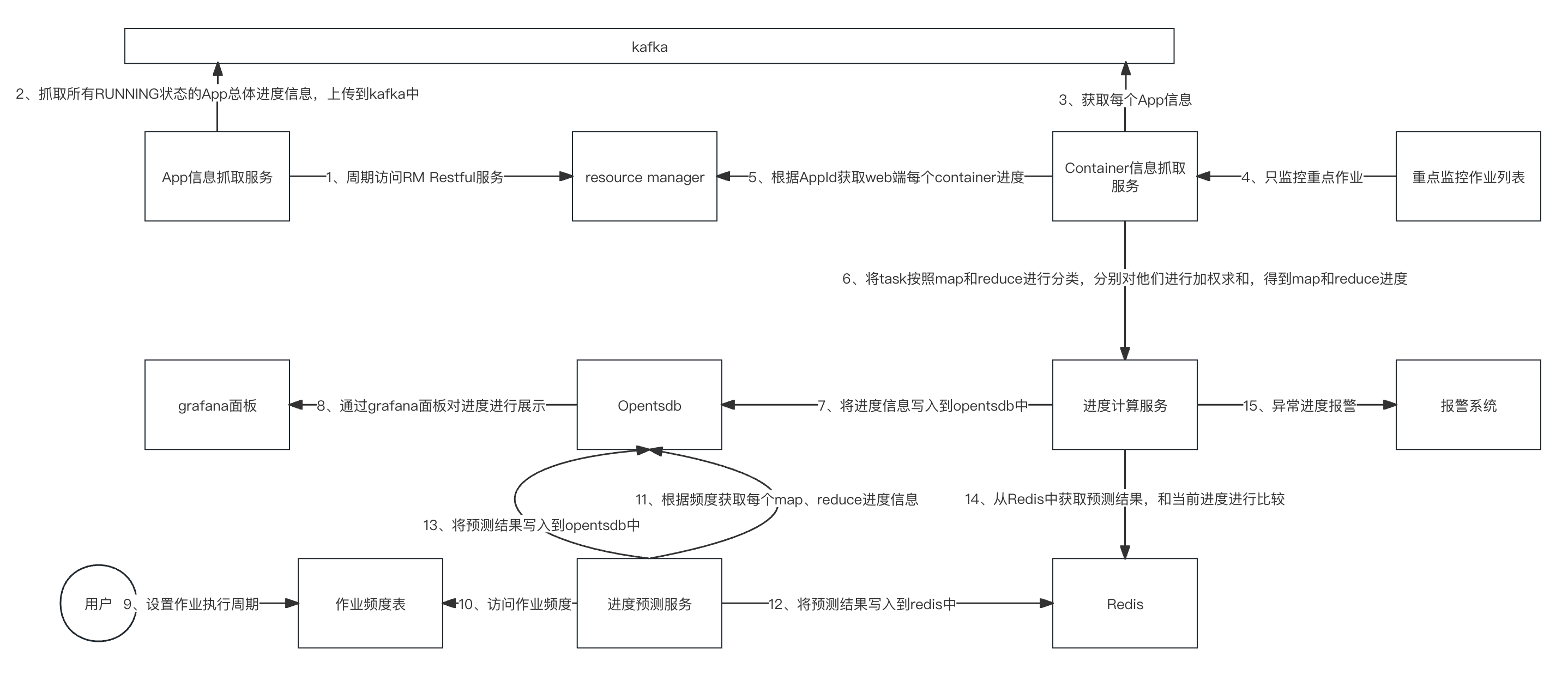
2. 架构设计
为了实现上述需求,设计了下面的流程:
- App信息抓取服务周期访问RM Restful服务,抓取所有RUNNING状态的App总体进度信息,上传到kafka中。
- Container信息抓取服务从Kafka中获取每个App信息,从重点监控作业列表了解监控的App,只监控重点作业。
- 进度计算服务根据AppId获取web端每个container进度。将task按照map和reduce进行分类,分别对他们进行加权求和,得到平均map和reduce进度。将进度信息写入到opentsdb中,通过grafana面板对进度进行展示。
- 用户设置作业执行周期到作业频度表中,进度预测服务每天定时访问作业频度,根据频度获取每个map、reduce进度信息。将预测结果写入到redis和opentsdb中。
- 从Redis中获取预测结果,和当前进度进行比较,将异常进度报警。
3. RUNNING状态作业上传Kafka
3.1 resourcemananger Restful接口介绍
resourcemananger提供了Restful接口,访问直接获取所有RUNNING状态的作业的运行进度数据:
http://<resourcemananger ip>:8088/ws/v1/cluster/apps?state=RUNNING
如下所示,该接口返回了非常详细的作业状态信息:
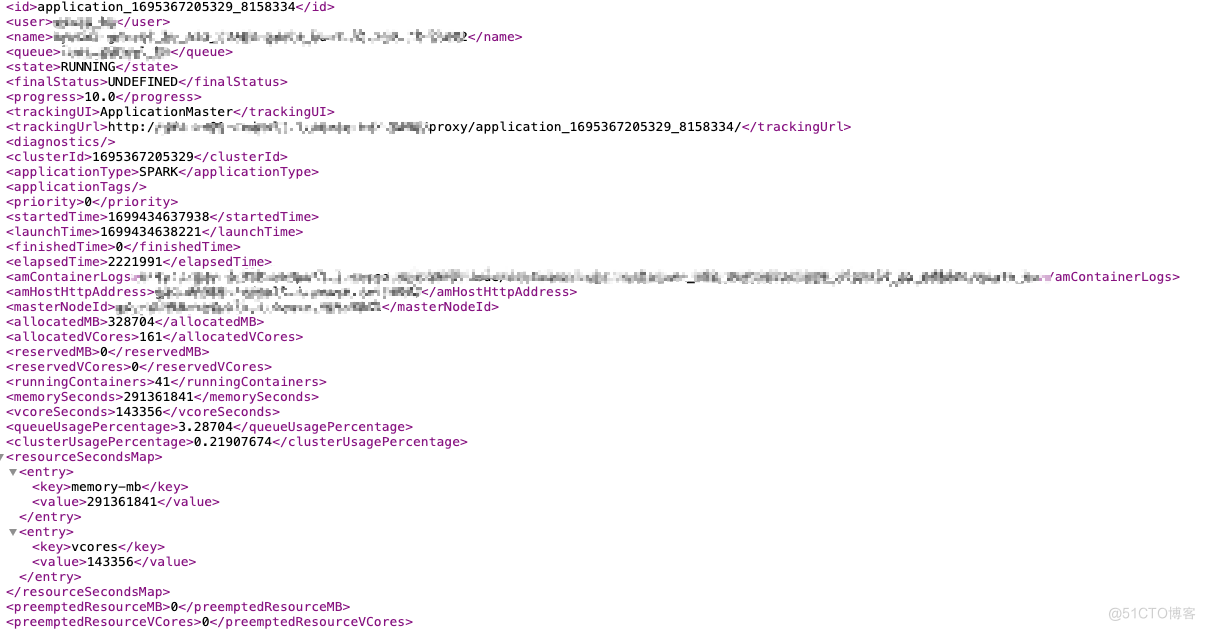
注意:/ws/v1/cluster/apps 默认会返回所有application信息,resourcemananger中application信息非常多,为了防止打爆resourcemananger,应该设置限制条件,例如只查询RUNNING状态的application:?state=RUNNING
注意,该页面上作业有一个整体信息,粒度不够细,本项目中按照的是map和reduce作业进度粒度。
3.2 定期获取应用信息
在项目中,每2分钟执行一次doFetchingRunningAppTasks方法,获取所有运行状态的App信息。并将App信息写入到kafka中:
private void doFetchingRunningAppTasks(long timeBeginGetApp, long timeEndGetApp) {
List<YarnAppInfo> runningApps = new ArrayList<>(yarnClient.getApplications("RUNNING",-1,-1,null));
logger.info("doFetchingRunningAppTasks get runningApps = " + runningApps.size());
kafkaService.send(runningApps);
}
获取的信息如下为例,它包含作业appId和TASKID,TASKID表示平台上的作业ID,appId则是Yarn生成的ID:

4. 爬虫定时抓取Task进度
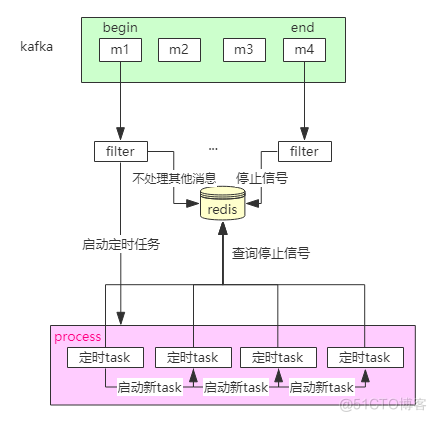
获取了需要监控的TASKID列表,从从kafka中获取对应的AppId。当第一次获取到AppId时,就开始执行定时任务,定时抓取Task进度;当获取到AppId的Finished状态的消息,结束定时抓取Task的任务。
如下,将开始和结束的信号放在redis中,定时进行监控redis决定定时任务是否结束:
每个定时任务执行的逻辑如下,它们逐级爬取App页面,Job页面,Task页面,Attempt页面获取每个task的进度信息:
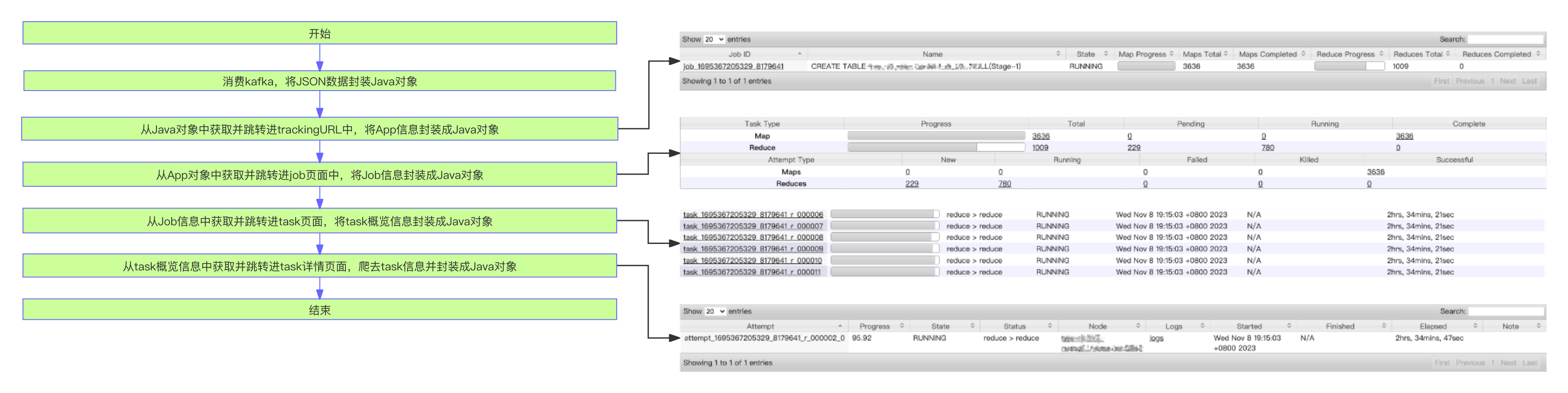
如下所示,代码会定义四类爬虫获取最终的attempt进度信息:

将task进度信息写入到opentsdb中:
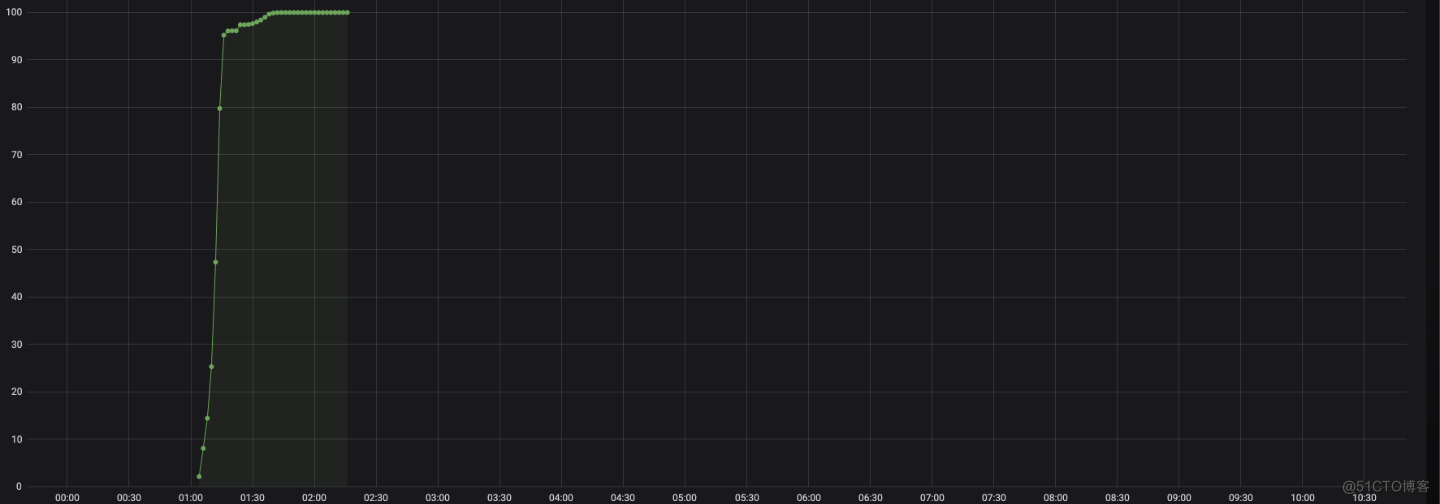
5. 时序预测task进度
5.1 预测模型选型
Sparkts0.4.0之后的版本中,包含了两个时序预测模型,一个是ARIMA,一个是HoltWinters。ARIMA模型主要用于处理由于未知原因导致均值、方差、协方差的特征随着时间变化的问题上,通过往期数据预测未来。HoltWinters模型则采用了周期概念,将时间序列的季节性这一特征也考虑进去。本文使用Sparkts0.4.0模块的HoltWinters模型对历史进度进行预测。
5.2 时序预测执行流程
- 从mysql中获取作业id和频度对应关系。
- 从opentsdb中获取历史进度信息。
- 根据频度按照周期收集不同日期的数据。如果没有设置作业频度,那么默认设置作业频度为1。
- 分别将不同频度的数据输入到时序预测算法HoltWinters中,获得预测结果。
- 将预测结果存储到Redis中,留给后一天比较执行时间时使用。
其流程如下:
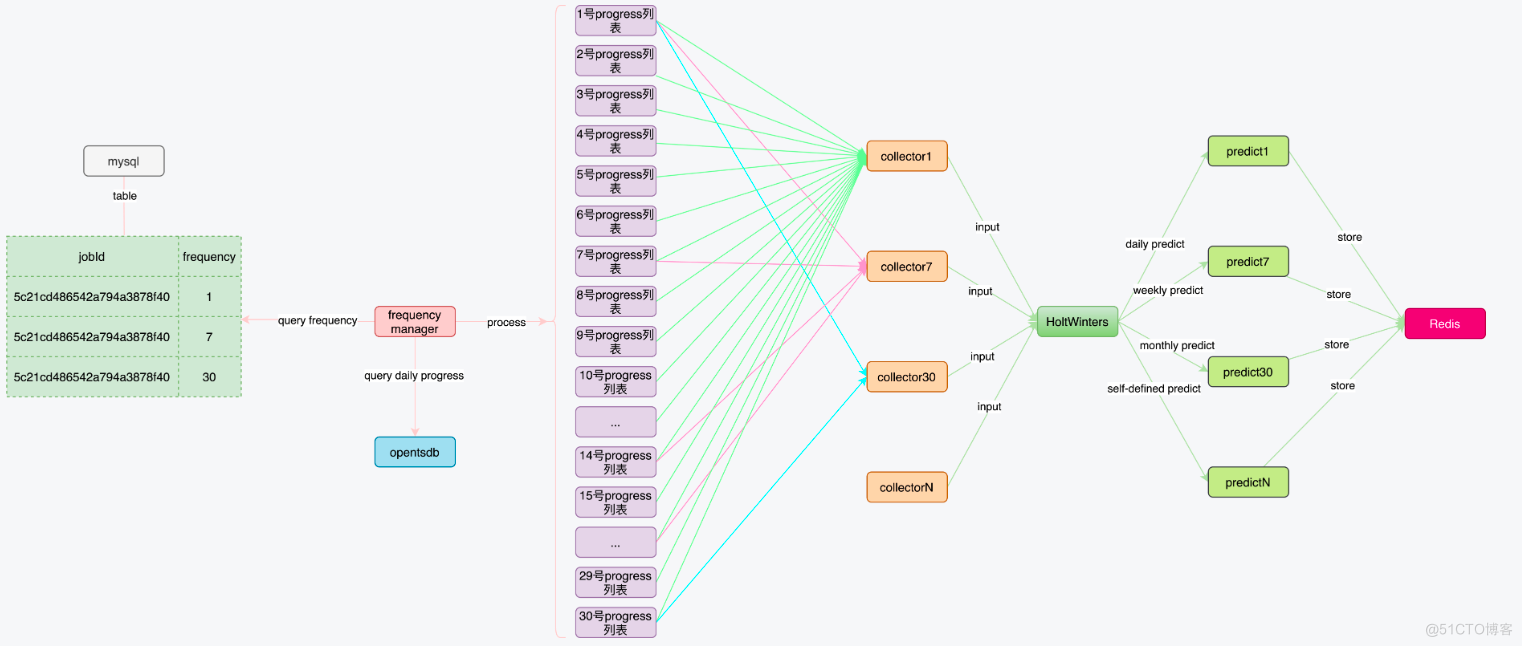
上述过程中,frequency manager获取到opentsdb的数据,需要经过处理才能使用。这里面有以下重点:
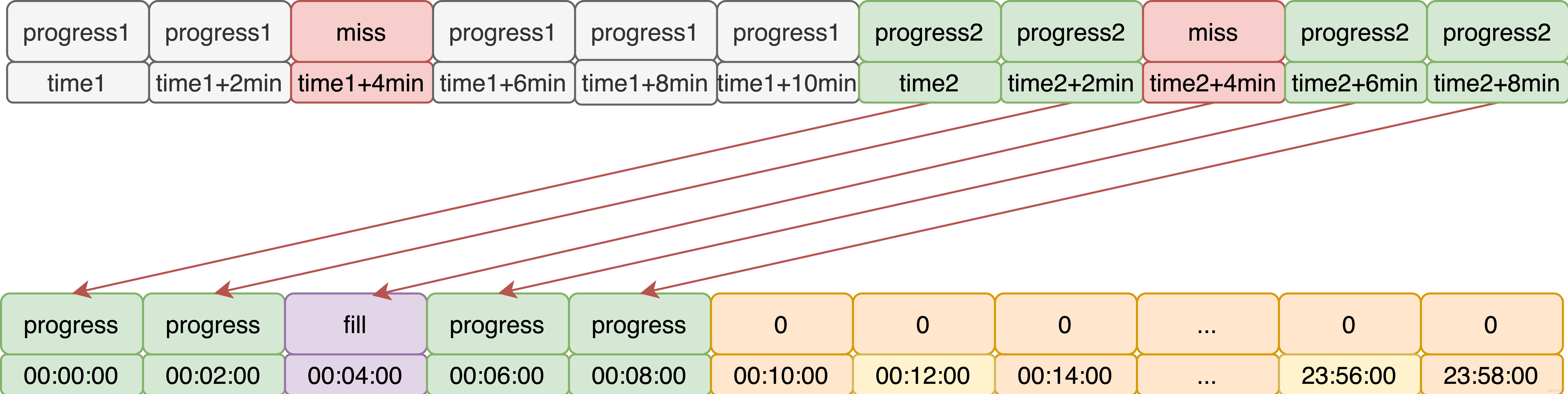
- 如果指定时间点的数据发生丢失,需要将丢失的数据进行填充。
- 为了防止每日的启动时间不一致导致预测不准的情况,模块将进度预测全部移到每日最开始,避免启动时间不一致的情况。
- 由于在预测时移动了历史数据点,那么需要考虑作业重跑的问题,每日有多组进度值时该如何处理。根据实际情况,最后一次重跑的进度能够代表整个作业的运行情况,因此,在历史数据收集时,只取最后一次作业进度情况。
- 没有进度数据的时间点,用0补充。这是因为opentsdb的数据对应的是无规律的数据点,但是要HoltWinters算法处理的数据必须是指定间隔的数据。
上述策略可用以下流程图表示:
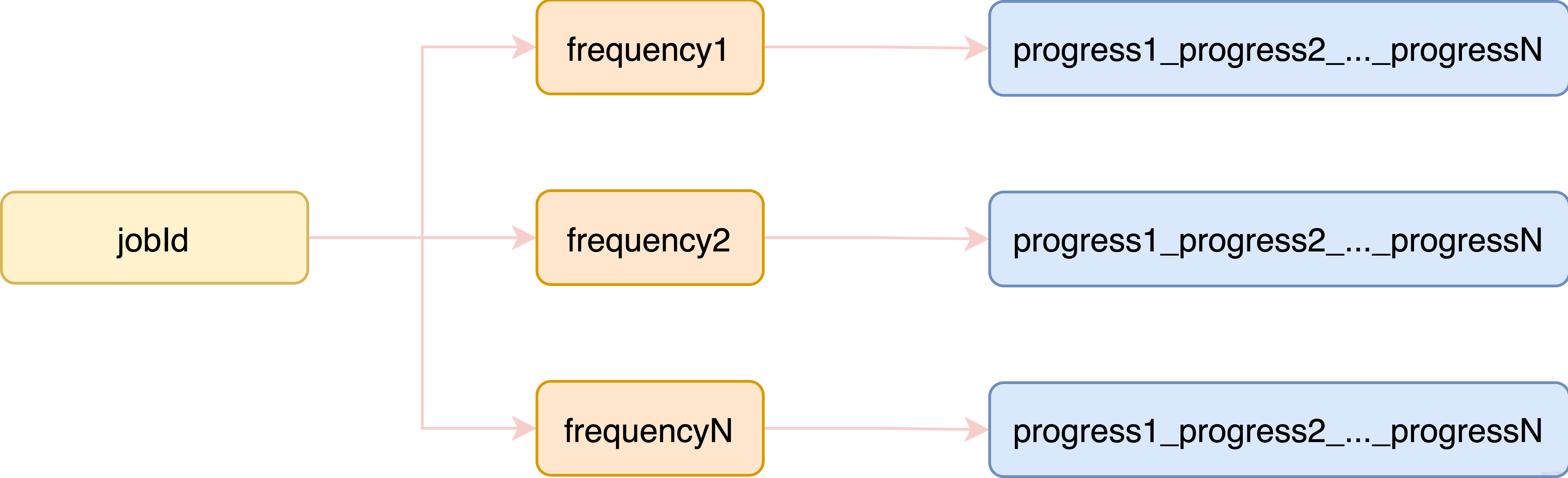
最终,根据频度将进度预测信息写入到redis中:
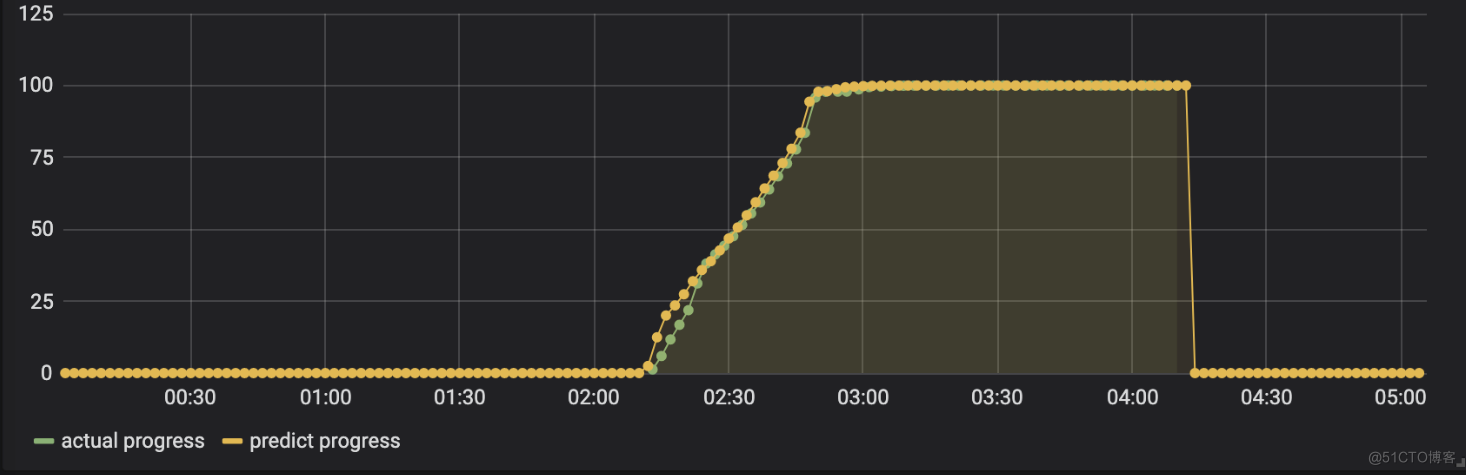
同时也写入到opentsdb中。如下,预测和时间进度基本一致,这是正常作业执行情况:
6. 报警
每次爬虫爬取进度信息时,都会从redis中获取同期预测进度,如果过去一段时间,实际值和预测值的差距越来越大,就进行告警。当进度异常时,报警:

| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |