Python机器学习:数据探索与可视化(一)
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
什么是数据探索
在前面我们说到所谓机器学习就是用已知的数据通过算法去预测未来未知的数据。但是这个过程进行的前提就是要保证已知数据的完成性。所以数据探索就是检查数据是否完整是否有缺失值。
什么是可视化
可视化就是将数据以图像的形式呈现出来例如散点图、直方图、正态图等等这些都是将单纯的数据以图像的形式呈现从而可以起到更清晰有效地传达、沟通并辅助数据分析的作用。
🌕 缺失值处理
⭐️数据缺失指在数据采集、传输和处理等过程中由于某些原因导致数据不完整的情况。
下面学习一下缺失值的处理方法。
🌗 简单的缺失值处理方法
在处理缺失值之前我们肯定要有缺失值才能处理所以我们第一步是去检查数据中有没有缺失值。
🌑 发现数据中的缺失值
在这里我们要用到一个数据集通过这个数据集来介绍发现缺失值的方法。
- 首先我们读取并查看这个数据集
import pandas as pd
a = pd.read_csv("D:/Pycharm/机器学习数据/program/data/chap2/热带大气海洋数据.csv")
print(a)
- 然后我们再用pd.isna()判断a的每个元素是否为缺失值
import pandas as pd
a = pd.read_csv("D:/Pycharm/机器学习数据/program/data/chap2/热带大气海洋数据.csv")
print(pd.isna(a))
- 然后再用sum()方法对每列求和计算出每列缺失值的数量
import pandas as pd
a = pd.read_csv("D:/Pycharm/机器学习数据/program/data/chap2/热带大气海洋数据.csv")
print(pd.isna(a).sum())
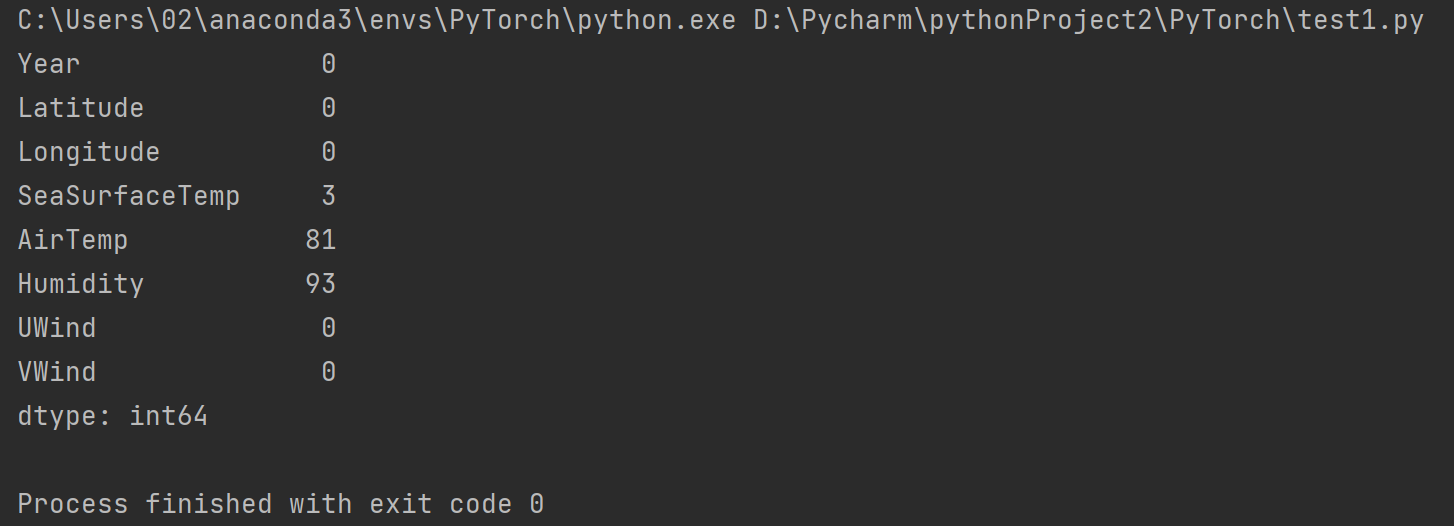
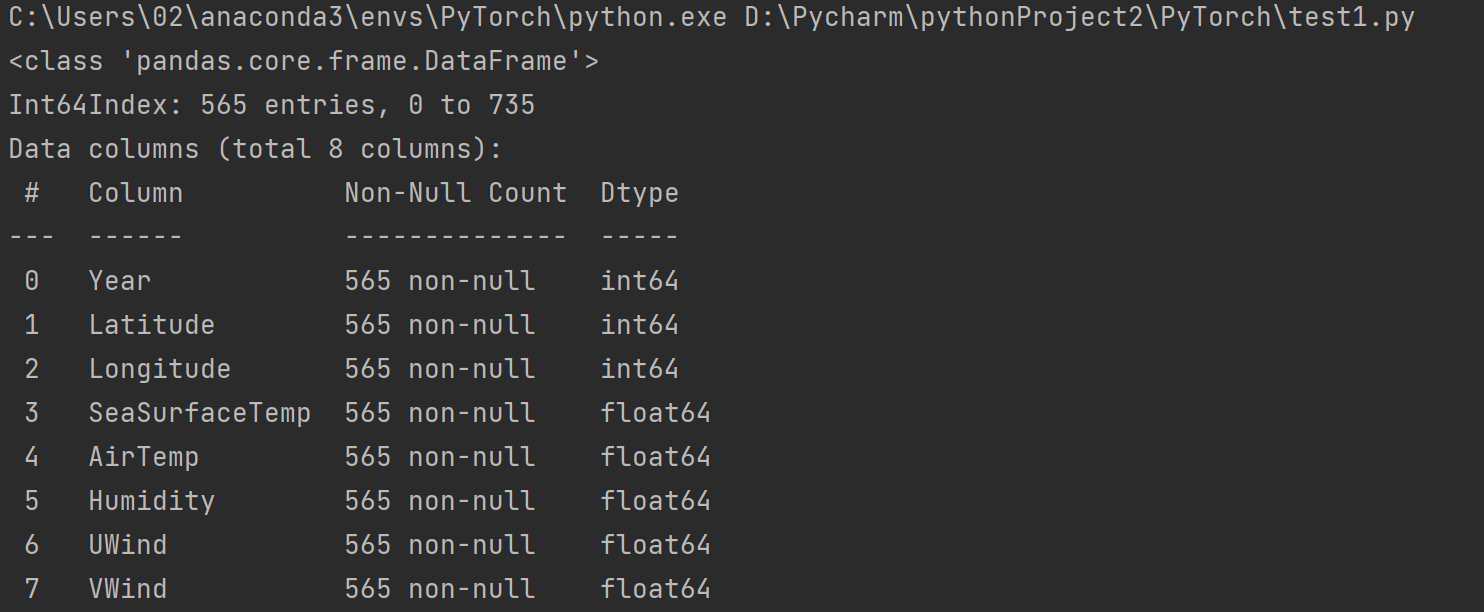
从结果中我们可以看到SeaSurFaceTemp有3个缺失值AirTemp有81个缺失值Humidity有93个缺失值。
虽然我们已经知道了数据集中每列缺失值的数量但是我们还不知道它们具体的分布情况缺失值在哪一行。
于是我们可以使用mano.matrix()可视化出缺失值在数据中的分布情况。
import pandas as pd
from matplotlib import pyplot as plt
import missingno as msno
a = pd.read_csv("D:/Pycharm/机器学习数据/program/data/chap2/热带大气海洋数据.csv")
msno.matrix(a,figsize = (10,6))
plt.show()

该图左边的1和736表示行数中间这一大块表示缺失值在数据中的分布空白的部位表示该处存在缺失值。
右侧的折线表示每个样本缺失值的情况8表示数据中一共有8个变量8列5表示对应的数据集只有5个变量是完整的存在3个缺失值。
现在我们已经发现数据中有缺失值接下来就是根据缺失值的情况进行预处理。
🌑 剔除带有缺失值的行或列
通常情况下如果数据中只有较少的样本带有缺失值则可以剔除带有缺失值的行。如果某列的数据带有大量的缺失值进行缺失值填充可能会带来更多的负面影响则可以直接剔除缺失值所在的列。
其中dropna()方法就是用来剔除带有缺失值的行或列。可以指定参数axis=0剔除行、axis=1剔除列。
# 剔除带有缺失值的行
import pandas as pd
a = pd.read_csv("D:/Pycharm/机器学习数据/program/data/chap2/热带大气海洋数据.csv")
b = a.dropna(axis = 0)
print(b.info())
# 剔除带有缺失值的列
import pandas as pd
a = pd.read_csv("D:/Pycharm/机器学习数据/program/data/chap2/热带大气海洋数据.csv")
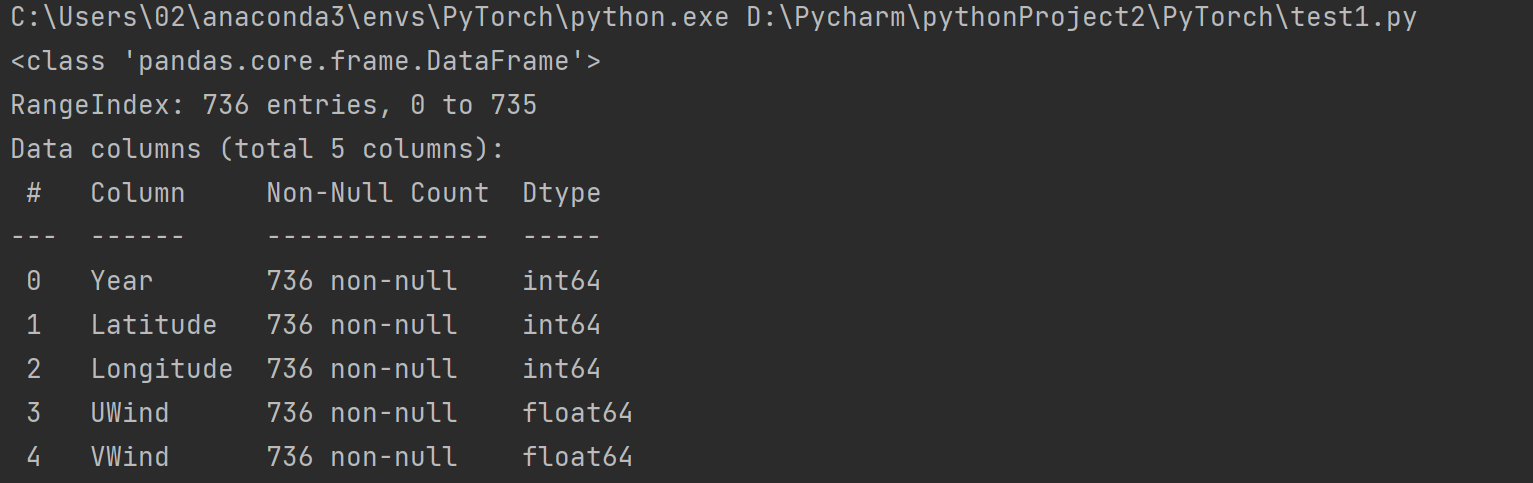
b = a.dropna(axis = 1)
print(b.info())
🌑 对缺失值进行插补
因为AirTemp和Humidity列的缺失值最多这里就针对这两个列来进行插补。
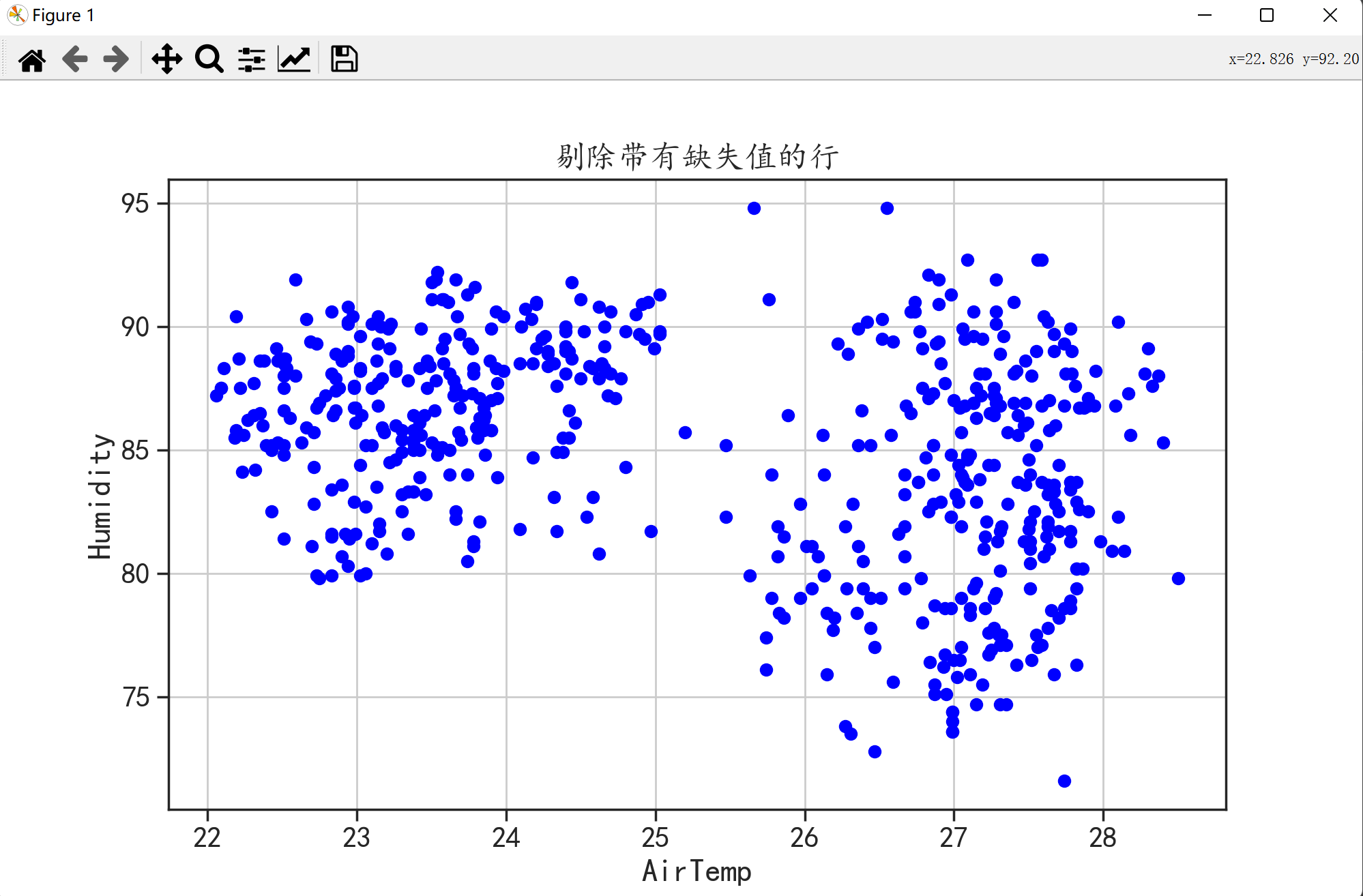
首先我们要使用散点图可视化出剔除带有缺失值行后AirTemp和Humidity变量的数据分布。
import pandas as pd
from matplotlib import pyplot as plt
# 中文显示问题
import matplotlib
matplotlib.rcParams['axes.unicode_minus']=False
import seaborn as sns
sns.set(font="Kaiti",style="ticks",font_scale=1.4)
a = pd.read_csv("D:/Pycharm/机器学习数据/program/data/chap2/热带大气海洋数据.csv")
b = a.dropna(axis = 0)
plt.figure(figsize = (10,6))
plt.scatter(b.AirTemp,b.Humidity,c = "blue")
plt.grid()
plt.xlabel("AirTemp")
plt.ylabel("Humidity")
plt.title("剔除带有缺失值的行")
plt.show()
这里直接对原始数据可视化也可以这是因为plt.scatter()函数会自动地不显示带有缺失值的点。
对缺失值填充pandas库提供了数据表的fillna()方法该方法可通过参数method设置缺失值的填充方式。method=“ffill”使用缺失值前面的值进行填充method=“bfill”使用缺失值后面的值进行填充。
- 使用缺失值前面的值进行填充
import pandas as pd
import matplotlib
from matplotlib import pyplot as plt
matplotlib.rcParams['axes.unicode_minus']=False
import seaborn as sns
sns.set(font="Kaiti",style="ticks",font_scale=1.4)
a = pd.read_csv("D:/Pycharm/机器学习数据/program/data/chap2/热带大气海洋数据.csv")
# 找到缺失值所在位置
index = pd.isna(a.AirTemp) | pd.isna(a.Humidity) # “|”这个符号在这里是并集的意思
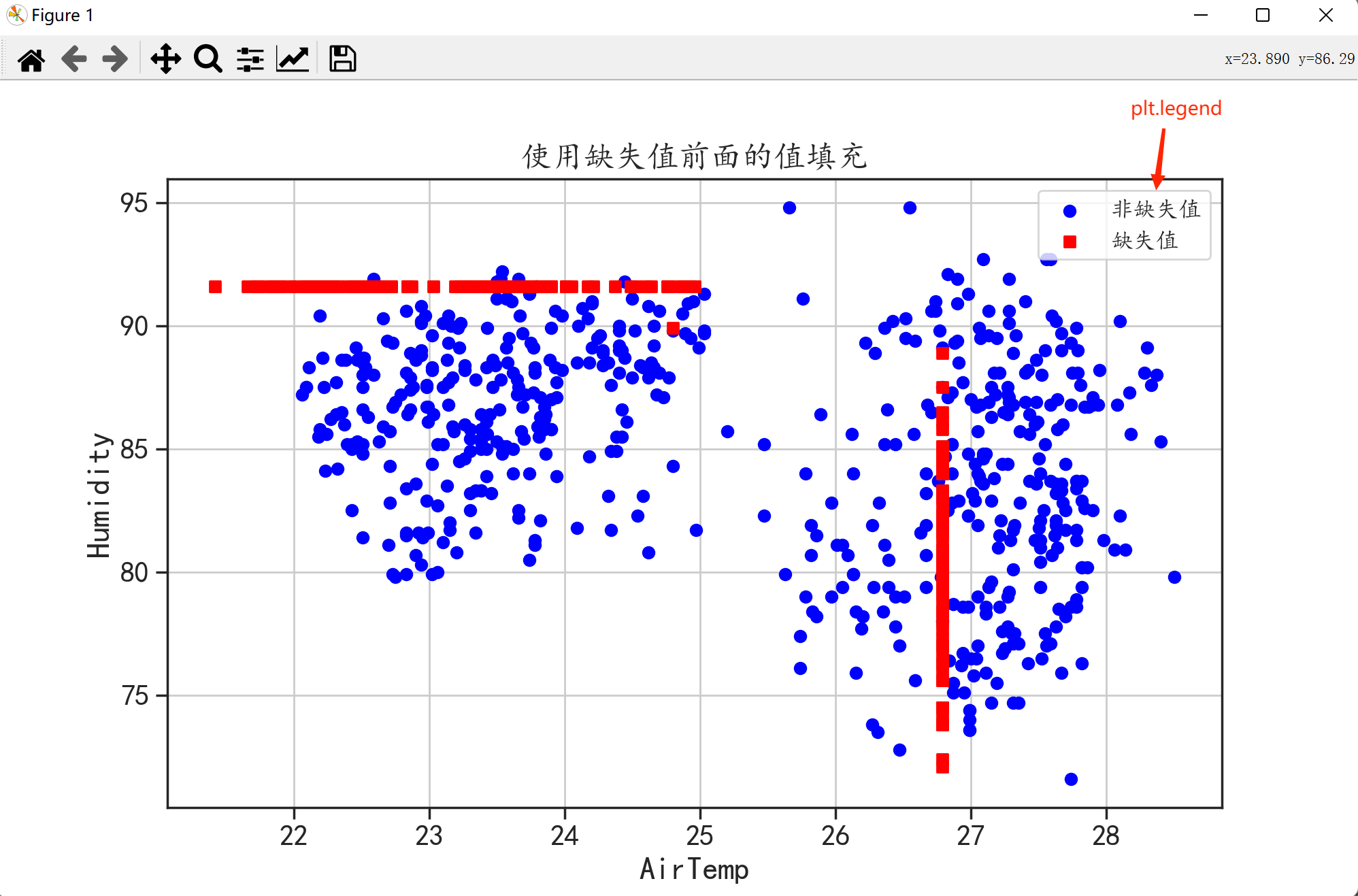
b = a.fillna(axis = 0,method = "ffill")
# 画图
plt.figure(figsize = (10,6))
plt.scatter(b.AirTemp[~index],b.Humidity[~index],c = "blue",marker = "o",label = "非缺失值") # “~”这个符号在这里是取反的意思
plt.scatter(b.AirTemp[index],b.Humidity[index],c = "red",marker = "s",label = "缺失值")
plt.grid()
plt.legend(loc = "upper right",fontsize = 12)
plt.xlabel("AirTemp")
plt.ylabel("Humidity")
plt.title("使用缺失值前面的值填充")
plt.show()
关于~index我们知道index是缺失值所在的位置那么~index就是非缺失值所在的位置。
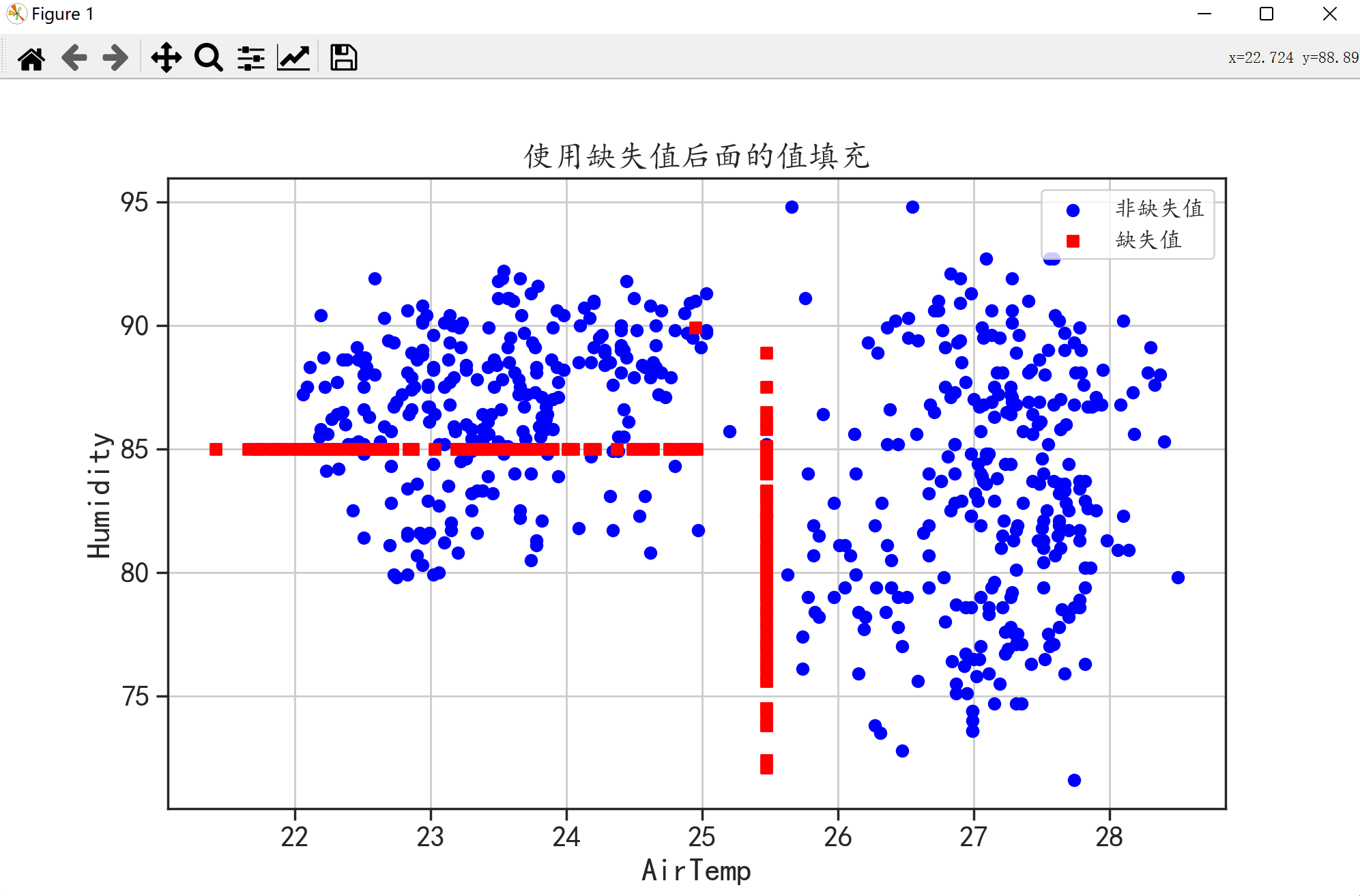
- 使用缺失值后面的值进行填充
我们只需将上面代码中参数“method”的值改成bfill就行了。
3. 使用均值进行填充
跟上面的代码也差不多再对这两列求个均值就行了。
import pandas as pd
import matplotlib
from matplotlib import pyplot as plt
matplotlib.rcParams['axes.unicode_minus']=False
import seaborn as sns
sns.set(font="Kaiti",style="ticks",font_scale=1.4)
a = pd.read_csv("D:/Pycharm/机器学习数据/program/data/chap2/热带大气海洋数据.csv")
index = pd.isna(a.AirTemp) | pd.isna(a.Humidity)
# 求均值
AirTempmean = a.AirTemp.mean()
Humiditymean = a.Humidity.mean()
# 填充
AirTemp = a.AirTemp.fillna(value = AirTempmean)
Humidity = a.Humidity.fillna(value = Humiditymean)
plt.figure(figsize = (10,6))
plt.scatter(AirTemp[~index],Humidity[~index],c = "blue",marker = "o",label = "非缺失值")
plt.scatter(AirTemp[index],Humidity[index],c = "red",marker = "s",label = "缺失值")
plt.grid()
plt.legend(loc = "upper right",fontsize = 12)
plt.xlabel("AirTemp")
plt.ylabel("Humidity")
plt.title("使用缺失值后面的值填充")
plt.show()
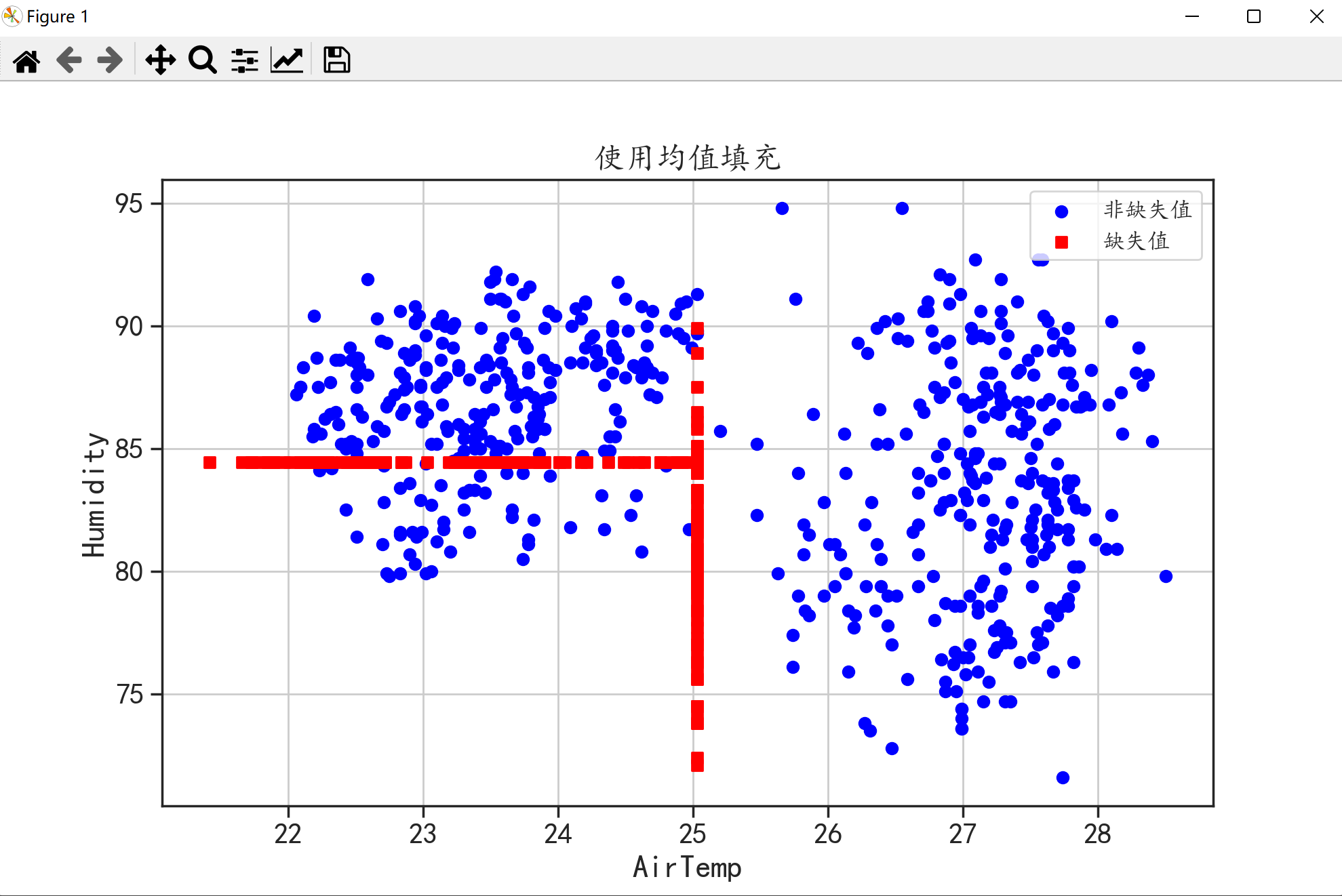
从上面三种简单的填充方式的结果图可以看出红色并没有起到填充的作用红色分布太规律了并且很“单独”这是因为这三种方法只是简单地分析一个变量没有从整体出发。下面我们来学习一下比较复杂的填充方法它们都能考虑到数据的整体情况。
🌗 复杂的缺失值填充方法
🌑 IterativeImputer多变量缺失值填充
IterativeImputer是sklearn库中提供的一种缺失值填充方式。该方法会考虑数据在高维空间中的整体分布情况然后对缺失值的样本进行填充。
from sklearn.experimental import enable_iterative_imputer
from sklearn.impute import IterativeImputer # 导入我们所需的IterativeImputer同时还要加上上面一句不然会导入失败
import pandas as pd
from matplotlib import pyplot as plt
# 中文显示问题
import matplotlib
matplotlib.rcParams['axes.unicode_minus']=False
import seaborn as sns
sns.set(font="Kaiti",style="ticks",font_scale=1.4)
a = pd.read_csv("D:/Pycharm/机器学习数据/program/data/chap2/热带大气海洋数据.csv")
index = pd.isna(a.AirTemp) | pd.isna(a.Humidity)
# 填充
iterimp = IterativeImputer(random_state = 123) # random_state相当于随机数种子
a_iter = iterimp.fit_transform(a)
# 获取填充后的变量
AirTemp = a_iter[:,4] # [:,4]表示第4列的所有行下同
Humidity = a_iter[:,5]
plt.figure(figsize = (10,6))
plt.scatter(AirTemp[~index],Humidity[~index],c = "blue",marker = "o",label = "非缺失值")
plt.scatter(AirTemp[index],Humidity[index],c = "red",marker = "s",label = "缺失值")
plt.grid()
plt.legend(loc = "upper right",fontsize = 12)
plt.xlabel("AirTemp")
plt.ylabel("Humidity")
plt.title("使用IterativeImputer方式填充")
plt.show()
关于sklearn中的模块导入失败的问题我自己之前也在网上找到了很多解决办法都挨个试了一下还是不行最后还是在一位大佬的帮助下才成功具体怎么解决的我也没看懂0.0
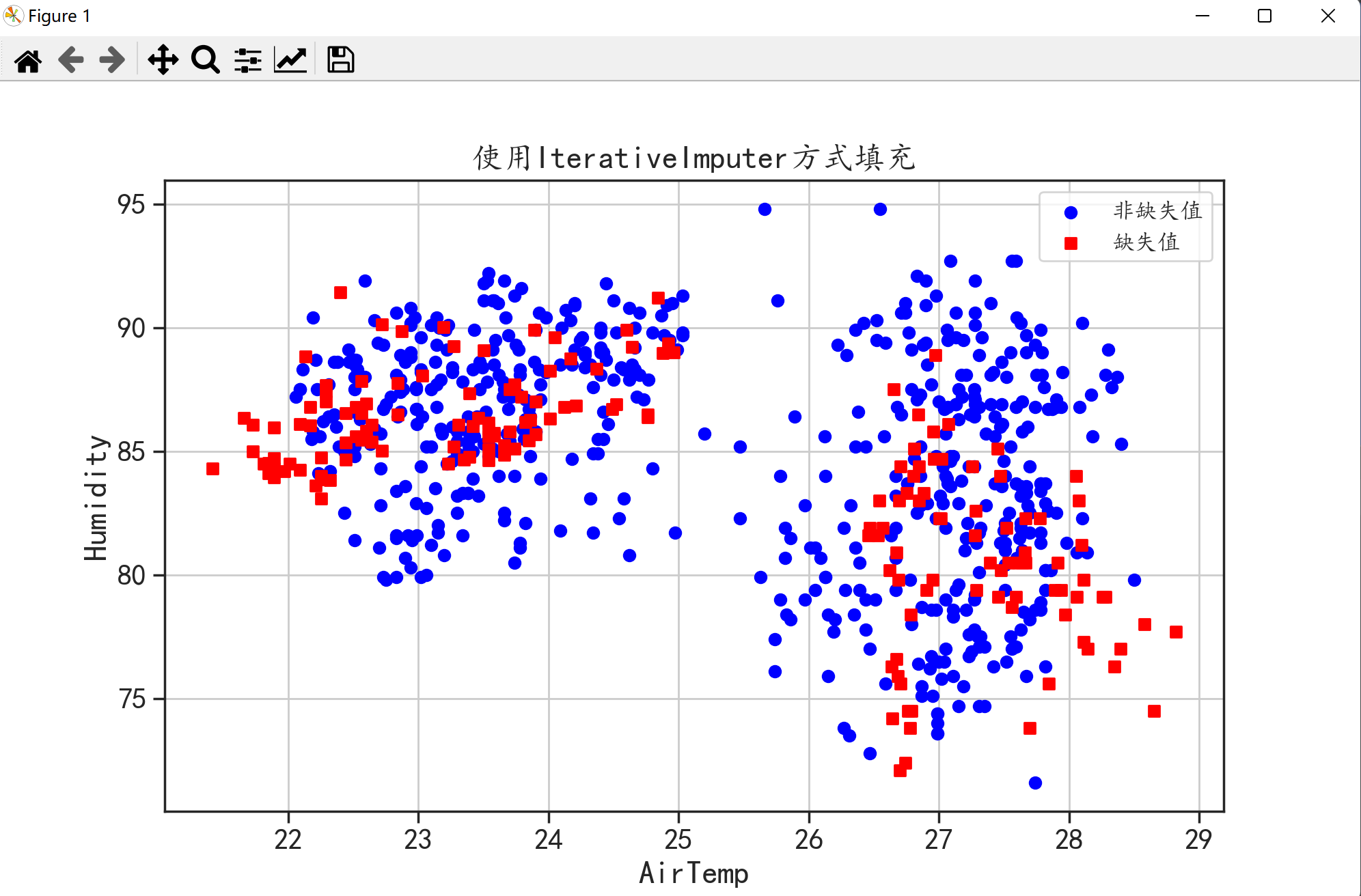
将这个图和上面那三个图一对比是不是发现这个图填充的结果更符合数据的分布规律
🌑 K-近邻缺失值填充
该方法可以使用sklearn库中的KNNImputer来完成。该方法会利用带有缺失值样本的多个近邻挨得近的综合情况对缺失值样本进行填充。
# 只需改一下上面代码的填充和获取填充后的变量部分即可
knnimp = KNNImputer(n_neighbors = 5)
a_knn = knnimp.fit_transform(a)
AirTemp = a_knn[:,4]
Humidity = a_knn[:,5]
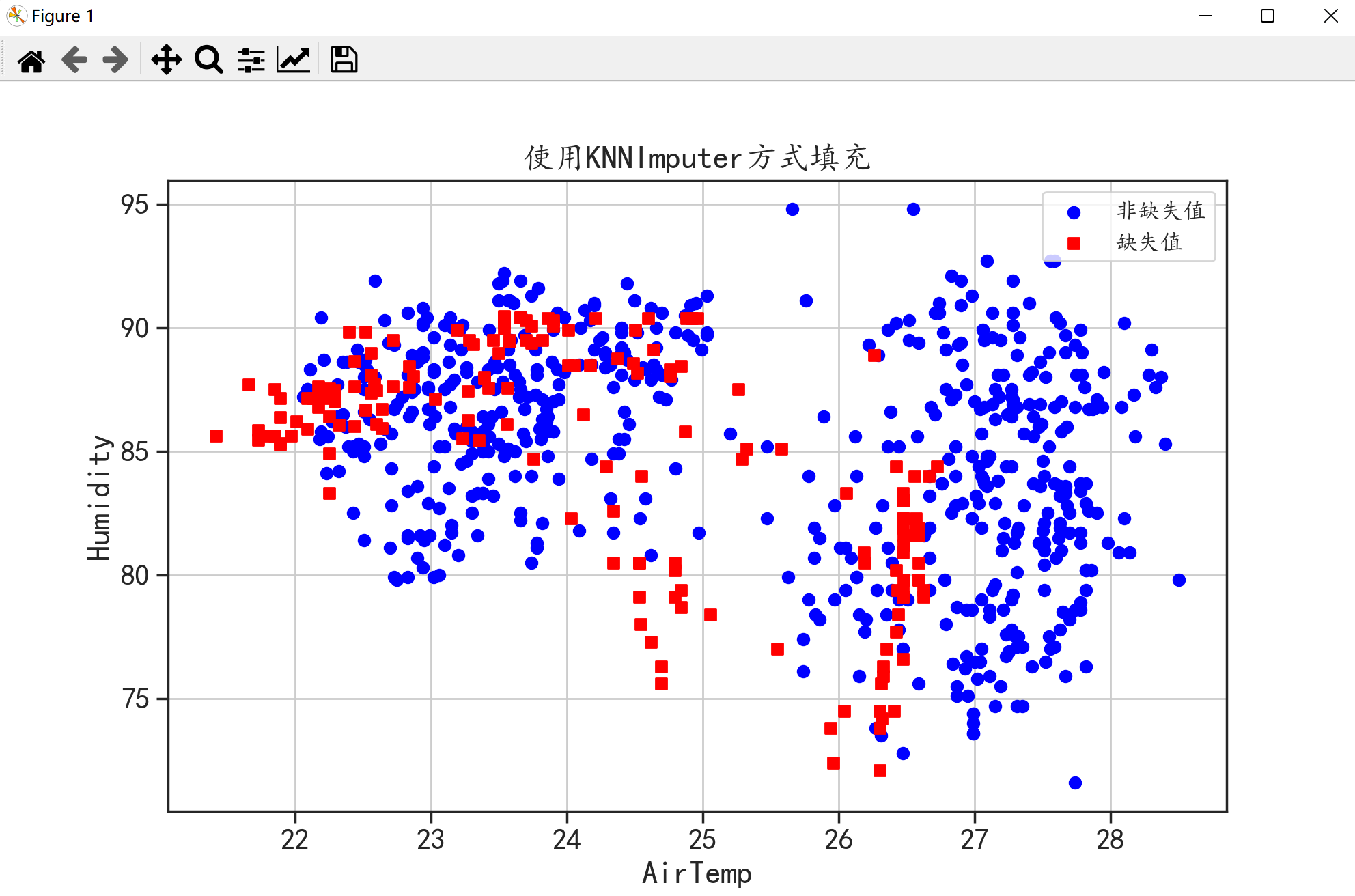
🌑
🌕 数据描述与异常值发现
数据描述是通过分析数据的统计特征增强对数据的理解从而利用合适的机器学习方法对数据进行挖掘、分析。
🌗 数据描述统计
数据描述统计主要有数据的集中位置、离散程度、偏度和峰度等。
首先我们导入一个数据集。
这个数据集的部分如下
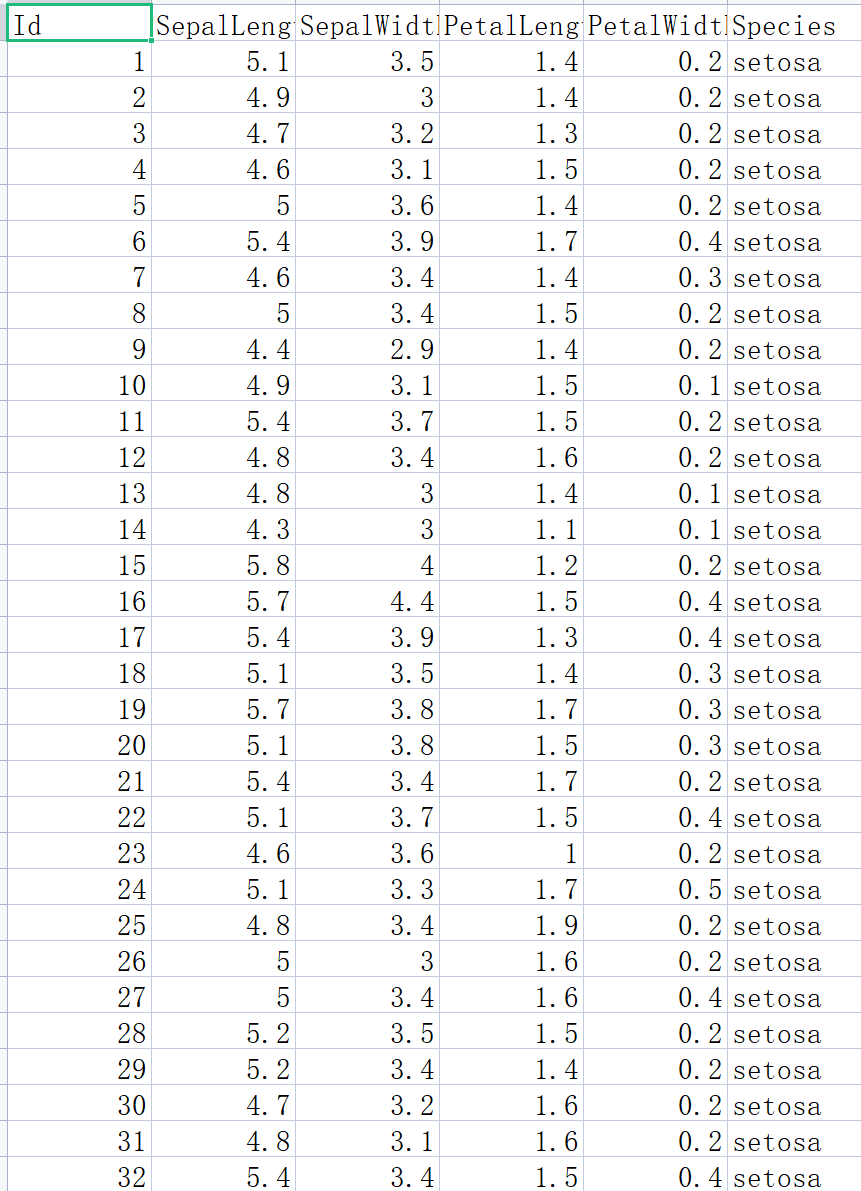
为了方面我们进行数据描述统计我们需要把Id列和Species列删除因为Id并不是我们要的数据Species也不是数字。
import pandas as pd
a = pd.read_csv("D:/Pycharm/机器学习数据/program/data/chap2/Iris.csv")
a = a.drop(["Id","Species"],axis = 1)
print(a)

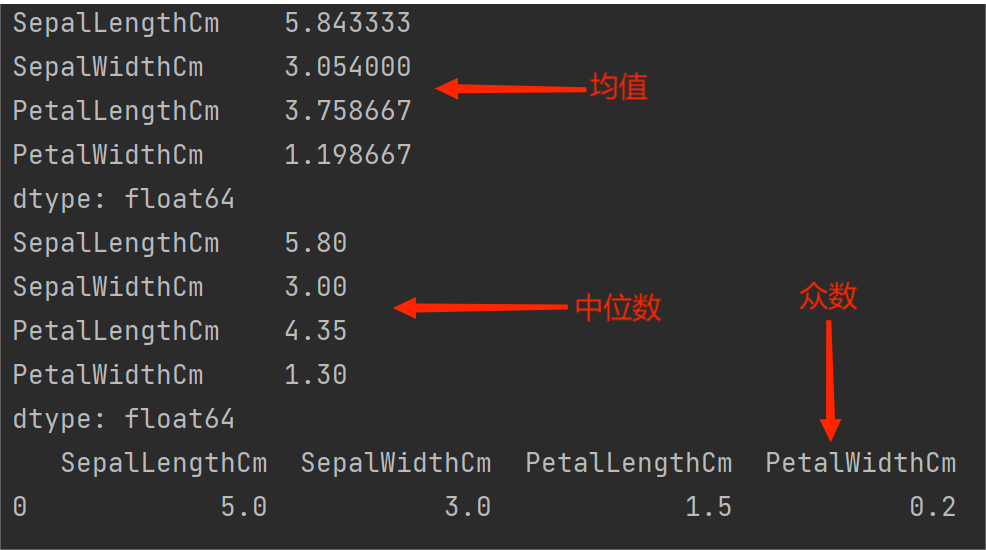
🌑 数据集中位置
描述数据集中位置的统计量主要有均值、中位数、众数等。
print(a.mean()) # 求均值
print(a.median()) # 求中位数
print(a.mode()) # 求众数
🌑 离散程度
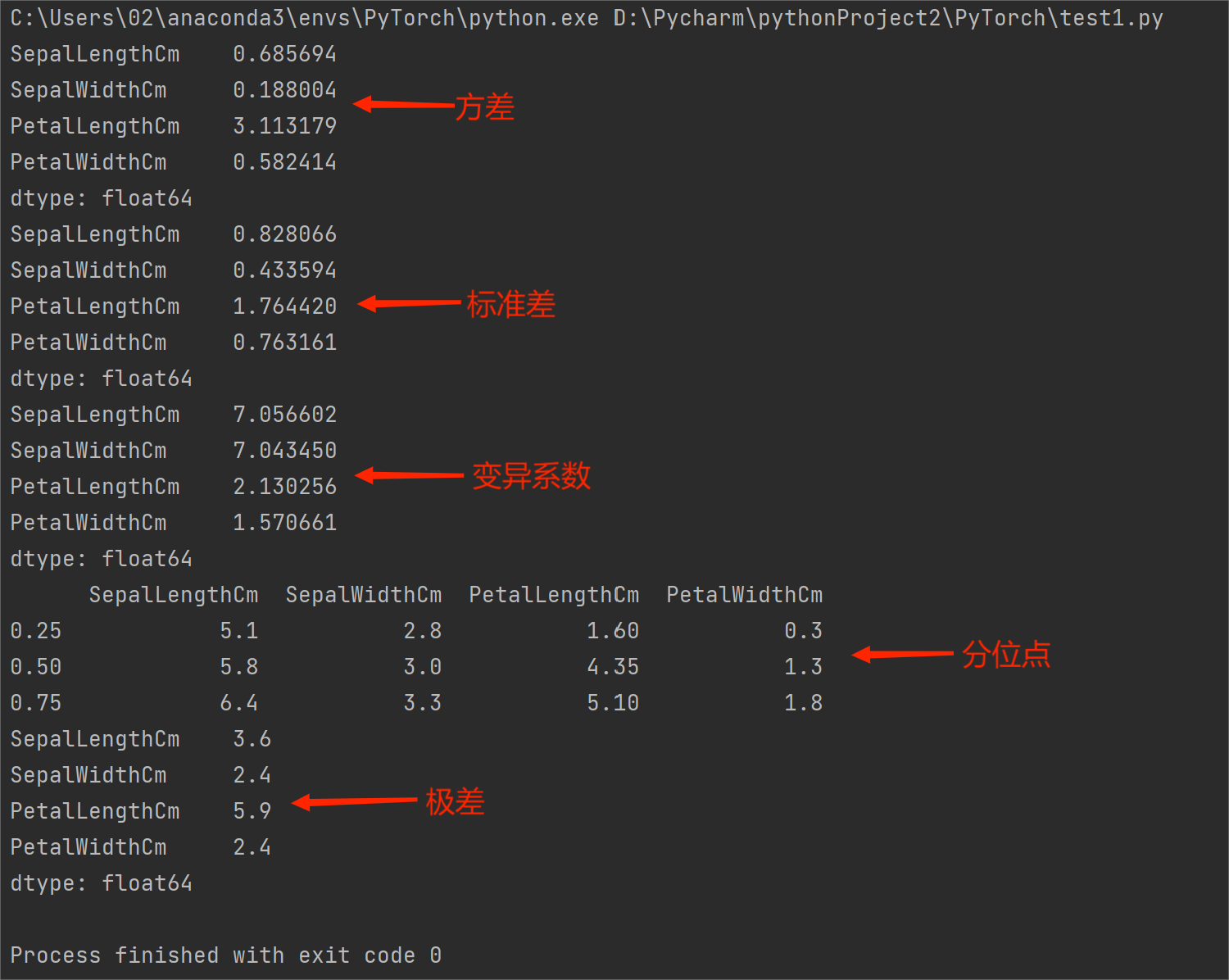
描述数据离散程度的统计量主要有方差、标准差、变异系数、分位数和极差等。
⭐️变异系数度量观测数据的标准差相对于均值的离中程度计算公式为均值除以标准差。变异系数没有量纲所以针对不同度量方式的变量可以相互比较变异系数取值越大说明数据越分散。
⭐️分位数亦称分位点是指将一个随机变量的概率分布范围分为几个等份的数值点可以使用quantile()方法进行计算。
⭐️极差指的是数据最大值和最小值之间的差值极差越小说明数据越集中。
print(a.var()) # 方差
print(a.std()) # 标准差
print(a.mean() / a.std()) # 变异系数
print(a.quantile(q=[0.25,0.5,0.75])) # 分位点0.25是计算第一四分位数0.5是第二四分位数中位数0.75是第三四分位数
print(a.max() - a.min()) # 极差
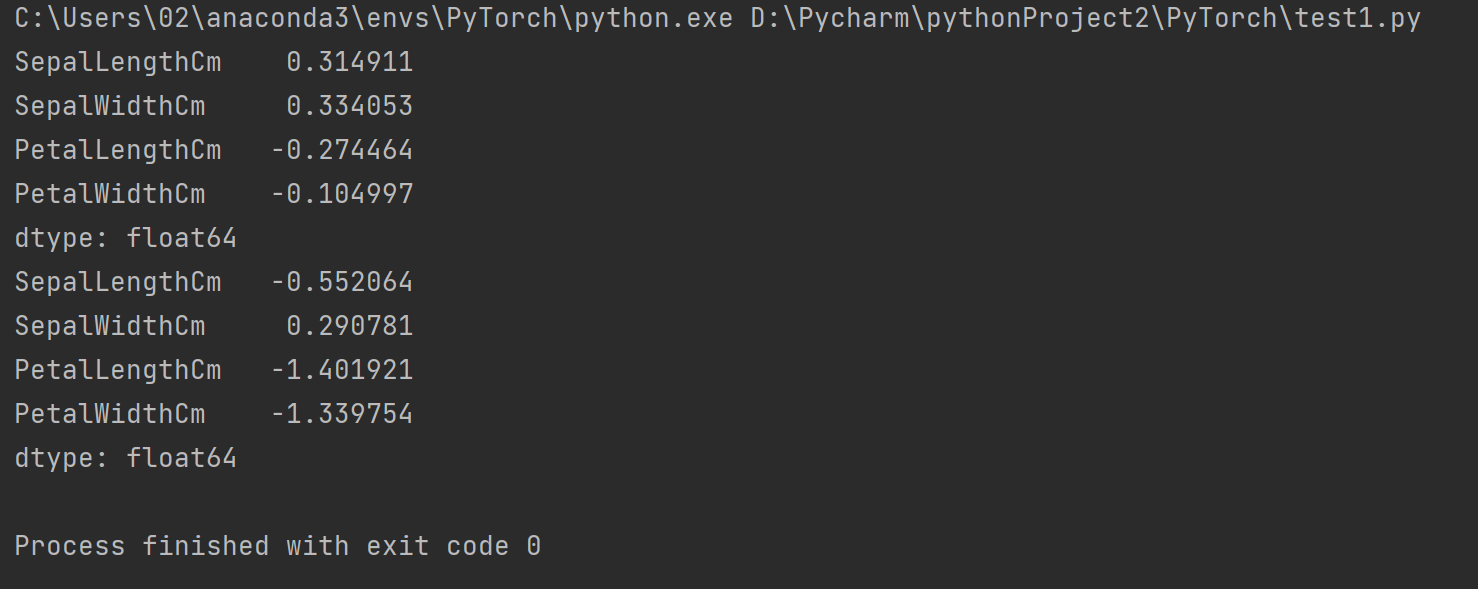
🌑 偏度和峰度
⭐️ 偏度也称偏态系数是用于衡量对称程度或偏斜程度的指标。可以通过skew()方法进行计算。
⭐️ 峰度也称峰态系数是哟过来衡量数据尾部分散度的指标。可以通过kurtosis()方法进行计算。
print(a.skew())
print(a.kurtosis())
🌑 单个数据变量的分布情况
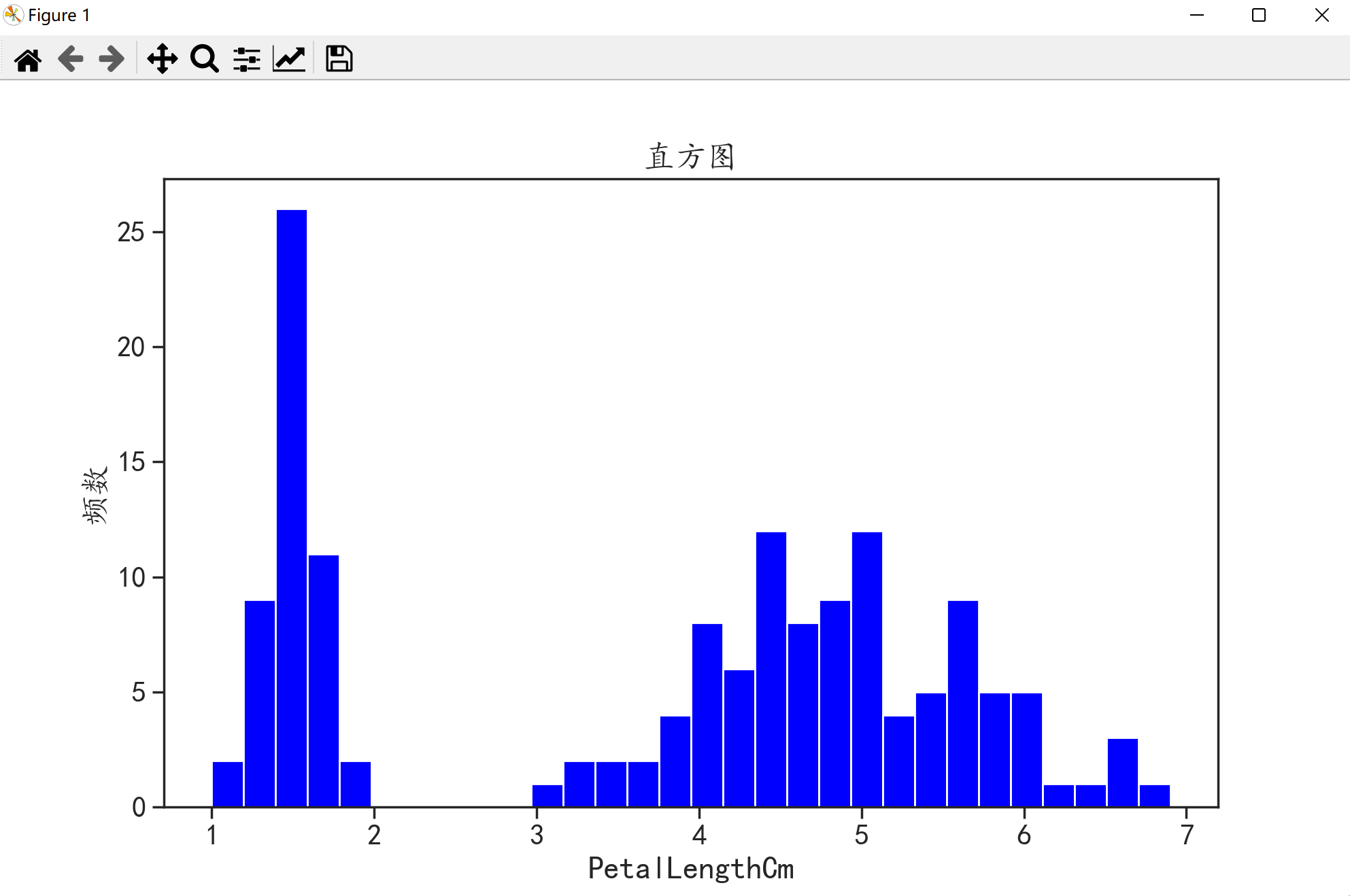
单个连续变量可以使用直方图进行可视化。
import pandas as pd
from matplotlib import pyplot as plt
import matplotlib
matplotlib.rcParams['axes.unicode_minus']=False
import seaborn as sns
sns.set(font="Kaiti",style="ticks",font_scale=1.4)
a = pd.read_csv("D:/Pycharm/机器学习数据/program/data/chap2/Iris.csv")
a = a.drop(["Id","Species"],axis = 1)
plt.figure(figsize = (10,6))
plt.hist(a.PetalLengthCm,bins = 30,color = "blue")
plt.xlabel("PetalLengthCm")
plt.ylabel("频数")
plt.title("直方图")
plt.show()
hist()是绘制直方图的函数第一个参数是指定要绘制直方图的数据a.PetalLengthCm第二个参数是设置长条形的数目bins=30)第三个参数是长条形的颜色设置。
🌗 发现异常值的基本方法
在前面我们处理了缺失值当一个数据没有缺失值后我们就要去分析去看有没有异常值。要处理异常值我们首先就要发现异常值。那么怎样的值才被定义为“异常”呢
🌑 3sigma法则
针对单个变量通常可以使用3sigma法则识别异常值即超出均值3倍标准差的数据可被认为是异常值言下之意就是用数据的值减去均值后的绝对值大于标准差的3倍就是异常值。
下面我们使用前面由IterativeImputer填充缺失值后的数据中的5个变量来分析每个变量是否存在异常值。
import pandas as pd
from matplotlib import pyplot as plt
from sklearn.experimental import enable_iterative_imputer
from sklearn.impute import IterativeImputer
# 中文显示问题
import matplotlib
matplotlib.rcParams['axes.unicode_minus']=False
import seaborn as sns
sns.set(font="Kaiti",style="ticks",font_scale=1.4)
# 数据准备前面有
a = pd.read_csv("D:/Pycharm/机器学习数据/program/data/chap2/热带大气海洋数据.csv")
index = pd.isna(a.AirTemp) | pd.isna(a.Humidity)
iterimp = IterativeImputer(random_state = 123)
a_iter = iterimp.fit_transform(a)
AirTemp = a_iter[:,4]
Humidity = a_iter[:,5]
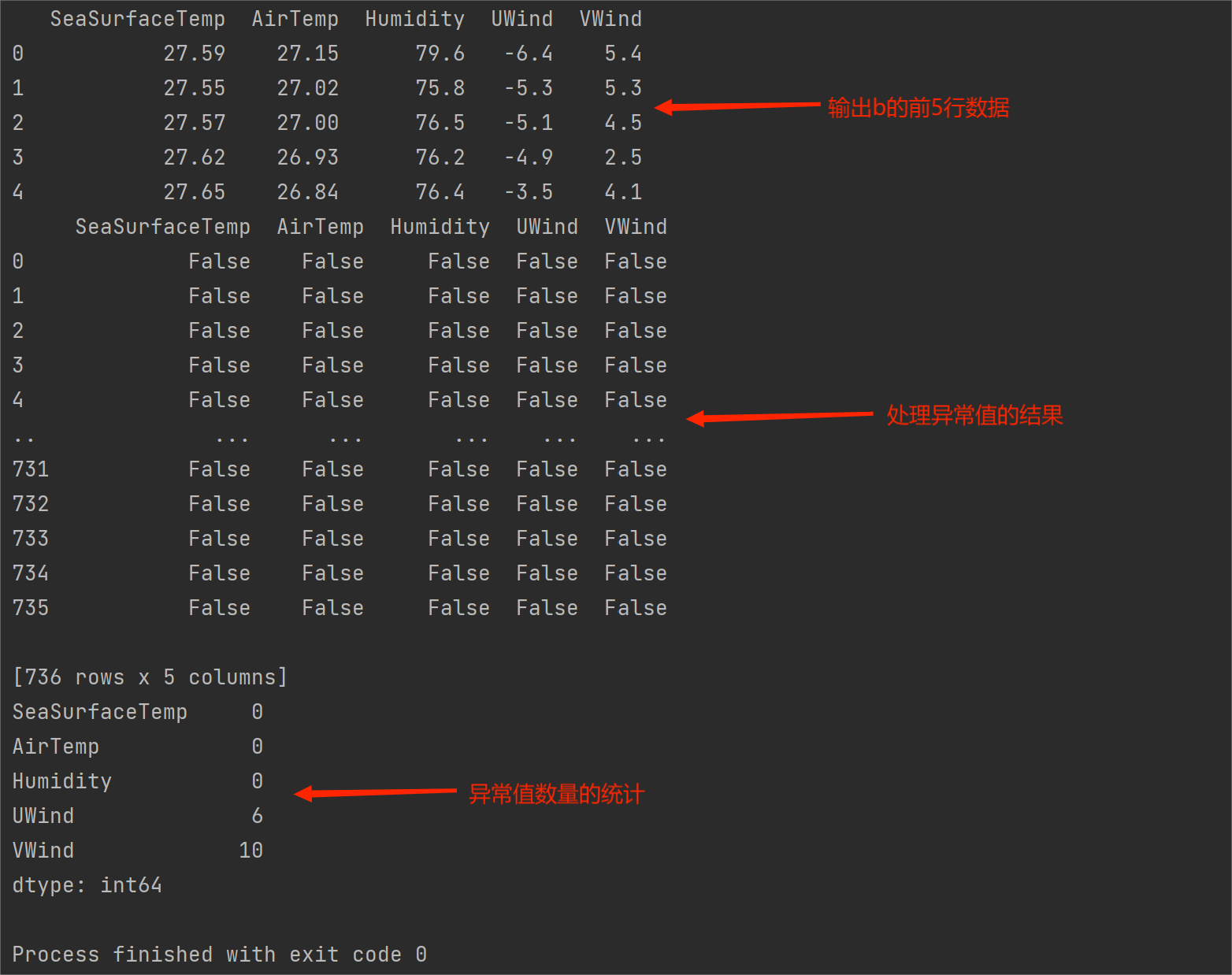
b = pd.DataFrame(data = a_iter[:,3:8],columns = ["SeaSurfaceTemp","AirTemp","Humidity","UWind","VWind"])
print(b.head(5)) # 输出b的前五行数据
# 找出异常值
bmean = b.mean() # 均值
bstd = b.std() # 标准差
result = abs(b - bmean) > 3 * bstd # 结果
print(result) # 处理异常值的结果
print(result.sum()) # 异常值数量的统计
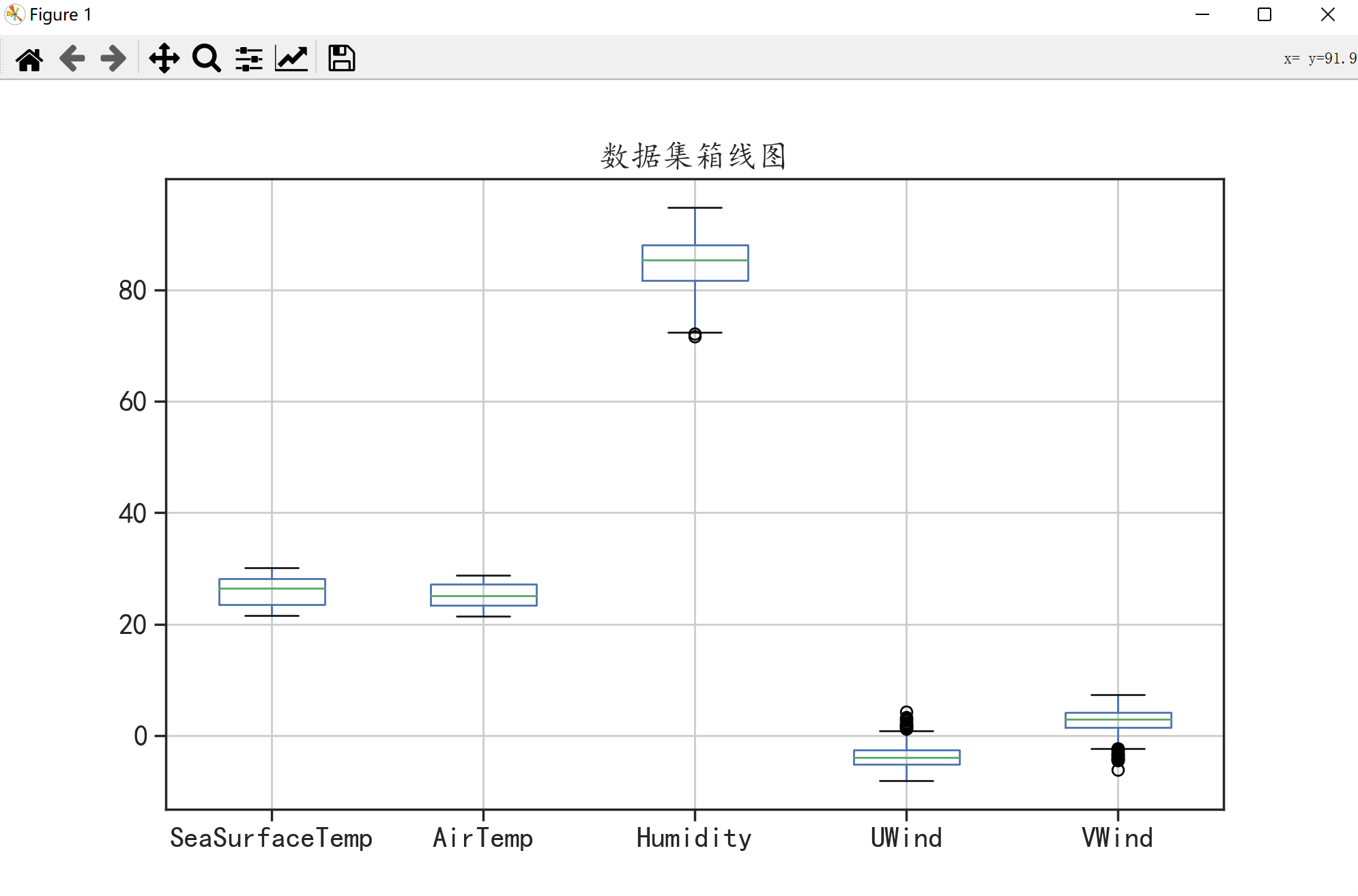
🌑 箱线图
同时针对该数据也可以用箱线图进行可视化分析箱线图在可视化时会使用点输出异常值的位置因此可以判断数据中是否存在异常值。
b.plot(kind = "box",figsize = (10,6))
plt.title("数据集箱线图")
plt.grid()
plt.show()
🌑 散点图
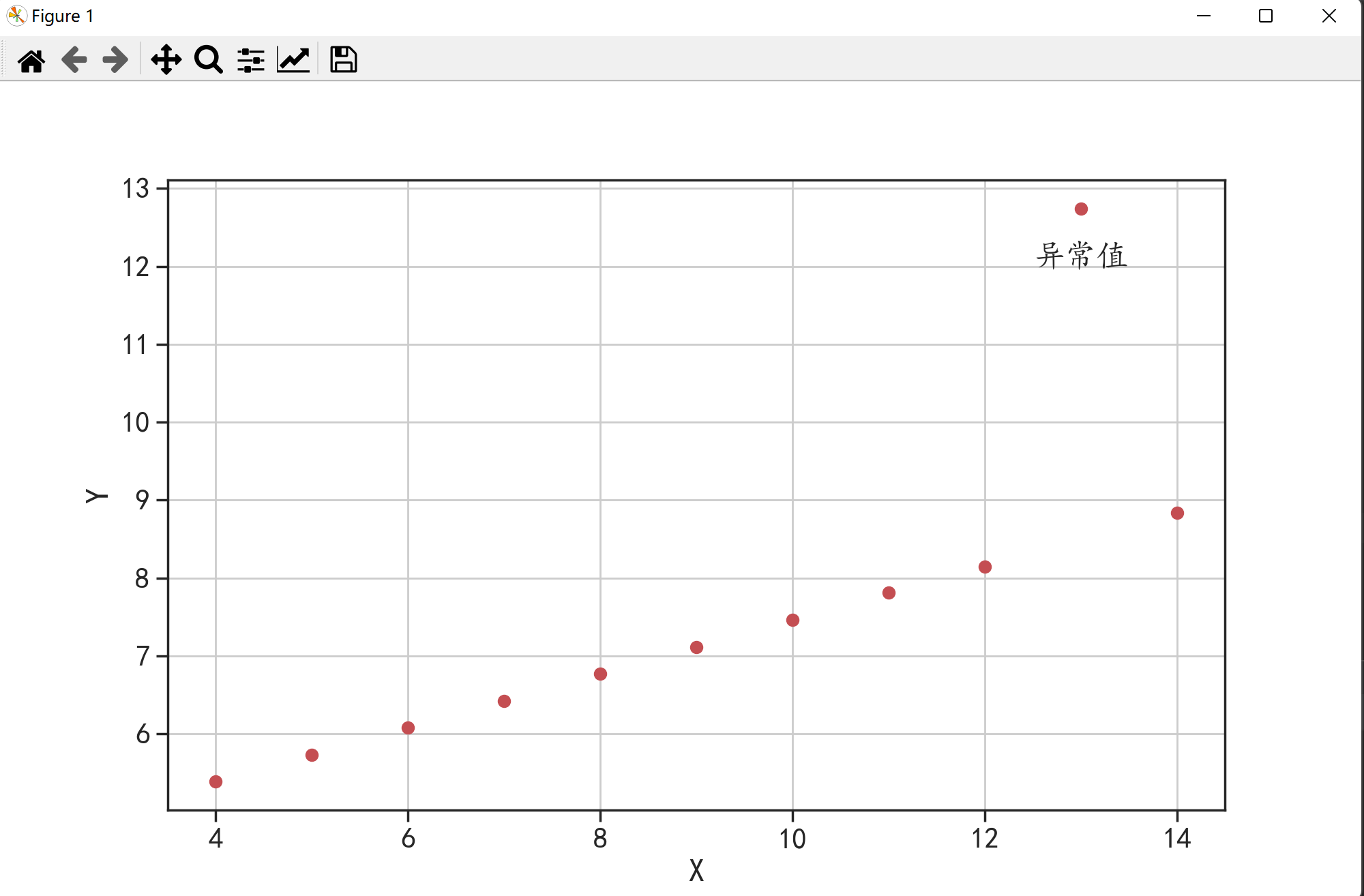
前面两种方式都是分析单个变量是否有异常值对于两个变量也可以使用散点图直观地分析数据中是否有异常值。
from matplotlib import pyplot as plt
import matplotlib
matplotlib.rcParams['axes.unicode_minus']=False
import seaborn as sns
sns.set(font="Kaiti",style="ticks",font_scale=1.4)
x = [10,8,13,9,11,14,6,4,12,7,5]
y = [7.46,6.77,12.74,7.11,7.81,8.84,6.08,5.39,8.15,6.42,5.73]
plt.figure(figsize = (10,6))
plt.plot(x,y,"ro")
plt.grid()
plt.xlabel("X")
plt.ylabel("Y")
plt.text(12.5,12,"异常值")
plt.show()