

吴恩达机器学习(二)——机器学习之监督模型之回归模型之线性回归模型
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
y-hat一般指的就是预测值
线性回归模型实例
构建模型
我们有一个房子的大小size得到房屋价格price通过这两个常数就可计算一个输入和输出的函数关系。
f wb(x(i)) = wx(i) +b
i指的是第几个训练数据
评估模型——成本函数
参考链接: link
成本函数和损失函数的区别
机器学习领域我们经常会遇到cost function和loss function(也叫error function)而这两个function实际是有区别的。loss function通常用于衡量单个样本其预测值和实际值的“差距”而cost function通常是针对样本集中的所有样本而且是一个平均值。
通常来说模型越准确越接近真实其cost function的值就越小
在线性回归问题中通常使用square loss的形式。线性回归常用的square loss形式是均方误差MSE

选择最优模型——梯度下降法
在训练模型的过程中我们需要选择一个最符合数据的模型出来根据上述我们可以知道成本函数越小说明训练的模型越能够有较好的预测效果。如下图回顾整个过程
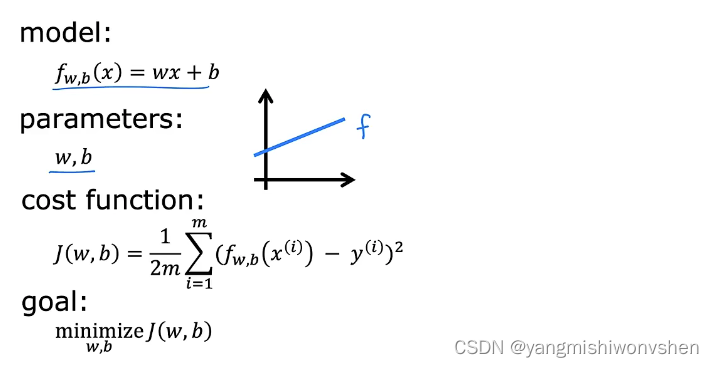
一般最小化成本函数是通过梯度下降法即先随机给出参数的一组值然后更新参数使每次更新后的结构都能够让损失函数变小最终达到最小即可
如下图很形象的展示了找到局部最优参数w的过程
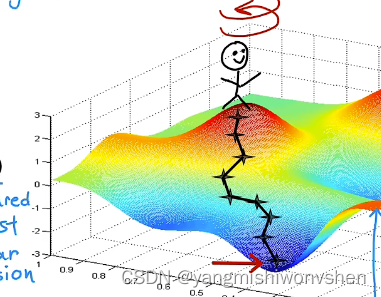
梯度下降如何实现

这里的α是学习率表示参数更新的步长α永远是正数α越大参数一次调整的幅度越大很容易无法找到局部最优解α如果太小了可以找到局部最优解但是找局部最优参数的速度就会变得非常慢。
找到局部最优解的情况
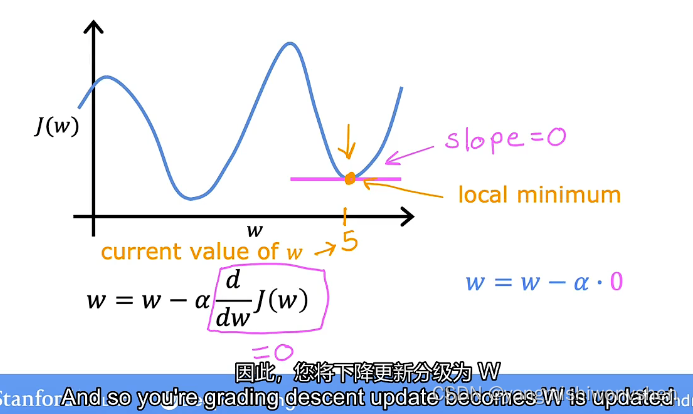
当找到局部最优解的时候梯度偏导数为0参数w不再更新将不会再继续进行梯度下降的过程
为什么使用固定的学习率就可以达到局部最优解
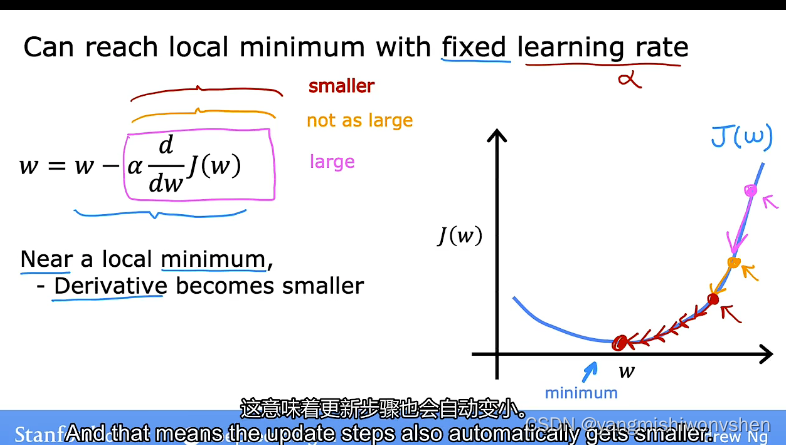
因为随着越来越靠近成本函数局部最小值收敛的这个过程中导数值也会越来越小参数调整的幅度也会越来越小
线性回归模型的梯度下降公式

| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |